Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
🍒 Cherry Studio 是一个支持多模型服务的桌面客户端,为专业用户而打造,内置 30 多个行业的智能助手,帮助用户在多种场景下提升工作效率。
Cherry Studio 内置了很多服务商,集成了超过 300 多个大语言模型。在使用过程中,你可以随意切换模型来回答问题,充分利用各个大模型的优势解决问题。目前,已经集成的服务商见服务商配置:
Cherry Studio 支持 Windows 和 macOS 两大主流操作系统,未来还会支持移动平台。这意味着无论您使用什么设备,都能享受到 Cherry Studio 带来的便利。告别平台限制,尽情挖掘 GPT 技术的潜力!
Cherry Studio 的设计初衷是满足各行各业对 GPT 技术的需求。无论您是埋头编码的开发者、追求灵感的设计师,还是笔耕不辍的作家,Cherry Studio 都能成为您的得力助手。通过自然语言处理技术,它能帮助您提升工作效率,轻松应对数据分析、文本生成、代码编写等各种挑战。
开发者的代码伙伴:利用 Cherry Studio 进行代码生成和调试,让编程更加高效。
设计师的灵感源泉:借助 Cherry Studio 进行创意文本生成和设计说明,激发无限创意。
作家的得力助手:通过 Cherry Studio 辅助撰写和编辑文章,让文字创作更加流畅。
突出特色,引领创新
开源精神:Cherry Studio 提供开源代码,鼓励用户自行定制和扩展,打造专属的 GPT 助手。
持续更新:最新版本 v0.4.4 已经发布,开发者始终致力于优化用户体验和功能完善。
简约设计:界面直观简洁,操作便捷,让您专注于创作本身。
高效工作:可以快速切换不同的模型回答问题,快速寻找解决方案
智能会话:通过 AI 自动命名会话,让所有的聊天记录都一目了然,方便后期整理和阅读
拖拽排序:不论是智能体、会话、还是设置都可以拖拽鼠标完成排序,让信息井井有条
翻译无忧:内置智能翻译服务,覆盖主流语种,借助 AI 技术实现精准高效的跨语言交流
多语言支持:满足全球用户的需求,让 GPT 技术跨越语言障碍。
多主题切换:支持白天和夜间模式,不论是白天还是夜晚都可以赏心悦目
使用 Cherry Studio 非常简单,只需几个步骤即可开启您的 GPT 之旅:
下载适合您系统的版本
安装并启动客户端
根据界面提示操作
尽情使用各种强大功能
根据需要调整设置
加入社区,与其他用户交流经验
Cherry Studio 不仅仅是一款软件,更是您通往 GPT 技术无限可能的大门。它将复杂的技术简化为易用的工具,让每个人都能轻松驾驭 GPT 的力量。无论您是技术专家还是普通用户,Cherry Studio 都能为您的工作和生活带来前所未有的便利。立即下载 Cherry Studio,开启您的智能之旅吧!
智能体页面是一个助手广场,这里你可以选择或者搜索你想要的模型预设,点击器卡片后即可将助手添加在对话页面的助手列表当中。
你也可以在页面中编辑和创建自己的助手。
点击我的点击创建智能体卡片即可开始创建自己的助手。
提示词输入框右上角按钮为AI优化提示词按钮,点击后会覆盖原文。所用模型为。
翻译初始状态是一个基础的翻译提示词,你也可以自定义翻译提示词来实现自己想要的翻译效果。
翻译所使用的模型可以点击顶部设置按钮到页面设置。
在小程序页面你可以在客户端内使用各大服务商的网页版AI相关程序,目前暂不支持自定义添加和删除。
知识库使用可参考进阶教程中的。
在此页面可设置软件的界面语言,以及设置代理等。
助手是对所选模型做一些个性化的设置来使用模型,如提示词预设和参数预设等,通过这些设置让所选模型能更加符合你预期的工作。
系统默认助手预设了一个比较通用的参数(无提示词),您可以直接使用或者到智能体页面寻找你需要的预设来使用。
助手是话题的父集,单个助手下可以创建多个话题(即对话),所有话题共用助手的参数设置和预设词(prompt)等模型设置。
模型设置与助手设置当中的模型设置参数同步,详见助手设置部分文档。
在对话设置当中,仅该模型设置作用于当前助手,其余设置作用于全局。如:设置消息样式为气泡后在任何助手的任何话题下都是气泡样式。
消息分割线:使用分割线将消息正文与操作栏隔开。
使用衬线字体:字体样式切换,现在你也可以通过自定义css来更换字体。
代码显示行号:模型输出代码片段时显示代码块行号。
代码块可折叠:打开后当输出长代码在代码片段当中时,可自动折叠代码块。
消息样式:可切对话界面换为气泡样式或列表样式。
代码风格:可切换代码片段的显示风格。
数学公式引擎:
KaTeX 渲染速度更快,因为它是专门为性能优化设计的;
MathJax 渲染较慢,但功能更全面,支持更多的数学符号和命令。
消息字体大小:调整对话界面字体的大小。
显示预估Token数:在输入框显示输入文本预估消耗的Token数(非实际上下文消耗的Token,仅供参考)。
长文本粘贴为文件:当从其他地方复制长段文本粘贴到输入框时会自动显示为文件的样式,减少后续输入内容时的干扰。
Markdown渲染输入消息:关闭时只渲染模型回复的消息,不渲染发送的消息。
快速敲击3次空格翻译:在对话界面输入框输入消息后,连敲三次空格可翻译输入的内容为英文。的
注意:该操作会覆盖原文。
在助手界面选择需要设置的助手名称→在右键菜单中选对应设置
助手设置作用于该助手下的所有话题。
名称:可自定义为方便辨识的助手名称;
提示词:即prompt,可以参照智能体页面的提示词写法来编辑内容。
默认模型:可以为该助手固定一个默认模型,从智能体页面添加时或复制助手时初始模型为该模型。不设置该项初始模型则为全局初始模型(即默认助手模型)。
助手的默认模型有两种,一为全局默认对话模型,另一为助手默认模型;助手的默认模型优先级高于全局默认对话模型。当不设置助手默认模型时,助手默认模型=全局默认对话模型。
自动重置模型:打开时 - 当在该话题下使用过程中切换其他模型使用时,再次新建话题会将新话题的重置为助手的默认模型。当该项关闭时新建话题的模型会跟随上一话题所使用的模型。
如助手的默认模型为gpt-3.5-turbo,我在该助手下创建话题1,在话题1的对话过程中切换了gpt-4o使用,此时:
如果开启了自动重置:新建话题2时,话题2默认选择的模型为gpt-3.5-turbo;
如果未开启自动重置:新建话题2时,话题2默认选择的模型为gpt-4o。
温度 (Temperature) :
温度参数控制模型生成文本的随机性和创造性程度(默认值为0.7)。具体表现为:
低温度值(0-0.3):
输出更确定、更专注
适合代码生成、数据分析等需要准确性的场景
倾向于选择最可能的词汇输出
中等温度值(0.4-0.7):
平衡了创造性和连贯性
适合日常对话、一般性写作
推荐用于聊天机器人对话(0.5左右)
高温度值(0.8-1.0):
产生更具创造性和多样性的输出
适合创意写作、头脑风暴等场景
但可能降低文本的连贯性
Top P (核采样):默认值为 1,值越小,AI 生成的内容越单调,也越容易理解;值越大,AI 回复的词汇范围越大,越多样化。
核采样通过控制词汇选择的概率阈值来影响输出:
较小值(0.1-0.3):
仅考虑最高概率的词汇
输出更保守、更可控
适合代码注释、技术文档等场景
中等值(0.4-0.6):
平衡词汇多样性和准确性
适合一般对话和写作任务
较大值(0.7-1.0):
考虑更广泛的词汇选择
产生更丰富多样的内容
适合创意写作等需要多样化表达的场景
这两个参数可以独立使用或组合使用
根据具体任务类型选择合适的参数值
建议通过实验找到最适合特定应用场景的参数组合
以上内容仅供参考和了解概念,所给参数范围不一定适合所有模型,具体可参考模型相关文档给出的参数建议。
上下文数量 (Context Window)
要保留在上下文中的消息数量,数值越大,上下文越长,消耗的 token 越多:
5-10:适合普通对话
>10:需要更长记忆的复杂任务(例如:按照写作提纲分步生成长文的任务,需要确保生成的上下文逻辑连贯)
注意:消息数越多,token 消耗越大
开启消息长度限制(MaxToken)
单次回答最大Token数,在大语言模型中,max token(最大令牌数)是一个关键参数,它直接影响模型生成回答的质量和长度。具体设置多少取决于自己的需要,当然也可以参考以下建议。
如:在CherryStudio当中填写好key后测试模型是否连通时,只需要知道模型是否有正确返回消息而不需特定内容,这种情况下设置MaxToken为1即可。
多数模型的MaxToken上限为4k Tokens,当然也有2k也有16k甚至更多的,具体需要到对应介绍页面查看。
建议:
普通聊天:500-800
短文生成:800-2000
代码生成:2000-3600
长文生成:4000及以上 (需要模型本身支持)
一般情况下模型生成的回答将被限制在MaxToken的范围内,当然也有可能会出现被截断(如写长代码时)或表达不完整等情况出现,特殊情况下也需要根据实际情况来灵活调整。
流式输出(Stream)
流式输出是一种数据处理方式,它允许数据以连续的流形式进行传输和处理,而不是一次性发送所有数据。这种方式使得数据可以在生成后立即被处理和输出,极大地提高了实时性和效率。
在CherryStudio客户端等类似环境下简单来说就是打字机效果,
关闭后(非流):模型生成完信息后整段一次性输出(想象一下微信收到消息的感觉);
打开时:逐字输出,可以理解为大模型每生成一个字就立马发送给你,直到全部发送完。
如果某些特殊模型不支持流式输出需要将该开关关闭,比如刚开始只支持非流的o1-mini等。
自定义参数
在请求体(body)中加入额外请求参数,如presence_penalty等字段,一般人一般情况下用不到。
填法:参数名称—参数类型(文本、数字等)—值,参考文档:点击前往
上述top-p、maxtokens、stream等参数就是这些参数之一。
自定义参数优先级高于内置参数。即自定义参数如果与内置参数重复,则自定义参数会覆盖内置参数。
如:自定义参数中设置model为gpt-4o后,在对话中无论选择哪个模型都使用的是gpt-4o模型。
当前页面仅做界面功能的介绍,配置教程可以参考基础教程中的教程。
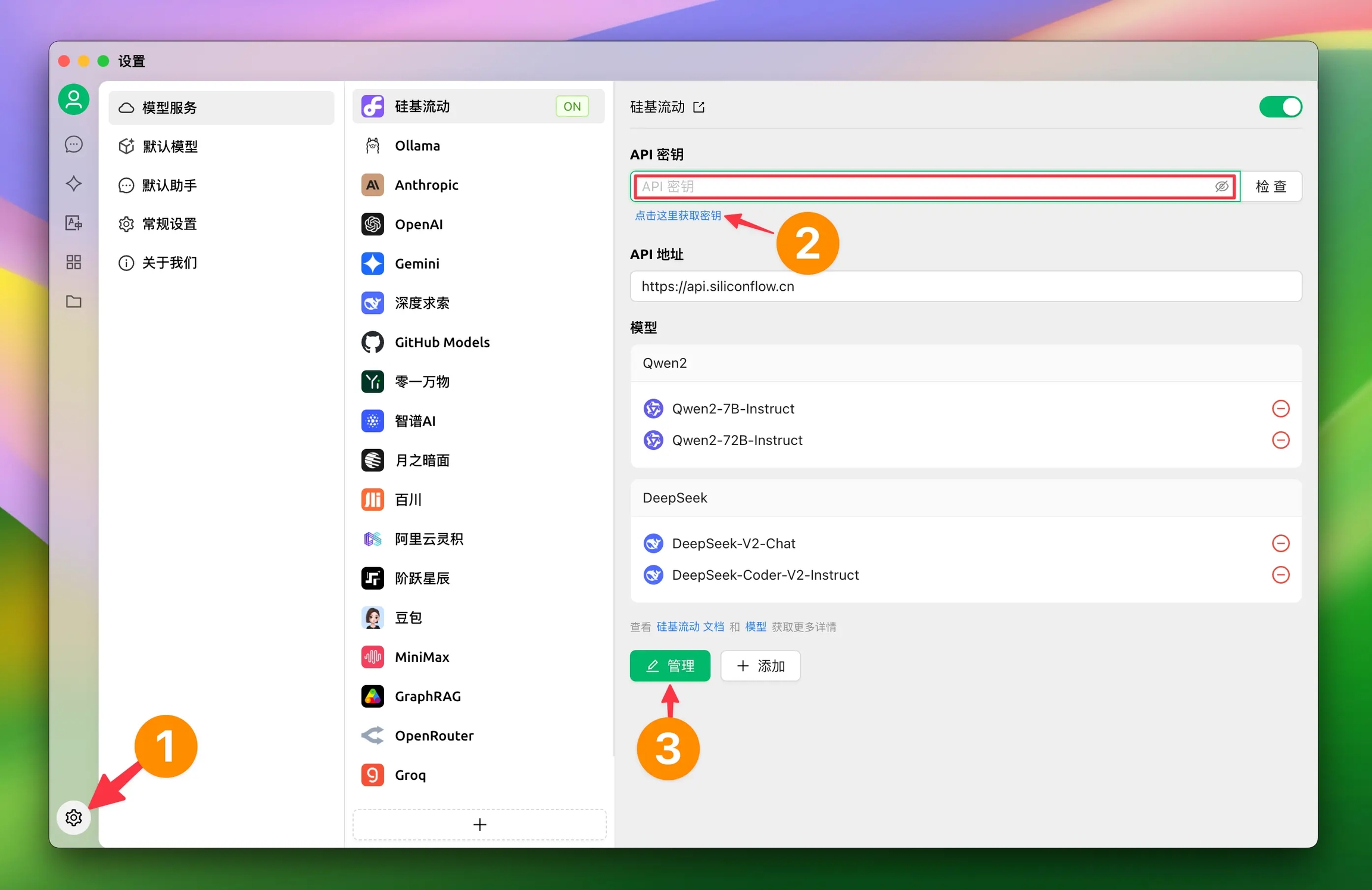
在使用内置服务商时只需要填写对应的秘钥即可;
不同服务商对秘钥的叫法可能有所不同,秘钥、Key、API Key、令牌等都指的是同一个东西。
在CherryStudio当中,单个服务商支持多Key轮询使用,轮询方式为从前到后列表循环的方式。
多Key用英文逗号隔开添加。如以下示例方式:
在使用内置服务商时一般不需要填写API地址,如果需要修改请严格按照对应的官方文档给的地址填写。
如果服务商给的地址为https://xxx.xxx.com/v1/chat/completions这种格式,只需要填写根地址部分(https://xxx.xxx.com)即可。
CherryStudio客户端会自动拼接剩余的路径(/v1/chat/completions),未按要求填写可能会导致无法正常使用。
说明:大多数服务商的大语言模型路由是统一的,一般情况下不需要进行如下操作。如果服务商的API路径是v2、v3/chat/completions或者其他版本时,可在地址栏手动输入对应版本以"/"结尾;当服务商请求路由不是常规的/v1/chat/completions时使用服务商提供的完整的地址以“#”结尾,
即:
API地址使用"/"结尾时只拼接"chat/completions"
API地址使用"#"结尾时不执行拼接操作,只使用填入的地址。
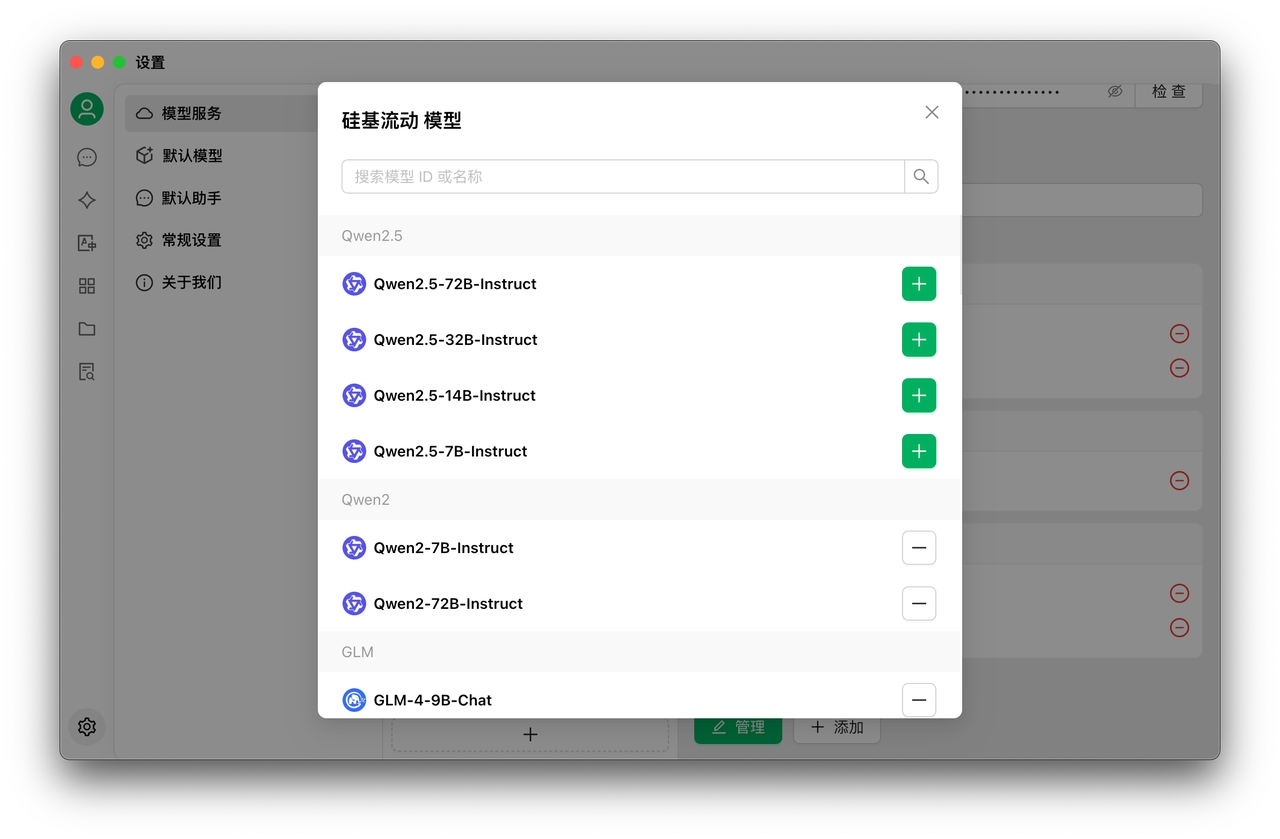
一般情况下点击服务商配置页面最左下角的管理按钮会自动获取该服务商所有支持调用的模型,从获取列表中点击“+”号添加到模型列表即可。
注意:点击管理按钮时弹窗列表里的模型需要点击模型后的“+”号添加到服务商配置页面的模型列表才可以在模型选择列表当中出现。
点击API 秘钥输入框后的检查按钮即可测试是否成功配置。
模型检查时默认使用模型列表已添加模型的最后一个对话模型,如果检查时有失败的情况请检查模型列表是否有错误的或不被支持的模型。
配置成功后务必打开右上角的开关,否则该服务商仍处于未启用状态,无法在模型列表中找到对应模型。
绘画功能目前仅支持硅基流动的绘画模型,你可以到注册一个账户添加到来使用。
后续将会增加更多服务商,敬请期待。
有关参数的疑问可以鼠标悬停在对应区域的?处查看介绍。




文件界面会展示所有对话、绘画、知识库等相关的文件,可以在此页面集中管理和查看。
通过此设置可灵活的对界面做一些个性化的更改和设置。具体方法参考进阶教程中的。
首先到首页点击下载 Mac 版本,或点击下方直达
下载完成后点击这里
拖拽图标安装
安装完成
在该界面可以启(停)用和设置一些功能的快捷键,具体按照界面指示设置。
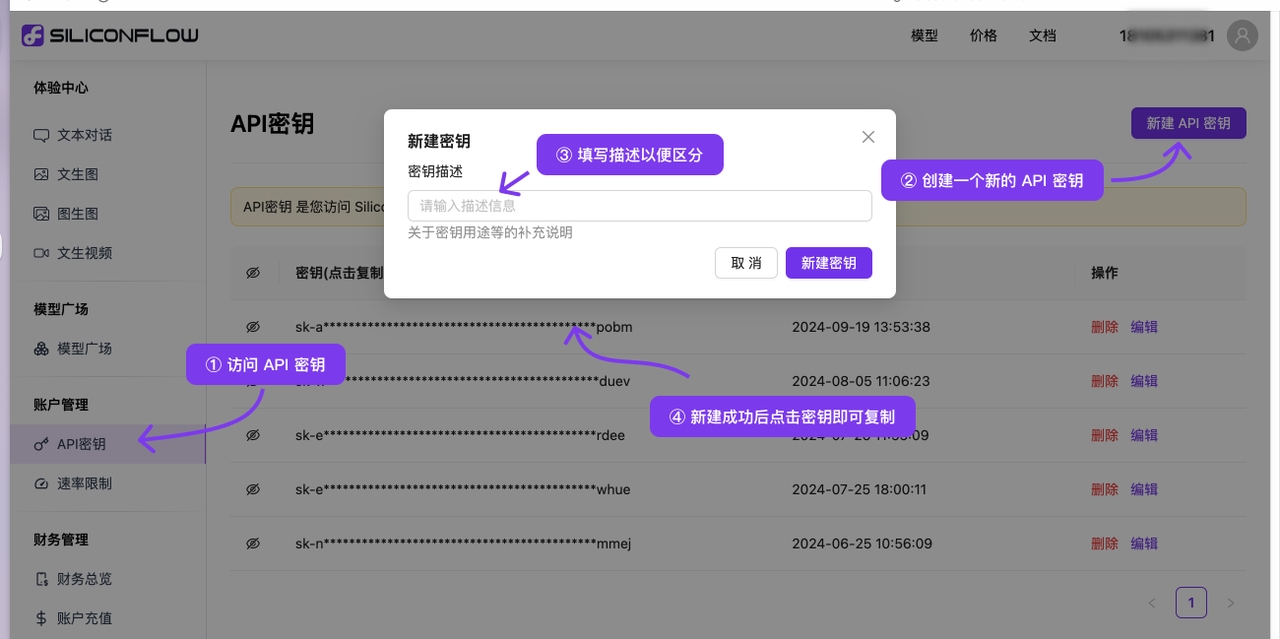
将生成的key复制,并打开CherryStudio的
登录并进入令牌页面
创建新令牌(也可以直接使用default令牌↑)
复制令牌
打开CherryStudio的服务商设置点击服务商列表最下方的添加
输入备注名称,提供商选OpenAI,点击确定
填入刚刚复制的key
回到获取API Key的页面,在对应浏览器地址栏复制根地址,例:
当地址为IP+端口时填http://IP:端口即可,如:http://127.0.0.1:3000
严格区分http和https,如果没有开启SSL就不要填https
添加模型(点击管理自动获取或手动输入)打开右上角开关即可使用。
OneAPI其他主题可能界面有所不同,但添加方法跟上述操作流程一致。































下载
到官网找到对应版本的安装包下载
等待下载完成
如果出现浏览器提示文件不被信任等情况选择保留即可
选择保留→信任 Cherry-Studio
打开文件
安装
登录
找到火山方舟点击进入,或直接点击
进入页面后在侧栏最下方找到开通管理
在开通管理页面开通需要使用的模型
全部开通完成后点击在线管理,进入后点击创建推理接入点
接入点名称随便写,保证自己能辨识即可,建议跟模型名同步
点击+添加模型按钮
① 选择模型、② 选择版本(主线模型)、③ 确认
点击确认接入
点击添加模型
按照此流程依次添加模型
点击侧栏最下方的API Key管理
创建API Key
创建成功后,点击创建好的API Key后的小眼睛打开并复制
将复制的API Key填入到CherryStudio当中后,打开服务商开关就可以使用了。
API地址有两种写法
第一种为客户端默认的:https://ark.cn-beijing.volces.com/api/v3/
第二种写法为:https://ark.cn-beijing.volces.com/api/v3/chat/completions#
两种写法没什么区别,保持默认即可,无需修改。
打开CherryStudio的设置找到豆包
关于/和#结尾的区别参考文档服务商设置的API地址部分,
Monaspace
英文字体 可商用
GitHub 推出了名为 Monaspace 的开源字体家族,拥有五种风格可选:Neon(现代风格)、Argon(人文风格)、Xenon(衬线风格)、Radon(手写风格)、Krypton(机械风格)。
MiSans Global
多语言 可商用
MiSans Global 是由小米主导,联合蒙纳字库、汉仪字库共同打造的全球语言字体定制项目。
这是一个庞大的字体家族,涵盖 20 多种书写系统,支持 600 多种语言。















Docs Github 仓库地址:https://github.com/CherryHQ/cherry-studio-docs
贡献文档可以通过以下方式来进行:
可以通过提交 issue 或者提交 Pull Request 方式进行
也可以联系开发者 [email protected] 获取编辑身份
我们欢迎对 Cherry Studio 的贡献!您可以通过以下方式贡献:
1. 贡献代码:开发新功能或优化现有代码。
2. 修复错误:提交您发现的错误修复。
3. 维护问题:帮助管理 GitHub 问题。
4. 产品设计:参与设计讨论。
5. 撰写文档:改进用户手册和指南。
6. 社区参与:加入讨论并帮助用户。
7. 推广使用:宣传 Cherry Studio。
Tokens 是 AI 模型处理文本的基本单位,可以理解为模型"思考"的最小单元。它不完全等同于我们理解的字符或单词,而是模型自己的一种特殊的文本分割方式。
一个汉字通常会被编码为 1-2 个 tokens
例如:"你好" ≈ 2-4 tokens
常见单词通常是 1 个 token
较长或不常见的单词会被分解成多个 tokens
例如:
"hello" = 1 token
"indescribable" = 4 tokens
空格、标点符号等也会占用 tokens
换行符通常是 1 个 token
不同服务商的tokenizer都不一样,甚至同服务商不同模型的tokenizer也有所差别,该知识仅用于明确token的概念。
Tokenizer(分词器)是 AI 模型将文本转换为 tokens 的工具。它决定了如何把输入文本切分成模型可以理解的最小单位。
不同的语料库导致优化方向不同
多语言支持程度差异
特定领域(医疗、法律等)的专门优化
BPE (Byte Pair Encoding) - OpenAI GPT 系列
WordPiece - Google BERT
SentencePiece - 适合多语言场景
有的注重压缩效率
有的注重语义保留
有的注重处理速度
同样的文本在不同模型中的 token 数量可能不同:
基本概念: 嵌入模型是一种将高维离散数据(文本、图像等)转换为低维连续向量的技术,这种转换让机器能更好地理解和处理复杂数据。想象一下,就像把复杂的拼图简化成一个简单的坐标点,但这个点仍然保留了拼图的关键特征。在大模型生态中,它作为"翻译官",将人类可理解的信息转换为AI可计算的数字形式。
工作原理: 以自然语言处理为例,嵌入模型可以将词语映射到向量空间中的特定位置。在这个空间里,语义相近的词会自动聚集在一起。比如:
"国王"和"王后"的向量会很接近
"猫"和"狗"这样的宠物词也会距离相近
而"汽车"和"面包"这样语义无关的词则会距离较远
主要应用场景:
文本分析:文档分类、情感分析
推荐系统:个性化内容推荐
图像处理:相似图片检索
搜索引擎:语义搜索优化
核心优势:
降维效果:将复杂数据简化为易处理的向量形式
语义保持:保留原始数据中的关键语义信息
计算效率:显著提升机器学习模型的训练和推理效率
技术价值: 嵌入模型是现代AI系统的基础组件,为机器学习任务提供了高质量的数据表示,是推动自然语言处理、计算机视觉等领域发展的关键技术。
基本工作流程:
知识库预处理阶段
将文档分割成适当大小的chunk(文本块)
使用embedding模型将每个chunk转换为向量
将向量和原文存储到向量数据库中
查询处理阶段
将用户问题转换为向量
在向量库中检索相似内容
将检索到的相关内容作为上下文提供给LLM
登录并打开令牌页面
点击添加令牌
输入令牌名称后点击提交(其他设置如有需要可自行配置)
打开CherryStudio的服务商设置点击服务商列表最下方的添加
输入备注名称,提供商选OpenAI,点击确定
填入刚刚复制的key
回到获取API Key的页面,在对应浏览器地址栏复制根地址,例:
当地址为IP+端口时填http://IP:端口即可,如:http://127.0.0.1:3000
严格区分http和https,如果没有开启SSL就不要填https
添加模型(点击管理自动获取或手动输入)打开右上角开关即可使用。
通过自定义 CSS 可以修改软件的外观更加符合自己的喜好,例如这样:
https://github.com/CherryHQ/cherry-studio/tree/develop/src/renderer/src/assets/styles
分享一些中国风 Cherry Studio 主题皮肤: https://linux.do/t/topic/325119/95
Cherry Studio 数据存储遵循系统规范,数据会自动放在用户目录下,具体目录位置如下:
macOS: /Users/username/Library/Application Support/CherryStudioDev
Windows: C:\Users\username\AppData\Roaming\CherryStudio
如果希望能够修改存储位置,可以通过创建软连接的方式来实现。将软件退出,然后把数据移动到你希望保存的位置,然后在原位置创建一个链接指向移动后的位置即可。
知识库教程
在 0.91 版本中,CherryStudio 带来了期待已久的知识库功能。
下面我们将按步骤呈现 CherryStudio 的详细使用说明。
在模型管理服务中查找模型,可以点击“嵌入模型”快速筛选;
找到需要的模型,添加到我的模型。
知识库入口:在 CherryStudio 左侧工具栏,点击知识库图标,即可进入管理页面;
添加知识库:点击添加,开始创建知识库;
命名:输入知识库的名称并添加嵌入模型,以 bge-m3 为例,即可完成创建。
添加文件:点击添加文件的按钮,打开文件选择;
选择文件:选择支持的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,并打开;
向量化:系统会自动进行向量化处理,当显示完成时(绿色 ✓),代表向量化已完成。
CherryStudio 支持多种添加数据的方式:
文件夹目录:可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
纯文本笔记:支持输入纯文本的自定义内容。
当文件等资料向量化完成后,即可进行查询:
点击页面下方的搜索知识库按钮;
输入查询的内容;
呈现搜索的结果;
并显示该条结果的匹配分数。
创建一个新的话题,在对话工具栏中,点击知识库,会展开已经创建的知识库列表,选择需要引用的知识库;
输入并发送问题,模型即返回通过检索结果生成的答案 ;
同时,引用的数据来源会附在答案下方,可快捷查看源文件。
点击CherryStudio客户端窗口后按下快捷键Ctrl+Shift+I(Mac端:Command+Option+I)
当前活动窗口必须为CherryStudio的客户端窗口才能调出控制台;
需要先打开控制台,再点击测试或者发起对话等请求才能收集到请求信息。
在弹出的控制台窗口中点击Network → 点击查看②处最后一个标有红色 × 的completions(对话类、翻译、模型连通性检查等遇到错误时) 或generations(绘画遇到错误时) → 点击Response查看完整的返回内容(图中④的区域)。
如果你无法判断该错误的原因,请将该界面截图发送到中寻求帮助。
讨论组成员会分享自己的使用经验,帮助你解决问题
加入 Telegram 讨论组获取帮助:
适合记录防止开发者遗忘,或者在这里参与讨论
Github Issues:
如果没有找到其他反馈渠道,可以联系开发者获取帮助
邮箱联系开发者:[email protected]
具体操作步骤可以参考:
网址链接:支持网址 url,如;
站点地图:支持 xml 格式的站点地图,如;
















400
请求体格式错误等
查看对话返回的错误内容或控制台查看报错内容,根据提示操作。
【常见情况1】:如果是gemini模型,可能需要进行绑卡操作; 【常见情况2】:数据体积超限,常见于视觉模型,图片体积超过上游单个请求流量上限会返回该错误码。
401
认证失败:模型不被支持或服务端账户被封禁等
联系或查看对应服务商账户状态
403
请求操作无权限
根据对话返回的错误信息或控制台错误信息提示进行相应操作

排名更新时间: 2025-01-19
1
1
Gemini-Exp-1206
1374
+5/-4
20,845
2
1
ChatGPT-4o-latest (2024-11-20)
1365
+4/-4
34,030
OpenAI
2
4
Gemini-2.0-Flash-Thinking-Exp-1219
1364
+5/-5
16,357
2
4
Gemini-2.0-Flash-Exp
1357
+5/-5
19,640
4
1
o1-2024-12-17
1352
+7/-7
7,957
OpenAI
6
4
o1-preview
1335
+5/-3
33,197
OpenAI
7
7
DeepSeek-V3
1320
+5/-6
11,591
DeepSeek
7
10
Step-2-16K-Exp
1306
+8/-8
4,028
StepFun
8
11
o1-mini
1305
+4/-3
48,654
OpenAI
8
8
Gemini-1.5-Pro-002
1303
+3/-3
45,203
11
13
Grok-2-08-13
1288
+4/-3
66,281
xAI
11
15
Yi-Lightning
1287
+5/-3
28,959
01 AI
11
10
GPT-4o-2024-05-13
1285
+3/-2
117,760
OpenAI
11
7
Claude 3.5 Sonnet (20241022)
1284
+3/-3
47,437
Anthropic
11
22
Qwen2.5-plus-1127
1282
+7/-6
7,680
Alibaba
11
18
Deepseek-v2.5-1210
1279
+7/-5
7,261
DeepSeek
14
22
Athene-v2-Chat-72B
1277
+5/-4
21,014
NexusFlow
15
21
GLM-4-Plus
1274
+5/-3
27,773
Zhipu AI
15
21
GPT-4o-mini-2024-07-18
1273
+3/-2
60,551
OpenAI
16
24
Gemini-1.5-Flash-002
1271
+3/-3
34,540
16
35
Llama-3.1-Nemotron-70B-Instruct
1269
+6/-6
7,596
Nvidia
18
11
Meta-Llama-3.1-405B-Instruct-bf16
1268
+4/-3
21,285
Meta
20
10
Claude 3.5 Sonnet (20240620)
1268
+2/-3
86,177
Anthropic
20
12
Meta-Llama-3.1-405B-Instruct-fp8
1267
+3/-3
63,202
Meta
20
11
Gemini Advanced App (2024-05-14)
1266
+3/-3
52,148
20
31
Grok-2-Mini-08-13
1266
+3/-3
54,893
xAI
20
12
GPT-4o-2024-08-06
1265
+3/-2
47,981
OpenAI
21
23
Qwen-Max-0919
1263
+4/-4
17,436
Alibaba
28
19
Gemini-1.5-Pro-001
1260
+2/-2
82,432
28
28
Deepseek-v2.5
1258
+3/-4
26,353
DeepSeek
28
33
Qwen2.5-72B-Instruct
1257
+3/-4
39,984
Alibaba
28
20
Llama-3.3-70B-Instruct
1257
+5/-4
15,516
Meta
29
18
GPT-4-Turbo-2024-04-09
1256
+2/-2
102,126
OpenAI
30
23
Mistral-Large-2407
1252
+3/-3
48,207
Mistral
30
30
Athene-70B
1250
+5/-5
20,618
NexusFlow
30
38
Llama-3.1-Tulu-3-70B
1244
+11/-9
3,026
Ai2
33
22
GPT-4-1106-preview
1250
+3/-2
103,732
OpenAI
34
39
Meta-Llama-3.1-70B-Instruct
1248
+3/-3
58,786
Meta
34
20
Claude 3 Opus
1247
+2/-2
202,735
Anthropic
34
39
Amazon Nova Pro 1.0
1244
+5/-5
13,076
Amazon
36
24
GPT-4-0125-preview
1245
+3/-2
97,070
OpenAI
36
37
Mistral-Large-2411
1243
+5/-5
10,634
Mistral
39
20
Claude 3.5 Haiku (20241022)
1237
+7/-4
10,773
Anthropic
40
39
Reka-Core-20240904
1235
+6/-6
7,937
Reka AI
44
42
Gemini-1.5-Flash-001
1227
+3/-2
65,650
45
40
Jamba-1.5-Large
1221
+5/-5
9,125
AI21 Labs
46
41
Gemma-2-27B-it
1220
+3/-3
72,425
46
55
Amazon Nova Lite 1.0
1218
+6/-5
10,868
Amazon
46
48
Qwen2.5-Coder-32B-Instruct
1217
+7/-6
5,731
Alibaba
46
43
Gemma-2-9B-it-SimPO
1216
+5/-6
10,557
Princeton
46
44
Command R+ (08-2024)
1215
+5/-5
10,546
Cohere
46
39
Llama-3.1-Nemotron-51B-Instruct
1211
+7/-8
3,897
Nvidia
46
54
Phi-4
1210
+9/-10
2,485
Microsoft
47
56
Gemini-1.5-Flash-8B-001
1212
+4/-4
36,162
48
55
Aya-Expanse-32B
1209
+4/-4
26,994
Cohere
48
52
GLM-4-0520
1207
+8/-5
10,214
Zhipu AI
49
46
Nemotron-4-340B-Instruct
1209
+4/-3
20,609
Nvidia
49
47
Reka-Flash-20240904
1205
+7/-5
8,130
Reka AI
52
48
Llama-3-70B-Instruct
1206
+2/-3
163,797
Meta
57
46
Claude 3 Sonnet
1201
+2/-2
113,033
Anthropic
57
69
Amazon Nova Micro 1.0
1197
+5/-6
10,956
Amazon
61
57
Gemma-2-9B-it
1191
+3/-3
50,239
61
56
Command R+ (04-2024)
1190
+2/-2
80,868
Cohere
61
69
Hunyuan-Standard-256K
1189
+8/-9
2,899
Tencent
61
70
Llama-3.1-Tulu-3-8B
1185
+11/-10
3,077
Ai2
62
56
Qwen2-72B-Instruct
1187
+3/-3
38,889
Alibaba
62
44
GPT-4-0314
1186
+3/-2
55,965
OpenAI
62
69
Ministral-8B-2410
1182
+7/-7
5,109
Mistral
64
70
Aya-Expanse-8B
1181
+6/-6
8,797
Cohere
64
56
Command R (08-2024)
1180
+5/-5
10,846
Cohere
66
60
Claude 3 Haiku
1179
+2/-2
122,291
Anthropic
66
56
DeepSeek-Coder-V2-Instruct
1178
+5/-5
15,752
DeepSeek AI
66
69
Jamba-1.5-Mini
1176
+5/-6
9,269
AI21 Labs
67
84
Meta-Llama-3.1-8B-Instruct
1176
+3/-3
52,646
Meta
75
55
GPT-4-0613
1163
+2/-3
91,642
OpenAI
75
69
Qwen1.5-110B-Chat
1161
+4/-4
27,467
Alibaba
75
85
Yi-1.5-34B-Chat
1157
+4/-4
25,126
01 AI
75
69
Mistral-Large-2402
1157
+3/-3
64,912
Mistral
75
70
Reka-Flash-21B-online
1156
+5/-4
16,024
Reka AI
75
103
QwQ-32B-Preview
1153
+11/-11
3,415
Alibaba
78
78
Llama-3-8B-Instruct
1152
+2/-2
109,211
Meta
78
90
InternLM2.5-20B-chat
1149
+5/-5
10,599
InternLM
80
74
Command R (04-2024)
1149
+2/-3
56,380
Cohere
80
78
Mistral Medium
1148
+3/-3
35,554
Mistral
80
78
Reka-Flash-21B
1148
+4/-3
25,803
Reka AI
80
72
Mixtral-8x22b-Instruct-v0.1
1148
+2/-3
53,788
Mistral
80
72
Qwen1.5-72B-Chat
1147
+3/-3
40,638
Alibaba
80
81
Granite-3.1-8B-Instruct
1139
+13/-12
2,468
IBM
82
91
Gemma-2-2b-it
1142
+3/-4
41,868
89
72
Gemini-1.0-Pro-001
1131
+4/-4
18,793
89
82
Zephyr-ORPO-141b-A35b-v0.1
1127
+10/-8
4,860
HuggingFace
89
86
Qwen1.5-32B-Chat
1125
+4/-4
22,772
Alibaba
89
93
Granite-3.1-2B-Instruct
1117
+11/-11
2,476
IBM
90
90
Phi-3-Medium-4k-Instruct
1123
+4/-3
26,112
Microsoft
91
103
Starling-LM-7B-beta
1119
+5/-5
16,671
Nexusflow
94
93
Mixtral-8x7B-Instruct-v0.1
1114
+0/-0
76,138
Mistral
94
97
Yi-34B-Chat
1111
+5/-4
15,922
01 AI
94
82
Gemini Pro
1110
+7/-8
6,559
96
96
Qwen1.5-14B-Chat
1109
+3/-5
18,678
Alibaba
96
95
WizardLM-70B-v1.0
1106
+7/-6
8,380
Microsoft
96
82
GPT-3.5-Turbo-0125
1106
+3/-3
68,873
OpenAI
96
101
Meta-Llama-3.2-3B-Instruct
1103
+8/-7
8,411
Meta
97
92
DBRX-Instruct-Preview
1103
+4/-3
33,737
Databricks
97
99
Phi-3-Small-8k-Instruct
1102
+5/-6
18,477
Microsoft
98
102
Tulu-2-DPO-70B
1099
+6/-6
6,663
AllenAI/UW
103
92
Granite-3.0-8B-Instruct
1093
+6/-6
7,005
IBM
103
97
OpenChat-3.5-0106
1091
+5/-5
12,980
OpenChat
104
112
Llama-2-70B-chat
1093
+3/-3
39,634
Meta
105
104
Vicuna-33B
1091
+4/-4
22,950
LMSYS
105
107
Starling-LM-7B-alpha
1088
+7/-4
10,416
UC Berkeley
105
116
Nous-Hermes-2-Mixtral-8x7B-DPO
1084
+11/-10
3,835
NousResearch
106
97
Snowflake Arctic Instruct
1090
+3/-3
34,172
Snowflake
106
112
NV-Llama2-70B-SteerLM-Chat
1081
+10/-8
3,637
Nvidia
107
99
Gemma-1.1-7B-it
1084
+4/-4
25,065
111
101
DeepSeek-LLM-67B-Chat
1077
+7/-7
4,987
DeepSeek AI
112
100
OpenChat-3.5
1076
+5/-8
8,112
OpenChat
112
100
OpenHermes-2.5-Mistral-7B
1074
+8/-6
5,089
NousResearch
112
107
Granite-3.0-2B-Instruct
1074
+7/-8
7,193
IBM
113
118
Mistral-7B-Instruct-v0.2
1072
+4/-4
20,058
Mistral
113
118
Phi-3-Mini-4K-Instruct-June-24
1071
+4/-4
12,818
Microsoft
113
118
Qwen1.5-7B-Chat
1070
+6/-9
4,868
Alibaba
114
93
GPT-3.5-Turbo-1106
1068
+5/-5
17,032
OpenAI
115
122
Phi-3-Mini-4k-Instruct
1066
+4/-4
21,085
Microsoft
115
116
Dolphin-2.2.1-Mistral-7B
1062
+10/-13
1,713
Cognitive Computations
115
117
SOLAR-10.7B-Instruct-v1.0
1062
+10/-10
4,288
Upstage AI
119
123
Llama-2-13b-chat
1063
+5/-5
19,738
Meta
121
118
WizardLM-13b-v1.2
1059
+7/-7
7,178
Microsoft
123
127
CodeLlama-70B-instruct
1041
+21/-17
1,194
Meta
124
128
Meta-Llama-3.2-1B-Instruct
1054
+6/-6
8,535
Meta
124
125
Zephyr-7B-beta
1053
+6/-6
11,334
HuggingFace
124
118
SmolLM2-1.7B-Instruct
1047
+13/-13
2,371
HuggingFace
124
118
MPT-30B-chat
1046
+12/-10
2,648
MosaicML
125
121
Zephyr-7B-alpha
1042
+11/-15
1,814
HuggingFace
127
126
CodeLlama-34B-instruct
1043
+7/-5
7,515
Meta
127
118
falcon-180b-chat
1034
+18/-17
1,327
TII
130
118
Vicuna-13B
1042
+5/-5
19,790
LMSYS
130
126
Gemma-7B-it
1037
+6/-5
9,176
130
127
Phi-3-Mini-128k-Instruct
1037
+4/-4
21,632
Microsoft
130
141
Llama-2-7B-chat
1037
+6/-5
14,555
Meta
130
118
Qwen-14B-Chat
1035
+7/-7
5,070
Alibaba
130
128
Guanaco-33B
1033
+10/-12
2,999
UW
139
132
Gemma-1.1-2b-it
1021
+6/-5
11,348
139
135
StripedHyena-Nous-7B
1018
+9/-7
5,273
Together AI
140
148
OLMo-7B-instruct
1016
+6/-7
6,504
Allen AI
143
140
Mistral-7B-Instruct-v0.1
1008
+6/-6
9,144
Mistral
143
142
Vicuna-7B
1005
+8/-7
7,015
LMSYS
143
129
PaLM-Chat-Bison-001
1004
+8/-5
8,744
148
146
Gemma-2B-it
989
+7/-9
4,922
148
145
Qwen1.5-4B-Chat
988
+6/-6
7,813
Alibaba
150
149
Koala-13B
964
+8/-6
7,034
UC Berkeley
150
150
ChatGLM3-6B
955
+8/-8
4,765
Tsinghua
152
149
GPT4All-13B-Snoozy
932
+13/-15
1,786
Nomic AI
152
150
MPT-7B-Chat
928
+11/-8
4,012
MosaicML
152
155
ChatGLM2-6B
924
+13/-10
2,707
Tsinghua
152
155
RWKV-4-Raven-14B
922
+9/-8
4,934
RWKV
156
150
Alpaca-13B
902
+9/-9
5,876
Stanford
156
156
OpenAssistant-Pythia-12B
893
+7/-8
6,380
OpenAssistant
157
158
ChatGLM-6B
879
+10/-9
4,988
Tsinghua
158
158
FastChat-T5-3B
868
+9/-8
4,302
LMSYS
160
160
StableLM-Tuned-Alpha-7B
840
+11/-11
3,341
Stability AI
160
158
Dolly-V2-12B
822
+11/-12
3,485
Databricks
161
160
LLaMA-13B
800
+12/-14
2,444
Meta
排名(UB):基于 Bradley-Terry 模型的上界排名
排名(StyleCtrl):考虑对话风格的样式控制排名
置信区间:模型表现的置信区间
分数:基于模型性能的竞技场得分
数据来自 lmarena.ai