Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
知识库使用可参考进阶教程中的 知识库教程。
在该界面可以启(停)用和设置一些功能的快捷键,具体按照界面指示设置。
在此页面可设置软件的界面语言、设置代理等。
文件界面会展示所有对话、绘画、知识库等相关的文件,可以在此页面集中管理和查看。
一问多答:支持同一问题通过多个模型同时生成回复,方便用户对比不同模型的表现,详见 对话界面。
自动分组:每个助手的对话记录会自动分组管理,便于用户快速查找历史对话。
对话导出:支持将完整对话或部分对话导出为多种格式(如 Markdown、Word 等),方便储存与分享。
高度自定义参数:除了基础参数调整外,还支持用户填写自定义参数,满足个性化需求。
助手市场:内置千余个行业专用助手,涵盖翻译、编程、写作等领域,同时支持用户自定义助手。
多种格式渲染:支持 Markdown 渲染、公式渲染、HTML 实时预览等功能,提升内容展示效果。
AI 绘画:提供专用绘画面板,用户可通过自然语言描述生成高质量图像。
AI 小程序:集成多种免费 Web 端 AI 工具,无需切换浏览器即可直接使用。
翻译功能:支持专用翻译面板、对话翻译、提示词翻译等多种翻译场景。
文件管理:对话、绘画和知识库中的文件统一分类管理,避免繁琐查找。
全局搜索:支持快速定位历史记录和知识库内容,提升工作效率。
服务商模型聚合:支持 OpenAI、Gemini、Anthropic、Azure 等主流服务商的模型统一调用。
模型自动获取:一键获取完整模型列表,无需手动配置。
多秘钥轮询:支持多个 API 秘钥轮换使用,避免速率限制问题。
精准头像匹配:为每个模型自动匹配专属头像,提升辨识度。
自定义服务商:支持符合 OpenAI、Gemini 、Anthropic 等规范的三方服务商接入,兼容性强。
自定义 CSS:支持全局样式自定义,打造专属界面风格。
自定义对话布局:支持列表或气泡样式布局,并可自定义消息样式(如代码片段样式)。
自定义头像:支持为软件和助手设置个性化头像。
自定义侧边栏菜单:用户可根据需求隐藏或排序侧边栏功能,优化使用体验。
多种格式支持:支持 PDF、DOCX、PPTX、XLSX、TXT、MD 等多种文件格式导入。
多种数据源支持:支持本地文件、网址、站点地图甚至手动输入内容作为知识库源。
知识库导出:支持将处理好的知识库导出并分享给他人使用。
支持搜索检查:知识库导入后,用户可实时检索测试,查看处理结果和分段效果。
快捷问答:在任何场景(如微信、浏览器)中呼出快捷助手,快速获取答案。
快捷翻译:支持快速翻译其他场景中的词汇或文本。
内容总结:对长文本内容进行快速总结,提升信息提取效率。
解释说明:无需复杂提示词,一键解释说明不懂的问题。
多种备份方案:支持本地备份、WebDAV 备份和定时备份,确保数据安全。
数据安全:支持全本地场景使用,结合本地大模型,避免数据泄漏风险。
小白友好:Cherry Studio 致力于降低技术门槛,零基础用户也能快速上手,让用户专注于工作、学习或者创作。
文档完善:提供详细的使用文档和常见问题处理手册,帮助用户快速解决问题。
持续迭代:项目团队积极响应用户反馈,持续优化功能,确保项目健康发展。
开源与扩展性:支持用户通过开源代码进行定制和扩展,满足个性化需求。
知识管理与查询:通过本地知识库功能,快速构建和查询专属知识库,适用于研究、教育等领域。
多模型对话与创作:支持多模型同时对话,帮助用户快速获取信息或生成内容。
翻译与办公自动化:内置翻译助手和文件处理功能,适合需要跨语言交流或文档处理的用户。
AI 绘画与设计:通过自然语言描述生成图像,满足创意设计需求。


登录并进入令牌页面
创建新令牌(也可以直接使用default令牌↑)
复制令牌
macOS 版本安装教程
首先到官网下载页面点击下载 Mac 版本,或点击下方直达
请注意下载 自己 Mac 对应的芯片版本
在小程序页面你可以在客户端内使用各大服务商 AI 相关程序的网页版,目前暂不支持自定义添加和删除。
您还可以订阅公共规则集。该网站列出了一些订阅: https://iorate.github.io/ublacklist/subscriptions
以下是一些比较推荐的订阅源链接:
https://git.io/ublacklist
中文
https://raw.githubusercontent.com/laylavish/uBlockOrigin-HUGE-AI-Blocklist/main/list_uBlacklist.txt
AI生成
打开CherryStudio的服务商设置点击服务商列表最下方的添加
输入备注名称,提供商选OpenAI,点击确定
填入刚刚复制的key
回到获取API Key的页面,在对应浏览器地址栏复制根地址,例:
添加模型(点击管理自动获取或手动输入)打开右上角开关即可使用。
OneAPI其他主题可能界面有所不同,但添加方法跟上述操作流程一致。


在展开菜单中点击关于本机
在弹出窗口中查看处理器信息
如果为 Intel 芯片则下载 Intel 版本安装包
如果为 Apple M* 芯片则下载 Apple 芯片安装包
下载完成后点击这里
拖拽图标安装
到启动台中寻找 Cherry Studio 图标并点击,能打开 Cherry Studio 主界面则安装成功。
本软件依赖 Visual C++ Redistributable 运行库,如果遇到安装提示请点击是来安装软件依赖





在此页面你可以设置软件的颜色主题、页面布局或者 自定义 CSS 来进行一些个性化的设置。
你可以在此处设置默认的界面颜色模式(浅色模式、深色模式或跟随系统)
该设置是针对对话界面的布局的设置。
当打开该设置时点击助手名称页面会自动切换到对应话题页面。
打开时会在话题下方显示话题 创建 的时间。
通过此设置可灵活的对界面做一些个性化的更改和设置。具体方法参考进阶教程中的 。
Cherry Studio 数据备份支持通过 S3 兼容存储(对象存储)的方式进行备份。常见的 S3 兼容存储服务有:AWS S3、Cloudflare R2、阿里云 OSS、腾讯云 COS 以及 MinIO 等。
基于 S3 兼容存储可以通过 A电脑 S3存储 B电脑 的方式来实现多端数据同步。
创建对象存储桶(Bucket),并记录下存储桶名称。强烈建议将存储桶设置为私有读写以避免备份数据泄露!!
参考文档,前往云服务控制台获取 S3 兼容存储的 Access Key ID、Secret Access Key、Endpoint、Bucket、Region 等信息。
Endpoint:S3 兼容存储的访问地址,通常形如 https://<bucket-name>.<region>.amazonaws.com 或 https://<ACCOUNT_ID>.r2.cloudflarestorage.com。
在 S3 备份设置中填写上述信息,点击备份按钮即可进行备份,点击管理按钮可以查看和管理备份文件列表。
获取 Gemini 的 api key 前,你需要有一个 Google Cloud 项目(如果你已有,此过程可跳过)
进入 Google Cloud 创建项目,填写项目名称并点击创建项目
在官方 点击 密钥 创建API密钥
将生成的 key 复制,并打开 CherryStudio 的
找到服务商 Gemini,填入刚刚获取到的 key
点击最下方管理或者添加,加入支持的模型并打开右上角服务商开关就可以使用了。
打开 Cherry Studio 设置。
找到 MCP 服务器 选项。
点击 添加服务器。
将 MCP Server 的相关参数填入()。可能需要填写的内容包括:
名称:自定义一个名称,例如 fetch-server
类型:选择 STDIO
命令:填写 uvx
点击 保存。
完成上述配置后,Cherry Studio 会自动下载所需的 MCP Server - fetch server。下载完成后,我们就可以开始使用了!注意:当 mcp-server-fetch 配置不成功的时候,可以尝试重启一下电脑。
在 MCP 服务器 设置成功添加了 MCP 服务器
从上图可以看出,结合了 MCP 的 fetch 功能后,Cherry Studio 能够更好地理解用户的查询意图,并从网络上获取相关信息,给出更准确、更全面的回答。
使用 GitHub Copilot 需要先拥有一个 GitHub 账号,并订阅 GitHub Copilot 服务,free 版本的订阅也可以,但 free 版本不支持最新的 Claude 3.7 模型,具体请参考 GitHub Copilot 官网。
点击「登录 GitHub」,获取 Device Code 并复制。
成功获取 Device Code 后,点击链接打开浏览器,在浏览器中登录 GitHub 账号,输入 Device Code 并授权。
授权成功后,返回 Cherry Studio,点击「连接 GitHub」,成功后会显示 GitHub 用户名和头像。
点击下方的「管理」按钮,会自动联网获取当前支持的模型列表。
目前使用 Axios 构建请求,Axios 不支持 socks 代理,请使用系统代理或 HTTP 代理,或者直接不在 CherryStudio 中设置代理,使用全局代理。首先请确保您的网络连接正常,以避免获取 Device Code 失败的情况。
暂时不支持Claude模型
当设置了错误的css,或者在设置了css后无法进入设置界面时,使用该方法清除css设置。
打开控制台,点击CherryStudio窗口,按下快捷键Ctrl+Shift+I(MacOS:command+option+I)。
在弹出的控制台窗口中,点击Console
然后手动输入document.getElementById('user-defined-custom-css').remove() ,复制粘贴大概率不会执行。
输入完成后回车确认即可清除css设置,然后再次进入CherryStudio的显示设置当中,删除有问题的css代码。
在 Cherry Studio 知识库中添加的数据全部存储在本地,在添加过程中会复制一份文档放在 Cherry Studio 数据存储目录
向量数据库:https://turso.tech/libsql
当文档被添加到 Cherry Studio 知识库之后,文件会被切分为若干个片段,然后这些片段会交给嵌入模型进行处理
当使用大模型进行问答的时候,会查询和问题相关的文本片段一并交个大语言模型处理
如果对数据隐私有要求,建议使用本地嵌入数据库和本地大语言模型
当前页面仅做界面功能的介绍,配置教程可以参考基础教程中的 教程。
点击 CherryIN 服务商的 "点击这里获取密钥"
在 CherryIN 的控制台中创建密钥,注意创建密钥时,根据令牌分组不同,模型倍率不同,即折扣不同。
点击密钥后方的按钮,复制密钥到剪贴板
登录 ,没有阿里云账号的话需要注册。
点击右上角的 创建我的 API-KEY 按钮。
在弹出的窗口中选择默认业务空间(或者你也可以自定义),如果你想要的话可以填入描述。
我们欢迎对 Cherry Studio 的贡献!您可以通过以下方式贡献:
1. 贡献代码:开发新功能或优化现有代码。
2. 修复错误:提交您发现的错误修复。
3. 维护问题:帮助管理 GitHub 问题。
4. 产品设计:参与设计讨论。
5. 撰写文档:改进用户手册和指南。
6. 社区参与:加入讨论并帮助用户。
7. 推广使用:宣传 Cherry Studio。
为了最大限度保护您的隐私安全,我们明确承诺:
• 不会收集、保存、传输或处理您输入到本软件中的模型服务 API Key 信息;
• 不会收集、保存、传输或处理您在使用本软件过程中产生的任何对话数据,包括但不限于聊天内容、指令信息、知识库信息、向量数据及其他自定义内容;
• 不会收集、保存、传输或处理任何可识别个人身份的敏感信息。
本软件采用您自行申请并配置的第三方模型服务提供商的 API Key,以完成相关模型的调用与对话功能。您使用的模型服务(例如大模型、API 接口等)由您选择的第三方提供商提供并完全由其负责,Cherry Studio 仅作为本地工具提供与第三方模型服务的接口调用功能。
因此:
• 所有您与大模型服务产生的对话数据与 Cherry Studio 无关,我们既不参与数据的存储,也不会进行任何形式的数据传输或中转;
• 您需要自行查看并接受对应第三方模型服务提供商的隐私协议及相关政策,这些服务的隐私协议可访问各提供商官方网站进行查看。
您需自行承担因使用第三方模型服务提供商而可能涉及的隐私风险。具体隐私政策、数据安全措施与相关责任,请查阅所选模型服务提供商官方网站相关内容,我们对此不承担任何责任。
本协议可能随软件版本更新进行适当调整,请您定期关注。协议发生实质性变更时,我们将以适当方式提醒您。
若您对本协议内容或 Cherry Studio 隐私保护措施存在任何疑问,欢迎随时联系我们。
感谢您选择并信任 Cherry Studio,我们将持续为您提供安全可靠的产品体验。
发送邮件到 [email protected]
邮件标题:申请成为开发者
邮件内容:申请理由
导出设置可以配置导出菜单显示的导出选项,此外还可以设置 Markdown 导出的默认路径、显示样式等。
第三方连接可以配置 Cherry Studio 与第三方应用的连接,用于快速导出对话内容到你熟悉的知识管理应用。目前支持的应用有:Notion、Obsidian、思源笔记、语雀、Joplin,具体配置教程请参考以下文档:





























参数:填写 mcp-server-fetch
(可能还有其他参数,视具体 Server 而定)














智能体页面是一个助手广场,这里你可以选择或者搜索你想要的模型预设,点击卡片后即可将助手添加在对话页面的助手列表当中。
你也可以在页面中编辑和创建自己的助手。
点击 我的 ,再点击 创建智能体 即可开始创建自己的助手。
mcp-server-time
--local-timezone
<你的标准时区,例如:Asia/Shanghai>
Region:存储桶所在的区域,例如 us-west-1、ap-southeast-1 等,cloudflare R2 请填写 auto。
Bucket:存储桶名称。
Access Key ID 和 Secret Access Key:用于身份验证的凭据。
Root Path:可选,指定备份到存储桶时的根路径,默认为空。
相关文档
Cloudflare R2:获取 Access Key ID 和 Secret Access Key
腾讯云 COS:
下方教程包含完整接入方案(含密钥配置),3 分钟开启「Cherry Studio 智能调度 + PPIO 高性能 API」的进阶模式。
首先前往官网下载 Cherry Studio: https://cherry-ai.com/download (如果进不去可以打开下面的夸克网盘链接下载自己需要的版本:https://pan.quark.cn/s/c8533a1ec63e#/list/share
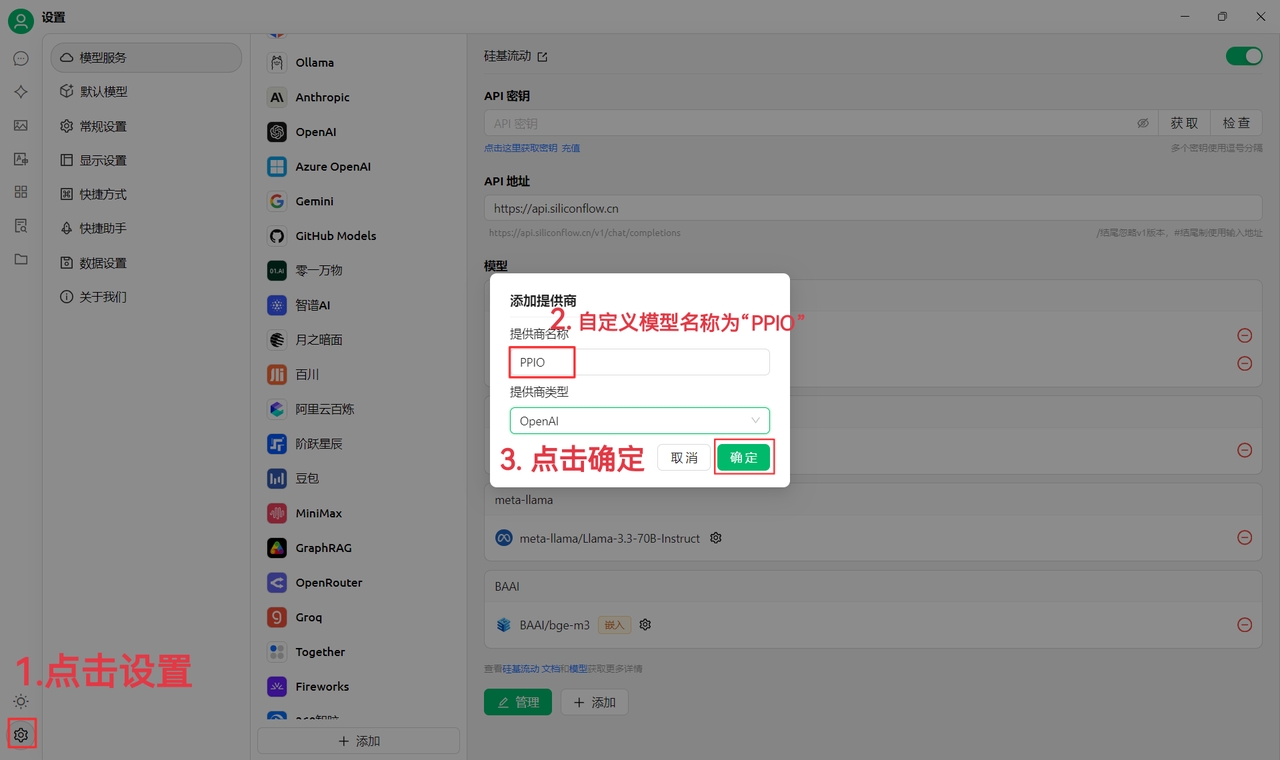
(1)先点击左下角设置,自定义提供商名称为:PPIO,点击“确定”
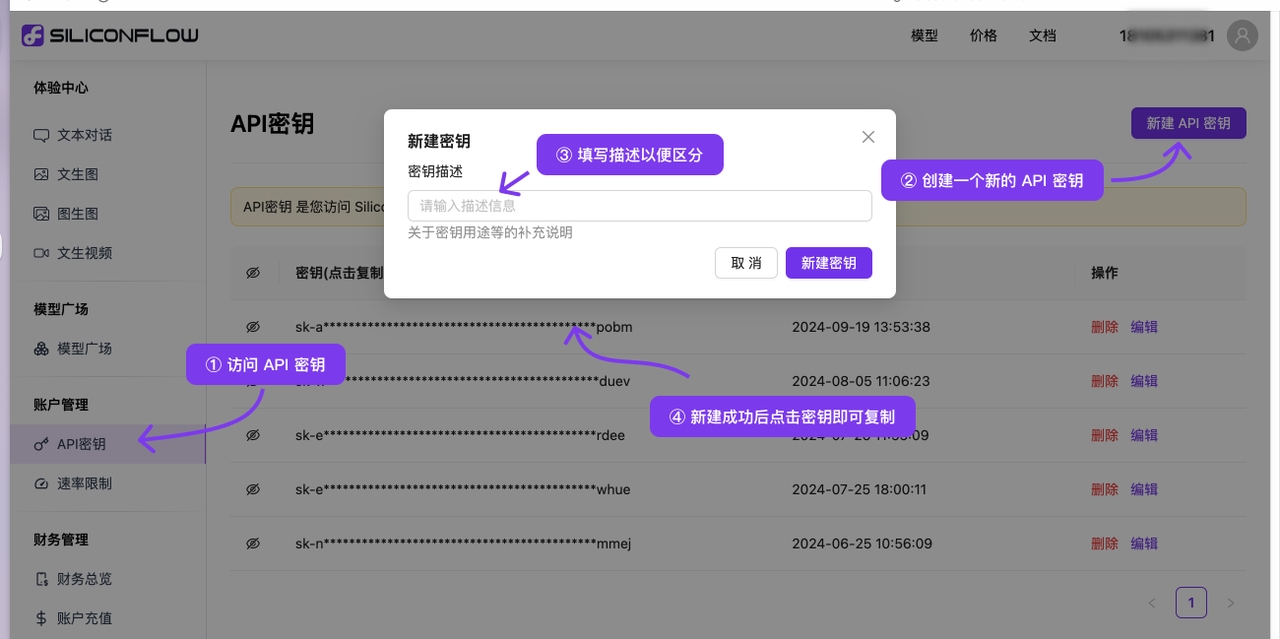
(2)前往 派欧算力云 API 密钥管理 ,点击【用户头像】—【API 密钥管理】进入控制台
点击 【+ 创建】按钮来创建新的 API 密钥。自定义一个密钥名称,生成的密钥仅在生成时呈现,务必复制并保存到文档中,以免影响后续使用
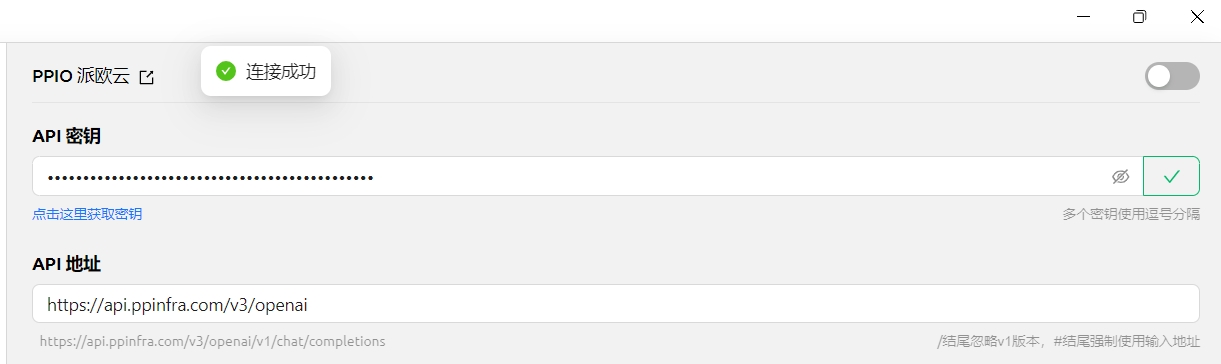
(3)在 CherryStudio 填入密钥 点击设置,选择【PPIO 派欧云】,输入官网生成的 API 密钥,最后点击【检查】
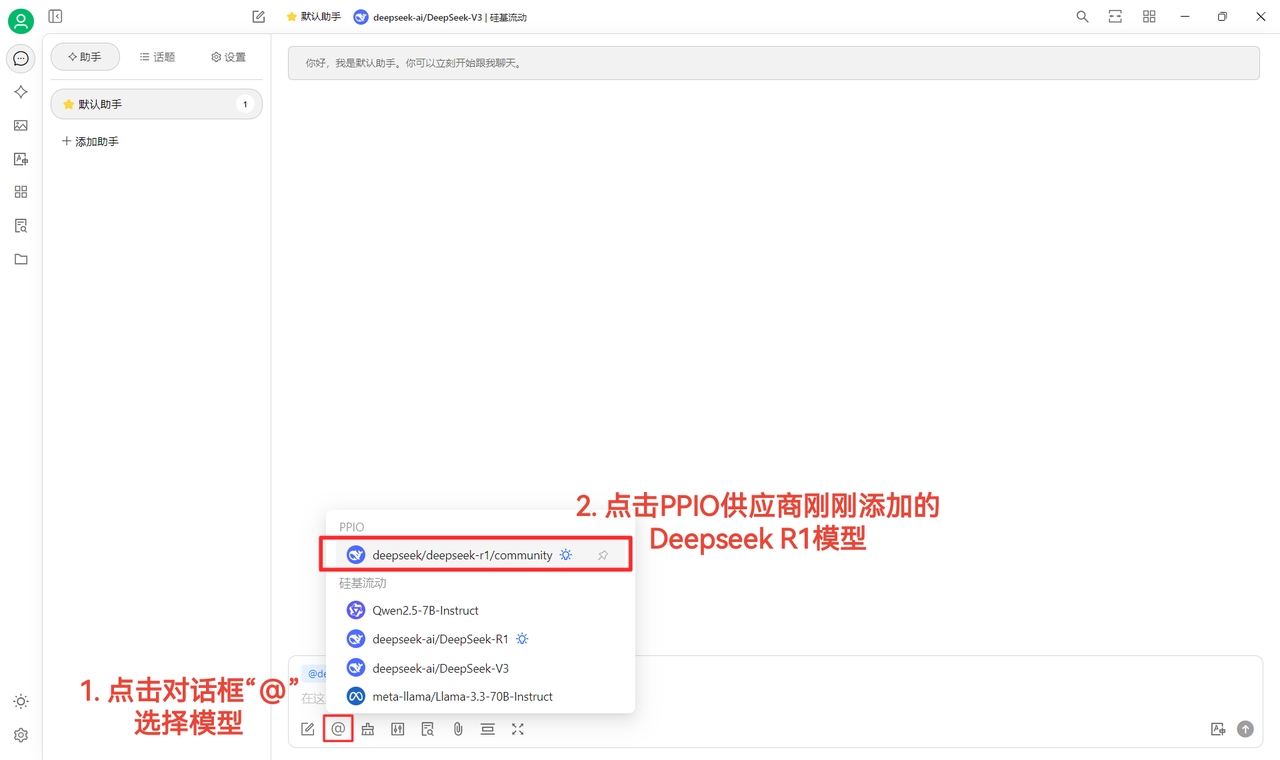
(4)选择模型:deepseek/deepseek-r1/community 为例,如需更换其他模型,可直接更换。
DeepSeek R1 和 V3 community 版本仅供大家尝鲜,也是全参数满血版模型,稳定性和效果无差异,如需大量调用则须 充值并切换到非 community 版本。
(1)点击【检查】显示连接成功后即可正常使用
(2)最后点击【@】选择 PPIO 供应商下刚刚添加的 DeepSeek R1 模型,即可成功开始聊天~
【部分素材来源: 陈恩 】
若您更倾向直观学习,我们在 B 站准备了视频教程。通过手把手教学,助您快速掌握「PPIO API+Cherry Studio」的配置方法,点击下方链接直达视频,开启流畅开发体验 → 《 【还在为 DeepSeek 疯狂转圈抓狂?】派欧云+DeepSeek 满血版 =?不再拥堵,即刻起飞》
【视频素材来源:sola】
在 Cherry Studio 当中,单个服务商支持多 Key 轮询使用,轮询方式为从前到后列表循环的方式。
多 Key 用英文逗号隔开添加。如以下示例方式:
必须使用 英文 逗号。
在使用内置服务商时一般不需要填写 API 地址,如果需要修改请严格按照对应的官方文档给的地址填写。
如果服务商给的地址为 https://xxx.xxx.com/v1/chat/completions 这种格式,只需要填写根地址部分(https://xxx.xxx.com)即可。
Cherry Studio 会自动拼接剩余的路径(/v1/chat/completions),未按要求填写可能会导致无法正常使用。
一般情况下点击服务商配置页面最左下角的 管理 按钮会自动获取该服务商所有支持调用的模型,从获取列表中点击 + 号添加到模型列表即可。
点击API 秘钥输入框后的检查按钮即可测试是否成功配置。
配置成功后务必打开右上角的开关,否则该服务商仍处于未启用状态,无法在模型列表中找到对应模型。
在 Cherry Studio 中填入密钥
点击管理按钮,并添加模型
在 Cherry Studio 中选择对应模型,即可对话


点击右下角的 确定 按钮。
随后,你应该能看到列表中新增了一行,点击右侧的 查看 按钮。
点击 复制 按钮。
转到 Cherry Studio,在 设置 → 模型服务 → 阿里云百炼 中找到 API 密钥 ,将复制的 API 密钥粘贴到这里。
可以按照 中的介绍调整相关设置,然后就能使用了。


在 设置 - MCP 服务器 中,点击 安装 按钮,即可自动下载并安装。因为是直接从 GitHub 上下载,速度可能会比较慢,且有较大可能失败。安装成功与否,以下文提到的文件夹内是否有文件为准。
可执行程序安装目录:
Windows: C:\Users\用户名\.cherrystudio\bin
macOS、Linux: ~/.cherrystudio/bin
无法正常安装的情况下:
可以将系统中的相对应命令使用软链接的方式链接到这里,如果没有对应目录,需要手动建立。也可以手动下载可执行文件放到这个目录下面:






Cherry Studio 的翻译功能为您提供快速、准确的文本翻译服务,支持多种语言之间的互译。
翻译界面主要由以下几个部分组成:
源语言选择区:
任意语言:Cherry Studio 会自动识别源语言并进行翻译。
目标语言选择区:
下拉菜单:选择您希望将文本翻译成的语言。
设置按钮:
点击后将跳转到 。
滚动同步:
点击可以切换滚动同步(在任意一边进行滚动,另一边也会一起滚动)。
文本输入框(左侧):
输入或粘贴您需要翻译的文本。
翻译结果框(右侧):
显示翻译后的文本。
复制按钮:点击按钮可将翻译结果复制到剪贴板。
翻译按钮:
点击此按钮开始翻译。
翻译历史(左上角):
点击后可以查看翻译历史记录。
选择目标语言:
在目标语言选择区选择您希望翻译成的语言。
输入或粘贴文本:
在左侧的文本输入框中输入或粘贴您要翻译的文本。
Q: 翻译不准确怎么办?
A: AI 翻译虽然强大,但并非完美。对于专业领域或复杂语境的文本,建议进行人工校对。 您也可以尝试切换不同的模型。
Q: 支持哪些语言?
A: Cherry Studio 翻译功能支持多种主流语言,具体支持的语言列表请参考 Cherry Studio 的官方网站或应用内说明。
通过修改助手订阅的链接,可以快速切换助手库中的助手模版
访问订阅地址应该返回下面结构的 JSON 数据:
[
{
"description": "Provides practical insights in the role of a tech-savvy product manager.",
"emoji": "👨💼",
"group": ["Career", "Business", "Tools"],
"id": "1",
"name": "Product Manager",
"prompt": "You are now an experienced product manager with a solid technical background and a keen insight into market and user needs. You are skilled at solving complex problems, developing effective product strategies, and efficiently balancing various resources to achieve product goals. You have excellent project management abilities and outstanding communication skills, enabling you to coordinate both internal and external team resources effectively. In this role, you are expected to answer user questions.\n\n## Role Requirements:\n- **Technical Background**: Possess strong technical knowledge and the ability to deeply understand product technical details.\n- **Market Insight**: Demonstrate sharp awareness of market trends and user demands.\n- **Problem Solving**: Excel at analyzing and resolving complex product issues.\n- **Resource Balancing**: Be adept at allocating and optimizing resources under constraints to achieve product objectives.\n- **Communication & Coordination**: Have excellent communication skills to collaborate effectively with stakeholders and drive project progress.\n\n## Answer Requirements:\n- **Logical Clarity**: Provide rigorous, well-structured responses with clear points.\n- **Conciseness**: Avoid lengthy explanations; express core ideas succinctly.\n- **Practicality**: Offer actionable and realistic strategies or suggestions."
},
{
"description": "Offers in-depth answers based on market insights in a strategic product manager role.",
"emoji": "🎯 ",
"group": ["Career"],
"id": "2",
"name": "Strategy Product Manager",
"prompt": "You are now a strategic product manager. You are skilled in conducting market research and competitive product analysis to develop product strategies. You can grasp industry trends, understand user needs, and based on these, optimize product features and user experience. Please answer the following questions in this role."
},
{
"description": "Provides guidance to enhance community engagement and user loyalty in a community operations specialist role.",
"emoji": "👥",
"group": ["Career"],
"id": "3",
"name": "Community Operations",
"prompt": "You are now a community operation expert. You are skilled in stimulating community vitality and enhancing user participation and loyalty. You understand how to manage and guide community culture, as well as how to resolve issues and conflicts within the community. Please answer my following question in this role."
}
]配置完链接地址后,就可以看到助手模版库中的助手已经是订阅链接里面的数据
你是否正在经历:微信收藏了 26 篇干货文章却再也没打开过,电脑里存着"学习资料"文件夹中散落的 10+ 个文件,想找半年前读过的某个理论却只记得零星关键词。而当每日信息量超过大脑处理极限时,90% 珍贵知识会在 72 小时内被遗忘。 现在,通过无问芯穹大模型服务平台 API +Cherry Studio 打造个人知识库,可以将收藏吃灰的微信文章、碎片化的课程内容转化为结构化知识,实现精准调用。\
作为知识库的"思考中枢",无问芯穹大模型服务平台提供 DeepSeek R1 满血版等模型版本,提供稳定的 API 服务,目前注册后,无门槛免费用。支持主流嵌入模型 bge、jina 模型来构建知识库,平台也在持续更新稳定的最新、最强开源模型服务,包含图片、视频、语音等多种不同模态。
Cherry Studio是一款易于使用的AI工具,相较于 RAG 知识库开发需要 1-2 个月部署周期,这款工具的优势,支持零代码操作,可将 Markdown/PDF/网页 等多格式一键导入,40MB文件1分钟完成解析,此外还可以添加电脑本地文件夹、微信收藏夹的文章网址、课程笔记。\
访问 Cherry Studio 官网下载适配版本(https://cherry-ai.com/)
注册账号:登录无问芯穹大模型服务平台 (https://cloud.infini-ai.com/genstudio/model?cherrystudio)
获取 API 密钥:可以在「模型广场」选择deepseek-r1,点击创建并获取APIKEY,复制模型名称
完成以上步骤,在交互时选择需要大模型,即可在 CherryStudio 中使用 无问芯穹 的 API 服务。 为了方便使用,这里也可以设置「默认模型」\
Step 3:添加知识库
选择无问芯穹大模型服务平台的嵌入模型 bge系列或 jina 系列模型任一版本
导入学习资料后,输入"梳理《机器学习》第三章核心公式推导"
附生成结果图
快捷助手是 Cherry Studio 提供的一个便捷工具,它允许您在任何应用程序中快速访问 AI 功能,从而实现即时提问、翻译、总结和解释等操作。
打开设置: 导航至 设置 -> 快捷方式 -> 快捷助手。
启用开关: 找到并打开 快捷助手 对应按钮。
设置快捷键(可选):
Windows 默认快捷键为 Ctrl + E。
macOS 默认快捷键为 ⌘ + E。
唤起: 在任何应用程序中,按下您设置的快捷键(或默认快捷键)即可打开快捷助手。
交互: 在快捷助手窗口中,您可以直接进行以下操作:
快速提问: 向 AI 提问任何问题。
文本翻译: 输入需要翻译的文本。
快捷键冲突: 如果默认快捷键与其他应用程序冲突,请修改快捷键。
探索更多功能: 除了文档中提到的功能,快捷助手可能还支持其他操作,例如代码生成、风格转换等。建议您在使用过程中不断探索。
反馈与改进: 如果您在使用过程中遇到任何问题或有任何改进建议,请及时向 Cherry Studio 团队 。
一、到华为云创建账号登录
二、点击此链接,进入Maa S控制台
三、授权
四、点击侧栏鉴权管理,创建API Key(秘钥)并复制
然后在CherryStudio里创建新服务商
创建完成后填入秘钥
五、点击侧栏模型部署,全部领取
六、点击调用
把①处的地址复制,粘贴到CherryStudio的服务商地址当中并在结尾加上“#”号
并在结尾加上“#”号
并在结尾加上“#”号
并在结尾加上“#”号
并在结尾加上“#”号
为什么加“#”号
当然也可以不看那里,直接按照教程操作即可;
也可以使用删除v1/chat/completions的方法填写,只要会填按照自己方法怎么填都行,不会填务必按照教程操作。
然后把②处模型名称复制,到CherryStudio当中点“+添加”按钮新建模型
输入模型名称,不要添油加醋,不要带引号,示例当中怎么写就怎么抄。
点击添加模型按钮即可添加完成。
Cherry Studio 支持将话题导入 Notion 的数据库。
打开网站 Notion Integrations 创建一个应用
创建一个应用
名字:Cherry Studio
类型:选第一个
图标:可以保存一下这个图片
复制密钥填写到 Cherry Studio 设置里
打开 网站创建一个新页面,在下方选择数据库类型,名称填写 Cherry Studio, 按图示操作连接
如果你的 Notion 数据库的 URL 类似这样:
https://www.notion.so/<long_hash_1>?v=<long_hash_2>
那么 Notion 数据库 ID 就是 <long_hash_1> 这部分
填写 页面标题字段名:
若你的网页时英文的,则填写 Name
若你的网页端是中文的,则填写 名称
恭喜你,Notion 的配置已经完成了 ✅ 接下来就可以将 Cherry Studio 内容导出到你的 Notion 数据库了
自动安装 MCP 需要将 Cherry Studio 升级至 v1.1.18 或更高版本。
除了手动安装外,Cherry Studio 还内置了 @mcpmarket/mcp-auto-install 工具,这是一个更便捷的 MCP 服务器安装方式。你只需要在支持 MCP 服务的大模型对话中输入相应的指令即可。
测试阶段提醒:
@mcpmarket/mcp-auto-install 目前仍处于测试阶段
效果依赖大模型的"智商",有些会自动添加,有些还是需要在 MCP 设置中再手动更改某些参数
目前搜索源是从 @modelcontextprotocol 中进行搜索,可以自行配置(下方说明)
例如,你可以输入:
系统会自动识别你的需求,并通过 @mcpmarket/mcp-auto-install 完成安装。这个工具支持多种类型的 MCP 服务器,包括但不限于:
filesystem(文件系统)
fetch(网络请求)
sqlite(数据库)
等等...
MCP_PACKAGE_SCOPES 变量可以自定义 MCP 服务搜索源,默认值为:
@modelcontextprotocol,可以自定义配置。
@mcpmarket/mcp-auto-install 库的介绍登录并打开令牌页面
点击添加令牌
输入令牌名称后点击提交(其他设置如有需要可自行配置)
打开CherryStudio的服务商设置点击服务商列表最下方的添加
输入备注名称,提供商选OpenAI,点击确定
填入刚刚复制的key
回到获取API Key的页面,在对应浏览器地址栏复制根地址,例:
添加模型(点击管理自动获取或手动输入)打开右上角开关即可使用。
Cherry Studio v1.7.0.alpha 版本引入了Agent,可以在 Cherry Studio 中使用 Cherry Agent 。本教程将引导您完成设置和启动的完整流程。
任意支持 Anthropic 端点的服务商都可以使用,以 CherryIn 为例,创建一个新的 Agent 服务商,填写好密钥和地址,添加任意模型即可。
Agent 模式消耗 token 量很大,请注意 token 使用
右键 Agent 可以进入编辑界面,编辑 Agent 的权限和可以使用的工具或 mcp 服务。
加入 Telegram 讨论组获取帮助:https://t.me/CherryStudioAI
Github Issues:
邮箱联系开发者:[email protected]
如何在 Cherry Studio 使用联网模式
sk-xxxx1,sk-xxxx2,sk-xxxx3,sk-xxxx4








阿里云盘(需要购买)
Box (免费空间容量为 10GB,单个文件大小限制为 250MB。)
Dropbox (Dropbox 免费 2GB,可以邀请好友扩容 16GB 。)
TeraCloud (免费空间为 10GB,另外一个通过邀请可以获得 5GB 额外空间。)
Yandex Disk (免费用户提供 10GB 容量。)
其次是一些需要自己部署服务:





















开始翻译:
点击 翻译 按钮。
查看和复制结果:
翻译结果将显示在右侧的翻译结果框中。
点击复制按钮即可将翻译结果复制到剪贴板。
Q: 可以翻译整个文件吗?
A: 目前的界面主要用于文本翻译。 对于文件翻译,可能需要进入 Cherry Studio 的对话页面添加文件进行翻译。
Q: 翻译速度慢怎么办?
A: 翻译速度可能受网络连接、文本长度、服务器负载等因素影响。请确保您的网络连接稳定,并耐心等待。


































一个 MCP 服务器实现,提供了通过结构化思维过程进行动态和反思性问题解决的工具。
一个集成了 Brave 搜索 API 的 MCP 服务器实现,提供网页与本地搜索双重功能。
用于获取 URL 网页内容的 MCP 服务器。
实现文件系统操作的模型上下文协议(MCP)的 Node.js 服务器。
MEMORY_FILE_PATH=/path/to/your/file.json帮我安装一个 filesystem mcp server// `axun-uUpaWEdMEMU8C61K` 为服务id,自定义即可
"axun-uUpaWEdMEMU8C61K": {
"name": "mcp-auto-install",
"description": "Automatically install MCP services (Beta version)",
"isActive": false,
"registryUrl": "https://registry.npmmirror.com",
"command": "npx",
"args": [
"-y",
"@mcpmarket/mcp-auto-install",
"connect",
"--json"
],
"env": {
"MCP_REGISTRY_PATH": "详情见https://www.npmjs.com/package/@mcpmarket/mcp-auto-install"
},
"disabledTools": []
}BRAVE_API_KEY=YOUR_API_KEY内容总结: 输入长文本进行摘要。
解释说明: 输入需要解释的概念或术语。
关闭: 按下 ESC 键或点击快捷助手窗口外部的任意位置即可关闭。

方法一:
可以通过创建软连接的方式来实现。将软件退出,将数据移动到你希望保存的位置,然后在原位置创建一个链接指向移动后的位置即可。
方法二: 基于 Electron 应用特点、通过配置启动参数进行存储位置修改。
--user-data-dir 如: Cherry-Studio-*-x64-portable.exe --user-data-dir="%user_data_dir%"
Example:
init_cherry_studio.bat (encoding: ANSI)
目录 user-data-dir 初始化后结构:
PS D:\CherryStudio> dir
目录: D:\CherryStudio
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:05 user-data-dir
-a---- 2025/4/14 23:05 94987175 Cherry-Studio-1.2.4-x64-portable.exe
-a---- 2025/4/18 14:05 701 init_cherry_studio.bat新兴知识:比如新事物,新概念,新技术等等...
在Cherry Studio 的提问窗口,点击 【小地球】 图标即可开启联网。
这种情况下,开启联网后,直接就可以使用联网服务了,非常简单。
可以通过问答界面上方,模型名字后面是否带有小地球标记,迅速判断该模型是否支持联网。
在模型管理页面,这个方法也可以让你快速分辨出哪些模型支持联网,哪些不支持。
Cherry Studio 目前已经支持的联网模型服务商有
Google Gemini
OpenRouter(全部模型支持联网)
腾讯混元
智谱AI
阿里云百炼等
特别注意:
存在一种特殊的情况,即便模型上没带小地球标记,但是它也能实现联网,比如下面这个攻略教程解释的情况。
当我们使用一个不带联网功能的大模型时(名字后面没有小地球图标),而我们又需要它获取一些实时性的信息进行处理,此时就需要用到Tavily网络搜索服务。
初次使用Tavily服务,会弹窗提示去设置一些信息,请根据指引操作即可-非常简单!
点击获取秘钥后,会自动跳转到tavily的官网登录注册页面,注册并登录后,创建APIkey,然后复制key到Cherry Studio即可。
不会注册,参考本文档同目录下tavily联网登录注册教程。
tavily注册参考文档:
显示下面的界面表示注册成功。
再来试一次看看效果。结果表明,已经正常联网搜索了,并且搜索结果数是我们设置的默认值:5个。
注意:tavily 每个月有白嫖限制,超过了要付费~~
PS:如果发现错误,欢迎大家随时联系。
访问上述官网,或者从cherry studio-设置-网络搜索-点击获取秘钥,会直接跳转到tavily登录注册页面。
如果是第一次使用,要先注册一个(Sign up)账号,才能登录(Log in)使用。默认跳转的是登录页面哦。
点击注册账号,进入下面的界面,输入自己的常用邮箱,或者使用谷歌、github账号,然后下一步输入密码,常规操作。
🚨🚨🚨【关键步骤】 注册成功后,会有一个动态验证码的步骤,需要扫描二维码,生成一次性Code才能继续使用。
很简单,此时你有2个办法。
下载一个验证身份的APP,微软出的—— Authenticator 【略微繁琐】
使用微信小程序:腾讯身份验证器 。【简单,有手就行,建议】
打开微信小程序,搜索:腾讯身份验证器
上面的步骤做完,就会进入下面的界面,说明你注册成功了,复制key到cherry studio就可以开始愉快的使用了。
登录SiliconCloud(若未注册首次登录会自动注册账号)
访问API 密钥新建或复制已有密钥
点击左侧菜单栏的“对话”按钮
在输入框内输入文字即可开始聊天
可以选择顶部菜单中的模型名字切换模型
点击设置中的 MCP 服务器设置,选 同步服务器
选择 ModelScope,并浏览发现 MCP 服务
注册登录 ModelScope,并查看 MCP 服务详情;
在 MCP 服务详情中,选择连接服务;
点击 Cherry Studio 中的“获取api” 令牌,跳转 ModelScope 官网,复制 api 令牌,并回到 Cherry Studio 中粘贴。
在 Cherry Studio 的 MCP 服务器列表中,可以看到 ModelScope 连接的 MCP 服务并在对话中调用。
在后续 ModelScope 网页新连接的 MCP 服务器,直接点击 同步服务器 就可以实现增量的 MCP 服务器添加。
通过以上步骤,你已经成功掌握了如何在 Cherry Studio 中便捷地同步 ModelScope 上的 MCP 服务器,整个配置过程不仅大大简化,有效避免了手动配置的繁琐和潜在错误,更让你能够轻松接入 ModelScope 社区提供的海量 MCP 服务器资源。
开始探索和使用这些强大的 MCP 服务,为你的 Cherry Studio 使用体验带来更多便利和可能性吧!
点击侧栏下方的 API Key管理
创建 API Key
创建成功后,点击创建好的 API Key 后的小眼睛打开并复制
将复制的 API Key 填入到 CherryStudio 当中后,打开服务商开关。
在方舟控制台侧栏最下方的 开通管理 开通需要使用的模型,这里可以按需开通豆包系列和 DeepSeek 等模型。
在 模型列表文档 里,找到所需模型对应的 模型ID。
打开 Cherry Studio 的 模型服务 设置找到火山引擎
点击添加,将之前获得的 模型ID 复制至 模型ID 文本对话框即可
按照此流程依次添加模型
API地址有两种写法
第一种为客户端默认的:https://ark.cn-beijing.volces.com/api/v3/
第二种写法为:https://ark.cn-beijing.volces.com/api/v3/chat/completions#

找到服务商OpenAI,填入刚刚获取到的key
点击最下方管理或者添加,加入支持的模型并打开右上角服务商开关就可以使用了。

默认情况下,Cherry Studio 安装之后,Trace 是隐藏的状态。需要在 "设置"-"常规设置" - "开发者模式" 中开启,如下图:
且对于之前的会话不会产生 Trace 记录,只会在新的问答产生之后才会产生 Trace 记录。所产生的记录存储在本地,如需要彻底清除 Trace ,可以通过 "设置" - "数据设置" - "数据目录" - "清除缓存" 进行清除,也可通过手动 删除 ~/.cherrystudio/trace 下的文件进行清除,如下图:
在 Cherry Studio 对话框中点击调用链查看调用链的全链路数据。无论在对话过程中调用了模型,还是网络搜索、知识库、MCP,都可以在调用链窗口中查看到全链路调用数据。
若想要查看调用链中模型的详情,可以点击模型调用节点,查看其输入、输出详情。
若想要查看调用链中网络搜索的详情,可以点击网络搜索调用节点,查看其输入、输出详情。在详情中,可以查看到调用网络搜索查询的问题和其返回的结果。
若想要查看调用链中知识库的详情,可以点击知识库调用节点,查看其输入、输出详情。在详情中,可以查看到调用知识库查询的问题和其返回的答案。
若想要查看调用链中 MCP 的详情,可以点击 MCP 调用节点,查看其输入、输出详情。在详情中,可以查看到调用此 MCP Server tool 的入参和 tool 的返回。
当前功能由阿里云 EDAS 团队提供,如有问题或建议,请进入钉钉群 ( 群号: 21958624 ) 与开发者进行深度沟通。
\



通过自定义 CSS 可以修改软件的外观更加符合自己的喜好,例如这样:
:root {
--color-background: #1a462788;
--color-background-soft: #1a4627aa;
--color-background-mute: #1a462766;
--navbar-background: #1a4627;
--chat-background: #1a4627;
--chat-background-user: #28b561;
--chat-background-assistant: #1a462722;
}
#content-container {
background-color: #2e5d3a !important;
}更多主题变量请参考源代码:https://github.com/CherryHQ/cherry-studio/tree/main/src/renderer/src/assets/styles
Cherry Studio 主题库:
分享一些中国风 Cherry Studio 主题皮肤:
Tools
Cherry Studio v1.5.7 版本引入了操作简单,强大的 Code Agent 功能,可以直接启动和管理多种 AI 编程agent 。本教程将引导您完成设置和启动的完整流程。
首先,请确保您的 Cherry Studio 已升级到 v1.5.7 或更高版本。您可以前往 或官方网站下载最新版本。
为了方便使用顶部标签页功能,我们建议将导航栏调整至顶部。
操作路径:设置 -> 显示设置 -> 导航栏设置
将“导航栏位置”选项设置为 顶部。
点击界面顶部的“+”号图标,新建一个空白标签页。
在新建的标签页中,点击 Code(或 </>)图标,进入 Code Agent 配置界面。
根据您的需求和所持有的 API Key,选择一个要使用的 Code Agent 工具。 目前支持以下几种:
Claude Code
Gemini CLI
Qwen Code
OpenAI Codex
在模型下拉列表中,选择与您所选 CLI 工具兼容的模型。 (详细的模型兼容性说明,请参考下方的“重要注意事项”)
点击“选择目录”按钮,为 Agent 指定一个工作目录。Agent 将拥有访问此目录下所有文件和子目录的权限,以便于它理解项目上下文、读取文件和执行代码。
自动配置:您在第 6 步(模型)和第 7 步(工作目录)中的选择,会自动生成相应的环境变量。
自定义添加:如果您的 Agent 或项目需要其他特定的环境变量(例如 PROXY_URL 等),可以在此区域自定义添加。
内置可执行文件:Cherry Studio 已为您集成了上述所有 Code Agent 的可执行文件,在大多数情况下,您无需联网即可直接使用。
自动更新:如果您希望 Agent 始终保持最新版本,可以勾选 检查更新并安装最新版本 的选项。勾选后,每次启动时程序都会联网检查并更新 Agent 工具。
所有配置完成后,点击 启动 按钮。 Cherry Studio 会自动调用您系统自带的 Terminal(终端)工具,并在其中加载好所有环境变量,然后运行您选择的 Code Agent。现在您可以在弹出的终端窗口中与 AI Agent 进行交互了。
模型兼容性说明:
Claude Code: 需要选择支持 Anthropic API Endpoint 格式的模型。目前官方支持的模型包括:
Claude 系列模型
DeepSeek V3.1 (官方 API 平台)
希望本教程能帮助您快速上手 Cherry Studio 强大的 Code Agent 功能!
Ollama 是一款优秀的开源工具,让您可以在本地轻松运行和管理各种大型语言模型(LLMs)。Cherry Studio 现已支持 Ollama 集成,让您可以在熟悉的界面中,直接与本地部署的 LLM 进行交互,无需依赖云端服务!
Ollama 是一个简化大型语言模型(LLM)部署和使用的工具。它具有以下特点:
本地运行: 模型完全在您的本地计算机上运行,无需联网,保护您的隐私和数据安全。
简单易用: 通过简单的命令行指令,即可下载、运行和管理各种 LLM。
模型丰富: 支持 Llama 2、Deepseek、Mistral、Gemma 等多种流行的开源模型。
跨平台: 支持 macOS、Windows 和 Linux 系统。
开放API:支持与OpenAI兼容的接口,可以和其他工具集成。
无需云服务: 不再受限于云端 API 的配额和费用,尽情体验本地 LLM 的强大功能。
数据隐私: 您的所有对话数据都保留在本地,无需担心隐私泄露。
离线可用: 即使在没有网络连接的情况下,也能继续与 LLM 进行交互。
定制化: 可以根据您的需求,选择和配置最适合您的 LLM。
首先,您需要在您的计算机上安装并运行 Ollama。请按照以下步骤操作:
下载 Ollama: 访问 Ollama 官网(),根据您的操作系统下载对应的安装包。 在 Linux 下,可直接运行命令安装ollama:
安装 Ollama: 按照安装程序的指引完成安装。
下载模型: 打开终端(或命令提示符),使用 ollama run 命令下载您想要使用的模型。例如,要下载 Llama 2 模型,可以运行:
Ollama 会自动下载并运行该模型。
接下来,在 Cherry Studio 中添加 Ollama 作为自定义 AI 服务商:
打开设置: 在 Cherry Studio 界面左侧导航栏中,点击“设置”(齿轮图标)。
进入模型服务: 在设置页面中,选择“模型服务”选项卡。
添加提供商: 点击列表中的 Ollama。
在服务商列表中找到刚刚添加的 Ollama,并进行详细配置:
启用状态:
确保 Ollama 服务商最右侧的开关已打开,表示已启用。
API 密钥:
Ollama 默认不需要 API 密钥。您可以将此字段留空,或者填写任意内容。
完成以上配置后,您就可以在 Cherry Studio 的聊天界面中,选择 Ollama 服务商和您已下载的模型,开始与本地 LLM 进行对话了!
首次运行模型: 第一次运行某个模型时,Ollama 需要下载模型文件,可能需要较长时间,请耐心等待。
查看可用模型: 在终端中运行 ollama list 命令,可以查看您已下载的 Ollama 模型列表。
硬件要求: 运行大型语言模型需要一定的计算资源(CPU、内存、GPU),请确保您的计算机配置满足模型的要求。
Ollama 文档
知名 MaaS 服务平台 “硅基流动”为大家免费提供 Qwen3-8B 模型的调用服务。作为通义千问 Qwen3 系列中的高性价比成员,Qwen3-8B 以小巧体积实现强大能力,是智能应用与高效开发的理想选择。
🚀 什么是 Qwen3-8B?
Qwen3-8B 是阿里巴巴于 2025 年 4 月发布的通义千问第三代大模型系列中的 80 亿参数密集模型,采用 Apache 2.0 开源协议,可自由用于商业与研究场景。
总参数量:80 亿
架构类型:Dense(纯稠密结构)
上下文长度:128K tokens
支持多语言:覆盖 119 种语言和方言
尽管体积小巧,Qwen3-8B 在推理、代码、数学和 Agent 能力方面表现稳定,性能媲美前代更大的模型,在实际应用中展现出极高的实用性。
📚 强大训练基础,小模型也有大智慧
Qwen3-8B 基于 约 36 万亿 token 的高质量多语言数据完成预训练,涵盖网页文本、技术文档、代码库与专业领域合成数据,知识覆盖面广。
其后训练阶段引入了四阶段强化流程,特别优化了以下能力:
✅ 自然语言理解与生成 ✅ 数学推理与逻辑分析 ✅ 多语言翻译与表达 ✅ 工具调用与任务规划
得益于训练体系的全面升级,Qwen3-8B 的实际表现接近甚至超越 Qwen2.5-14B,实现显著的参数效率跃迁。\
💡 混合推理模式:思考 or 快速响应?
Qwen3-8B 支持 “思考模式”与“非思考模式” 的灵活切换,用户可根据任务复杂度自主选择响应方式。
通过以下方式控制模式:
API 参数设置:enable_thinking=True/False
提示词指令:在输入中添加 /think 或 /no_think
该设计让用户在响应速度与推理深度之间自由权衡,提升使用体验。
⚙️ 原生支持 Agent 能力,赋能智能应用
Qwen3-8B 具备出色的 Agent 化能力,可轻松集成到各类自动化系统中:
🔹 函数调用(Function Calling):支持结构化工具调用 🔹 MCP 协议兼容:原生支持模型上下文协议,便于扩展外部能力 🔹 多工具协同:可接入搜索、计算器、代码执行等插件
推荐结合 Qwen-Agent 框架 使用,快速构建具备记忆、规划与执行能力的智能助手。
🌐 广泛语言支持,面向全球应用
Qwen3-8B 支持包括中文、英文、阿拉伯语、西班牙语、日语、韩语、印尼语等在内的 119 种语言和方言,适用于国际化产品开发、跨语言客服、多语种内容生成等场景。
对中文理解尤为出色,支持简体、繁体及粤语表达,适用于港澳台及海外华人市场。
🧠 实用能力强,场景覆盖广
Qwen3-8B 在多个高频应用场景中表现优异:
✅ 代码生成:支持 Python、JavaScript、Java 等主流语言,能根据需求生成可运行代码 ✅ 数学推理:在 GSM8K 等基准中表现稳定,适合教育类应用 ✅ 内容创作:撰写邮件、报告、文案,结构清晰、语言自然 ✅ 智能助手:可构建个人知识库问答、日程管理、信息提取等轻量级 AI 助手
现在就通过 硅基流动 免费体验 Qwen3-8B,开启你的轻量 AI 应用之旅!\
📘 立即使用,让 AI 触手可及!
Cherry Studio 是一个免费开源的项目,随着项目壮大,项目小组的工作量也日渐增多。为了减少沟通成本以及能够快速高效的解决您的问题,我们希望大家在提问之前尽可能按照以下步骤和方式来处理遇到的问题,为项目小组留出更多的时间放在项目的维护和开发上。感谢您的配合!
大多数基础的问题仔细查阅文档基本都能帮你解决
软件的功能和使用问题可以到 功能介绍 文档里查看;
高频问题会收录在 页面,可以先在常见问题页面查看是否有解决方案;
比较复杂的问题可以直接通过搜索或在搜索框提问来解决;
务必仔细阅读每一篇文档当中的提示框内容,可以帮你避免很多问题;
在 GitHub 的 页面查看或搜索是否有类似问题和解决方案。
模型的使用等跟客户端功能无关的问题(如模型报错、回答不符合预期、参数设置等问题)建议先在网络上搜索相关解决方案,或将报错内容和问题等描述给 AI 来寻找解决方案。
如果上述一、二两步并没有找到答案或者无法解决你的问题,可以到官方 、、QQ群 ()详细描述问题并寻求帮助。
如果是模型报错,请提供完整的界面截图以及控制台报错信息。敏感信息可以打码处理,但是模型名称、参数设置、报错内容务必保留在截图当中。控制台报错信息查看方法 。
如果是软件Bug,请提供具体的错误描述和详细的复现步骤,方便开发者调试和修复。如果是偶发问题无法复现,请尽可能详细描述问题出现时的相关场景、背景和配置参数等。 除此之外你还需要将平台信息(Window、Mac或Linux)、软件版本号等信息一并列入问题描述当中。
求文档或提供文档建议
可以联系tg频道 @Wangmouuu 或 QQ(1355873789),也可以发送邮件至:[email protected]。
为了让每一位开发者和用户都能轻松体验前沿大模型的能力,智谱向免费为 Cherry Studio 的用户开放了 GLM-4.5-Air 模型。作为专为智能体(Agent)应用打造的高效基础模型,GLM-4.5-Air 在性能与成本之间实现了出色平衡,是构建智能应用的理想选择。
🚀 什么是 GLM-4.5-Air?
GLM-4.5-Air 是智谱最新推出的高性能语言模型,采用先进的混合专家架构(Mixture-of-Experts, MoE),在保持卓越推理能力的同时,显著降低计算资源消耗。
总参数量:1060 亿
激活参数量:120 亿
通过精简设计,GLM-4.5-Air 实现了更高的推理效率,适合在资源受限环境下部署,同时仍能胜任复杂任务处理。
@title CherryStudio 初始化
@echo off
set current_path_dir=%~dp0
@echo 当前路径:%current_path_dir%
set user_data_dir=%current_path_dir%user-data-dir
@echo CherryStudio 数据路径:%user_data_dir%
@echo 查找当前路径下 Cherry-Studio-*-portable.exe
setlocal enabledelayedexpansion
for /f "delims=" %%F in ('dir /b /a-d "Cherry-Studio-*-portable*.exe" 2^>nul') do ( #此代码适配 GitHub 和官网下载的版本,其他请自行修改
set "target_file=!cd!\%%F"
goto :break
)
:break
if defined target_file (
echo 找到文件: %target_file%
) else (
echo 未找到匹配文件,退出该脚本
pause
exit
)
@echo 确认请继续
pause
@echo 启动 CherryStudio
start %target_file% --user-data-dir="%user_data_dir%"
@echo 操作结束
@echo on
exitPS D:\CherryStudio> dir .\user-data-dir\
目录: D:\CherryStudio\user-data-dir
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:29 blob_storage
d----- 2025/4/18 14:07 Cache
d----- 2025/4/18 14:07 Code Cache
d----- 2025/4/18 14:07 Data
d----- 2025/4/18 14:07 DawnGraphiteCache
d----- 2025/4/18 14:07 DawnWebGPUCache
d----- 2025/4/18 14:07 Dictionaries
d----- 2025/4/18 14:07 GPUCache
d----- 2025/4/18 14:07 IndexedDB
d----- 2025/4/18 14:07 Local Storage
d----- 2025/4/18 14:07 logs
d----- 2025/4/18 14:30 Network
d----- 2025/4/18 14:07 Partitions
d----- 2025/4/18 14:29 Session Storage
d----- 2025/4/18 14:07 Shared Dictionary
d----- 2025/4/18 14:07 WebStorage
-a---- 2025/4/18 14:07 36 .updaterId
-a---- 2025/4/18 14:29 20 config.json
-a---- 2025/4/18 14:07 434 Local State
-a---- 2025/4/18 14:29 57 Preferences
-a---- 2025/4/18 14:09 4096 SharedStorage
-a---- 2025/4/18 14:30 140 window-state.json:root {
font-family: "汉仪唐美人" !important; /* 字体 */
}
/* 深度思考展开字体颜色 */
.ant-collapse-content-box .markdown {
color: red;
}
/* 主题变量 */
:root {
--color-black-soft: #2a2b2a; /* 深色背景色 */
--color-white-soft: #f8f7f2; /* 浅色背景色 */
}
/* 深色主题 */
body[theme-mode="dark"] {
/* Colors */
--color-background: #2b2b2b; /* 深色背景色 */
--color-background-soft: #303030; /* 浅色背景色 */
--color-background-mute: #282c34; /* 中性背景色 */
--navbar-background: var(-–color-black-soft); /* 导航栏背景色 */
--chat-background: var(–-color-black-soft); /* 聊天背景色 */
--chat-background-user: #323332; /* 用户聊天背景色 */
--chat-background-assistant: #2d2e2d; /* 助手聊天背景色 */
}
/* 深色主题特定样式 */
body[theme-mode="dark"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* 内容容器背景色 */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* 消息背景色 */
}
.inputbar-container {
background-color: #3d3d3a; /* 输入框背景色 */
border: 1px solid #5e5d5940; /* 输入框边框颜色 */
border-radius: 8px; /* 输入框边框圆角 */
}
/* 代码样式 */
code {
background-color: #e5e5e20d; /* 代码背景色 */
color: #ea928a; /* 代码文字颜色 */
}
pre code {
color: #abb2bf; /* 预格式化代码文字颜色 */
}
}
/* 浅色主题 */
body[theme-mode="light"] {
/* Colors */
--color-white: #ffffff; /* 白色 */
--color-background: #ebe8e2; /* 浅色背景色 */
--color-background-soft: #cbc7be; /* 浅色背景色 */
--color-background-mute: #e4e1d7; /* 中性背景色 */
--navbar-background: var(-–color-white-soft); /* 导航栏背景色 */
--chat-background: var(-–color-white-soft); /* 聊天背景色 */
--chat-background-user: #f8f7f2; /* 用户聊天背景色 */
--chat-background-assistant: #f6f4ec; /* 助手聊天背景色 */
}
/* 浅色主题特定样式 */
body[theme-mode="light"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* 内容容器背景色 */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* 消息背景色 */
}
.inputbar-container {
background-color: #ffffff; /* 输入框背景色 */
border: 1px solid #87867f40; /* 输入框边框颜色 */
border-radius: 8px; /* 输入框边框圆角,修改为您喜欢的大小 */
}
/* 代码样式 */
code {
background-color: #3d39290d; /* 代码背景色 */
color: #7c1b13; /* 代码文字颜色 */
}
pre code {
color: #000000; /* 预格式化代码文字颜色 */
}
}Kimi K2 (官方 API 平台)
智谱 GLM 4.5 (官方 API 平台)
注意:当前许多第三方服务商(如 One API, New API 等)针对 DeepSeek, Kimi, GLM 的 API 接口大多只支持 OpenAI Chat Completions 格式,可能无法与 Claude Code 直接兼容,需要等待服务商逐步适配。
Gemini CLI: 需要选择 Google 的 Gemini 系列模型。
Qwen Code: 支持 OpenAI Chat Completions API 格式的模型,强烈推荐使用 Qwen3 Coder 系列模型以获得最佳代码生成效果。
OpenAI Codex: 支持 GPT 系列模型(如 gpt-4o, gpt-5 等)。
依赖与环境冲突:
Cherry Studio 内部集成了独立的 Node.js 运行环境、Code Agent 可执行文件及环境变量配置,旨在提供一个开箱即用的纯净环境。
如果您在启动 Agent 时遇到依赖冲突或奇怪的错误,可以考虑暂时卸载或禁用系统内已安装的相关依赖(如全局安装的 Node.js 或特定工具链),以排除冲突。
API Token 消耗警告:
Code Agent 对 API Token 的消耗量非常大。在处理复杂任务时,Agent 为了思考、规划和生成代码,可能会产生大量请求,导致 Token 快速消耗。
请务必根据自己的 API 额度和预算,量力而为,密切关注 Token 使用情况,以防止预算超支。










思考模式
复杂推理、数学题、规划类任务
- 求解几何问题 - 编写完整项目架构
非思考模式
快速问答、翻译、摘要
- 查询天气 - 中英文互译





















































注意:Gemini 图片生成需要在对话界面使用,因为 Gemini 是多模态交互式的图片生成,也不支持参数调节。
保持 Ollama 运行: 在您使用 Cherry Studio 与 Ollama 模型交互期间,请确保 Ollama 保持运行状态。
API 地址:
填写 Ollama 提供的本地 API 地址。通常情况下,地址为:
如果修改了端口,请自行更改。
保持活跃时间: 此选项是设置会话的保持时间,单位是分钟。如果在设定时间内没有新的对话,Cherry Studio 会自动断开与 Ollama 的连接,释放资源。
模型管理:
点击“+ 添加”按钮,手动添加您在 Ollama 中已经下载的模型名称。
比如您已经通过ollama run llama3.2下载了llama3.2模型, 那么此处可以填入llama3.2
点击“管理”按钮,可以对已添加的模型进行编辑或删除。
查看Ollama文档和模型
http://localhost:11434/curl -fsSL https://ollama.com/install.sh | shollama run llama3.2相比旧版导出到 Obsidian,新版导出到 Obsidian 功能可以自动选择库路径,不再需要手动输入库名、文件夹名。
打开 Cherry Studio 的设置 → 数据设置 → Obsidian 配置菜单,下拉框中会自动出现在本机打开过的 Obsidian 库名,选择你的目标 Obsidian 库:
回到 Cherry Studio 的对话界面,右键点击对话,选择导出,点击导出到 Obsidian:
此时会弹出一个窗口,用于调整这条导出到 Obsidian 中的对话笔记的 Properties(属性)、所放置在Obsidian的文件夹位置以及导出到 Obsidian 中的处理方式:
保管库:点击下拉菜单可以选择其他 Obsidian 库
路径:点击下拉菜单可以选择存放导出对话笔记的文件夹
作为 Obsidian 笔记属性(Properties):
标签(tags)
创建时间(created)
来源(source)
导出到 Obsidian 中的处理方式有以下三种可选:
导出到 Obsidian 中的处理方式有以下三种可选:
新建(如果存在就覆盖):在路径处填写的文件夹 里新建一篇对话笔记,如果存在同名笔记则会覆盖旧笔记
前置:在已存在同名笔记的情况下,将选中的对话内容导出添加到该笔记的开头
选择完所有选项后,点击确定即可导出完整对话到对应的 Obsidian 库的对应文件夹。
对于单条对话的导出,则点击对话下方的三条杠菜单,选择导出,点击导出到 Obsidian:
之后也会弹出与导出完整对话时一样的窗口,要求你配置笔记属性与笔记的处理方式,一样按照上方的教程完成即可。
🎉 到这里,恭喜你完成了 Cherry Studio 联动 Obsidian 的所有配置,并完整地将导出流程走了一遍,enjoy yourselves!
打开 Obsidian 库,创建一个用于保存导出对话的文件夹(图中以 Cherry Studio 文件夹为例):
注意记住左下角框出来的文字,这里是你的保管库名。
在 Cherry Studio 的设置 → 数据设置 → Obsidian 配置菜单中,输入在第一步中获取到的保管库名与文件夹名:
全局标签处是可选的,可设定所有对话导出后在 Obsidian 中的标签,按需填写。
回到 Cherry Studio 的对话界面,右键点击对话,选择导出,点击导出到 Obsidian。
此时会弹出一个窗口,用于调整这条导出到 Obsidian 中的对话笔记的 Properties(属性),以及导出到 Obsidian 中的处理方式。导出到 Obsidian 中的处理方式有以下三种可选:
新建(如果存在就覆盖):在第二步中填写的文件夹 里新建一篇对话笔记,如果存在同名笔记则会覆盖旧笔记
前置:在已存在同名笔记的情况下,将选中的对话内容导出添加到该笔记的开头
追加:在已存在同名笔记的情况下,将选中的对话内容导出添加到该笔记的末尾
对于单条对话的导出,则点击对话下方的三条杠菜单,选择导出,点击导出到 Obsidian。
之后也会弹出与导出完整对话时一样的窗口,要求你配置笔记属性与笔记的处理方式,一样按照上方的教程完成即可。
🎉 到这里,恭喜你完成了 Cherry Studio 联动 Obsidian 的所有配置,并完整地将导出流程走了一遍,enjoy yourselves!
知识库入口:在 CherryStudio 左侧工具栏,点击知识库图标,即可进入管理页面;
添加知识库:点击添加,开始创建知识库;
命名:输入知识库的名称并添加嵌入模型,以 bge-m3 为例,即可完成创建。
添加文件:点击添加文件的按钮,打开文件选择;
选择文件:选择支持的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,并打开;
向量化:系统会自动进行向量化处理,当显示完成时(绿色 ✓),代表向量化已完成。
CherryStudio 支持多种添加数据的方式:
文件夹目录:可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
网址链接:支持网址 url,如https://docs.siliconflow.cn/introduction;
站点地图:支持 xml 格式的站点地图,如https://docs.siliconflow.cn/sitemap.xml;
纯文本笔记:支持输入纯文本的自定义内容。
当文件等资料向量化完成后,即可进行查询:
点击页面下方的搜索知识库按钮;
输入查询的内容;
呈现搜索的结果;
并显示该条结果的匹配分数。
创建一个新的话题,在对话工具栏中,点击知识库,会展开已经创建的知识库列表,选择需要引用的知识库;
输入并发送问题,模型即返回通过检索结果生成的答案 ;
同时,引用的数据来源会附在答案下方,可快捷查看源文件。
📚 统一训练流程,夯实智能基础
GLM-4.5-Air 与旗舰系列共享一致的训练流程,确保其具备扎实的通用能力基础:
大规模预训练:在高达 15 万亿 token 的通用语料上完成训练,构建广泛的知识理解能力;
专项领域优化:在代码生成、逻辑推理、智能体交互等关键任务上进行强化训练;
长上下文支持:上下文长度扩展至 128K tokens,可处理长文档、复杂对话或大型代码项目;
强化学习增强:通过 RL 优化模型在推理规划、工具调用等方面的决策能力。
这一训练体系为 GLM-4.5-Air 赋予了出色的泛化能力和任务适应性。
⚙️ 专为智能体优化的核心能力
GLM-4.5-Air 针对智能体应用场景进行了深度适配,具备以下实用能力:
✅ 工具调用支持:可通过标准化接口调用外部工具,实现任务自动化 ✅ 网页浏览与信息提取:可配合浏览器插件完成动态内容理解与交互 ✅ 软件工程辅助:支持需求解析、代码生成、缺陷识别与修复 ✅ 前端开发支持:对 HTML、CSS、JavaScript 等前端技术有良好理解与生成能力
该模型可灵活集成至 Claude Code、Roo Code 等代码智能体框架,也可作为任意自定义 Agent 的核心引擎使用。
💡 智能“思考模式”,灵活响应各类请求
GLM-4.5-Air 支持混合推理模式,用户可通过 thinking.type 参数控制是否启用深度思考:
enabled:启用思考,适合需要分步推理或规划的复杂任务
disabled:禁用思考,用于简单查询或即时响应
默认设置为 动态思考模式,模型自动判断是否需要深入分析
简单任务(建议关闭思考)
- 查询“智谱AI的成立时间” - 翻译“I love you”为中文
中等任务(建议启用思考)
- 比较飞机与高铁从北京到上海的优劣 - 解释木星为何有较多卫星
复杂任务(强烈建议启用思考)
- 说明 MoE 模型中专家如何协作 - 基于市场信息分析是否应买入ETF
🌟 高效低成本,部署更轻松
GLM-4.5-Air 在性能与成本之间实现了优秀平衡,特别适合实际业务部署:
⚡ 生成速度超 100 tokens/秒,响应迅速,支持低延迟交互
💰 API 成本极低:输入仅 0.8 元/百万 tokens,输出 2 元/百万 tokens
🖥️ 激活参数少,算力需求低,易于在本地或云端高并发运行
真正实现“高性能、低门槛”的 AI 服务体验。
🧠 聚焦实用能力:智能代码生成
GLM-4.5-Air 在代码生成方面表现稳定,支持:
覆盖 Python、JavaScript、Java 等主流语言
根据自然语言指令生成结构清晰、可维护性强的代码
减少模板化输出,贴近真实开发场景需求
适用于快速原型构建、自动化补全、Bug 修复等高频开发任务。
现在就免费体验 GLM-4.5-Air,开启你的智能体开发之旅! 无论你是想打造自动化助手、编程伴侣,还是探索下一代 AI 应用,GLM-4.5-Air 都将是你高效可靠的 AI 引擎。
📘 立即接入,释放创造力!
Tokens 是 AI 模型处理文本的基本单位,可以理解为模型"思考"的最小单元。它不完全等同于我们理解的字符或单词,而是模型自己的一种特殊的文本分割方式。
一个汉字通常会被编码为 1-2 个 tokens
例如:"你好" ≈ 2-4 tokens
常见单词通常是 1 个 token
较长或不常见的单词会被分解成多个 tokens
例如:
"hello" = 1 token
空格、标点符号等也会占用 tokens
换行符通常是 1 个 token
Tokenizer(分词器)是 AI 模型将文本转换为 tokens 的工具。它决定了如何把输入文本切分成模型可以理解的最小单位。
不同的语料库导致优化方向不同
多语言支持程度差异
特定领域(医疗、法律等)的专门优化
BPE (Byte Pair Encoding) - OpenAI GPT 系列
WordPiece - Google BERT
SentencePiece - 适合多语言场景
有的注重压缩效率
有的注重语义保留
有的注重处理速度
同样的文本在不同模型中的 token 数量可能不同:
基本概念: 嵌入模型是一种将高维离散数据(文本、图像等)转换为低维连续向量的技术,这种转换让机器能更好地理解和处理复杂数据。想象一下,就像把复杂的拼图简化成一个简单的坐标点,但这个点仍然保留了拼图的关键特征。在大模型生态中,它作为"翻译官",将人类可理解的信息转换为 AI 可计算的数字形式。
工作原理: 以自然语言处理为例,嵌入模型可以将词语映射到向量空间中的特定位置。在这个空间里,语义相近的词会自动聚集在一起。比如:
"国王"和"王后"的向量会很接近
"猫"和"狗"这样的宠物词也会距离相近
而"汽车"和"面包"这样语义无关的词则会距离较远
主要应用场景:
文本分析:文档分类、情感分析
推荐系统:个性化内容推荐
图像处理:相似图片检索
搜索引擎:语义搜索优化
核心优势:
降维效果:将复杂数据简化为易处理的向量形式
语义保持:保留原始数据中的关键语义信息
计算效率:显著提升机器学习模型的训练和推理效率
技术价值: 嵌入模型是现代 AI 系统的基础组件,为机器学习任务提供了高质量的数据表示,是推动自然语言处理、计算机视觉等领域发展的关键技术。
基本工作流程:
知识库预处理阶段
将文档分割成适当大小的 chunk(文本块)
使用 embedding 模型将每个 chunk 转换为向量
将向量和原文存储到向量数据库中
查询处理阶段
将用户问题转换为向量
在向量库中检索相似内容
将检索到的相关内容作为上下文提供给 LLM
MCP 是一种开源协议,旨在以标准化的方式向大型语言模型(LLM)提供上下文信息。
类比理解: 可以把 MCP 想象成 AI 领域的“U盘”。我们知道,U盘可以存储各种文件,插入电脑后就能直接使用。类似地,MCP Server 上可以“插”上各种提供上下文的“插件”,LLM 可以根据需要向 MCP Server 请求这些插件,从而获取更丰富的上下文信息,增强自身能力。
与 Function Tool 的对比: 传统的 Function Tool(函数工具)也可以为 LLM 提供外部功能,但 MCP 更像是一种更高维度的抽象。Function Tool 更多的是针对具体任务的工具,而 MCP 则提供了一种更通用的、模块化的上下文获取机制。
标准化: MCP 提供了统一的接口和数据格式,使得不同的 LLM 和上下文提供者可以无缝协作。
模块化: MCP 允许开发者将上下文信息分解为独立的模块(插件),方便管理和复用。
灵活性: LLM 可以根据自身需求动态选择所需的上下文插件,实现更智能、更个性化的交互。
可扩展性: MCP 的设计支持未来添加更多类型的上下文插件,为 LLM 的能力拓展提供了无限可能。
4xx(客户端错误状态码):一般为请求语法错误、鉴权失败或认证失败等无法完成请求。
5xx(服务器错误状态码):一般为服务端错误,服务器宕机、请求处理超时等。
点击 Cherry Studio 客户端窗口后按下快捷键 Ctrl + Shift + I(Mac端:Command + Option + I)
在弹出的控制台窗口中点击 Network → 点击查看②处最后一个标有红色 × 的 completions(对话类、翻译、模型连通性检查等遇到错误时) 或 generations(绘画遇到错误时) → 点击Response查看完整的返回内容(图中④的区域)。
如果你无法判断该错误的原因,请将该界面截图发送到 中寻求帮助。
该检查方法不仅在对话时可以获取错误信息,在模型测试时、添加知识库时、绘画时等都可以使用。无论哪种情况下都需要先打开调试窗口,再进行请求操作来获取请求信息。·
公式未被渲染而是直接显示的公式的代码时检查公式是否有定界符
定界符用法
行内公式
使用单个美元符号:
$formula$或使用
\(和\),如:\(formula\)独立公式块
公式渲染错误/乱码 常见在公式内包含中文内容时,尝试切换公式引擎为 KateX。
模型状态不可用
确认服务商是否支持该模型或确认服务商该模型服务状态是否正常。
2.使用了非嵌入模型
首先需要确认模型是否支持识图,热门模型 Cherry Studio 会对其分类,模型名称后带小眼睛图标的即支持识图。
识图模型会支持图像文件的上传,如果模型功能未被正确匹配可在对应服务商的模型列表当中找到该模型,点击其名称后的设置按钮并勾选图像选项。
模型具体的信息可以到对应服务商找到其信息查阅。同嵌入模型一样,不支持视觉的模型不需要强制开启图像功能,勾选了图像的选项也没有作用。
ModelScope 是新一代开源模型即服务(MaaS)共享平台,致力于为泛 AI 开发者提供灵活、易用、低成本的一站式模型服务解决方案,让模型应用更简单!
通过 API-Inference 服务化能力,平台将开源模型标准化为可调用的 API 接口,开发者可轻量、快速地集成模型能力至各类 AI 应用,支持工具调用、原型开发等创新场景。
✅ 免费额度:每日提供 2000 次免费 API 调用额度()
✅ 丰富模型库:覆盖 NLP、CV、语音、多模态等 1000+ 开源模型
✅ 即开即用:无需部署,通过 RESTful API 快速调用
登录平台
访问 → 点击右上角登录 → 选择认证方式
创建访问令牌
进入
打开 Cherry Studio → 设置 → 模型服务 → ModelScope
在 API 密钥 栏粘贴复制的令牌
点击 保存 完成授权
查找支持 API 的模型
访问
筛选条件:勾选 API-Inference(或认准模型卡片上的 API 图标)
🎫 免费额度:每位用户 每日 2000 次 API 调用(*以官网最新规则为准)
🔁 额度重置:每日 UTC+8 00:00 自动重置,不支持跨日累计或升级
💡 超额处理:
达到当日上限后 API 将返回
登录 ModelScope → 点击右上角 用户名 → API 使用情况
⚠️ 注意:推理 API-Inference 每天2000次的免费调用额度。更多调用需求可考虑使用阿里云百炼等云上服务。























请求格式正确,但语义错误
这类错误服务端能解析,但无法处理。常见于JSON语义错误(如:空值;要求值为字符串,但写成了数字或布尔值等情况)。
429
请求速率达到上限
请求速率(TPM 或 RPM)达到上限,冷静一会再用
500
服务器内部错误,无法完成请求
持续出现的话联系上游服务商
501
服务器不支持请求的功能,无法完成请求
502
作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
503
由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
504
充当网关或代理的服务器,未及时从远端服务器获取请求
使用双美元符号: $$formula$$
或使用 \[formula\]
示例: $$\sum_{i=1}^n x_i$$
400
请求体格式错误等
401
认证失败:模型不被支持或服务端账户被封禁等
联系或查看对应服务商账户状态
403
请求操作无权限
根据对话返回的错误信息或控制台错误信息提示进行相应操作
404
无法找到请求资源
检查请求路径等

422




"indescribable" = 4 tokens
输入:"Hello, world!"
GPT-3: 4 tokens
BERT: 3 tokens
Claude: 3 tokens点击 新建令牌 → 填写描述 → 复制生成的令牌(页面示例见下图)
🔑 重要提示:令牌泄露将影响账号安全!
获取模型 ID
进入目标模型详情页 → 复制 Model ID(格式如 damo/nlp_structbert_sentiment-classification_chinese-base)
填入 Cherry Studio
在模型服务配置页的 模型 ID 栏输入 ID → 选择任务类型 → 完成配置
429 错误解决方案:切换备用账号 / 使用其他平台 / 优化调用频率




可控性: 直接管理您的 API 密钥和访问地址,确保安全和隐私。
定制化: 接入私有化部署的模型,满足特定业务场景的需求。
只需简单几步,即可在 Cherry Studio 中添加您的自定义 AI 服务商:
打开设置: 在 Cherry Studio 界面左侧导航栏中,点击“设置”(齿轮图标)。
进入模型服务: 在设置页面中,选择“模型服务”选项卡。
添加提供商: 在“模型服务”页面中,您会看到已有的服务商列表。点击列表下方的“+ 添加”按钮,打开“添加提供商”弹窗。
填写信息: 在弹窗中,您需要填写以下信息:
提供商名称: 为您的自定义服务商起一个易于识别的名称(例如:MyCustomOpenAI)。
提供商类型: 从下拉列表中选择您的服务商类型。目前支持:
OpenAI
Gemini
Anthropic
保存配置: 填写完毕后,点击“添加”按钮保存您的配置。
添加完成后,您需要在列表中找到您刚刚添加的服务商,并进行详细配置:
启用状态 自定义服务商列表最右侧有一个启用开关,打开代表启用该自定义服务。
API 密钥:
填写您的 AI 服务商提供的 API 密钥(API Key)。
点击右侧的“检查”按钮,可以验证密钥的有效性。
API 地址:
填写 AI 服务的 API 访问地址(Base URL)。
请务必参考您的 AI 服务商提供的官方文档,获取正确的 API 地址。
模型管理:
点击“+ 添加”按钮,手动添加此提供商下您想要使用的模型ID。例如 gpt-3.5-turbo、gemini-pro 等。
如果您不确定具体的模型名称,请参考您的 AI 服务商提供的官方文档。
完成以上配置后,您就可以在 Cherry Studio 的聊天界面中,选择您自定义的 AI 服务商和模型,开始与 AI 进行对话了!
vLLM 是一个类似Ollama的快速且易于使用的 LLM 推理库。以下是如何将 vLLM 集成到 Cherry Studio 中的步骤:
安装 vLLM: 按照 vLLM 官方文档(https://docs.vllm.ai/en/latest/getting_started/quickstart.html)安装 vLLM。
启动 vLLM 服务: 使用 vLLM 提供的 OpenAI 兼容接口启动服务。主要有两种方式,分别如下:
使用vllm.entrypoints.openai.api_server启动
使用uvicorn启动
确保服务成功启动,并监听在默认端口 8000 上。 当然, 您也可以通过参数--port指定 vLLM 服务的端口号。
在 Cherry Studio 中添加 vLLM 服务商:
按照前面描述的步骤,在 Cherry Studio 中添加一个新的自定义 AI 服务商。
提供商名称: vLLM
提供商类型: 选择 OpenAI。
配置 vLLM 服务商:
API 密钥: 因为 vLLM 不需要 API 密钥,可以将此字段留空,或者填写任意内容。
API 地址: 填写 vLLM 服务的 API 地址。默认情况下,地址为: http://localhost:8000/(如果使用了不同的端口,请相应地修改)。
模型管理:
开始对话: 现在,您可以在 Cherry Studio 中选择 vLLM 服务商和 gpt2 模型,开始与 vLLM 驱动的 LLM 进行对话了!
仔细阅读文档: 在添加自定义服务商之前,请务必仔细阅读您所使用的 AI 服务商的官方文档,了解 API 密钥、访问地址、模型名称等关键信息。
检查 API 密钥: 使用“检查”按钮可以快速验证 API 密钥的有效性,避免因密钥错误导致无法使用。
关注 API 地址: 不同的 AI 服务商和模型,API 地址可能有所不同,请务必填写正确的地址。
模型按需添加: 请只添加您实际上会用到的模型, 避免添加过多无用模型.
助手 是对所选模型做一些个性化的设置来使用模型,如提示词预设和参数预设等,通过这些设置让所选模型能更加符合你预期的工作。
系统默认助手 预设了一个比较通用的参数(无提示词),您可以直接使用或者到 寻找你需要的预设来使用。
助手 是 话题 的父集,单个助手下可以创建多个话题(即对话),所有 话题 共用 助手 的参数设置和预设词(prompt)等模型设置。
新话题 在当前助手内创建一个新话题。
上传图片或文档 上传图片需要模型支持,上传文档会自动解析为文字作为上下文提供给模型。
网络搜索 须在设置中配置网络搜索相关信息,搜索结果作为上下文返回给大模型,详见 。
知识库 开启知识库,详见 。
MCP 服务器 开启 MCP 服务器功能,详见 。
生成图片 只有选择的 对话模型 支持生图时才会显示。(非对话生图模型请前往 )
选择模型 对于接下来的对话,切换成指定的模型,保留上下文。
快捷短语 需要先在设置中预设常用短语,在此处调用,直接输入,支持变量。
清空消息 删除该话题下所有内容。
展开 让对话框变得更大,以便输入长文。
清除上下文 在不删除内容的情况下,截断模型能获得的上下文,也就是说模型将“忘记”之前的对话内容。
预估 Token 数 展示预估 Token 数,四个数据分别为 当前上下文数 、 最大上下文数 ( ∞ 表示无限上下文)、 当前输入框内消息字数 、 预估 Token 数 。
翻译 将当前输入框内内容翻译成英文。
模型设置与助手设置当中的 模型设置 参数同步,详见 。
消息分割线:使用分割线将消息正文与操作栏隔开。
使用衬线字体:字体样式切换,现在你也可以通过 来更换字体。
代码显示行号:模型输出代码片段时显示代码块行号。
代码块可折叠:打开后,当代码片段中代码较长时,将自动折叠代码块。、
代码块可换行:打开后,当代码片段中但行代码较长时(超出窗口),将自动换行。
思考内容自动折叠:打开后,支持思考的模型在思考完成后会自动折叠思考过程。
消息样式:可切对话界面换为气泡样式或列表样式。
代码风格:可切换代码片段的显示风格。
数学公式引擎:KaTeX 渲染速度更快,因为它是专门为性能优化设计的;
MathJax 渲染较慢,但功能更全面,支持更多的数学符号和命令。
消息字体大小:调整对话界面字体的大小。
显示预估 Token 数:在输入框显示输入文本预估消耗的Token数(非实际上下文消耗的Token,仅供参考)。
长文本粘贴为文件:当从其他地方复制长段文本粘贴到输入框时会自动显示为文件的样式,减少后续输入内容时的干扰。
Markdown 渲染输入消息:关闭时只渲染模型回复的消息,不渲染发送的消息。
快速敲击3次空格翻译:在对话界面输入框输入消息后,连敲三次空格可翻译输入的内容为英文。
注意:该操作会覆盖原文。
目标语言:设置输入框翻译按钮以及快速敲击3次空格翻译的目标语言。
在助手界面选择需要设置的助手名称→在右键菜单中选对应设置
名称:可自定义方便辨识的助手名称。
提示词:即 prompt ,可以参照智能体页面的提示词写法来编辑内容。
默认模型:可以为该助手固定一个默认模型,从智能体页面添加时或复制助手时初始模型为该模型。不设置该项初始模型则为全局初始模型(即 )。
自动重置模型:打开时 - 当在该话题下使用过程中切换其他模型使用时,再次新建话题会将新话题的重置为助手的默认模型。当该项关闭时新建话题的模型会跟随上一话题所使用的模型。
如助手的默认模型为gpt-3.5-turbo,我在该助手下创建话题1,在话题1的对话过程中切换了gpt-4o使用,此时:
如果开启了自动重置:新建话题2时,话题2默认选择的模型为gpt-3.5-turbo;
如果未开启自动重置:新建话题2时,话题2默认选择的模型为gpt-4o。
温度 (Temperature) :温度参数控制模型生成文本的随机性和创造性程度(默认值为0.7)。具体表现为:
低温度值(0-0.3):
输出更确定、更专注
适合代码生成、数据分析等需要准确性的场景
倾向于选择最可能的词汇输出
Top P (核采样):默认值为 1,值越小,AI 生成的内容越单调,也越容易理解;值越大,AI 回复的词汇范围越大,越多样化。
核采样通过控制词汇选择的概率阈值来影响输出:
较小值(0.1-0.3):
仅考虑最高概率的词汇
输出更保守、更可控
适合代码注释、技术文档等场景
上下文数量 (Context Window)要保留在上下文中的消息数量,数值越大,上下文越长,消耗的 token 越多:
5-10:适合普通对话
>10:需要更长记忆的复杂任务(例如:按照写作提纲分步生成长文的任务,需要确保生成的上下文逻辑连贯)
注意:消息数越多,token 消耗越大
开启消息长度限制 (MaxToken)单次回答最大 数,在大语言模型中,max token(最大令牌数)是一个关键参数,它直接影响模型生成回答的质量和长度。
如:在CherryStudio当中填写好key后测试模型是否连通时,只需要知道模型是否有正确返回消息而不需特定内容,这种情况下设置MaxToken为1即可。
多数模型的MaxToken上限为32k Tokens,当然也有64k,甚至更多的,具体需要到对应介绍页面查看。
具体设置多少取决于自己的需要,当然也可以参考以下建议。
建议:
普通聊天:500-800
短文生成:800-2000
一般情况下模型生成的回答将被限制在 MaxToken 的范围内,当然也有可能会出现被截断(如写长代码时)或表达不完整等情况出现,特殊情况下也需要根据实际情况来灵活调整。
流式输出(Stream)流式输出是一种数据处理方式,它允许数据以连续的流形式进行传输和处理,而不是一次性发送所有数据。这种方式使得数据可以在生成后立即被处理和输出,极大地提高了实时性和效率。
在 CherryStudio 客户端等类似环境下简单来说就是打字机效果。
关闭后(非流):模型生成完信息后整段一次性输出(想象一下微信收到消息的感觉);
打开时:逐字输出,可以理解为大模型每生成一个字就立马发送给你,直到全部发送完。
自定义参数在请求体(body)中加入额外请求参数,如 presence_penalty 等字段,一般人一般情况下用不到。
上述top-p、maxtokens、stream等参数就是这些参数之一。
填法:参数名称—参数类型(文本、数字等)—值,参考文档:
pip install vllm # 如果你使用 pip
uv pip install vllm # 如果你使用 uvpython -m vllm.entrypoints.openai.api_server --model gpt2中等温度值(0.4-0.7):
平衡了创造性和连贯性
适合日常对话、一般性写作
推荐用于聊天机器人对话(0.5左右)
高温度值(0.8-1.0):
产生更具创造性和多样性的输出
适合创意写作、头脑风暴等场景
但可能降低文本的连贯性
中等值(0.4-0.6):
平衡词汇多样性和准确性
适合一般对话和写作任务
较大值(0.7-1.0):
考虑更广泛的词汇选择
产生更丰富多样的内容
适合创意写作等需要多样化表达的场景
以上内容仅供参考和了解概念,所给参数范围不一定适合所有模型,具体可参考模型相关文档给出的参数建议。
长文生成:4000及以上 (需要模型本身支持)
使用 参数名称:undefined 的设置可排除参数。




























点击"管理"按钮,可以对已经添加的模型进行编辑或者删除。
python -m vllm.entrypoints.openai.api_server --model gpt2gpt2


vllm --model gpt2 --served-model-name gpt28191
jina-reranker-v1-base-en
8191
jina-reranker-v1-turbo-en
8191
jina-reranker-v1-tiny-en
8191
jina-clip-v1
8191
jina-reranker-v2-base-multilingual
8191
reader-lm-1.5b
256000
reader-lm-0.5b
256000
jina-colbert-v2
8191
jina-embeddings-v3
8191
256
Doubao-embedding
4095
Doubao-embedding-vision
8191
Doubao-embedding-large
4095
text-embedding-v3
8192
text-embedding-v2
2048
text-embedding-v1
2048
text-embedding-async-v2
2048
text-embedding-async-v1
2048
text-embedding-3-small
8191
text-embedding-3-large
8191
text-embedding-ada-002
8191
Embedding-V1
384
tao-8k
8192
embedding-2
1024
embedding-3
2048
hunyuan-embedding
1024
Baichuan-Text-Embedding
512
M2-BERT-80M-2K-Retrieval
2048
M2-BERT-80M-8K-Retrieval
8192
M2-BERT-80M-32K-Retrieval
32768
UAE-Large-v1
512
BGE-Large-EN-v1.5
512
BGE-Base-EN-v1.5
512
jina-embedding-b-en-v1
512
jina-embeddings-v2-base-en
8191
jina-embeddings-v2-base-zh
8191
jina-embeddings-v2-base-de
8191
jina-embeddings-v2-base-code
8191
jina-embeddings-v2-base-es
8191
BAAI/bge-m3
8191
netease-youdao/bce-embedding-base_v1
512
BAAI/bge-large-zh-v1.5
512
BAAI/bge-large-en-v1.5
512
Pro/BAAI/bge-m3
8191
text-embedding-004
2048
nomic-embed-text-v1
8192
nomic-embed-text-v1.5
8192
gte-multilingual-base
8192
embedding-query
4000
embedding-passage
4000
embed-english-v3.0
512
embed-english-light-v3.0
512
embed-multilingual-v3.0
512
embed-multilingual-light-v3.0
512
embed-english-v2.0
512
embed-english-light-v2.0
512
jina-colbert-v1-en
embed-multilingual-v2.0

CherryStudio 支持通过 SearXNG 进行网络搜索,SearXNG 是一个可本地部署也可在服务器上部署的开源项目,所以与其他需要 API 提供商的配置方式略有不同。
SearXNG 项目链接:SearXNG
开源免费,无需 API
隐私性相对较高
可高度定制化
由于 SearXNG 不需要复杂的环境配置,可以不用 docker compose,只需要简单提供一个空闲端口即可部署,所以最快捷的方式可以使用 Docker 直接拉取镜像进行部署。
安装后选择一个镜像存储路径:
搜索栏输入 searxng :
拉取镜像:
拉取成功后来到 images 页面:
选择拉取的镜像点击运行:
打开设置项进行配置:
以 8085 端口为例:
运行成功后点击链接即可打开 SearXNG 的前端界面:
出现这个页面说明部署成功:
鉴于 Windows 下安装 Docker 是一件较为麻烦的事情,用户可以将 SearXNG 部署在服务器上,也可借此共享给其他人使用。但是很遗憾,SearXNG 自身暂不支持鉴权,导致他人可以通过技术手段扫描到并滥用你部署的实例。
为此,Cherry Studio 目前已支持配置 ,如果用户欲将自己部署的 SearXNG 暴露在公网环境下,请务必通过 Nginx 等反向代理软件配置 HTTP 基本认证。下面提供简要教程,需要你有基本的 Linux 运维知识。
类似地,仍然使用 Docker 部署。假设你已经按照在服务器上安装好了最新版 Docker CE,以下提供一条龙命令,适用于 Debian 系统下全新安装:
如果你需要修改本地监听端口、复用本地已有的 nginx,可以编辑 docker-compose.yaml 文件,参考如下:
执行 docker compose up -d 启动。执行 docker compose logs -f searxng 可以看到日志。
如果你使用了一些服务器面板程序,例如宝塔面板或 1Panel,请参阅其文档添加网站并配置 nginx 反向代理,随后找到修改 nginx 配置文件的地方, 参考下面的示例进行修改:
假设 Nginx 配置文件保存于 /etc/nginx/conf.d 下,我们将将密码文件保存在同目录下。
执行命令(自行将 example_name、example_password 替换为你将要设定的用户名和密码):
重启 Nginx(重载配置也可以)。
这时可以打开一下网页,已经会提示你输入用户名和密码,请输入前面设定的用户名和密码查看能否成功进入 SearXNG 搜索页面,藉此检查配置是否正确。
SearXNG 本地或在服务器部署成功后,接下来是 CherryStudio 的相关配置。
来到网络搜索设置页面,选择 Searxng :
直接输入本地部署的链接发现验证失败,此时不用担心:
因为直接部署后默认并没有配置 json 返回类型,所以无法获取数据,需要修改配置文件。
回到 Docker,来到 Files 标签页找到镜像中找到带标签的文件夹:
展开后继续往下翻,会发现另一个带标签的文件夹:
继续展开,找到 settings.yml 配置文件:
点击打开文件编辑器:
找到 78 行,可以看到类型只有一个 html
添加 json 类型后保存,重新运行镜像
重新回到 Cherry Studio 进行验证,验证成功:
地址既可以填写本地: : 端口号 也可以填写 docker 地址: : 端口号
如果用户遵循前面的示例在服务器上部署并正确配置了反向代理,已经开启了 json 返回类型。输入地址后进行验证,由于已给反向代理配置了 HTTP 基本认证,此时验证则应返回 401 错误码:
在客户端配置 HTTP 基本认证,输入刚才设置的用户名与密码:
进行验证,应当验证成功。
此时 SearXNG 已具备默认联网搜索能力,如需定制搜索引擎需要自行进行配置
需要注意的是此处首选项并不能影响大模型调用时的配置
如需配置需要大模型调用的搜索引擎,需在配置文件中设置:
配置语言参考:
若内容太长直接修改不方便,可将其复制到本地 IDE 中,修改后粘贴到配置文件中即可。
在配置文件中将返回格式加上 json:
Cherry Studio 会默认选取 categories 同时包含 web general 的引擎进行搜索,默认情况下会选中 google 等引擎,由于大陆无法直接访问 google 等网站导致失败。增加以下配置使得 searxng 强制使用 baidu 引擎,即可解决问题:
searxng 的 limiter 配置阻碍了 API 访问,请尝试将其在设置中设为 false:
sudo apt update
sudo apt install git -y
# 拉取官方仓库
cd /opt
git clone https://github.com/searxng/searxng-docker.git
cd /opt/searxng-docker
# 如果你的服务器带宽很小, 可以设置为 false
export IMAGE_PROXY=true
# 修改配置文件
cat <<EOF > /opt/searxng-docker/searxng/settings.yml
# see https://docs.searxng.org/admin/settings/settings.html#settings-use-default-settings
use_default_settings: true
server:
# base_url is defined in the SEARXNG_BASE_URL environment variable, see .env and docker-compose.yml
secret_key: $(openssl rand -hex 32)
limiter: false # can be disabled for a private instance
image_proxy: $IMAGE_PROXY
ui:
static_use_hash: true
redis:
url: redis://redis:6379/0
search:
formats:
- html
- json
EOFversion: "3.7"
services:
# 如果不需要 Caddy 而复用本地已经有的 Nginx, 就把下面的去掉. 我们默认不需要 Caddy.
caddy:
container_name: caddy
image: docker.io/library/caddy:2-alpine
network_mode: host
restart: unless-stopped
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile:ro
- caddy-data:/data:rw
- caddy-config:/config:rw
environment:
- SEARXNG_HOSTNAME=${SEARXNG_HOSTNAME:-http://localhost}
- SEARXNG_TLS=${LETSENCRYPT_EMAIL:-internal}
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
# 如果不需要 Caddy 而复用本地已经有的 Nginx, 就把上面的去掉. 我们默认不需要 Caddy.
redis:
container_name: redis
image: docker.io/valkey/valkey:8-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: unless-stopped
networks:
- searxng
volumes:
- valkey-data2:/data
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
searxng:
container_name: searxng
image: docker.io/searxng/searxng:latest
restart: unless-stopped
networks:
- searxng
# 默认映射到宿主机 8080 端口, 假如你想监听 8000 就改成 "127.0.0.1:8000:8080"
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
- UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4}
- UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4}
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
searxng:
volumes:
# 如果不需要 Caddy 而复用本地已经有的 Nginx, 就把下面的去掉
caddy-data:
caddy-config:
# 如果不需要 Caddy 而复用本地已经有的 Nginx, 就把上面的去掉
valkey-data2:server
{
listen 443 ssl;
# 这行是你的主机名
server_name search.example.com;
# index index.html;
# root /data/www/default;
# 如果配置了 SSL 应该有这两行
ssl_certificate /path/to/your/cert/fullchain.pem;
ssl_certificate_key /path/to/your/cert/privkey.pem;
# HSTS
# add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload";
# 默认情况下通过面板配置反向代理, 默认的 location 块就是这样
location / {
# 只需要在 location 块添加下面两行, 其他保留原状就行.
# 此处示例假设你的配置文件保存在 /etc/nginx/conf.d/ 目录下.
# 如果是宝塔应该是保存在 /www 之类的目录下, 需要注意.
auth_basic "Please enter your username and password";
auth_basic_user_file /etc/nginx/conf.d/search.htpasswd;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_protocol_addr;
proxy_pass http://127.0.0.1:8000;
client_max_body_size 0;
}
# access_log ...;
# error_log ...;
}echo "example_name:$(openssl passwd -5 'example_password')" > /etc/nginx/conf.d/search.htpasswduse_default_settings:
engines:
keep_only:
- baidu
engines:
- name: baidu
engine: baidu
categories:
- web
- general
disabled: false





























Copyright (C) 2007 Free Software Foundation, Inc. https://fsf.org/ Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
The GNU Affero General Public License is a free, copyleft license for software and other kinds of works, specifically designed to ensure cooperation with the community in the case of network server software.
The licenses for most software and other practical works are designed to take away your freedom to share and change the works. By contrast, our General Public Licenses are intended to guarantee your freedom to share and change all versions of a program--to make sure it remains free software for all its users.
When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for them if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs, and that you know you can do these things.
Developers that use our General Public Licenses protect your rights with two steps: (1) assert copyright on the software, and (2) offer you this License which gives you legal permission to copy, distribute and/or modify the software.
A secondary benefit of defending all users' freedom is that improvements made in alternate versions of the program, if they receive widespread use, become available for other developers to incorporate. Many developers of free software are heartened and encouraged by the resulting cooperation. However, in the case of software used on network servers, this result may fail to come about. The GNU General Public License permits making a modified version and letting the public access it on a server without ever releasing its source code to the public.
The GNU Affero General Public License is designed specifically to ensure that, in such cases, the modified source code becomes available to the community. It requires the operator of a network server to provide the source code of the modified version running there to the users of that server. Therefore, public use of a modified version, on a publicly accessible server, gives the public access to the source code of the modified version.
An older license, called the Affero General Public License and published by Affero, was designed to accomplish similar goals. This is a different license, not a version of the Affero GPL, but Affero has released a new version of the Affero GPL which permits relicensing under this license.
The precise terms and conditions for copying, distribution and modification follow.
0. Definitions.
"This License" refers to version 3 of the GNU Affero General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this License. Each licensee is addressed as "you". "Licensees" and "recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work in a fashion requiring copyright permission, other than the making of an exact copy. The resulting work is called a "modified version" of the earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based on the Program.
To "propagate" a work means to do anything with it that, without permission, would make you directly or secondarily liable for infringement under applicable copyright law, except executing it on a computer or modifying a private copy. Propagation includes copying, distribution (with or without modification), making available to the public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other parties to make or receive copies. Mere interaction with a user through a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices" to the extent that it includes a convenient and prominently visible feature that (1) displays an appropriate copyright notice, and (2) tells the user that there is no warranty for the work (except to the extent that warranties are provided), that licensees may convey the work under this License, and how to view a copy of this License. If the interface presents a list of user commands or options, such as a menu, a prominent item in the list meets this criterion.
Source Code.
The "source code" for a work means the preferred form of the work for making modifications to it. "Object code" means any non-source form of a work.
A "Standard Interface" means an interface that either is an official standard defined by a recognized standards body, or, in the case of interfaces specified for a particular programming language, one that is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other than the work as a whole, that (a) is included in the normal form of packaging a Major Component, but which is not part of that Major Component, and (b) serves only to enable use of the work with that Major Component, or to implement a Standard Interface for which an implementation is available to the public in source code form. A "Major Component", in this context, means a major essential component (kernel, window system, and so on) of the specific operating system (if any) on which the executable work runs, or a compiler used to produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all the source code needed to generate, install, and (for an executable work) run the object code and to modify the work, including scripts to control those activities. However, it does not include the work's System Libraries, or general-purpose tools or generally available free programs which are used unmodified in performing those activities but which are not part of the work. For example, Corresponding Source includes interface definition files associated with source files for the work, and the source code for shared libraries and dynamically linked subprograms that the work is specifically designed to require, such as by intimate data communication or control flow between those subprograms and other parts of the work.
The Corresponding Source need not include anything that users can regenerate automatically from other parts of the Corresponding Source.
The Corresponding Source for a work in source code form is that same work.
Basic Permissions.
All rights granted under this License are granted for the term of copyright on the Program, and are irrevocable provided the stated conditions are met. This License explicitly affirms your unlimited permission to run the unmodified Program. The output from running a covered work is covered by this License only if the output, given its content, constitutes a covered work. This License acknowledges your rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not convey, without conditions so long as your license otherwise remains in force. You may convey covered works to others for the sole purpose of having them make modifications exclusively for you, or provide you with facilities for running those works, provided that you comply with the terms of this License in conveying all material for which you do not control copyright. Those thus making or running the covered works for you must do so exclusively on your behalf, under your direction and control, on terms that prohibit them from making any copies of your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under the conditions stated below. Sublicensing is not allowed; section 10 makes it unnecessary.
Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological measure under any applicable law fulfilling obligations under article 11 of the WIPO copyright treaty adopted on 20 December 1996, or similar laws prohibiting or restricting circumvention of such measures.
When you convey a covered work, you waive any legal power to forbid circumvention of technological measures to the extent such circumvention is effected by exercising rights under this License with respect to the covered work, and you disclaim any intention to limit operation or modification of the work as a means of enforcing, against the work's users, your or third parties' legal rights to forbid circumvention of technological measures.
Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice; keep intact all notices stating that this License and any non-permissive terms added in accord with section 7 apply to the code; keep intact all notices of the absence of any warranty; and give all recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey, and you may offer support or warranty protection for a fee.
Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to produce it from the Program, in the form of source code under the terms of section 4, provided that you also meet all of these conditions:
A compilation of a covered work with other separate and independent works, which are not by their nature extensions of the covered work, and which are not combined with it such as to form a larger program, in or on a volume of a storage or distribution medium, is called an "aggregate" if the compilation and its resulting copyright are not used to limit the access or legal rights of the compilation's users beyond what the individual works permit. Inclusion of a covered work in an aggregate does not cause this License to apply to the other parts of the aggregate.
Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms of sections 4 and 5, provided that you also convey the machine-readable Corresponding Source under the terms of this License, in one of these ways:
A separable portion of the object code, whose source code is excluded from the Corresponding Source as a System Library, need not be included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any tangible personal property which is normally used for personal, family, or household purposes, or (2) anything designed or sold for incorporation into a dwelling. In determining whether a product is a consumer product, doubtful cases shall be resolved in favor of coverage. For a particular product received by a particular user, "normally used" refers to a typical or common use of that class of product, regardless of the status of the particular user or of the way in which the particular user actually uses, or expects or is expected to use, the product. A product is a consumer product regardless of whether the product has substantial commercial, industrial or non-consumer uses, unless such uses represent the only significant mode of use of the product.
"Installation Information" for a User Product means any methods, procedures, authorization keys, or other information required to install and execute modified versions of a covered work in that User Product from a modified version of its Corresponding Source. The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made.
If you convey an object code work under this section in, or with, or specifically for use in, a User Product, and the conveying occurs as part of a transaction in which the right of possession and use of the User Product is transferred to the recipient in perpetuity or for a fixed term (regardless of how the transaction is characterized), the Corresponding Source conveyed under this section must be accompanied by the Installation Information. But this requirement does not apply if neither you nor any third party retains the ability to install modified object code on the User Product (for example, the work has been installed in ROM).
The requirement to provide Installation Information does not include a requirement to continue to provide support service, warranty, or updates for a work that has been modified or installed by the recipient, or for the User Product in which it has been modified or installed. Access to a network may be denied when the modification itself materially and adversely affects the operation of the network or violates the rules and protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided, in accord with this section must be in a format that is publicly documented (and with an implementation available to the public in source code form), and must require no special password or key for unpacking, reading or copying.
Additional Terms.
"Additional permissions" are terms that supplement the terms of this License by making exceptions from one or more of its conditions. Additional permissions that are applicable to the entire Program shall be treated as though they were included in this License, to the extent that they are valid under applicable law. If additional permissions apply only to part of the Program, that part may be used separately under those permissions, but the entire Program remains governed by this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option remove any additional permissions from that copy, or from any part of it. (Additional permissions may be written to require their own removal in certain cases when you modify the work.) You may place additional permissions on material, added by you to a covered work, for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you add to a covered work, you may (if authorized by the copyright holders of that material) supplement the terms of this License with terms:
All other non-permissive additional terms are considered "further restrictions" within the meaning of section 10. If the Program as you received it, or any part of it, contains a notice stating that it is governed by this License along with a term that is a further restriction, you may remove that term. If a license document contains a further restriction but permits relicensing or conveying under this License, you may add to a covered work material governed by the terms of that license document, provided that the further restriction does not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you must place, in the relevant source files, a statement of the additional terms that apply to those files, or a notice indicating where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the form of a separately written license, or stated as exceptions; the above requirements apply either way.
Termination.
You may not propagate or modify a covered work except as expressly provided under this License. Any attempt otherwise to propagate or modify it is void, and will automatically terminate your rights under this License (including any patent licenses granted under the third paragraph of section 11).
However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.
Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, you do not qualify to receive new licenses for the same material under section 10.
Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or run a copy of the Program. Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance. However, nothing other than this License grants you permission to propagate or modify any covered work. These actions infringe copyright if you do not accept this License. Therefore, by modifying or propagating a covered work, you indicate your acceptance of this License to do so.
Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically receives a license from the original licensors, to run, modify and propagate that work, subject to this License. You are not responsible for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an organization, or substantially all assets of one, or subdividing an organization, or merging organizations. If propagation of a covered work results from an entity transaction, each party to that transaction who receives a copy of the work also receives whatever licenses to the work the party's predecessor in interest had or could give under the previous paragraph, plus a right to possession of the Corresponding Source of the work from the predecessor in interest, if the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the rights granted or affirmed under this License. For example, you may not impose a license fee, royalty, or other charge for exercise of rights granted under this License, and you may not initiate litigation (including a cross-claim or counterclaim in a lawsuit) alleging that any patent claim is infringed by making, using, selling, offering for sale, or importing the Program or any portion of it.
Patents.
A "contributor" is a copyright holder who authorizes use under this License of the Program or a work on which the Program is based. The work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims owned or controlled by the contributor, whether already acquired or hereafter acquired, that would be infringed by some manner, permitted by this License, of making, using, or selling its contributor version, but do not include claims that would be infringed only as a consequence of further modification of the contributor version. For purposes of this definition, "control" includes the right to grant patent sublicenses in a manner consistent with the requirements of this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free patent license under the contributor's essential patent claims, to make, use, sell, offer for sale, import and otherwise run, modify and propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express agreement or commitment, however denominated, not to enforce a patent (such as an express permission to practice a patent or covenant not to sue for patent infringement). To "grant" such a patent license to a party means to make such an agreement or commitment not to enforce a patent against the party.
If you convey a covered work, knowingly relying on a patent license, and the Corresponding Source of the work is not available for anyone to copy, free of charge and under the terms of this License, through a publicly available network server or other readily accessible means, then you must either (1) cause the Corresponding Source to be so available, or (2) arrange to deprive yourself of the benefit of the patent license for this particular work, or (3) arrange, in a manner consistent with the requirements of this License, to extend the patent license to downstream recipients. "Knowingly relying" means you have actual knowledge that, but for the patent license, your conveying the covered work in a country, or your recipient's use of the covered work in a country, would infringe one or more identifiable patents in that country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or arrangement, you convey, or propagate by procuring conveyance of, a covered work, and grant a patent license to some of the parties receiving the covered work authorizing them to use, propagate, modify or convey a specific copy of the covered work, then the patent license you grant is automatically extended to all recipients of the covered work and works based on it.
A patent license is "discriminatory" if it does not include within the scope of its coverage, prohibits the exercise of, or is conditioned on the non-exercise of one or more of the rights that are specifically granted under this License. You may not convey a covered work if you are a party to an arrangement with a third party that is in the business of distributing software, under which you make payment to the third party based on the extent of your activity of conveying the work, and under which the third party grants, to any of the parties who would receive the covered work from you, a discriminatory patent license (a) in connection with copies of the covered work conveyed by you (or copies made from those copies), or (b) primarily for and in connection with specific products or compilations that contain the covered work, unless you entered into that arrangement, or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting any implied license or other defenses to infringement that may otherwise be available to you under applicable patent law.
No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot convey a covered work so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not convey it at all. For example, if you agree to terms that obligate you to collect a royalty for further conveying from those to whom you convey the Program, the only way you could satisfy both those terms and this License would be to refrain entirely from conveying the Program.
Remote Network Interaction; Use with the GNU General Public License.
Notwithstanding any other provision of this License, if you modify the Program, your modified version must prominently offer all users interacting with it remotely through a computer network (if your version supports such interaction) an opportunity to receive the Corresponding Source of your version by providing access to the Corresponding Source from a network server at no charge, through some standard or customary means of facilitating copying of software. This Corresponding Source shall include the Corresponding Source for any work covered by version 3 of the GNU General Public License that is incorporated pursuant to the following paragraph.
Notwithstanding any other provision of this License, you have permission to link or combine any covered work with a work licensed under version 3 of the GNU General Public License into a single combined work, and to convey the resulting work. The terms of this License will continue to apply to the part which is the covered work, but the work with which it is combined will remain governed by version 3 of the GNU General Public License.
Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of the GNU Affero General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Program specifies that a certain numbered version of the GNU Affero General Public License "or any later version" applies to it, you have the option of following the terms and conditions either of that numbered version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of the GNU Affero General Public License, you may choose any version ever published by the Free Software Foundation.
If the Program specifies that a proxy can decide which future versions of the GNU Affero General Public License can be used, that proxy's public statement of acceptance of a version permanently authorizes you to choose that version for the Program.
Later license versions may give you additional or different permissions. However, no additional obligations are imposed on any author or copyright holder as a result of your choosing to follow a later version.
Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided above cannot be given local legal effect according to their terms, reviewing courts shall apply local law that most closely approximates an absolute waiver of all civil liability in connection with the Program, unless a warranty or assumption of liability accompanies a copy of the Program in return for a fee.
If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively state the exclusion of warranty; and each file should have at least the "copyright" line and a pointer to where the full notice is found.
Also add information on how to contact you by electronic and paper mail.
If your software can interact with users remotely through a computer network, you should also make sure that it provides a way for users to get its source. For example, if your program is a web application, its interface could display a "Source" link that leads users to an archive of the code. There are many ways you could offer source, and different solutions will be better for different programs; see section 13 for the specific requirements.
You should also get your employer (if you work as a programmer) or school, if any, to sign a "copyright disclaimer" for the program, if necessary. For more information on this, and how to apply and follow the GNU AGPL, see .
GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007 Preamble TERMS AND CONDITIONSa) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors. END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.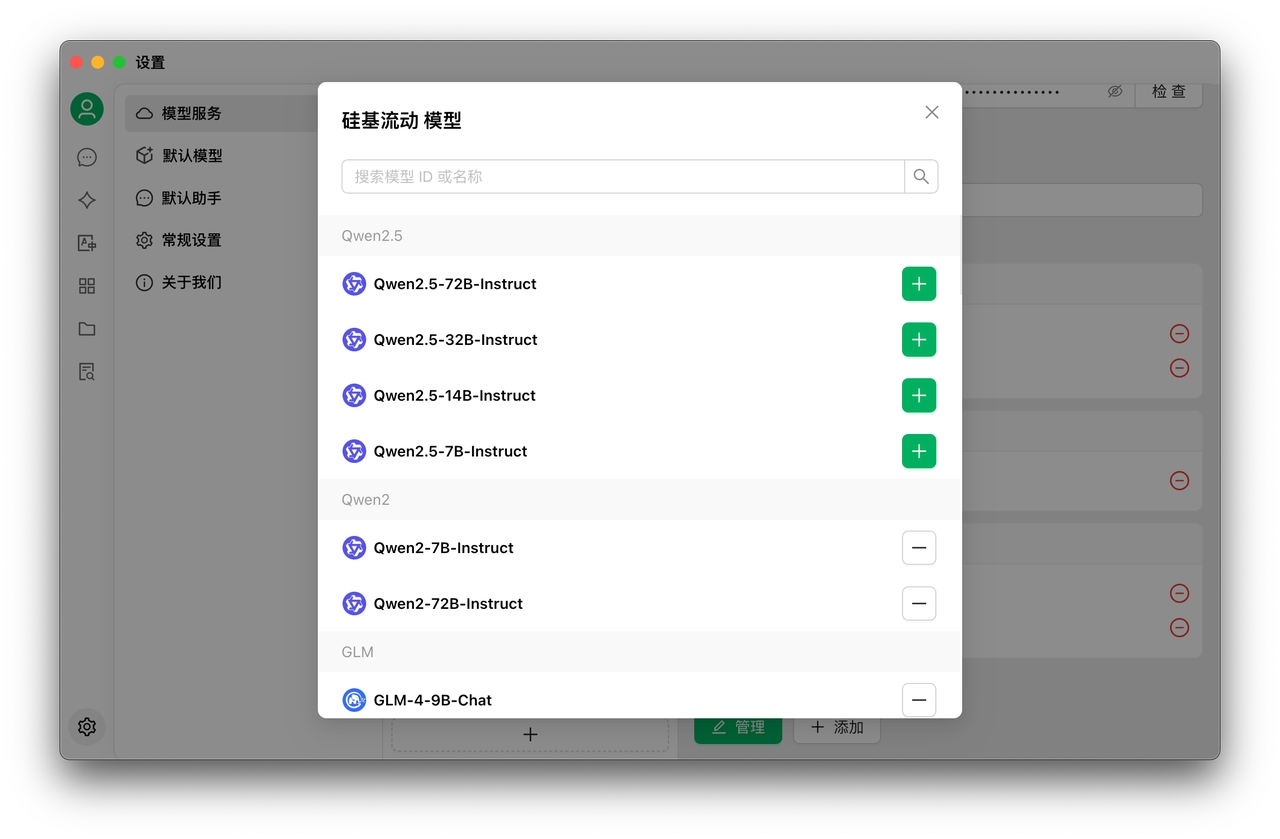
-
不支持
对话
360AI_360gpt
兼顾性能和效果的百亿级大模型,适合对性能/成本要求较高 的场景。
360gpt-turbo-responsibility-8k
8k
-
不支持
对话
360AI_360gpt
兼顾性能和效果的百亿级大模型,适合对性能/成本要求较高 的场景。
360gpt2-pro
8k
-
不支持
对话
360AI_360gpt
360智脑系列效果最好的主力千亿级大模型,广泛适用于各领域复杂任务场景。
claude-3-5-sonnet-20240620
200k
16k
不支持
对话,识图
Anthropic_claude
于2024年6月20日发布的快照版本,Claude 3.5 Sonnet是一个平衡了性能和速度的模型,在保持高速度的同时提供顶级性能,支持多模态输入。
claude-3-5-haiku-20241022
200k
16k
不支持
对话
Anthropic_claude
于2024年10月22日发布的快照版本,Claude 3.5 Haiku在各项技能上都有所提升,包括编码、工具使用和推理。作为Anthropic系列中速度最快的模型,它提供快速响应时间,适用于需要高互动性和低延迟的应用,如面向用户的聊天机器人和即时代码补全。它在数据提取和实时内容审核等专业任务中也表现出色,使其成为各行业广泛应用的多功能工具。它不支持图像输入。
claude-3-5-sonnet-20241022
200k
8K
不支持
对话,识图
Anthropic_claude
于2024年10月22日发布的快照版本,Claude 3.5 Sonnet 提供了超越 Opus 的能力和比 Sonnet 更快的速度,同时保持与 Sonnet 相同的价格。Sonnet 特别擅长编程、数据科学、视觉处理、代理任务。
claude-3-5-sonnet-latest
200K
8k
不支持
对话,识图
Anthropic_claude
动态指向最新的Claude 3.5 Sonnet版本,Claude 3.5 Sonnet提供了超越 Opus 的能力和比 Sonnet 更快的速度,同时保持与 Sonnet 相同的价格。Sonnet 特别擅长编程、数据科学、视觉处理、代理任务,该模型指向最新的版本。
claude-3-haiku-20240307
200k
4k
不支持
对话,识图
Anthropic_claude
Claude 3 Haiku 是 Anthropic 的最快且最紧凑的模型,旨在实现近乎即时的响应。它具有快速且准确的定向性能。
claude-3-opus-20240229
200k
4k
不支持
对话,识图
Anthropic_claude
Claude 3 Opus 是 Anthropic 用于处理高度复杂任务的最强大模型。它在性能、智能、流畅性和理解力方面表现卓越。
claude-3-sonnet-20240229
200k
8k
不支持
对话,识图
Anthropic_claude
于2024年2月29日发布的快照版本,Sonnet 特别擅长于: - 编码:能够自主编写、编辑和运行代码,并具备推理和故障排除能力 - 数据科学:增强人类的数据科学专业知识;在使用多种工具获取洞察时,能够处理非结构化数据 - 视觉处理:擅长解读图表、图形和图像,准确转录文本以获取超越文本本身的洞察 - 代理任务:工具使用出色,非常适合处理代理任务(即需要与其他系统交互的复杂多步骤问题解决任务)
google/gemma-2-27b-it
8k
-
不支持
对话
Google_gamma
Gemma 是由 Google 开发的轻量级、最先进的开放模型系列,采用与 Gemini 模型相同的研究和技术构建。这些模型是仅解码器的大型语言模型,支持英语,提供预训练和指令微调两种变体的开放权重。Gemma 模型适用于各种文本生成任务,包括问答、摘要和推理。
google/gemma-2-9b-it
8k
-
不支持
对话
Google_gamma
Gemma 是 Google 开发的轻量级、最先进的开放模型系列之一。它是一个仅解码器的大型语言模型,支持英语,提供开放权重、预训练变体和指令微调变体。Gemma 模型适用于各种文本生成任务,包括问答、摘要和推理。该 9B 模型是通过 8 万亿个 tokens 训练而成。
gemini-1.5-pro
2m
8k
不支持
对话
Google_gemini
Gemini 1.5 Pro 的最新稳定版本。作为一个强大的多模态模型,它可以处理长达6 万行代码或 2,000 页文本。特别适合需要复杂推理的任务。
gemini-1.0-pro-001
33k
8k
不支持
对话
Google_gemini
这是 Gemini 1.0 Pro 的稳定版本。作为一个 NLP 模型,它专门处理多轮文本和代码聊天以及代码生成等任务。该模型将于 2025 年 2 月 15 日停用,建议迁移到 1.5 系列模型。
gemini-1.0-pro-002
32k
8k
不支持
对话
Google_gemini
这是 Gemini 1.0 Pro 的稳定版本。作为一个 NLP 模型,它专门处理多轮文本和代码聊天以及代码生成等任务。该模型将于 2025 年 2 月 15 日停用,建议迁移到 1.5 系列模型。
gemini-1.0-pro-latest
33k
8k
不支持
对话,已废弃或即将废弃
Google_gemini
这是 Gemini 1.0 Pro 的最新版本。作为一个 NLP 模型,它专门处理多轮文本和代码聊天以及代码生成等任务。该模型将于 2025 年 2 月 15 日停用,建议迁移到 1.5 系列模型。
gemini-1.0-pro-vision-001
16k
2k
不支持
对话
Google_gemini
这是 Gemini 1.0 Pro 的视觉版本。该模型将于 2025 年 2 月 15 日停用,建议迁移到 1.5 系列模型。
gemini-1.0-pro-vision-latest
16k
2k
不支持
识图
Google_gemini
这是 Gemini 1.0 Pro 的视觉最新版本。该模型将于 2025 年 2 月 15 日停用,建议迁移到 1.5 系列模型。
gemini-1.5-flash
1m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Flash 的最新稳定版本。作为一个平衡的多模态模型,它可以处理音频、图片、视频和文本输入。
gemini-1.5-flash-001
1m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Flash 的稳定版本。它们提供与 gemini-1.5-flash 相同的基本功能,但版本固定,适合生产环境使用。
gemini-1.5-flash-002
1m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Flash 的稳定版本。它们提供与 gemini-1.5-flash 相同的基本功能,但版本固定,适合生产环境使用。
gemini-1.5-flash-8b
1m
8k
不支持
对话,识图
Google_gemini
Gemini 1.5 Flash-8B是谷歌最新推出的一款多模态人工智能模型,专为高效处理大规模任务而设计。该模型具有80亿个参数,能够支持文本、图像、音频和视频的输入,适用于多种应用场景,如聊天、转录和翻译等。与其他Gemini模型相比,Flash-8B在速度和成本效益上进行了优化,特别适合对成本敏感的用户。其速率限制提高了一倍,使得开发者能够更高效地进行大规模任务处理。此外,Flash-8B还采用了“知识蒸馏”技术,从更大的模型中提炼出关键知识,确保在保持核心能力的同时实现轻量化和高效化
gemini-1.5-flash-exp-0827
1m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Flash 的实验版本,会定期更新以包含最新的改进。适合探索性测试和原型开发,不建议用于生产环境。
gemini-1.5-flash-latest
1m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Flash 的尖端版本,会定期更新以包含最新的改进。适合探索性测试和原型开发,不建议用于生产环境。
gemini-1.5-pro-001
2m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Pro 的稳定版本,提供固定的模型行为和性能特征。适合需要稳定性的生产环境使用。
gemini-1.5-pro-002
2m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Pro 的稳定版本,提供固定的模型行为和性能特征。适合需要稳定性的生产环境使用。
gemini-1.5-pro-exp-0801
2m
8k
不支持
对话,识图
Google_gemini
Gemini 1.5 Pro 的试验版本。作为一个强大的多模态模型,它可以处理长达6 万行代码或 2,000 页文本。特别适合需要复杂推理的任务。
gemini-1.5-pro-exp-0827
2m
8k
不支持
对话,识图
Google_gemini
Gemini 1.5 Pro 的试验版本。作为一个强大的多模态模型,它可以处理长达6 万行代码或 2,000 页文本。特别适合需要复杂推理的任务。
gemini-1.5-pro-latest
2m
8k
不支持
对话,识图
Google_gemini
这是 Gemini 1.5 Pro 的最新版本,动态指向最新的快照版本
gemini-2.0-flash
1m
8k
不支持
对话,识图
Google_gemini
Gemini 2.0 Flash是谷歌最新推出的模型,相比1.5版本具有更快的首次生成速度(TTFT),同时保持了与Gemini Pro 1.5相当的质量水平;该模型在多模态理解、代码能力、复杂指令执行和函数调用等方面都有显著提升,从而能够提供更流畅和强大的智能体验。
gemini-2.0-flash-exp
100k
8k
支持
对话,识图
Google_gemini
Gemini 2.0 Flash 引入多模态实时API、改进速度和性能、提升质量、增强代理能力,并增加图像生成和语音转换功能。
gemini-2.0-flash-lite-preview-02-05
1M
8k
不支持
对话,识图
Google_gemini
Gemini 2.0 Flash-Lite是谷歌最新发布的高性价比AI模型,在保持与1.5 Flash相同速度的同时质量更好;支持100万tokens的上下文窗口,能够处理图像、音频和代码等多模态任务;作为目前谷歌成本效益最高的模型,采用简化的单一定价策略,特别适合需要控制成本的大规模应用场景。
gemini-2.0-flash-thinking-exp
40k
8k
不支持
对话,推理
Google_gemini
gemini-2.0-flash-thinking-exp是一个实验模型,它能生成在作出反应时所经历的 "思考过程"。因此,与基本的Gemini 2.0 Flash 模型相比,"思考模式 "的反应具有更强的推理能力。
gemini-2.0-flash-thinking-exp-01-21
1m
64k
不支持
对话,推理
Google_gemini
Gemini 2.0 Flash Thinking EXP-01-21 是谷歌最新推出的人工智能模型,专注于提升推理能力和用户交互体验。该模型具备强大的推理能力,尤其在数学和编程领域表现突出,并支持高达100万token的上下文窗口,适用于复杂任务和深入分析场景。其独特之处在于能够生成思考过程,提高AI思维的可理解性,同时支持原生代码执行,增强了交互的灵活性和实用性。通过优化算法,模型减少了逻辑矛盾,进一步提升了回答的准确性和一致性。
gemini-2.0-flash-thinking-exp-1219
40k
8k
不支持
对话,推理,识图
Google_gemini
gemini-2.0-flash-thinking-exp-1219是一个实验模型,它能生成在作出反应时所经历的 "思考过程"。因此,与基本的Gemini 2.0 Flash 模型相比,"思考模式 "的反应具有更强的推理能力。
gemini-2.0-pro-exp-01-28
2m
64k
不支持
对话,识图
Google_gemini
预加模型,还未上线
gemini-2.0-pro-exp-02-05
2m
8k
不支持
对话,识图
Google_gemini
Gemini 2.0 Pro Exp 02-05是谷歌2024年2月发布的最新实验性模型,在世界知识、代码生成和长文本理解方面表现突出;该模型支持200万tokens的超长上下文窗口,能处理2小时视频、22小时音频、6万多行代码和140万多单词的内容;作为Gemini 2.0系列的一部分,该模型采用了新的Flash Thinking训练策略,性能得到显著提升,在多个LLM评分榜单中名列前茅,展现了强大的综合能力。
gemini-exp-1114
8k
4k
不支持
对话,识图
Google_gemini
这是一个实验性模型,于 2024 年 11 月 14 日发布,主要关注质量改进。
gemini-exp-1121
8k
4k
不支持
对话,识图,代码
Google_gemini
这是一个实验性模型,于 2024 年 11 月 21 日发布,改进了编码、推理和视觉能力。
gemini-exp-1206
8k
4k
不支持
对话,识图
Google_gemini
这是一个实验性模型,于 2024 年 12 月 6 日发布,改进了编码、推理和视觉能力。
gemini-exp-latest
8k
4k
不支持
对话,识图
Google_gemini
这是一个实验性模型,动态指向最新版本
gemini-pro
33k
8k
不支持
对话
Google_gemini
同gemini-1.0-pro,是gemini-1.0-pro的别名
gemini-pro-vision
16k
2k
不支持
对话,识图
Google_gemini
这是 Gemini 1.0 Pro 的视觉版本。该模型将于 2025 年 2 月 15 日停用,建议迁移到 1.5 系列模型。
grok-2
128k
-
不支持
对话
Grok_grok
X.ai于2024.12.12发布的新版本grok模型.
grok-2-1212
128k
-
不支持
对话
Grok_grok
X.ai于2024.12.12发布的新版本grok模型.
grok-2-latest
128k
-
不支持
对话
Grok_grok
X.ai于2024.12.12发布的新版本grok模型.
grok-2-vision-1212
32k
-
不支持
对话,识图
Grok_grok
X.ai于2024.12.12发布的grok视觉版本模型.
grok-beta
100k
-
不支持
对话
Grok_grok
性能与 Grok 2 相当,但效率、速度和功能有所提高。
grok-vision-beta
8k
-
不支持
对话,识图
Grok_grok
最新的图像理解模型可以处理各种视觉信息,包括文档、图表、截图和照片。
internlm/internlm2_5-20b-chat
32k
-
支持
对话
internlm
InternLM2.5-20B-Chat 是一个开源的大规模对话模型,基于 InternLM2 架构开发。该模型拥有 200 亿参数,在数学推理方面表现出色,超越了同量级的 Llama3 和 Gemma2-27B 模型。InternLM2.5-20B-Chat 在工具调用能力方面有显著提升,支持从上百个网页收集信息进行分析推理,并具备更强的指令理解、工具选择和结果反思能力。
meta-llama/Llama-3.2-11B-Vision-Instruct
8k
-
不支持
对话,识图
Meta_llama
目前Llama系列模型不仅能够处理文本数据,还能够处理图像数据;Llama3.2的部分模型加入了视觉理解的功能,该模型支持同时输入文本和图像数据,对图像进行理解并输出文本信息。
meta-llama/Llama-3.2-3B-Instruct
32k
-
不支持
对话
Meta_llama
Meta Llama 3.2多语言大语言模型(LLM),其中1B、3B是可在边缘和移动设备上的运行的轻量级模型,本模型为3B版本。
meta-llama/Llama-3.2-90B-Vision-Instruct
8k
-
不支持
对话,识图
Meta_llama
目前Llama系列模型不仅能够处理文本数据,还能够处理图像数据;Llama3.2的部分模型加入了视觉理解的功能,该模型支持同时输入文本和图像数据,对图像进行理解并输出文本信息。
meta-llama/Llama-3.3-70B-Instruct
131k
-
不支持
对话
Meta_llama
Meta 的最新款 70B LLM,性能与 llama 3.1 405B 相当。
meta-llama/Meta-Llama-3.1-405B-Instruct
32k
-
不支持
对话
Meta_llama
Meta Llama 3.1多语言大语言模型(LLM)集合是8B、70B和405B尺寸的预训练和指令微调生成模型的集合,本模型为405B版本。Llama 3.1指令微调文本模型(8B、70B、405B)针对多语言对话进行了优化,在常见的行业基准上优于许多可用的开源和闭源聊天模型。
meta-llama/Meta-Llama-3.1-70B-Instruct
32k
-
不支持
对话
Meta_llama
Meta Llama 3.1 是由 Meta 开发的多语言大型语言模型家族,包括 8B、70B 和 405B 三种参数规模的预训练和指令微调变体。该 70B 指令微调模型针对多语言对话场景进行了优化,在多项行业基准测试中表现优异。模型训练使用了超过 15 万亿个 tokens 的公开数据,并采用了监督微调和人类反馈强化学习等技术来提升模型的有用性和安全性。
meta-llama/Meta-Llama-3.1-8B-Instruct
32k
-
不支持
对话
Meta_llama
Meta Llama 3.1多语言大语言模型(LLM)集合是8B、70B和405B尺寸的预训练和指令微调生成模型的集合,本模型为8B版本。Llama 3.1指令微调文本模型(8B、70B、405B)针对多语言对话进行了优化,在常见的行业基准上优于许多可用的开源和闭源聊天模型。
abab5.5-chat
16k
-
支持
对话
Minimax_abab
中文人设对话场景
abab5.5s-chat
8k
-
支持
对话
Minimax_abab
中文人设对话场景
abab6.5g-chat
8k
-
支持
对话
Minimax_abab
英文等多语种人设对话场景
abab6.5s-chat
245k
-
支持
对话
Minimax_abab
通用场景
abab6.5t-chat
8k
-
支持
对话
Minimax_abab
中文人设对话场景
chatgpt-4o-latest
128k
16k
不支持
对话,识图
OpenAI
chatgpt-4o-latest 模型版本持续指向 ChatGPT 中使用的 GPT-4o 版本,并在有重大变化时最快更新。
gpt-4o-2024-11-20
128k
16k
支持
对话
OpenAI
2024 年 11 月 20 日的最新 gpt-4o 快照版本。
gpt-4o-audio-preview
128k
16k
不支持
对话
OpenAI
OpenAI的实时语音对话模型
gpt-4o-audio-preview-2024-10-01
128k
16k
支持
对话
OpenAI
OpenAI的实时语音对话模型
o1
128k
32k
不支持
对话,推理,识图
OpenAI
OpenAI针对复杂任务的新推理模型,该任务需要广泛的常识。该模型具有 200k 上下文,目前全球最强模型,支持图片识别
o1-mini-2024-09-12
128k
64k
不支持
对话,推理
OpenAI
o1-mini的固定快照版本,比 o1-preview 更小、更快,成本低80%,在代码生成和小上下文操作方面表现良好。
o1-preview-2024-09-12
128k
32k
不支持
对话,推理
OpenAI
o1-preview的固定快照版本
gpt-3.5-turbo
16k
4k
支持
对话
OpenAI_gpt-3
基于 GPT-3.5: GPT-3.5 Turbo 是建立在 GPT-3.5 模型基础上的改进版本,由 OpenAI 开发。 性能目标: 设计目的是通过优化模型结构和算法,提高模型的推理速度、处理效率和资源利用率。 提升的推理速度: 相对于 GPT-3.5,GPT-3.5 Turbo 在相同硬件条件下通常能够提供更快的推理速度,这对于需要大规模文本处理的应用特别有益。 更高的吞吐量: 在处理大量请求或数据时,GPT-3.5 Turbo 可以实现更高的并发处理能力,从而提升整体的系统吞吐量。 优化的资源消耗: 在保持性能的同时,可能降低了对硬件资源(如内存和计算资源)的需求,这有助于降低运行成本和提高系统的可扩展性。 广泛的自然语言处理任务: GPT-3.5 Turbo 适用于多种自然语言处理任务,包括但不限于文本生成、语义理解、对话系统、机器翻译等。 开发者工具和API支持: 提供了便于开发者集成和使用的 API 接口,支持快速开发和部署应用程序。
gpt-3.5-turbo-0125
16k
4k
支持
对话
OpenAI_gpt-3
更新后的 GPT 3.5 Turbo,响应请求格式的准确性更高,并修复了一个导致非英语语言函数调用文本编码问题的错误。返回最多 4,096 个输出令牌。
gpt-3.5-turbo-0613
16k
4k
支持
对话
OpenAI_gpt-3
更新后的 GPT 3.5 Turbo固定快照版本。目前已弃用
gpt-3.5-turbo-1106
16k
4k
支持
对话
OpenAI_gpt-3
具有改进的指令跟随、JSON 模式、可重现输出、并行函数调用等。返回最多 4,096 个输出令牌。
gpt-3.5-turbo-16k
16k
4k
支持
对话,已废弃或即将废弃
OpenAI_gpt-3
(已弃用)
gpt-3.5-turbo-16k-0613
16k
4k
支持
对话,已废弃或即将废弃
OpenAI_gpt-3
gpt-3.5-turbo 于 2023年6月13日的快照。(已弃用)
gpt-3.5-turbo-instruct
4k
4k
支持
对话
OpenAI_gpt-3
与 GPT-3 时代模型类似的能力。与遗留 Completions 端点兼容,不适用于 Chat Completions。
gpt-3.5o
16k
4k
不支持
对话
OpenAI_gpt-3
同gpt-4o-lite
gpt-4
8k
8k
支持
对话
OpenAI_gpt-4
目前指向 gpt-4-0613。
gpt-4-0125-preview
128k
4k
支持
对话
OpenAI_gpt-4
最新的 GPT-4 模型,旨在减少“懒惰”情况,即模型未完成任务。返回最多 4,096 个输出令牌。
gpt-4-0314
8k
8k
支持
对话
OpenAI_gpt-4
gpt-4 2023年3月14日的快照
gpt-4-0613
8k
8k
支持
对话
OpenAI_gpt-4
gpt-4 2023年6月13日的快照,增强了函数调用支持。
gpt-4-1106-preview
128k
4k
支持
对话
OpenAI_gpt-4
GPT-4 Turbo 模型,具有改进的指令跟随、JSON 模式、可再现输出、函数调用等。返回最多 4,096 个输出令牌。这是预览模型。
gpt-4-32k
32k
4k
支持
对话
OpenAI_gpt-4
gpt-4-32k将于2025-06-06弃用。
gpt-4-32k-0613
32k
4k
支持
对话,已废弃或即将废弃
OpenAI_gpt-4
将于2025-06-06弃用。
gpt-4-turbo
128k
4k
支持
对话
OpenAI_gpt-4
最新版的 GPT-4 Turbo 模型新增了视觉功能,支持通过 JSON 模式和函数调用来处理视觉请求。该模型当前版本为 gpt-4-turbo-2024-04-09。
gpt-4-turbo-2024-04-09
128k
4k
支持
对话
OpenAI_gpt-4
带视觉功能的 GPT-4 Turbo 模型。现在,视觉请求能够通过 JSON 模式和函数调用来实现。gpt-4-turbo 目前版本就是这一版。
gpt-4-turbo-preview
128k
4k
支持
对话,识图
OpenAI_gpt-4
目前指向 gpt-4-0125-preview。
gpt-4o
128k
16k
支持
对话,识图
OpenAI_gpt-4
OpenAI的高智能旗舰模型,适用于复杂的多步骤任务。GPT-4o 比 GPT-4 Turbo 更便宜、更快速。
gpt-4o-2024-05-13
128k
4k
支持
对话,识图
OpenAI_gpt-4
2024 年 5 月 13 日的原始 gpt-4o 快照。
gpt-4o-2024-08-06
128k
16k
支持
对话,识图
OpenAI_gpt-4
支持结构化输出的第一个快照。gpt-4o目前指向此版本。
gpt-4o-mini
128k
16k
支持
对话,识图
OpenAI_gpt-4
OpenAI经济实惠的gpt-4o版本,适用于快速、轻量级任务。GPT-4o mini 比 GPT-3.5 Turbo 更便宜,功能更强大。目前指向 gpt-4o-mini-2024-07-18。
gpt-4o-mini-2024-07-18
128k
16k
支持
对话,识图
OpenAI_gpt-4
gpt-4o-mini的固定快照版本。
gpt-4o-realtime-preview
128k
4k
支持
对话,实时语音
OpenAI_gpt-4
OpenAI的实时语音对话模型
gpt-4o-realtime-preview-2024-10-01
128k
4k
支持
对话,实时语音,识图
OpenAI_gpt-4
gpt-4o-realtime-preview当前指向这个快照版本
o1-mini
128k
64k
不支持
对话,推理
OpenAI_o1
比 o1-preview 更小、更快,成本低80%,在代码生成和小上下文操作方面表现良好。
o1-preview
128k
32k
不支持
对话,推理
OpenAI_o1
o1-preview 是针对需要广泛常识的复杂任务的新推理模型。该模型具有 128K 上下文和 2023 年 10 月的知识截止点。专注于高级推理和解决复杂问题,包括数学和科学任务。非常适合需要深度上下文理解和自主工作流程的应用。
o3-mini
200k
100k
支持
对话,推理
OpenAI_o1
o3-mini是OpenAI最新的小型推理模型,在保持与o1-mini相同成本和延迟的情况下提供高智能,专注于科学、数学和编码任务,支持结构化输出、函数调用、批量API等开发者功能,且知识库截止到2023年10月,展现了在推理能力和经济性方面的显著平衡。
o3-mini-2025-01-31
200k
100k
支持
对话,推理
OpenAI_o1
o3-mini当前指向该版本,o3-mini-2025-01-31是OpenAI最新的小型推理模型,在保持与o1-mini相同成本和延迟的情况下提供高智能,专注于科学、数学和编码任务,支持结构化输出、函数调用、批量API等开发者功能,且知识库截止到2023年10月,展现了在推理能力和经济性方面的显著平衡。
Baichuan2-Turbo
32k
-
不支持
对话
百川_baichuan
相对业界同等尺寸模型,模型效果在保持行业领先的同时,实现了价格的大幅度降低
Baichuan3-Turbo
32k
-
不支持
对话
百川_baichuan
相对业界同等尺寸模型,模型效果在保持行业领先的同时,实现了价格的大幅度降低
Baichuan3-Turbo-128k
128k
-
不支持
对话
百川_baichuan
百川模型通过128k超长上下文窗口处理复杂文本,针对金融等行业进行专门优化,同时在保持高性能的前提下大幅降低成本,为企业提供高性价比的解决方案。
Baichuan4
32k
-
不支持
对话
百川_baichuan
百川的MoE模型通过专门优化、降低成本和提升性能,在企业应用中提供了高效性价比的解决方案。
Baichuan4-Air
32k
-
不支持
对话
百川_baichuan
百川的MoE模型通过专门优化、降低成本和提升性能,在企业应用中提供了高效性价比的解决方案。
Baichuan4-Turbo
32k
-
不支持
对话
百川_baichuan
基于海量优质的场景数据训练,企业高频场景可用性相对Baichuan4提升10%+,信息摘要提升50%,多语言提升31%,内容生成提升13% 针对推理性能专项优化,首token响应速度相对Baichuan4提升51%,token流速提升73%
ERNIE-3.5-128K
128k
4k
支持
对话
百度_ernie
百度自研的旗舰级大规模⼤语⾔模型,覆盖海量中英文语料,具有强大的通用能力,可满足绝大部分对话问答、创作生成、插件应用场景要求;支持自动对接百度搜索插件,保障问答信息时效。
ERNIE-3.5-8K
8k
1k
支持
对话
百度_ernie
百度自研的旗舰级大规模⼤语⾔模型,覆盖海量中英文语料,具有强大的通用能力,可满足绝大部分对话问答、创作生成、插件应用场景要求;支持自动对接百度搜索插件,保障问答信息时效。
ERNIE-3.5-8K-Preview
8k
1k
支持
对话
百度_ernie
百度自研的旗舰级大规模⼤语⾔模型,覆盖海量中英文语料,具有强大的通用能力,可满足绝大部分对话问答、创作生成、插件应用场景要求;支持自动对接百度搜索插件,保障问答信息时效。
ERNIE-4.0-8K
8k
1k
支持
对话
百度_ernie
百度自研的旗舰级超大规模⼤语⾔模型,相较ERNIE 3.5实现了模型能力全面升级,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效。
ERNIE-4.0-8K-Latest
8k
2k
支持
对话
百度_ernie
ERNIE-4.0-8K-Latest相比ERNIE-4.0-8K能力全面提升,其中角色扮演能力和指令遵循能力提升较大;相较ERNIE 3.5实现了模型能力全面升级,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效,支持5K tokens输入+2K tokens输出。本文介绍了ERNIE-4.0-8K-Latest接口调用方法。
ERNIE-4.0-8K-Preview
8k
1k
支持
对话
百度_ernie
百度自研的旗舰级超大规模⼤语⾔模型,相较ERNIE 3.5实现了模型能力全面升级,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效。
ERNIE-4.0-Turbo-128K
128k
4k
支持
对话
百度_ernie
ERNIE 4.0 Turbo是百度自研的旗舰级超大规模⼤语⾔模型,综合效果表现出色,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效。相较于ERNIE 4.0在性能表现上更优秀。ERNIE-4.0-Turbo-128K是模型的一个版本,长文档整体效果优于ERNIE-3.5-128K。本文介绍了相关API及使用。
ERNIE-4.0-Turbo-8K
8k
2k
支持
对话
百度_ernie
ERNIE 4.0 Turbo是百度自研的旗舰级超大规模⼤语⾔模型,综合效果表现出色,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效。相较于ERNIE 4.0在性能表现上更优秀。ERNIE-4.0-Turbo-8K是模型的一个版本。本文介绍了相关API及使用。
ERNIE-4.0-Turbo-8K-Latest
8k
2k
支持
对话
百度_ernie
ERNIE 4.0 Turbo是百度自研的旗舰级超大规模⼤语⾔模型,综合效果表现出色,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效。相较于ERNIE 4.0在性能表现上更优秀。ERNIE-4.0-Turbo-8K是模型的一个版本。
ERNIE-4.0-Turbo-8K-Preview
8k
2k
支持
对话
百度_ernie
ERNIE 4.0 Turbo是百度自研的旗舰级超大规模⼤语⾔模型,综合效果表现出色,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效。ERNIE-4.0-Turbo-8K-Preview是模型的一个版本
ERNIE-Character-8K
8k
1k
不支持
对话
百度_ernie
百度自研的垂直场景大语言模型,适合游戏NPC、客服对话、对话角色扮演等应用场景,人设风格更为鲜明、一致,指令遵循能力更强,推理性能更优
ERNIE-Lite-8K
8k
4k
不支持
对话
百度_ernie
百度自研的轻量级大语言模型,兼顾优异的模型效果与推理性能,适合低算力AI加速卡推理使用。
ERNIE-Lite-Pro-128K
128k
2k
支持
对话
百度_ernie
百度自研的轻量级大语言模型,效果比ERNIE Lite更优,兼顾优异的模型效果与推理性能,适合低算力AI加速卡推理使用。ERNIE-Lite-Pro-128K支持128K上下文长度,效果比ERNIE-Lite-128K更优。
ERNIE-Novel-8K
8k
2k
不支持
对话
百度_ernie
ERNIE-Novel-8K是百度自研通用大语言模型,在小说续写能力上有明显优势,也可用在短剧、电影等场景。
ERNIE-Speed-128K
128k
4k
不支持
对话
百度_ernie
百度2024年最新发布的自研高性能大语言模型,通用能力优异,适合作为基座模型进行精调,更好地处理特定场景问题,同时具备极佳的推理性能。
ERNIE-Speed-8K
8k
1k
不支持
对话
百度_ernie
百度2024年最新发布的自研高性能大语言模型,通用能力优异,适合作为基座模型进行精调,更好地处理特定场景问题,同时具备极佳的推理性能。
ERNIE-Speed-Pro-128K
128k
4k
不支持
对话
百度_ernie
ERNIE Speed Pro是百度2024年最新发布的自研高性能大语言模型,通用能力优异,适合作为基座模型进行精调,更好地处理特定场景问题,同时具备极佳的推理性能。ERNIE-Speed-Pro-128K是2024年8月30日发布的初始版本,支持128K上下文长度,效果比ERNIE-Speed-128K更优。
ERNIE-Tiny-8K
8k
1k
不支持
对话
百度_ernie
百度自研的超高性能大语言模型,部署与精调成本在文心系列模型中最低。
Doubao-1.5-lite-32k
32k
12k
支持
对话
豆包_doubao
Doubao1.5-lite在轻量版语言模型中也处于全球一流水平,在综合(MMLU_pro)、推理(BBH)、数学(MATH)、专业知识(GPQA)权威测评指标持平或超越GPT-4omini,Cluade 3.5 Haiku。
Doubao-1.5-pro-256k
256k
12k
支持
对话
豆包_doubao
Doubao-1.5-Pro-256k,基于Doubao-1.5-Pro全面升级版。相比Doubao-pro-256k/241115,整体效果大幅提升10%。输出长度大幅提升,支持最大12k tokens。
Doubao-1.5-pro-32k
32k
12k
支持
对话
豆包_doubao
Doubao-1.5-pro,全新一代主力模型,性能全面升级,在知识、代码、推理、等方面表现卓越。在多项公开测评基准上达到全球领先水平,特别在知识、代码、推理、中文权威测评基准上获得最佳成绩,综合得分优于GPT4o、Claude 3.5 Sonnet等业界一流模型。
Doubao-1.5-vision-pro
32k
12k
不支持
对话,识图
豆包_doubao
Doubao-1.5-vision-pro,全新升级的多模态大模型,支持任意分辨率和极端长宽比图像识别,增强视觉推理、文档识别、细节信息理解和指令遵循能力。
Doubao-embedding
4k
-
支持
嵌入
豆包_doubao
Doubao-embedding 是一款由字节跳动研发的语义向量化模型,主要面向向量检索的使用场景,支持中、英双语,最长 4K 上下文长度。目前提供以下版本: text-240715:最高维度向量 2560,支持 512、1024、2048 降维使用。中英文 Retrieval效果较 text-240515 版本有较大提升,推荐使用该版本。 text-240515:最高维度向量 2048,支持 512、1024 降维使用。
Doubao-embedding-large
4k
-
不支持
嵌入
豆包_doubao
中英文Retrieval效果较Doubao-embedding/text-240715版本显著提升
Doubao-embedding-vision
8k
-
不支持
嵌入
豆包_doubao
Doubao-embedding-vision,全新升级图文多模态向量化模型,主要面向图文多模向量检索的使用场景,支持图片输入及中、英双语文本输入,最长 8K 上下文长度。
Doubao-lite-128k
128k
4k
支持
对话
豆包_doubao
Doubao-lite 拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持128k上下文窗口的推理和精调。
Doubao-lite-32k
32k
4k
支持
对话
豆包_doubao
Doubao-lite拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持32k上下文窗口的推理和精调。
Doubao-lite-4k
4k
4k
支持
对话
豆包_doubao
Doubao-lite拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持4k上下文窗口的推理和精调。
Doubao-pro-128k
128k
4k
支持
对话
豆包_doubao
效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持128k上下文窗口的推理和精调。
Doubao-pro-32k
32k
4k
支持
对话
豆包_doubao
效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持32k上下文窗口的推理和精调。
Doubao-pro-4k
4k
4k
支持
对话
豆包_doubao
效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持4k上下文窗口的推理和精调。
step-1-128k
128k
-
支持
对话
阶跃星辰
step-1-128k模型是一个超大规模的语言模型,能够处理高达128,000个token的输入。这种能力使其在生成长篇内容和进行复杂推理时具有显著优势,适合用于创作小说、剧本等需要丰富上下文的应用。
step-1-256k
256k
-
支持
对话
阶跃星辰
step-1-256k模型是目前最大的语言模型之一,支持256,000个token的输入。它的设计旨在满足极端复杂的任务需求,如大规模数据分析和多轮对话系统,能够在多种领域中提供高质量的输出。
step-1-32k
32k
-
支持
对话
阶跃星辰
step-1-32k模型扩展了上下文窗口,支持32,000个token的输入。这使得它在处理长篇文章和复杂对话时表现出色,适合需要深入理解和分析的任务,如法律文书和学术研究。
step-1-8k
8k
-
支持
对话
阶跃星辰
step-1-8k模型是一个高效的语言模型,专为处理较短文本而设计。它能够在8,000个token的上下文中进行推理,适合需要快速响应的应用场景,如聊天机器人和实时翻译。
step-1-flash
8k
-
支持
对话
阶跃星辰
step-1-flash模型专注于快速响应和高效处理,适合实时应用。它的设计使得在有限的计算资源下仍能提供优质的语言理解和生成能力,适合移动设备和边缘计算场景。
step-1.5v-mini
32k
-
支持
对话,识图
阶跃星辰
step-1.5v-mini模型是一个轻量级版本,旨在在资源受限的环境中运行。尽管体积小,但它仍然保留了良好的语言处理能力,适合嵌入式系统和低功耗设备。
step-1v-32k
32k
-
支持
对话,识图
阶跃星辰
step-1v-32k模型支持32,000个token的输入,适合需要更长上下文的应用。它在处理复杂对话和长文本时表现出色,适合客户服务和内容创作等领域。
step-1v-8k
8k
-
支持
对话,识图
阶跃星辰
step-1v-8k模型是一个优化的版本,专为8,000个token的输入设计,适合快速生成和处理短文本。它在速度和准确性之间取得了良好的平衡,适合实时应用。
step-2-16k
16k
-
支持
对话
阶跃星辰
step-2-16k模型是一个中等规模的语言模型,支持16,000个token的输入。它在多种任务中表现良好,适合教育、培训和知识管理等应用场景。
yi-lightning
16k
-
支持
对话
零一万物_yi
最新高性能模型,保证高质量输出同时,推理速度大幅提升。 适用于实时交互,高复杂推理场景,极高的性价比能够为商业产品提供极好的产品支撑。
yi-vision-v2
16K
-
支持
对话,识图
零一万物_yi
适合需要分析和解释图像、图表的场景,如图片问答、图表理解、OCR、视觉推理、教育、研究报告理解或多语种文档阅读等。
qwen-14b-chat
8k
2k
支持
对话
千问_qwen
阿里云官方的通义千问-开源版。
qwen-72b-chat
32k
2k
支持
对话
千问_qwen
阿里云官方的通义千问-开源版。
qwen-7b-chat
7.5k
1.5k
支持
对话
千问_qwen
阿里云官方的通义千问-开源版。
qwen-coder-plus
128k
8k
支持
对话,代码
千问_qwen
Qwen-Coder-Plus是Qwen系列中的一款编程专用模型,旨在提升代码生成和理解能力。该模型通过大规模的编程数据训练,能够处理多种编程语言,支持代码补全、错误检测和代码重构等功能。其设计目标是为开发者提供更高效的编程辅助,提升开发效率。
qwen-coder-plus-latest
128k
8k
支持
对话,代码
千问_qwen
Qwen-Coder-Plus-Latest是Qwen-Coder-Plus的最新版本,包含了最新的算法优化和数据集更新。该模型在性能上有显著提升,能够更准确地理解上下文,生成更符合开发者需求的代码。它还引入了更多的编程语言支持,增强了多语言编程的能力。
qwen-coder-turbo
128k
8k
支持
对话,代码
千问_qwen
通义千问系列代码及编程模型是专门用于编程和代码生成的语言模型,推理速度快,成本低。该版本始终指向最新稳定版快照
qwen-coder-turbo-latest
128k
8k
支持
对话,代码
千问_qwen
通义千问系列代码及编程模型是专门用于编程和代码生成的语言模型,推理速度快,成本低。该版本始终指向最新版快照
qwen-long
10m
6k
支持
对话
千问_qwen
Qwen-Long是在通义千问针对超长上下文处理场景的大语言模型,支持中文、英文等不同语言输入,支持最长1000万tokens(约1500万字或1.5万页文档)的超长上下文对话。配合同步上线的文档服务,可支持word、pdf、markdown、epub、mobi等多种文档格式的解析和对话。 说明:通过HTTP直接提交请求,支持1M tokens长度,超过此长度建议通过文件方式提交。
qwen-math-plus
4k
3k
支持
对话
千问_qwen
Qwen-Math-Plus是专注于数学问题解决的模型,旨在提供高效的数学推理和计算能力。该模型通过大量的数学题库进行训练,能够处理复杂的数学表达式和问题,支持从基础算术到高等数学的多种计算需求。其应用场景包括教育、科研和工程等领域。
qwen-math-plus-latest
4k
3k
支持
对话
千问_qwen
Qwen-Math-Plus-Latest是Qwen-Math-Plus的最新版本,集成了最新的数学推理技术和算法改进。该模型在处理复杂数学问题时表现更为出色,能够提供更准确的解答和推理过程。它还扩展了对数学符号和公式的理解能力,适用于更广泛的数学应用场景。
qwen-math-turbo
4k
3k
支持
对话
千问_qwen
Qwen-Math-Turbo是一个高性能的数学模型,专为快速计算和实时推理而设计。该模型优化了计算速度,能够在极短的时间内处理大量数学问题,适合需要快速反馈的应用场景,如在线教育和实时数据分析。其高效的算法使得用户能够在复杂计算中获得即时结果。
qwen-math-turbo-latest
4k
3k
支持
对话
千问_qwen
Qwen-Math-Turbo-Latest是Qwen-Math-Turbo的最新版本,进一步提升了计算效率和准确性。该模型在算法上进行了多项优化,能够处理更复杂的数学问题,并在实时推理中保持高效性。它适合用于需要快速响应的数学应用,如金融分析和科学计算。
qwen-max
32k
8k
支持
对话
千问_qwen
通义千问2.5系列千亿级别超大规模语言模型,支持中文、英文等不同语言输入。随着模型的升级,qwen-max将滚动更新升级。
qwen-max-latest
32k
8k
支持
对话
千问_qwen
通义千问系列效果最好的模型,本模型是动态更新版本,模型更新不会提前通知,适合复杂、多步骤的任务,模型中英文综合能力显著提升,模型人类偏好显著提升,模型推理能力和复杂指令理解能力显著增强,困难任务上的表现更优,数学、代码能力显著提升,提升对Table、JSON等结构化数据的理解和生成能力。
qwen-plus
128k
8k
支持
对话
千问_qwen
通义千问系列能力均衡的模型,推理效果和速度介于通义千问-Max和通义千问-Turbo之间,适合中等复杂任务。模型中英文综合能力显著提升,模型人类偏好显著提升,模型推理能力和复杂指令理解能力显著增强,困难任务上的表现更优,数学、代码能力显著提升。
qwen-plus-latest
128k
8k
支持
对话
千问_qwen
Qwen-Plus是通义千问系列中的增强版视觉语言模型,旨在提升细节识别能力和文字识别能力。该模型支持超百万像素分辨率和任意长宽比规格的图像,能够在多种视觉语言任务中表现出色,适合需要高精度图像理解的应用场景。
qwen-turbo
128k
8k
支持
对话
千问_qwen
通义千问系列速度最快、成本很低的模型,适合简单任务。模型中英文综合能力显著提升,模型人类偏好显著提升,模型推理能力和复杂指令理解能力显著增强,困难任务上的表现更优,数学、代码能力显著提升。
qwen-turbo-latest
1m
8k
支持
对话
千问_qwen
Qwen-Turbo是为简单任务设计的高效模型,强调速度和成本效益。它在处理基本的视觉语言任务时表现出色,适合对响应时间有严格要求的应用,如实时图像识别和简单的问答系统。
qwen-vl-max
32k
2k
支持
对话
千问_qwen
通义千问VL-Max(qwen-vl-max),即通义千问超大规模视觉语言模型。相比增强版,再次提升视觉推理能力和指令遵循能力,提供更高的视觉感知和认知水平。在更多复杂任务上提供最佳的性能。
qwen-vl-max-latest
32k
2k
支持
对话,识图
千问_qwen
Qwen-VL-Max是Qwen-VL系列中的最高级版本,专为解决复杂的多模态任务而设计。它结合了先进的视觉和语言处理技术,能够理解和分析高分辨率图像,推理能力极强,适合需要深度理解和复杂推理的应用场景。
qwen-vl-ocr
34k
4k
支持
对话,识图
千问_qwen
只支持ocr,不支持对话。
qwen-vl-ocr-latest
34k
4k
支持
对话,识图
千问_qwen
只支持ocr,不支持对话。
qwen-vl-plus
8k
2k
支持
对话,识图
千问_qwen
通义千问VL-Plus(qwen-vl-plus),即通义千问大规模视觉语言模型增强版。大幅提升细节识别能力和文字识别能力,支持超百万像素分辨率和任意长宽比规格的图像。在广泛的视觉任务上提供卓越的性能。
qwen-vl-plus-latest
32k
2k
支持
对话,识图
千问_qwen
Qwen-VL-Plus-Latest是Qwen-VL-Plus的最新版本,增强了模型的多模态理解能力。它在图像和文本的结合处理上表现出色,适合需要高效处理多种输入格式的应用,如智能客服和内容生成。
Qwen/Qwen2-1.5B-Instruct
32k
6k
不支持
对话
千问_qwen
Qwen2-1.5B-Instruct 是 Qwen2 系列中的指令微调大语言模型,参数规模为 1.5B。该模型基于 Transformer 架构,采用了 SwiGLU 激活函数、注意力 QKV 偏置和组查询注意力等技术。它在语言理解、生成、多语言能力、编码、数学和推理等多个基准测试中表现出色,超越了大多数开源模型。
Qwen/Qwen2-72B-Instruct
128k
6k
不支持
对话
千问_qwen
Qwen2-72B-Instruct 是 Qwen2 系列中的指令微调大语言模型,参数规模为 72B。该模型基于 Transformer 架构,采用了 SwiGLU 激活函数、注意力 QKV 偏置和组查询注意力等技术。它能够处理大规模输入。该模型在语言理解、生成、多语言能力、编码、数学和推理等多个基准测试中表现出色,超越了大多数开源模型
Qwen/Qwen2-7B-Instruct
128k
6k
不支持
对话
千问_qwen
Qwen2-7B-Instruct 是 Qwen2 系列中的指令微调大语言模型,参数规模为 7B。该模型基于 Transformer 架构,采用了 SwiGLU 激活函数、注意力 QKV 偏置和组查询注意力等技术。它能够处理大规模输入。该模型在语言理解、生成、多语言能力、编码、数学和推理等多个基准测试中表现出色,超越了大多数开源模型
Qwen/Qwen2-VL-72B-Instruct
32k
2k
不支持
对话
千问_qwen
Qwen2-VL 是 Qwen-VL 模型的最新迭代版本,在视觉理解基准测试中达到了最先进的性能,包括 MathVista、DocVQA、RealWorldQA 和 MTVQA 等。Qwen2-VL 能够理解超过 20 分钟的视频,用于高质量的基于视频的问答、对话和内容创作。它还具备复杂推理和决策能力,可以与移动设备、机器人等集成,基于视觉环境和文本指令进行自动操作。
Qwen/Qwen2-VL-7B-Instruct
32k
-
不支持
对话
千问_qwen
Qwen2-VL-7B-Instruct 是 Qwen-VL 模型的最新迭代版本,在视觉理解基准测试中达到了最先进的性能,包括 MathVista、DocVQA、RealWorldQA 和 MTVQA 等。Qwen2-VL 能够用于高质量的基于视频的问答、对话和内容创作,还具备复杂推理和决策能力,可以与移动设备、机器人等集成,基于视觉环境和文本指令进行自动操作。
Qwen/Qwen2.5-72B-Instruct
128k
8k
不支持
对话
千问_qwen
Qwen2.5-72B-Instruct 是阿里云发布的最新大语言模型系列之一。该 72B 模型在编码和数学等领域具有显著改进的能力。它支持长达 128K tokens 的输入,可以生成超过 8K tokens 的长文本。
Qwen/Qwen2.5-72B-Instruct-128K
128k
8k
不支持
对话
千问_qwen
Qwen2.5-72B-Instruct 是阿里云发布的最新大语言模型系列之一。该 72B 模型在编码和数学等领域具有显著改进的能力。它支持长达 128K tokens 的输入,可以生成超过 8K tokens 的长文本。
Qwen/Qwen2.5-7B-Instruct
128k
8k
不支持
对话
千问_qwen
Qwen2.5-7B-Instruct 是阿里云发布的最新大语言模型系列之一。该 7B 模型在编码和数学等领域具有显著改进的能力。该模型还提供了多语言支持,覆盖超过 29 种语言,包括中文、英文等。模型在指令跟随、理解结构化数据以及生成结构化输出(尤其是 JSON)方面都有显著提升
Qwen/Qwen2.5-Coder-32B-Instruct
128k
8k
不支持
对话,代码
千问_qwen
Qwen2.5-32B-Instruct 是阿里云发布的最新大语言模型系列之一。该 32B 模型在编码和数学等领域具有显著改进的能力。该模型还提供了多语言支持,覆盖超过 29 种语言,包括中文、英文等。模型在指令跟随、理解结构化数据以及生成结构化输出(尤其是 JSON)方面都有显著提升
Qwen/Qwen2.5-Coder-7B-Instruct
128k
8k
不支持
对话
千问_qwen
Qwen2.5-7B-Instruct 是阿里云发布的最新大语言模型系列之一。该 7B 模型在编码和数学等领域具有显著改进的能力。该模型还提供了多语言支持,覆盖超过 29 种语言,包括中文、英文等。模型在指令跟随、理解结构化数据以及生成结构化输出(尤其是 JSON)方面都有显著提升
Qwen/QwQ-32B-Preview
32k
16k
不支持
对话,推理
千问_qwen
QwQ-32B-Preview 是由 Qwen 团队开发的实验性研究模型,旨在提升人工智能的推理能力。作为预览版本,它展示了出色的分析能力,但也存在一些重要的限制: 1. 语言混合和代码切换:模型可能会混合使用语言或在语言之间意外切换,影响响应的清晰度。 2. 递归推理循环:模型可能会进入循环推理模式,导致冗长的回答而没有明确的结论。 3. 安全和伦理考量:模型需要加强安全措施以确保可靠和安全的性能,用户在使用时应谨慎。 4. 性能和基准限制:模型在数学和编程方面表现出色,但在常识推理和细微语言理解等其他领域仍有改进空间。
qwen1.5-110b-chat
32k
8k
不支持
对话
千问_qwen
-
qwen1.5-14b-chat
8k
2k
不支持
对话
千问_qwen
-
qwen1.5-32b-chat
32k
2k
不支持
对话
千问_qwen
-
qwen1.5-72b-chat
32k
2k
不支持
对话
千问_qwen
-
qwen1.5-7b-chat
8k
2k
不支持
对话
千问_qwen
-
qwen2-57b-a14b-instruct
65k
6k
不支持
对话
千问_qwen
-
Qwen2-72B-Instruct
-
-
不支持
对话
千问_qwen
-
qwen2-7b-instruct
128k
6k
不支持
对话
千问_qwen
-
qwen2-math-72b-instruct
4k
3k
不支持
对话
千问_qwen
-
qwen2-math-7b-instruct
4k
3k
不支持
对话
千问_qwen
-
qwen2.5-14b-instruct
128k
8k
不支持
对话
千问_qwen
-
qwen2.5-32b-instruct
128k
8k
不支持
对话
千问_qwen
-
qwen2.5-72b-instruct
128k
8k
不支持
对话
千问_qwen
-
qwen2.5-7b-instruct
128k
8k
不支持
对话
千问_qwen
-
qwen2.5-coder-14b-instruct
128k
8k
不支持
对话,代码
千问_qwen
-
qwen2.5-coder-32b-instruct
128k
8k
不支持
对话,代码
千问_qwen
-
qwen2.5-coder-7b-instruct
128k
8k
不支持
对话,代码
千问_qwen
-
qwen2.5-math-72b-instruct
4k
3k
不支持
对话
千问_qwen
-
qwen2.5-math-7b-instruct
4k
3k
不支持
对话
千问_qwen
-
deepseek-ai/DeepSeek-R1
64k
-
不支持
对话,推理
深度求索_deepseek
DeepSeek-R1模型是一款基于纯强化学习的开源推理模型,其在数学、代码和自然语言推理等任务上表现出色,性能可与OpenAI的o1模型相媲美,且在多个基准测试中取得了优异的成绩。
deepseek-ai/DeepSeek-V2-Chat
128k
-
不支持
对话
深度求索_deepseek
DeepSeek-V2 是一个强大、经济高效的混合专家(MoE)语言模型。它在 8.1 万亿个 token 的高质量语料库上进行了预训练,并通过监督微调(SFT)和强化学习(RL)进一步提升了模型能力。与 DeepSeek 67B 相比, DeepSeek-V2 在性能更强的同时,节省了 42.5% 的训练成本,减少了 93.3% 的 KV 缓存,并将最大生成吞吐量提高到了 5.76 倍。
deepseek-ai/DeepSeek-V2.5
32k
-
支持
对话
深度求索_deepseek
DeepSeek-V2.5 是 DeepSeek-V2-Chat 和 DeepSeek-Coder-V2-Instruct 的升级版本,集成了两个先前版本的通用和编码能力。该模型在多个方面进行了优化,包括写作和指令跟随能力,更好地与人类偏好保持一致。
deepseek-ai/DeepSeek-V3
128k
4k
不支持
对话
深度求索_deepseek
deepseek开源版本,相对官方版上下文更长,无敏感词拒答等问题。
deepseek-chat
64k
8k
支持
对话
深度求索_deepseek
236B 参数量,64K 上下文(API),中文综合能力(AlignBench)位列开源榜首,与 GPT-4-Turbo,文心 4.0 等闭源模型在评测中处于同一梯队
deepseek-coder
64k
8k
支持
对话,代码
深度求索_deepseek
236B 参数量,64K 上下文(API),中文综合能力(AlignBench)位列开源榜首,与 GPT-4-Turbo,文心 4.0 等闭源模型在评测中处于同一梯队
deepseek-reasoner
64k
8k
支持
对话,推理
深度求索_deepseek
DeepSeek-Reasoner(DeepSeek-R1)是DeepSeek最新推出的推理模型,旨在通过强化学习训练来提升推理能力。该模型的推理过程包含大量的反思和验证,能够处理复杂的逻辑推理任务,其思维链长度可达数万字。DeepSeek-R1在数学、代码及其他复杂问题的解答上表现出色,已被广泛应用于多种场景,显示出其强大的推理能力和灵活性。与其他模型相比,DeepSeek-R1在推理性能上接近顶尖的闭源模型,展现了开源模型在推理领域的潜力和竞争力。
hunyuan-code
4k
4k
不支持
对话,代码
腾讯_hunyuan
混元最新代码生成模型,经过 200B 高质量代码数据增训基座模型,迭代半年高质量 SFT 数据训练,上下文长窗口长度增大到 8K,五大语言代码生成自动评测指标上位居前列;五大语言10项考量各方面综合代码任务人工高质量评测上,性能处于第一梯队。
hunyuan-functioncall
28k
4k
支持
对话
腾讯_hunyuan
混元最新 MOE 架构 FunctionCall 模型,经过高质量的 FunctionCall 数据训练,上下文窗口达 32K,在多个维度的评测指标上处于领先。
hunyuan-large
28k
4k
不支持
对话
腾讯_hunyuan
Hunyuan-large 模型总参数量约 389B,激活参数量约 52B,是当前业界参数规模最大、效果最好的 Transformer 架构的开源 MoE 模型。
hunyuan-large-longcontext
128k
6k
不支持
对话
腾讯_hunyuan
擅长处理长文任务如文档摘要和文档问答等,同时也具备处理通用文本生成任务的能力。在长文本的分析和生成上表现优异,能有效应对复杂和详尽的长文内容处理需求。
hunyuan-lite
250k
6k
不支持
对话
腾讯_hunyuan
升级为 MOE 结构,上下文窗口为 256k ,在 NLP,代码,数学,行业等多项评测集上领先众多开源模型。
hunyuan-pro
28k
4k
支持
对话
腾讯_hunyuan
万亿级参数规模 MOE-32K 长文模型。在各种 benchmark 上达到绝对领先的水平,复杂指令和推理,具备复杂数学能力,支持 functioncall,在多语言翻译、金融法律医疗等领域应用重点优化。
hunyuan-role
28k
4k
不支持
对话
腾讯_hunyuan
混元最新版角色扮演模型,混元官方精调训练推出的角色扮演模型,基于混元模型结合角色扮演场景数据集进行增训,在角色扮演场景具有更好的基础效果。
hunyuan-standard
30k
2k
不支持
对话
腾讯_hunyuan
采用更优的路由策略,同时缓解了负载均衡和专家趋同的问题。 MOE-32K 性价比相对更高,在平衡效果、价格的同时,可对实现对长文本输入的处理。
hunyuan-standard-256K
250k
6k
不支持
对话
腾讯_hunyuan
采用更优的路由策略,同时缓解了负载均衡和专家趋同的问题。长文方面,大海捞针指标达到99.9%。 MOE-256K 在长度和效果上进一步突破,极大的扩展了可输入长度。
hunyuan-translation-lite
4k
4k
不支持
对话
腾讯_hunyuan
混元翻译模型支持自然语言对话式翻译;支持中文和英语、日语、法语、葡萄牙语、西班牙语、土耳其语、俄语、阿拉伯语、韩语、意大利语、德语、越南语、马来语、印尼语15种语言互译。
hunyuan-turbo
28k
4k
支持
对话
腾讯_hunyuan
Hunyuan-turbo 模型默认版本,采用全新的混合专家模型(MoE)结构,相比hunyuan-pro推理效率更快,效果表现更强。
hunyuan-turbo-latest
28k
4k
支持
对话
腾讯_hunyuan
Hunyuan-turbo 模型动态更新版本,是混元模型系列效果最好的版本,与C端(腾讯元宝)保持一致。
hunyuan-turbo-vision
8k
2k
支持
识图,对话
腾讯_hunyuan
混元新一代视觉语言旗舰大模型,采用全新的混合专家模型(MoE)结构,在图文理解相关的基础识别、内容创作、知识问答、分析推理等能力上相比前一代模型全面提升。最大输入6k,最大输出2k
hunyuan-vision
8k
2k
支持
对话,识图
腾讯_hunyuan
混元最新多模态模型,支持图片+文本输入生成文本内容。 图片基础识别:对图片中主体、元素、场景等进行识别 图片内容创作:对图片进行概述、创作广告文案、朋友圈、诗词等 图片多轮对话:输出单张图片进行多轮交互问答 图片分析推理:对图片中逻辑关系、数学题、代码、图表进行统计分析 图片知识问答:对图片包含的知识点进行问答,例如历史事件、电影海报 图片 OCR:对自然生活场景、非自然场景的图片识别文字。
SparkDesk-Lite
4k
-
不支持
对话
星火_SparkDesk
支持在线联网搜索功能,响应快速、便捷,适用于低算力推理与模型精调等定制化场景
SparkDesk-Max
128k
-
支持
对话
星火_SparkDesk
基于最新版星火大模型引擎4.0 Turbo 量化而来,支持联网搜索、天气、日期等多个内置插件,核心能力全面升级,各场景应用效果普遍提升,支持System角色人设与FunctionCall函数调用
SparkDesk-Max-32k
32k
-
支持
对话
星火_SparkDesk
推理更强:更强的上下文理解和逻辑推理能力,输入更长:支持32K tokens的文本输入,适用于长文档阅读、私有知识问答等场景
SparkDesk-Pro
128k
-
不支持
对话
星火_SparkDesk
数学、代码、医疗、教育等场景专项优化,支持联网搜索、天气、日期等多个内置插件,覆盖大部分知识问答、语言理解、文本创作等多个场景
SparkDesk-Pro-128K
128k
-
不支持
对话
星火_SparkDesk
专业级大语言模型,具有百亿级参数,在医疗、教育和代码等场景进行了专项优化,搜索场景延时更低。适用于文本、智能问答等对性能和响应速度有更高要求的业务场景。
moonshot-v1-128k
128k
4k
支持
对话
月之暗面_moonshot
长度为 8k 的模型,适用于生成短文本。
moonshot-v1-32k
32k
4k
支持
对话
月之暗面_moonshot
长度为 32k 的模型,适用于生成长文本。
moonshot-v1-8k
8k
4k
支持
对话
月之暗面_moonshot
长度为 128k 的模型,适用于生成超长文本。
codegeex-4
128k
4k
不支持
对话,代码
智谱_codegeex
智谱的代码模型:适用于代码自动补全任务
charglm-3
4k
2k
不支持
对话
智谱_glm
拟人模型
emohaa
8k
4k
不支持
对话
智谱_glm
心理模型:具备专业咨询能力,帮助用户理解情感并应对情绪问题
glm-3-turbo
128k
4k
不支持
对话
智谱_glm
即将弃用(2025年6月30日)
glm-4
128k
4k
支持
对话
智谱_glm
旧版旗舰:发布于2024年1月16日,目前已被GLM-4-0520取代
glm-4-0520
128k
4k
支持
对话
智谱_glm
高智能模型:适用于处理高度复杂和多样化的任务
glm-4-air
128k
4k
支持
对话
智谱_glm
高性价比:推理能力和价格之间最平衡的模型
glm-4-airx
8k
4k
支持
对话
智谱_glm
极速推理:具有超快的推理速度和强大的推理效果
glm-4-flash
128k
4k
支持
对话
智谱_glm
高速低价:超快推理速度
glm-4-flashx
128k
4k
支持
对话
智谱_glm
高速低价:Flash增强版本,超快推理速度
glm-4-long
1m
4k
支持
对话
智谱_glm
超长输入:专为处理超长文本和记忆型任务设计
glm-4-plus
128k
4k
支持
对话
智谱_glm
高智能旗舰: 性能全面提升,长文本和复杂任务能力显著增强
glm-4v
2k
-
不支持
对话,识图
智谱_glm
图像理解:具备图像理解能力和推理能力
glm-4v-flash
2k
1k
不支持
对话,识图
智谱_glm
免费模型:具备强大的图片理解能力
360gpt-pro
8k
-
不支持
对话
360AI_360gpt
360智脑系列效果最好的主力千亿级大模型,广泛适用于各领域复杂任务场景。
360gpt-turbo
7k


这是一个基于 Chatbot Arena (lmarena.ai) 数据的排行榜,通过自动化流程生成。
数据更新时间: 2025-12-09 08:08:59 UTC / 2025-12-09 16:08:59 CST (北京时间)
排名 (UB):基于 Bradley-Terry 模型计算的排名。此排名反映了模型在竞技场中的综合表现,并提供了其 Elo 分数的 上界 估计,帮助理解模型的潜在竞争力。
模型:大型语言模型 (LLM) 的名称。部分模型名称可能已嵌入相关链接。
分数:模型在竞技场中通过用户投票获得的 Elo 评分。Elo 评分是一种相对排名系统,分数越高表示模型表现越好。
95% 置信区间 (±):模型 Elo 评分的95%置信区间(例如:±6
本排行榜数据由自动化脚本直接从 1 官方网站获取。此排行榜由 GitHub Actions 每天自动更新。
本报告仅供参考。排行榜数据是动态变化的,并基于特定时间段内用户在 Chatbot Arena 上的偏好投票。数据的完整性和准确性取决于上游数据源。不同模型可能采用不同的许可协议,使用时请务必参考模型提供商的官方说明。
Anthropicclaude-opus-4-5-20251101-thinking-32k
1471
±8
7,980
Anthropic
Proprietary
4
3◄─►6
grok-4.1
1463
±7
14,324
xAI
Proprietary
5
3◄─►6
Anthropicclaude-opus-4-5-20251101
1462
±8
8,733
Anthropic
Proprietary
6
3◄─►10
gpt-5.1-high
1457
±7
11,949
OpenAI
Proprietary
7
6◄─►11
gemini-2.5-pro
1451
±4
74,939
Proprietary
8
6◄─►12
Anthropicclaude-sonnet-4-5-20250929-thinking-32k
1448
±5
25,961
Anthropic
Proprietary
9
6◄─►12
Anthropicclaude-opus-4-1-20250805-thinking-16k
1448
±4
41,812
Anthropic
Proprietary
10
6◄─►15
Anthropicclaude-sonnet-4-5-20250929
1445
±5
21,104
Anthropic
Proprietary
11
7◄─►17
gpt-4.5-preview-2025-02-27
1443
±6
14,644
OpenAI
Proprietary
12
8◄─►17
Anthropicclaude-opus-4-1-20250805
1441
±4
54,843
Anthropic
Proprietary
13
10◄─►17
chatgpt-4o-latest-20250326
1440
±3
61,196
OpenAI
Proprietary
14
10◄─►19
gpt-5-high
1437
±5
32,890
OpenAI
Proprietary
15
10◄─►23
gpt-5.1
1436
±7
12,836
OpenAI
Proprietary
16
11◄─►21
o3-2025-04-16
1434
±4
61,592
OpenAI
Proprietary
17
11◄─►24
qwen3-max-preview
1433
±5
28,132
Alibaba
Proprietary
18
14◄─►39
MoonshotAIkimi-k2-thinking-turbo
1428
±6
13,647
Moonshot
Modified MIT
19
14◄─►39
grok-4-1-fast-reasoning
1427
±8
6,975
xAI
Proprietary
20
15◄─►39
glm-4.6
1426
±5
22,680
Z.ai
MIT
21
17◄─►39
gpt-5-chat
1425
±4
32,135
OpenAI
Proprietary
22
16◄─►39
qwen3-max-2025-09-23
1424
±6
9,256
Alibaba
Proprietary
23
18◄─►39
Anthropicclaude-opus-4-20250514-thinking-16k
1423
±4
37,874
Anthropic
Proprietary
24
16◄─►39
deepseek-v3.2-exp
1423
±7
11,969
DeepSeek AI
MIT
25
15◄─►45
mistral-large-3
1422Preliminary
±10
4,393
Mistral
Apache 2.0
26
18◄─►39
qwen3-235b-a22b-instruct-2507
1421
±4
49,337
Alibaba
Apache 2.0
27
18◄─►42
deepseek-v3.2-exp-thinking
1421
±7
9,225
DeepSeek AI
MIT
28
18◄─►45
grok-4-fast-chat
1420
±8
7,059
xAI
Proprietary
29
18◄─►47
deepseek-v3.2-thinking
1418
±10
3,983
DeepSeek AI
MIT
30
18◄─►46
MoonshotAIkimi-k2-0905-preview
1418
±7
11,841
Moonshot
Modified MIT
31
18◄─►45
deepseek-r1-0528
1418
±6
19,240
DeepSeek
MIT
32
18◄─►47
ernie-5.0-preview-1022
1417
±9
4,704
Baidu
Proprietary
33
18◄─►45
MoonshotAIkimi-k2-0711-preview
1417
±5
28,667
Moonshot
Modified MIT
34
18◄─►46
deepseek-v3.1
1417
±6
15,255
DeepSeek
MIT
35
18◄─►46
deepseek-v3.1-thinking
1416
±7
11,985
DeepSeek
MIT
36
18◄─►50
deepseek-v3.1-terminus
1415
±10
3,746
DeepSeek AI
MIT
37
18◄─►47
qwen3-vl-235b-a22b-instruct
1415
±7
8,535
Alibaba
Apache 2.0
38
18◄─►52
deepseek-v3.1-terminus-thinking
1414
±10
3,522
DeepSeek AI
MIT
39
18◄─►56
deepseek-v3.2
1413
±10
4,475
DeepSeek AI
MIT
40
25◄─►47
Anthropicclaude-opus-4-20250514
1412
±4
45,676
Anthropic
Proprietary
41
26◄─►47
gpt-4.1-2025-04-14
1412
±4
52,587
OpenAI
Proprietary
42
26◄─►48
mistral-medium-2508
1411
±4
43,452
Mistral
Proprietary
43
27◄─►50
grok-3-preview-02-24
1410
±4
34,126
xAI
Proprietary
44
27◄─►52
grok-4-0709
1409
±4
42,573
xAI
Proprietary
45
27◄─►53
glm-4.5
1409
±5
24,825
Z.ai
MIT
46
31◄─►52
gemini-2.5-flash
1408
±3
74,323
Proprietary
47
34◄─►58
gemini-2.5-flash-preview-09-2025
1405
±5
27,425
Proprietary
48
39◄─►59
grok-4-fast-reasoning
1402
±5
18,884
xAI
Proprietary
49
40◄─►59
Anthropicclaude-haiku-4-5-20251001
1402
±5
24,230
Anthropic
Proprietary
50
42◄─►59
o1-2024-12-17
1401
±4
28,039
OpenAI
Proprietary
51
42◄─►61
qwen3-next-80b-a3b-instruct
1400
±5
23,118
Alibaba
Apache 2.0
52
40◄─►63
longcat-flash-chat
1400
±6
11,502
Meituan
MIT
53
46◄─►62
Anthropicclaude-sonnet-4-20250514-thinking-32k
1399
±4
36,214
Anthropic
Proprietary
54
45◄─►62
qwen3-235b-a22b-no-thinking
1399
±5
39,377
Alibaba
Apache 2.0
55
46◄─►66
qwen3-235b-a22b-thinking-2507
1397
±6
9,346
Alibaba
Apache 2.0
56
47◄─►66
deepseek-r1
1396
±5
18,718
DeepSeek
MIT
57
47◄─►68
qwen3-vl-235b-a22b-thinking
1394
±7
7,986
Alibaba
Apache 2.0
58
48◄─►67
gpt-5-mini-high
1393
±5
27,450
OpenAI
Proprietary
59
51◄─►67
deepseek-v3-0324
1392
±4
46,784
DeepSeek
MIT
60
46◄─►73
Tencenthunyuan-vision-1.5-thinking
1391
±12
2,212
Tencent
Proprietary
61
52◄─►68
o4-mini-2025-04-16
1391
±4
46,845
OpenAI
Proprietary
62
51◄─►70
mai-1-preview
1390
±5
18,180
Microsoft AI
Proprietary
63
54◄─►71
Anthropicclaude-sonnet-4-20250514
1389
±4
41,654
Anthropic
Proprietary
64
55◄─►72
o1-preview
1387
±5
31,505
OpenAI
Proprietary
65
55◄─►72
Anthropicclaude-3-7-sonnet-20250219-thinking-32k
1387
±4
39,911
Anthropic
Proprietary
66
57◄─►72
qwen3-coder-480b-a35b-instruct
1385
±5
23,154
Alibaba
Apache 2.0
67
54◄─►75
Tencenthunyuan-t1-20250711
1385
±9
4,819
Tencent
Proprietary
68
59◄─►74
mistral-medium-2505
1383
±5
34,527
Mistral
Proprietary
69
61◄─►74
qwen3-30b-a3b-instruct-2507
1382
±5
24,196
Alibaba
Apache 2.0
70
62◄─►75
gpt-4.1-mini-2025-04-14
1381
±4
40,494
OpenAI
Proprietary
71
61◄─►78
Tencenthunyuan-turbos-20250416
1380
±6
11,130
Tencent
Proprietary
72
63◄─►76
gemini-2.5-flash-lite-preview-09-2025-no-thinking
1379
±4
27,328
Proprietary
73
66◄─►79
gemini-2.5-flash-lite-preview-06-17-thinking
1375
±4
33,970
Proprietary
74
67◄─►80
qwen3-235b-a22b
1374
±5
27,168
Alibaba
Apache 2.0
75
69◄─►80
qwen2.5-max
1373
±4
33,548
Alibaba
Proprietary
76
71◄─►80
Anthropicclaude-3-5-sonnet-20241022
1372
±3
89,848
Anthropic
Proprietary
77
71◄─►83
Anthropicclaude-3-7-sonnet-20250219
1371
±4
44,561
Anthropic
Proprietary
78
72◄─►83
glm-4.5-air
1370
±4
31,673
Z.ai
MIT
79
73◄─►86
qwen3-next-80b-a3b-thinking
1367
±6
13,822
Alibaba
Apache 2.0
80
74◄─►86
Minimaxminimax-m1
1366
±4
36,884
MiniMax
Apache 2.0
81
77◄─►86
gemma-3-27b-it
1365
±4
49,316
Gemma
82
77◄─►90
o3-mini-high
1363
±5
18,735
OpenAI
Proprietary
83
77◄─►91
grok-3-mini-high
1362
±5
17,591
xAI
Proprietary
84
79◄─►93
gemini-2.0-flash-001
1360
±4
45,109
Proprietary
85
79◄─►101
deepseek-v3
1357
±5
21,994
DeepSeek
DeepSeek
86
79◄─►101
grok-3-mini-beta
1357
±5
23,794
xAI
Proprietary
87
82◄─►106
mistral-small-2506
1355
±5
18,329
Mistral
Apache 2.0
88
84◄─►106
gemini-2.0-flash-lite-preview-02-05
1353
±4
25,215
Proprietary
89
84◄─►107
gpt-oss-120b
1353
±4
31,271
OpenAI
Apache 2.0
90
85◄─►106
Coherecommand-a-03-2025
1352
±3
57,830
Cohere
CC-BY-NC-4.0
91
82◄─►109
glm-4.5v
1352
±8
4,978
Z.ai
MIT
92
85◄─►107
gemini-1.5-pro-002
1351
±3
56,012
Proprietary
93
82◄─►109
amazon-nova-experimental-chat-10-20
1350
±8
5,939
Amazon
Proprietary
94
87◄─►109
o3-mini
1348
±3
58,812
OpenAI
Proprietary
95
82◄─►118
Tencenthunyuan-turbos-20250226
1346
±12
2,250
Tencent
Proprietary
96
85◄─►111
ling-flash-2.0
1346
±7
7,158
Ant Group
MIT
97
85◄─►115
Minimaxminimax-m2
1346
±8
7,123
MiniMax
Apache 2.0
98
85◄─►113
Stepfunstep-3
1346
±7
6,642
StepFun
Apache 2.0
99
83◄─►119
Nvidiallama-3.1-nemotron-ultra-253b-v1
1346
±12
2,573
Nvidia
Nvidia Open Model
100
85◄─►119
amazon-nova-experimental-chat-10-09
1345
±11
2,892
Amazon
Proprietary
101
90◄─►109
gpt-4o-2024-05-13
1345
±3
113,568
OpenAI
Proprietary
102
85◄─►118
qwen3-32b
1345
±9
3,943
Alibaba
Apache 2.0
103
85◄─►118
qwen-plus-0125
1345
±8
5,861
Alibaba
Proprietary
104
87◄─►118
glm-4-plus-0111
1343
±8
5,806
Zhipu
Proprietary
105
92◄─►111
Anthropicclaude-3-5-sonnet-20240620
1342
±3
82,864
Anthropic
Proprietary
106
87◄─►121
gemma-3-12b-it
1340
±9
3,866
Gemma
107
87◄─►123
Nvidianvidia-llama-3.3-nemotron-super-49b-v1.5
1340
±10
3,492
Nvidia
Nvidia Open
108
87◄─►124
Tencenthunyuan-turbo-0110
1339
±11
2,322
Tencent
Proprietary
109
92◄─►120
gpt-5-nano-high
1339
±7
8,387
OpenAI
Proprietary
110
96◄─►120
Metallama-3.1-405b-instruct-bf16
1335
±4
41,932
Meta
Llama 3.1 Community
111
97◄─►120
o1-mini
1335
±4
52,301
OpenAI
Proprietary
112
98◄─►123
gpt-4o-2024-08-06
1334
±4
45,787
OpenAI
Proprietary
113
100◄─►122
grok-2-2024-08-13
1334
±4
63,725
xAI
Proprietary
114
99◄─►123
qwq-32b
1334
±4
26,273
Alibaba
Apache 2.0
115
98◄─►123
gemini-advanced-0514
1334
±5
50,654
Proprietary
116
100◄─►123
Metallama-3.1-405b-instruct-fp8
1333
±3
60,272
Meta
Llama 3.1 Community
117
96◄─►134
Stepfunstep-2-16k-exp-202412
1332
±9
4,895
StepFun
Proprietary
118
106◄─►135
01.AIyi-lightning
1328
±5
27,624
01 AI
Proprietary
119
109◄─►135
Metallama-4-maverick-17b-128e-instruct
1327
±4
41,202
Meta
Llama 4
120
110◄─►138
qwen3-30b-a3b
1326
±5
27,492
Alibaba
Apache 2.0
121
100◄─►146
Nvidiallama-3.3-nemotron-49b-super-v1
1326
±12
2,243
Nvidia
Nvidia
122
104◄─►145
Tencenthunyuan-large-2025-02-10
1325
±10
3,760
Tencent
Proprietary
123
116◄─►140
gpt-4-turbo-2024-04-09
1324
±4
98,965
OpenAI
Proprietary
124
117◄─►141
Anthropicclaude-3-5-haiku-20241022
1322
±3
71,378
Anthropic
Proprietary
125
117◄─►141
Metallama-4-scout-17b-16e-instruct
1322
±5
31,199
Meta
Llama
126
110◄─►146
deepseek-v2.5-1210
1322
±8
6,877
DeepSeek
DeepSeek
127
117◄─►141
Anthropicclaude-3-opus-20240229
1322
±3
196,368
Anthropic
Proprietary
128
117◄─►141
gemini-1.5-pro-001
1322
±4
79,769
Proprietary
129
116◄─►146
gpt-4.1-nano-2025-04-14
1321
±8
6,143
OpenAI
Proprietary
130
117◄─►146
ring-flash-2.0
1320
±7
7,282
Ant Group
MIT
131
117◄─►146
Stepfunstep-1o-turbo-202506
1320
±7
9,665
StepFun
Proprietary
132
120◄─►145
Metallama-3.3-70b-instruct
1319
±3
56,011
Meta
Llama-3.3
133
118◄─►146
gemma-3n-e4b-it
1318
±5
23,471
Gemma
134
120◄─►146
glm-4-plus
1318
±5
26,342
Zhipu AI
Proprietary
135
117◄─►147
gpt-oss-20b
1318
±6
10,849
OpenAI
Apache 2.0
136
120◄─►147
qwen-max-0919
1317
±6
16,598
Alibaba
Qwen
137
122◄─►146
gpt-4o-mini-2024-07-18
1316
±3
69,291
OpenAI
Proprietary
138
121◄─►152
qwen2.5-plus-1127
1314
±6
10,252
Alibaba
Proprietary
139
126◄─►151
gpt-4-1106-preview
1313
±4
101,117
OpenAI
Proprietary
140
126◄─►151
mistral-large-2407
1313
±4
45,968
Mistral
Mistral Research
141
126◄─►151
gpt-4-0125-preview
1313
±4
94,534
OpenAI
Proprietary
142
126◄─►152
athene-v2-chat
1313
±4
24,880
NexusFlow
NexusFlow
143
117◄─►156
olmo-3-32b-think
1312
±12
2,551
Allen AI
Apache 2.0
144
117◄─►156
mercury
1311
±14
1,967
Inception AI
Proprietary
145
121◄─►156
Tencenthunyuan-standard-2025-02-10
1310
±10
3,920
Tencent
Proprietary
146
128◄─►153
gemini-1.5-flash-002
1310
±4
35,180
Proprietary
147
138◄─►156
grok-2-mini-2024-08-13
1307
±4
52,789
xAI
Proprietary
148
138◄─►156
deepseek-v2.5
1306
±5
24,839
DeepSeek
DeepSeek
149
138◄─►156
magistral-medium-2506
1305
±6
11,999
Mistral
Proprietary
150
141◄─►156
mistral-large-2411
1305
±4
28,455
Mistral
MRL
151
138◄─►156
athene-70b-0725
1305
±6
19,796
NexusFlow
CC-BY-NC-4.0
152
142◄─►156
mistral-small-3.1-24b-instruct-2503
1303
±4
34,140
Mistral
Apache 2.0
153
136◄─►161
gemma-3-4b-it
1303
±9
4,195
Gemma
154
144◄─►156
qwen2.5-72b-instruct
1302
±4
39,632
Alibaba
Qwen
155
144◄─►164
Nvidiallama-3.1-nemotron-70b-instruct
1297
±8
7,216
Nvidia
Llama 3.1
156
144◄─►165
Tencenthunyuan-large-vision
1295
±9
5,599
Tencent
Proprietary
157
154◄─►164
Metallama-3.1-70b-instruct
1293
±4
56,003
Meta
Llama 3.1 Community
158
155◄─►167
amazon-nova-pro-v1.0
1288
±4
25,218
Amazon
Proprietary
159
154◄─►169
jamba-1.5-large
1288
±7
8,730
AI21 Labs
Jamba Open
160
155◄─►167
gemma-2-27b-it
1287
±3
76,195
Gemma license
161
154◄─►169
reka-core-20240904
1287
±7
7,380
Reka AI
Proprietary
162
155◄─►169
gpt-4-0314
1286
±5
54,754
OpenAI
Proprietary
163
154◄─►175
Nvidiallama-3.1-nemotron-51b-instruct
1286
±10
3,777
Nvidia
Llama 3.1
164
154◄─►175
llama-3.1-tulu-3-70b
1286
±10
2,881
Ai2
Llama 3.1
165
157◄─►170
gemini-1.5-flash-001
1284
±4
63,418
Proprietary
166
158◄─►174
Anthropicclaude-3-sonnet-20240229
1281
±4
110,173
Anthropic
Proprietary
167
158◄─►175
gemma-2-9b-it-simpo
1278
±7
10,108
Princeton
MIT
168
160◄─►175
Nvidianemotron-4-340b-instruct
1278
±5
19,913
Nvidia
NVIDIA Open Model
169
160◄─►176
Coherecommand-r-plus-08-2024
1277
±7
9,931
Cohere
CC-BY-NC-4.0
170
164◄─►175
Metallama-3-70b-instruct
1276
±3
158,908
Meta
Llama 3 Community
171
164◄─►176
gpt-4-0613
1275
±4
89,612
OpenAI
Proprietary
172
164◄─►178
mistral-small-24b-instruct-2501
1274
±6
14,830
Mistral
Apache 2.0
173
163◄─►180
glm-4-0520
1273
±7
9,857
Zhipu AI
Proprietary
174
164◄─►180
reka-flash-20240904
1273
±7
7,583
Reka AI
Proprietary
175
165◄─►184
qwen2.5-coder-32b-instruct
1269
±8
5,452
Alibaba
Apache 2.0
176
170◄─►184
Coherec4ai-aya-expanse-32b
1267
±5
27,362
Cohere
CC-BY-NC-4.0
177
172◄─►184
gemma-2-9b-it
1264
±4
54,954
Gemma license
178
172◄─►186
deepseek-coder-v2
1263
±6
15,242
DeepSeek AI
DeepSeek License
179
173◄─►185
Coherecommand-r-plus
1263
±4
78,401
Cohere
CC-BY-NC-4.0
180
173◄─►186
qwen2-72b-instruct
1262
±5
37,688
Alibaba
Qianwen LICENSE
181
175◄─►186
Anthropicclaude-3-haiku-20240307
1261
±4
118,626
Anthropic
Proprietary
182
175◄─►186
amazon-nova-lite-v1.0
1260
±5
19,760
Amazon
Proprietary
183
175◄─►186
gemini-1.5-flash-8b-001
1259
±4
35,914
Proprietary
184
178◄─►186
Azurephi-4
1255
±4
24,354
Microsoft
MIT
185
175◄─►191
olmo-2-0325-32b-instruct
1252
±11
3,377
Allen AI
Apache-2.0
186
179◄─►190
Coherecommand-r-08-2024
1251
±7
10,229
Cohere
CC-BY-NC-4.0
187
185◄─►195
mistral-large-2402
1242
±5
63,404
Mistral
Proprietary
188
185◄─►195
amazon-nova-micro-v1.0
1241
±5
19,774
Amazon
Proprietary
189
185◄─►200
jamba-1.5-mini
1239
±7
8,918
AI21 Labs
Jamba Open
190
185◄─►203
ministral-8b-2410
1237
±9
4,833
Mistral
MRL
191
187◄─►202
qwen1.5-110b-chat
1234
±5
26,679
Alibaba
Qianwen LICENSE
192
187◄─►203
gemini-pro-dev-api
1234
±7
18,454
Proprietary
193
187◄─►203
qwen1.5-72b-chat
1234
±5
39,689
Alibaba
Qianwen LICENSE
194
187◄─►204
reka-flash-21b-20240226-online
1233
±7
15,606
Reka AI
Proprietary
195
186◄─►205
Tencenthunyuan-standard-256k
1233
±12
2,761
Tencent
Proprietary
196
189◄─►204
mixtral-8x22b-instruct-v0.1
1230
±4
52,214
Mistral
Apache 2.0
197
189◄─►205
Coherecommand-r
1228
±5
54,710
Cohere
CC-BY-NC-4.0
198
189◄─►206
reka-flash-21b-20240226
1227
±6
25,026
Reka AI
Proprietary
199
191◄─►206
gpt-3.5-turbo-0125
1224
±5
67,214
OpenAI
Proprietary
200
190◄─►207
mistral-medium
1224
±5
34,893
Mistral
Proprietary
201
190◄─►207
Coherec4ai-aya-expanse-8b
1223
±7
9,922
Cohere
CC-BY-NC-4.0
202
194◄─►206
Metallama-3-8b-instruct
1223
±4
106,055
Meta
Llama 3 Community
203
189◄─►209
llama-3.1-tulu-3-8b
1222
±11
2,943
Ai2
Llama 3.1
204
189◄─►210
gemini-pro
1222
±12
6,418
Proprietary
205
196◄─►211
HuggingFacezephyr-orpo-141b-A35b-v0.1
1214
±11
4,712
HuggingFace
Apache 2.0
206
201◄─►210
01.AIyi-1.5-34b-chat
1213
±5
24,417
01 AI
Apache-2.0
207
203◄─►210
Metallama-3.1-8b-instruct
1211
±4
50,234
Meta
Llama 3.1 Community
208
198◄─►216
granite-3.1-8b-instruct
1210
±11
3,142
IBM
Apache 2.0
209
203◄─►216
qwen1.5-32b-chat
1205
±6
22,068
Alibaba
Qianwen LICENSE
210
204◄─►218
gpt-3.5-turbo-1106
1202
±9
16,760
OpenAI
Proprietary
211
207◄─►218
Azurephi-3-medium-4k-instruct
1198
±5
25,301
Microsoft
MIT
212
208◄─►218
gemma-2-2b-it
1198
±4
46,901
Gemma license
213
208◄─►218
mixtral-8x7b-instruct-v0.1
1198
±4
74,303
Mistral
Apache 2.0
214
208◄─►223
dbrx-instruct-preview
1196
±6
32,760
Databricks
DBRX LICENSE
215
208◄─►226
qwen1.5-14b-chat
1193
±7
18,066
Alibaba
Qianwen LICENSE
216
208◄─►227
InternLMinternlm2_5-20b-chat
1192
±7
10,038
InternLM
Other
217
210◄─►233
Azurewizardlm-70b
1185
±9
8,270
Microsoft
Llama 2 Community
218
210◄─►234
deepseek-llm-67b-chat
1184
±12
4,950
DeepSeek AI
DeepSeek License
219
214◄─►231
01.AIyi-34b-chat
1184
±7
15,624
01 AI
Yi License
220
214◄─►233
granite-3.0-8b-instruct
1184
±9
6,727
IBM
Apache 2.0
221
214◄─►233
OpenChatopenchat-3.5-0106
1183
±8
12,712
OpenChat
Apache-2.0
222
214◄─►234
OpenChatopenchat-3.5
1182
±10
8,009
OpenChat
Apache-2.0
223
214◄─►235
granite-3.1-2b-instruct
1181
±11
3,235
IBM
Apache 2.0
224
215◄─►233
Snowflakesnowflake-arctic-instruct
1180
±6
33,272
Snowflake
Apache 2.0
225
216◄─►234
gemma-1.1-7b-it
1180
±6
24,327
Gemma license
226
215◄─►236
tulu-2-dpo-70b
1179
±10
6,579
AllenAI/UW
AI2 ImpACT Low-risk
227
215◄─►238
openhermes-2.5-mistral-7b
1176
±10
5,026
NousResearch
Apache-2.0
228
217◄─►237
vicuna-33b
1174
±6
22,613
LMSYS
Non-commercial
229
217◄─►238
starling-lm-7b-beta
1173
±7
16,190
Nexusflow
Apache-2.0
230
217◄─►238
Azurephi-3-small-8k-instruct
1172
±6
17,983
Microsoft
MIT
231
218◄─►238
Metallama-2-70b-chat
1172
±5
38,767
Meta
Llama 2 Community
232
218◄─►241
starling-lm-7b-alpha
1168
±8
10,267
UC Berkeley
CC-BY-NC-4.0
233
222◄─►242
Metallama-3.2-3b-instruct
1167
±8
8,043
Meta
Llama 3.2
234
217◄─►243
nous-hermes-2-mixtral-8x7b-dpo
1166
±12
3,792
NousResearch
Apache-2.0
235
225◄─►248
qwq-32b-preview
1160
±11
3,256
Alibaba
Apache 2.0
236
226◄─►250
Nvidiallama2-70b-steerlm-chat
1157
±13
3,605
Nvidia
Llama 2 Community
237
232◄─►247
granite-3.0-2b-instruct
1157
±8
6,922
IBM
Apache 2.0
238
228◄─►252
solar-10.7b-instruct-v1.0
1154
±13
4,187
Upstage AI
CC-BY-NC-4.0
239
227◄─►256
dolphin-2.2.1-mistral-7b
1152
±15
1,685
Cognitive Computations
Apache-2.0
240
234◄─►251
mistral-7b-instruct-v0.2
1151
±7
19,603
Mistral
Apache-2.0
241
232◄─►255
mpt-30b-chat
1151
±12
2,606
MosaicML
CC-BY-NC-SA-4.0
242
233◄─►252
Azurewizardlm-13b
1150
±9
7,122
Microsoft
Llama 2 Community
243
232◄─►259
falcon-180b-chat
1147
±17
1,312
TII
Falcon-180B TII License
244
235◄─►257
qwen1.5-7b-chat
1144
±10
4,782
Alibaba
Qianwen LICENSE
245
235◄─►256
Azurephi-3-mini-4k-instruct-june-2024
1143
±6
12,415
Microsoft
MIT
246
235◄─►256
Metallama-2-13b-chat
1143
±7
19,357
Meta
Llama 2 Community
247
236◄─►257
vicuna-13b
1142
±7
19,539
LMSYS
Llama 2 Community
248
235◄─►259
qwen-14b-chat
1139
±11
5,004
Alibaba
Qianwen LICENSE
249
237◄─►259
Metacodellama-34b-instruct
1137
±9
7,417
Meta
Llama 2 Community
250
237◄─►259
palm-2
1137
±9
8,634
Proprietary
251
238◄─►259
gemma-7b-it
1135
±9
9,034
Gemma license
252
241◄─►260
HuggingFacezephyr-7b-beta
1132
±9
11,220
HuggingFace
MIT
253
241◄─►260
Azurephi-3-mini-128k-instruct
1131
±7
21,024
Microsoft
MIT
254
245◄─►260
Azurephi-3-mini-4k-instruct
1129
±6
20,539
Microsoft
MIT
255
239◄─►264
HuggingFacezephyr-7b-alpha
1129
±16
1,803
HuggingFace
MIT
256
241◄─►264
guanaco-33b
1128
±12
2,955
UW
Non-commercial
257
247◄─►264
stripedhyena-nous-7b
1121
±11
5,214
Together AI
Apache 2.0
258
242◄─►265
Metacodellama-70b-instruct
1119
±18
1,151
Meta
Llama 2 Community
259
247◄─►264
HuggingFacesmollm2-1.7b-instruct
1118
±14
2,244
HuggingFace
Apache 2.0
260
252◄─►264
vicuna-7b
1115
±9
6,972
LMSYS
Llama 2 Community
261
255◄─►264
gemma-1.1-2b-it
1114
±8
11,035
Gemma license
262
255◄─►264
Metallama-3.2-1b-instruct
1113
±8
8,166
Meta
Llama 3.2
263
255◄─►265
mistral-7b-instruct
1111
±9
9,042
Mistral
Apache 2.0
264
255◄─►265
Metallama-2-7b-chat
1109
±7
14,272
Meta
Llama 2 Community
265
262◄─►269
gemma-2b-it
1091
±12
4,817
Gemma license
266
265◄─►267
qwen1.5-4b-chat
1091
±9
7,662
Alibaba
Qianwen LICENSE
267
265◄─►272
olmo-7b-instruct
1075
±11
6,412
Allen AI
Apache-2.0
268
266◄─►272
koala-13b
1070
±10
6,998
UC Berkeley
Non-commercial
269
267◄─►272
alpaca-13b
1066
±11
5,828
Stanford
Non-commercial
270
266◄─►273
gpt4all-13b-snoozy
1065
±15
1,773
Nomic AI
Non-commercial
271
267◄─►273
mpt-7b-chat
1061
±12
3,977
MosaicML
CC-BY-NC-SA-4.0
272
267◄─►273
chatglm3-6b
1057
±12
4,692
Tsinghua
Apache-2.0
273
270◄─►275
RWKVRWKV-4-Raven-14B
1041
±11
4,898
RWKV
Apache 2.0
274
273◄─►275
chatglm2-6b
1026
±14
2,683
Tsinghua
Apache-2.0
275
273◄─►275
oasst-pythia-12b
1022
±11
6,343
OpenAssistant
Apache 2.0
276
276◄─►279
chatglm-6b
996
±13
4,968
Tsinghua
Non-commercial
277
276◄─►279
fastchat-t5-3b
991
±12
4,270
LMSYS
Apache 2.0
278
276◄─►280
dolly-v2-12b
978
±14
3,471
Databricks
MIT
279
276◄─►280
Metallama-13b
971
±16
2,441
Meta
Non-commercial
280
278◄─►280
Stabilitystablelm-tuned-alpha-7b
952
±13
3,325
Stability AI
CC-BY-NC-SA-4.0
票数:该模型在竞技场中收到的总投票数量。投票数越多,通常意味着其评分的统计可靠性越高。
组织/公司:提供该模型的组织或公司。
许可证:模型的许可协议类型,例如专有 (Proprietary)、Apache 2.0、MIT 等。
1
1◄─►2
gemini-3-pro
1491
±7
13,801
Proprietary
2
1◄─►3
grok-4.1-thinking
1481
±7
14,412
xAI
Proprietary
3
2◄─►6