Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
此文件由 AI 從中文翻譯而來,尚未經過審閱。
注意:Windows 7 系統不支援安裝 Cherry Studio。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
關注我們的社群帳號:、、、、
加入我們的社群:、、、
Cherry Studio 是一款集多模型對話、知識庫管理、AI 繪畫、翻譯等功能於一體的 AI 助手平台。 Cherry Studio 高度自訂的設計、強大的擴展能力和友善的使用者體驗,使其成為專業使用者與 AI 愛好者的理想選擇。無論是零基礎使用者還是開發者,都能在 Cherry Studio 中找到適合自己的 AI 功能,提升工作效率與創造力。
一問多答:支援同一問題透過多個模型同時生成回覆,方便使用者對比不同模型的表現,詳見 。
自動分組:每個助手的對話記錄會自動分組管理,便於使用者快速查閱歷史對話。
對話匯出:支援將完整對話或部分對話匯出為多種格式(如 Markdown、Word 等),方便儲存與分享。
高度自訂參數:除基礎參數調整外,還支援使用者填寫自訂參數,滿足個性化需求。
助手市集:內建千餘個產業專用助手,涵蓋翻譯、程式設計、寫作等領域,同時支援使用者自訂助手。
多種格式渲染:支援 Markdown 渲染、公式渲染、HTML 即時預覽等功能,提升內容展示效果。
AI 繪畫:提供專用繪畫面板,使用者可透過自然語言描述生成高品質圖像。
AI 小工具:整合多種免費 Web 端 AI 工具,無需切換瀏覽器即可直接使用。
翻譯功能:支援專用翻譯面板、對話翻譯、提示詞翻譯等多種翻譯情境。
檔案管理:對話、繪畫和知識庫中的檔案統一分類管理,避免繁瑣查詢。
全域搜尋:支援快速定位歷史記錄與知識庫內容,提升工作效率。
服務商模型聚合:支援 OpenAI、Gemini、Anthropic、Azure 等主流服務商的模型統一呼叫。
模型自動獲取:一鍵獲取完整模型列表,無需手動設定。
多 API 金鑰輪詢:支援多個 API 金鑰輪換使用,避免速率限制問題。
精準頭像匹配:為每個模型自動匹配專屬頭像,提升辨識度。
自訂服務商:支援符合 OpenAI、Gemini、Anthropic 等規範的第三方服務商接入,相容性強。
自訂 CSS:支援全域樣式自訂,打造專屬介面風格。
自訂對話佈局:支援清單或氣泡樣式佈局,並可自訂訊息樣式(如程式碼片段樣式)。
自訂頭像:支援為軟體和助手設定個性化頭像。
自訂側邊欄選單:使用者可根據需求隱藏或排序側邊欄功能,優化使用體驗。
多種格式支援:支援 PDF、DOCX、PPTX、XLSX、TXT、MD 等多種檔案格式匯入。
多種資料來源支援:支援本機檔案、網址、站點地圖甚至手動輸入內容作為知識庫來源。
知識庫匯出:支援將處理好的知識庫匯出並分享給他人使用。
支援搜尋檢查:知識庫匯入後,使用者可即時檢索測試,查看處理結果與分段效果。
快速問答:在任何情境(如微信、瀏覽器)中呼出快捷助手,快速取得答案。
快速翻譯:支援快速翻譯其他情境中的詞彙或文字。
內容總結:對長文字內容進行快速總結,提升資訊提取效率。
解釋說明:無需複雜提示詞,一鍵解釋說明不懂的問題。
多重備份方案:支援本機備份、WebDAV 備份和定時備份,確保資料安全。
資料安全:支援全本機場景使用,結合本機大模型,避免資料洩漏風險。
入門門檻低:Cherry Studio 致力降低技術門檻,零基礎使用者也能快速上手,讓使用者專注於工作、學習或創作。
文件完善:提供詳細的使用文件與常見問題處理手冊,協助使用者快速解決問題。
持續迭代:專案團隊積極回應使用者回饋,持續優化功能,確保專案健康發展。
開源與擴展性:支援使用者透過開原始碼進行自訂與擴展,滿足個性化需求。
知識管理與查詢:透過本機知識庫功能,快速建構與查詢專屬知識庫,適用於研究、教育等領域。
多模型對話與創作:支援多模型同時對話,協助使用者快速獲取資訊或產製內容。
翻譯與辦公室自動化:內建翻譯助手與檔案處理功能,適合需要跨語言交流或文件處理的使用者。
AI 繪畫與設計:透過自然語言描述產製圖像,滿足創意設計需求。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
當助手未設置預設助手模型時,其新對話當中預設選擇的模型為此處設置的模型。
優化提示詞、劃詞助手使用的也是此處設置的模型。
每次對話後會調用模型為對話生成一個話題名稱,此處設置的模型為命名時所使用的模型。
對話、繪畫等輸入框當中的翻譯功能,翻譯介面的翻譯模型都使用的是此處設置的模型。
快捷助手功能使用的模型,詳見 快捷助手











此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 資料備份支援透過 S3 兼容儲存(物件儲存)的方式進行備份。常見的 S3 兼容儲存服務有:AWS S3、Cloudflare R2、阿里雲 OSS、騰訊雲 COS 以及 MinIO 等。
基於 S3 兼容儲存可透過 A電腦 S3儲存 B電腦 的方式來實現多端資料同步。
建立物件儲存桶(Bucket),並記錄下儲存桶名稱。強烈建議將儲存桶設定為私有讀寫以避免備份資料外洩!!
參考文件,前往雲端服務控制台取得 S3 兼容儲存的 Access Key ID、Secret Access Key、Endpoint、Bucket、Region 等資訊。
Endpoint:S3 兼容儲存的存取位址,通常形如 https://<bucket-name>.<region>.amazonaws.com 或 https://<ACCOUNT_ID>.r2.cloudflarestorage.com。
Region:儲存桶所在的區域,例如 us-west-1、ap-southeast-1 等,Cloudflare R2 請填寫 auto。
Bucket:儲存桶名稱。
Access Key ID 與 Secret Access Key:用於身分驗證的憑證。
Root Path:選填,指定備份到儲存桶時的根路徑,預設為空。
相關文件
AWS S3:
Cloudflare R2:
阿里雲 OSS:
騰訊雲 COS:
在 S3 備份設定中填寫上述資訊,點擊備份按鈕即可進行備份,點擊管理按鈕可檢視和管理備份檔案清單。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
使用 GitHub Copilot 需要先擁有一個 GitHub 帳號,並訂閱 GitHub Copilot 服務,免費版本的訂閱也可以,但免費版本不支援最新的 Claude 3.7 模型,具體請參考 。
點擊「登入 GitHub」,取得 Device Code 並複製。
成功取得 Device Code 後,點擊連結開啟瀏覽器,在瀏覽器中登入 GitHub 帳號,輸入 Device Code 並授權。
授權成功後,返回 Cherry Studio,點擊「連接 GitHub」,成功後會顯示 GitHub 使用者名稱和頭像。
點擊下方的「管理」按鈕,會自動連網取得當前支援的模型清單。
目前使用 Axios 構建請求,Axios 不支援 socks 代理,請使用系統代理或 HTTP 代理,或者直接不在 CherryStudio 中設定代理,使用全域代理。首先請確保您的網路連線正常,以避免取得 Device Code 失敗的情況。
























此文件由 AI 從中文翻譯而來,尚未經過審閱。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
自動安裝 MCP 服務(測試版)
基於本體知識圖譜的持久性記憶基礎實現。這使得模型能夠在不同對話間記住用戶的相關資訊。
MEMORY_FILE_PATH=/path/to/your/file.json一個 MCP 伺服器實現,提供了透過結構化思維過程進行動態和反思性問題解決的工具。
一個整合了 Brave 搜尋 API 的 MCP 伺服器實現,提供網頁與本地搜尋雙重功能。
BRAVE_API_KEY=YOUR_API_KEY用於取得 URL 網頁內容的 MCP 伺服器。
實現檔案系統操作的模型上下文協議(MCP)的 Node.js 伺服器。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
加入 Telegram 討論群組獲取協助:https://t.me/CherryStudioAI
Github Issues 提交:https://github.com/CherryHQ/cherry-studio/issues/new/choose
開發者聯絡郵箱:[email protected]
此文件由 AI 從中文翻譯而來,尚未經過審閱。
我們歡迎對 Cherry Studio 的貢獻!您可以通過以下方式貢獻:
1. 貢獻程式碼: 開發新功能或優化現有程式碼。
2. 修復錯誤: 提交您發現的錯誤修復。
3. 維護問題: 協助管理 GitHub 問題。
4. 產品設計: 參與設計討論。
5. 撰寫文件: 改進使用者手冊和指南。
6. 社群參與: 加入討論並幫助使用者。
7. 推廣使用: 宣傳 Cherry Studio。
發送郵件至 [email protected]
郵件標題:申請成為開發者
郵件內容:申請理由





此文件由 AI 從中文翻譯而來,尚未經過審閱。
快捷助手是 Cherry Studio 提供的便捷工具,允許您在任何應用程式中快速存取 AI 功能,實現即時提問、翻譯、摘要和解釋等操作。
開啟設定: 導覽至 設定 -> 快速鍵 -> 快捷助手。
啟用開關: 找到並開啟 快捷助手 對應按鈕。
設定快速鍵(選用):
Windows 預設快速鍵為 Ctrl + E。
macOS 預設快速鍵為 ⌘ + E。
您可在此自訂快速鍵以避免衝突或符合個人使用習慣。
喚起功能: 在任何應用程式中,按下設定好的快速鍵(或預設快速鍵)即可開啟快捷助手。
功能操作: 在快捷助手視窗中可直接進行:
即時提問: 向 AI 提出任何疑問。
文字翻譯: 輸入待翻譯文字內容。
內容摘要: 輸入長文字進行重點摘要。
術語解釋: 輸入需說明的概念或專有名詞。
關閉視窗: 按下 ESC 鍵或點擊視窗外任意位置即可關閉。
快速鍵衝突: 若預設快速鍵與其他應用程式衝突,請修改設定。
探索進階功能: 除說明文件功能外,快捷助手可能支援程式碼生成、風格轉換等操作,建議持續嘗試發掘。
問題回報與建議: 使用時如遇問題或有功能改進建議,請隨時向 Cherry Studio 團隊 提交回饋。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
登入 阿里雲百煉,沒有阿里雲帳號的話需要註冊。
點擊右上角的 建立我的 API-KEY 按鈕。
在彈出的視窗中選擇預設業務空間(或者你也可以自訂),如果需要可以填寫描述。
點擊右下角的 確定 按鈕。
隨後,你應該能看到列表中新增了一行,點擊右側的 檢視 按鈕。
點擊 複製 按鈕。
轉到 Cherry Studio,在 設定 → 模型服務 → 阿里雲百煉 中找到 API 金鑰 ,將複製的 API 金鑰貼上到這裡。
可以按照 模型服務 中的介紹調整相關設定,之後就能使用了。
暂时不支持Claude模型
此文件由 AI 從中文翻譯而來,尚未經過審閱。
取得 Gemini 的 API 金鑰前,您需要有一個 Google Cloud 專案(若已有專案可跳過此步驟)
前往 Google Cloud 建立專案,填寫專案名稱並點擊建立專案
在建立的專案中啟用 Vertex AI API
開啟 服務帳號 權限介面,建立服務帳號
在服務帳號管理頁面找到新建的服務帳號,點擊金鑰並建立新的 JSON 格式金鑰
建立成功後,金鑰檔案將以 JSON 格式自動儲存到您的電腦,請 妥善保存
選擇Vertex AI服務供應商
將JSON檔案的對應欄位填入
點擊新增 模型,即可開始使用!
此文件由 AI 從中文翻譯而來,尚未經過審閱。
取得 Gemini 的 api key 前,你需要有一個 Google Cloud 專案(如果你已有,此過程可跳過)
進入 Google Cloud 建立專案,填寫專案名稱並點擊建立專案
在官方 API Key頁面 點擊 密鑰 創建API密鑰
將生成的 key 複製,並打開 CherryStudio 的 服務商設定
找到服務商 Gemini,填入剛剛取得的 key
點擊最下方管理或新增,加入支援的模型並開啟右上角服務商開關即可使用。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 支援將話題導入 Notion 的數據庫。
開啟網站 Notion Integrations 建立應用程式
建立應用程式
名稱:Cherry Studio
類型:選擇第一個
圖示:可以保存此圖片
複製金鑰並填寫到 Cherry Studio 設定中
開啟 Notion 網站建立新頁面,在下方選擇數據庫類型,名稱填寫 Cherry Studio,按照圖示操作連接
若您的 Notion 數據庫 URL 類似:
https://www.notion.so/<long_hash_1>?v=<long_hash_2>
則 Notion 數據庫 ID 就是 <long_hash_1> 部分
填寫 頁面標題欄位名稱:
若網頁顯示英文,填寫 Name
若網頁顯示中文,填寫 名稱
恭喜!Notion 配置已完成 ✅ 接下來可將 Cherry Studio 內容匯出到您的 Notion 數據庫
如何注册tavily?
此文件由 AI 從中文翻譯而來,尚未經過審閱。
訪問上述官網,或者從cherry studio-設定-網路搜尋-點擊取得秘鑰,會直接跳轉到tavily登入註冊頁面。
如果是第一次使用,要先註冊一個(Sign up)帳號,才能登入(Log in)使用。預設跳轉的是登入頁面哦。
點擊註冊帳號,進入下面的界面,輸入自己的常用信箱,或者使用谷歌、github帳號,然後下一步輸入密碼,常規操作。
🚨🚨🚨【關鍵步驟】 註冊成功後,會有一個動態驗證碼的步驟,需要掃描二維碼,產生一次性Code才能繼續使用。
很簡單,此時你有2個辦法。
下載一個驗證身份的APP,微軟出的—— Authenticator 【略微繁瑣】
使用微信小程式:騰訊身份驗證器 。【簡單,有手就行,建議】
開啟微信小程式,搜尋:騰訊身份驗證器
上面的步驟做完,就會進入下面的界面,說明你註冊成功了,複製key到cherry studio就可以開始愉快使用了。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
支援將話題、訊息匯出到思源筆記。
開啟思源筆記,建立一個筆記本
開啟筆記本進入設定,並複製筆記本ID
將複製的筆記本ID填寫到 Cherry Studio 設定中
填寫思源筆記地址
本地
通常為 http://127.0.0.1:6806
自部署
輸入你的網域名稱 http://note.domain.com
複製思源筆記 API Token
填入 Cherry Studio 設定中並進行檢查
恭喜您,思源筆記的配置已完成 ✅ 接下來即可將 Cherry Studio 內容匯出到您的思源筆記中
此文件由 AI 從中文翻譯而來,尚未經過審閱。
在 Cherry Studio 知識庫中添加的數據全部儲存在本機,在添加過程中會複製一份文件放在 Cherry Studio 資料儲存目錄。
向量資料庫:https://turso.tech/libsql
當文件被添加到 Cherry Studio 知識庫之後,文件會被切分為若干個片段,然後這些片段會交給嵌入模型進行處理。
當使用大模型進行問答的時候,會查詢和問題相關的文字片段一併交給大語言模型處理。
如果對資料隱私有要求,建議使用本機嵌入資料庫和本機大語言模型。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio支援手動和添加訂閱源兩種方式配置黑名單。配置規則參考ublacklist
您可以為搜尋結果添加規則或點擊工具列圖示以屏蔽指定的網站。規則可以通過以下方式指定:匹配模式 (範例:*://*.example.com/*) 或使用正規表示式 (範例:/example\.(net|org)/).
您還可以訂閱公共規則集。該網站列出了一些訂閱: https://iorate.github.io/ublacklist/subscriptions
以下是一些比較推薦的訂閱源連結:
https://git.io/ublacklist
中文
https://raw.githubusercontent.com/laylavish/uBlockOrigin-HUGE-AI-Blocklist/main/list_uBlacklist.txt
AI生成
此文件由 AI 從中文翻譯而來,尚未經過審閱。
開啟 Cherry Studio 設定。
找到 MCP 伺服器 選項。
點擊 新增伺服器。
將 MCP Server 的相關參數填入(參考連結)。可能需要填寫的內容包括:
名稱:自訂一個名稱,例如 fetch-server
類型:選擇 STDIO
命令:填寫 uvx
參數:填寫 mcp-server-fetch
(可能還有其他參數,視具體 Server 而定)
點擊 儲存。
完成上述配置後,Cherry Studio 會自動下載所需的 MCP Server - fetch server。下載完成後,我們就可以開始使用了!注意:當 mcp-server-fetch 配置不成功時,可以嘗試重啟電腦。
在 MCP 伺服器 設定成功新增 MCP 伺服器
從上圖可以看出,結合了 MCP 的 fetch 功能後,Cherry Studio 能夠更好地理解使用者的查詢意圖,並從網路上獲取相關資訊,給出更準確、更全面的回答。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 的翻譯功能為您提供快速、準確的文字翻譯服務,支援多種語言之間的相互翻譯。
翻譯介面主要由以下幾個部分組成:
來源語言選擇區:
任意語言:Cherry Studio 會自動識別來源語言並進行翻譯。
目標語言選擇區:
下拉選單:選擇您希望將文字翻譯成的語言。
設定按鈕:
點擊後將跳轉到 。
捲動同步:
點擊可以切換捲動同步(在任何一邊進行捲動,另一邊也會一起捲動)。
文字輸入框(左側):
輸入或貼上您需要翻譯的文字。
翻譯結果框(右側):
顯示翻譯後的文字。
複製按鈕:點擊按鈕可將翻譯結果複製到剪貼簿。
翻譯按鈕:
點擊此按鈕開始翻譯。
翻譯記錄(左上角):
點擊後可以檢視翻譯歷史記錄。
選擇目標語言:
在目標語言選擇區選擇您希望翻譯成的語言。
輸入或貼上文字:
在左側的文字輸入框中輸入或貼上您要翻譯的文字。
開始翻譯:
點擊 翻譯 按鈕。
檢視和複製結果:
翻譯結果將顯示在右側的翻譯結果框中。
點擊複製按鈕即可將翻譯結果複製到剪貼簿。
Q: 翻譯不準確怎麼辦?
A: AI 翻譯雖然強大,但並非完美。對於專業領域或複雜語境的文字,建議進行人工校對。您也可以嘗試切換不同的模型。
Q: 支援哪些語言?
A: Cherry Studio 翻譯功能支援多種主流語言,具體支援的語言清單請參考 Cherry Studio 的官方網站或應用程式內說明。
Q: 可以翻譯整個檔案嗎?
A: 目前的介面主要用於文字翻譯。對於檔案翻譯,可能需要進入 Cherry Studio 的對話頁面新增檔案進行翻譯。
Q: 翻譯速度慢怎麼辦?
A: 翻譯速度可能受網路連線、文字長度、伺服器負載等因素影響。請確保您的網路連線穩定,並耐心等待。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
一、前往建立帳號登入
二、點擊,進入ModelArts控制台
三、授權
四、點擊側欄鑒權管理,建立API Key(密鑰)並複製
然後在CherryStudio裡建立新服務商
建立完成後填入密鑰
五、點擊側欄模型部署,全部領取
六、點擊呼叫
把①處的地址複製,貼上到CherryStudio的服務商地址中並在結尾加上「#」號
並在結尾加上「#」號
並在結尾加上「#」號
並在結尾加上「#」號
並在結尾加上「#」號
為什麼加「#」號
當然也可不看那裡,直接按照教程操作即可;
也可使用刪除v1/chat/completions的方法填寫,只要會填按自己方式怎麼填都行,不會填務必按照教程操作。
然後把②處模型名稱複製,到CherryStudio中點「+添加」按鈕新建模型
輸入模型名稱,不要自行增減內容,不帶引號,示例怎麼寫就怎麼抄。
點擊添加模型按鈕即可完成。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
當前頁面僅做介面功能的介紹,配置教程可以參考基礎教程中的教學。
在 Cherry Studio 中,單個服務商支援多組 Key 輪流使用,輪詢方式依列表順序循環執行。
多組 Key 需以英文逗號分隔輸入。範例如下:
必須使用英文逗號分隔。
使用內建服務商時通常不需填寫 API 地址,若需修改請嚴格按照對應官方文件提供的地址填寫。
若服務商提供的地址格式為 https://xxx.xxx.com/v1/chat/completions,只需填寫根地址部分(https://xxx.xxx.com)。
Cherry Studio 會自動拼接後續路徑(/v1/chat/completions),未按規範填寫可能導致功能異常。
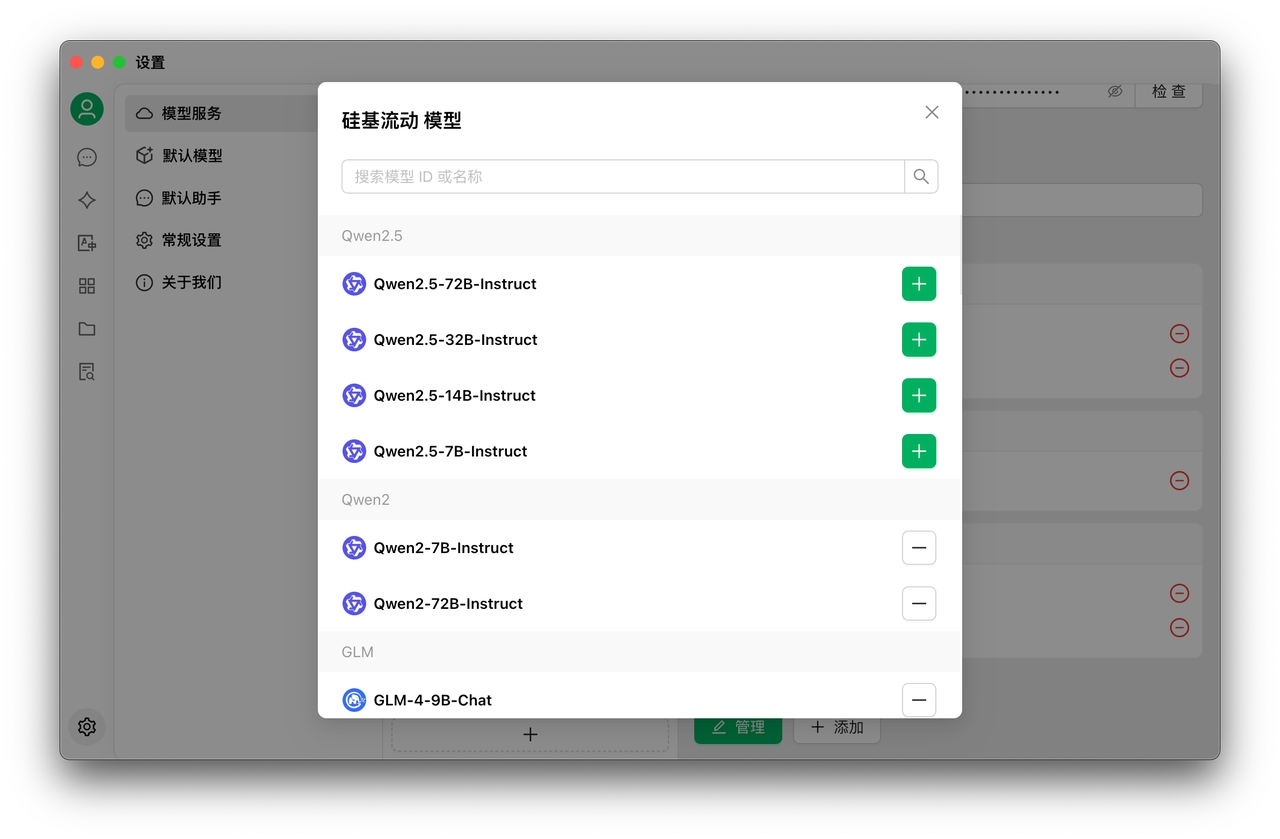
點擊服務商配置頁面左下角的 管理 按鈕,通常會自動獲取該服務商所有支援調用的模型,從彈出清單中點擊模型右側的 + 即可添加至模型列表。
點擊 API 密鑰輸入框旁的檢查按鈕,即可測試配置是否成功。
配置完成後務必開啟右上角的開關,否則服務商將處於未啟用狀態,無法在模型清單中顯示對應模型。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
你是否正在經歷:微信收藏了26篇乾貨文章卻再也沒打開過,電腦裡存著「學習資料」文件夾中散落的10+個文件,想找半年前讀過的某個理論卻只記得零星關鍵詞。而當每日信息量超過大腦處理極限時,90%珍貴知識會在72小時內被遺忘。 現在,通過無問芯穹大模型服務平台API + Cherry Studio打造個人知識庫,可以將被閒置收藏的微信文章、碎片化的課程內容轉化為結構化知識,實現精準調用。
1. 無問芯穹API服務:知識庫「思考中樞」,好用、穩定
作為知識庫的「思考中樞」,無問芯穹大模型服務平台提供 DeepSeek R1 完整功能版等模型版本,提供穩定的 API 服務,**目前註冊後無門檻免費使用。**支援主流嵌入模型 bge、jina 模型來建構知識庫,平台持續更新穩定最新、最強開源模型服務,包含圖片、影片、語音等多種不同模態。
2. Cherry Studio:零代碼搭建知識庫
Cherry Studio是一款易用的AI工具,相較於RAG知識庫開發需1-2個月部署週期,此工具支援零代碼操作,可將Markdown/PDF/網頁等多格式一鍵導入,40MB文件1分鐘完成解析,還可添加電腦本機文件夾、微信收藏夾文章網址、課程筆記。
Step 1:基礎準備
訪問Cherry Studio官網下載適配版本(https://cherry-ai.com/)
註冊帳號:登入無問芯穹大模型服務平台 (https://cloud.infini-ai.com/genstudio/model?cherrystudio)
獲取API金鑰:在「模型廣場」選擇deepseek-r1,點擊創建並獲取APIKEY,複製模型名稱
Step 2:開啟CherryStudio設定,在模型服務中選擇無問芯穹,填寫API金鑰,並啟用無問芯穹模型服務
完成以上步驟,在互動時選擇所需大模型,即可在CherryStudio中使用無問芯穹API服務。 為方便使用,此處可設定「預設模型」
Step 3:添加知識庫
選擇無問芯穹大模型服務平台的嵌入模型bge系列或jina系列任一版本
導入學習資料後,輸入"梳理〈機器學習〉第三章核心公式推導"
附生成結果圖
此文件由 AI 從中文翻譯而來,尚未經過審閱。
ModelScope MCP 伺服器 需要將 Cherry Studio 升級至 v1.2.9 或更高版本。
在 v1.2.9 版本中,Cherry Studio 與 ModelScope 魔搭 達成官方合作,大幅簡化了 MCP 伺服器新增的操作步驟,避免配置過程出錯,而且可以在 ModelScope 社群發現海量 MCP 伺服器。接下來跟隨操作步驟,一起看下如何在 Cherry Studio 中同步 ModelScope 的 MCP 伺服器。
點擊設定中的 MCP 伺服器設定,選擇 同步伺服器
選擇 ModelScope,並瀏覽發現 MCP 服務
註冊登入 ModelScope,並檢視 MCP 服務詳情;
在 MCP 服務詳情中,選擇連接服務;
點擊 Cherry Studio 中的「取得api令牌」,跳轉至 ModelScope 官網,複製 api 令牌,再回到 Cherry Studio 中貼上。
在 Cherry Studio 的 MCP 伺服器清單中,可以看到 ModelScope 連接的 MCP 服務,並能在對話中呼叫。
後續在 ModelScope 網頁新增的 MCP 伺服器,直接點選 同步伺服器 即可實現增量新增 MCP 伺服器。
透過以上步驟,你已成功掌握如何在 Cherry Studio 中便捷地同步 ModelScope 上的 MCP 伺服器。整個配置流程不僅大幅簡化,有效避免手動設定的繁瑣和潛在錯誤,更能輕鬆存取 ModelScope 社群提供的海量 MCP 伺服器資源。
現在就開始探索和使用這些強大的 MCP 服務,為你的 Cherry Studio 體驗帶來更多便利與可能性吧!
此文件由 AI 從中文翻譯而來,尚未經過審閱。
調用鏈(又稱「trace」)為用戶提供對話的洞察能力,幫助用戶覺察模型、知識庫、MCP、網路搜索等在對話過程中的具體表現。它是一個基於 實現的可觀測工具,透過端側採集、儲存、處理資料實現視覺化,為定位問題、最佳化效果提供量化評估依據。
每次對話對應一條 trace 資料,一條 trace 由多個 span 組成,每個 span 對應 Cherry Studio 的一個程式處理邏輯如呼叫模型會話、呼叫 MCP 、呼叫知識庫、呼叫網路搜索等。trace 以樹狀結構展示,span 為樹節點,主要資料包括耗時、token 使用量,當然在 span 詳情還可檢視其具體的輸入輸出。
預設情況下,Cherry Studio 安裝之後,Trace 是隱藏的狀態。需要在「設定」-「常規設定」 - 「開發者模式」中開啟,如下圖:
且對於之前的會話不會產生 Trace 記錄,只會在新的問答產生之後才會產生 Trace 記錄。所產生的記錄儲存在本地,如需要徹底清除 Trace ,可以透過「設定」 - 「資料設定」 - 「資料目錄」 - 「清除快取」進行清除,也可透過手動 刪除 ~/.cherrystudio/trace 下的檔案進行清除,如下圖:
在 Cherry Studio 對話方塊中點選調用鏈檢視調用鏈的全鏈路資料。無論在對話過程中呼叫了模型,還是網路搜索、知識庫、MCP,都可以在調用鏈視窗中檢視到全鏈路呼叫資料。
若想要檢視調用鏈中模型的詳情,可以點選模型呼叫節點,檢視其輸入、輸出詳情。
若想要檢視調用鏈中網路搜索的詳情,可以點選網路搜索呼叫節點,檢視其輸入、輸出詳情。在詳情中,可檢視到呼叫網路搜索查詢的問題和其傳回的結果。
若想要檢視調用鏈中知識庫的詳情,可以點選知識庫呼叫節點,檢視其輸入、輸出詳情。在詳情中,可檢視到呼叫知識庫查詢的問題和其傳回的答案。
若想要檢視調用鏈中 MCP 的詳情,可以點選 MCP 呼叫節點,檢視其輸入、輸出詳情。在詳情中,可檢視到呼叫此 MCP Server tool 的入參和 tool 的傳回。
當前功能由阿里雲 團隊提供,如有問題或建議,請進入釘釘群 ( 群號: 21958624 ) 與開發者進行深度溝通。
\
此文件由 AI 從中文翻譯而來,尚未經過審閱。
MCP(Model Context Protocol) 是一種開源協議,旨在以標準化的方式向大語言模型(LLM)提供上下文資訊。更多關於 MCP 的介紹請見
下面以 fetch 功能為例,演示如何在 Cherry Studio 中使用 MCP,可以在 中查找詳情。
Cherry Studio 目前只使用內建的 和 ,不會復用系統中已經安裝的 uv 和 bun。
在 設定 - MCP 伺服器 中,點擊 安裝 按鈕,即可自動下載並安裝。因為是直接從 GitHub 上下載,速度可能會比較慢,且有較大可能失敗。安裝成功與否,以下文提到的資料夾內是否有檔案為準。
可執行程序安裝目錄:
Windows: C:\Users\使用者名稱\.cherrystudio\bin
macOS、Linux: ~/.cherrystudio/bin
無法正常安裝的情況下:
可將系統中的相對應命令使用軟連結的方式連結到這裡,如果沒有對應目錄,需要手動建立。也可以手動下載可執行檔案放到這個目錄下面:
Bun: UV:
此文件由 AI 從中文翻譯而來,尚未經過審閱。
聯繫人:王先生
📱:18954281942 (非客服電話)
商用授權詳情:










































sk-xxxx1,sk-xxxx2,sk-xxxx3,sk-xxxx4


















































此文件由 AI 從中文翻譯而來,尚未經過審閱。
歡迎使用 Cherry Studio(以下簡稱「本軟體」或「我們」)。我們高度重視您的隱私保護,本隱私協議將說明我們如何處理與保護您的個人信息和數據。請在使用本軟體前仔細閱讀並理解本協議:
為了優化用戶體驗和提升軟體質量,我們僅可能會匿名收集以下非個人化信息:
• 軟體版本信息;
• 軟體功能的活躍度、使用頻次;
• 匿名的崩潰、錯誤日誌信息;
上述信息完全匿名,不會涉及任何個人身份數據,也無法關聯到您的個人信息。
為了最大限度保護您的隱私安全,我們明確承諾:
• 不會收集、保存、傳輸或處理您輸入到本軟體中的模型服務 API Key 信息;
• 不會收集、保存、傳輸或處理您在使用本軟體過程中產生的任何對話數據,包括但不限於聊天內容、指令信息、知識庫信息、向量數據及其他自定義內容;
• 不會收集、保存、傳輸或處理任何可識別個人身份的敏感信息。
本軟體採用您自行申請並配置的第三方模型服務提供商的 API Key,以完成相關模型的調用與對話功能。您使用的模型服務(例如大模型、API 接口等)由您選擇的第三方提供商提供並完全由其負責,Cherry Studio 僅作為本地工具提供與第三方模型服務的接口調用功能。
因此:
• 所有您與大模型服務產生的對話數據與 Cherry Studio 無關,我們既不參與數據的存儲,也不會進行任何形式的數據傳輸或中轉;
• 您需要自行查看並接受對應第三方模型服務提供商的隱私協議及相關政策,這些服務的隱私協議可訪問各提供商官方網站進行查看。
您需自行承擔因使用第三方模型服務提供商而可能涉及的隱私風險。具體隱私政策、數據安全措施與相關責任,請查閱所選模型服務提供商官方網站相關內容,我們對此不承擔任何責任。
本協議可能隨軟體版本更新進行適當調整,請您定期關注。協議發生實質性變更時,我們將以適當方式提醒您。
若您對本協議內容或 Cherry Studio 隱私保護措施存在任何疑問,歡迎隨時聯繫我們。
感謝您選擇並信任 Cherry Studio,我們將持續為您提供安全可靠的產品體驗。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 是一個免費開源的專案,隨著專案規模擴大,專案小組的工作量也日漸增多。為了減少溝通成本並能快速高效解決您的問題,我們希望大家在提問前盡可能按照以下步驟處理遇到的問題,讓專案小組能將更多時間投入專案維護和開發。感謝您的配合!
大多數基礎問題透過仔細查閱文件都能解決:
軟體功能和使用問題可查閱功能介紹文件;
高頻問題收錄在常見問題頁面,請先在此查看解決方案;
複雜問題可直接使用搜尋功能或在搜尋框提問;
務必仔細閱讀每篇文件中的提示框內容,能幫您避免許多問題;
在 GitHub 的 Issue 頁面查看或搜尋類似問題及解決方案。
與客戶端功能無關的問題(如模型報錯、回答不符預期、參數設置等),建議先在網路上搜尋解決方案,或將報錯內容和問題描述提供給AI尋找解決方案。
若上述方法仍未解決問題,請至官方 TG頻道、Discord頻道、(一鍵進群)詳細描述問題尋求協助:
模型報錯:提供完整介面截圖及控制台報錯資訊(敏感資訊可打碼,但需保留模型名稱、參數設置和報錯內容)。控制台報錯資訊查看方法點此
軟體Bug:提供具體錯誤描述及詳細。若為偶發問題,請詳細描述問題發生時的場景、背景與配置參數
同時請註明平台資訊(Windows/Mac/Linux)與軟體版本號
文件請求或建議
請聯繫 TG頻道 @Wangmouuu 或 QQ(1355873789),或發送郵件至:[email protected]




此文件由 AI 從中文翻譯而來,尚未經過審閱。
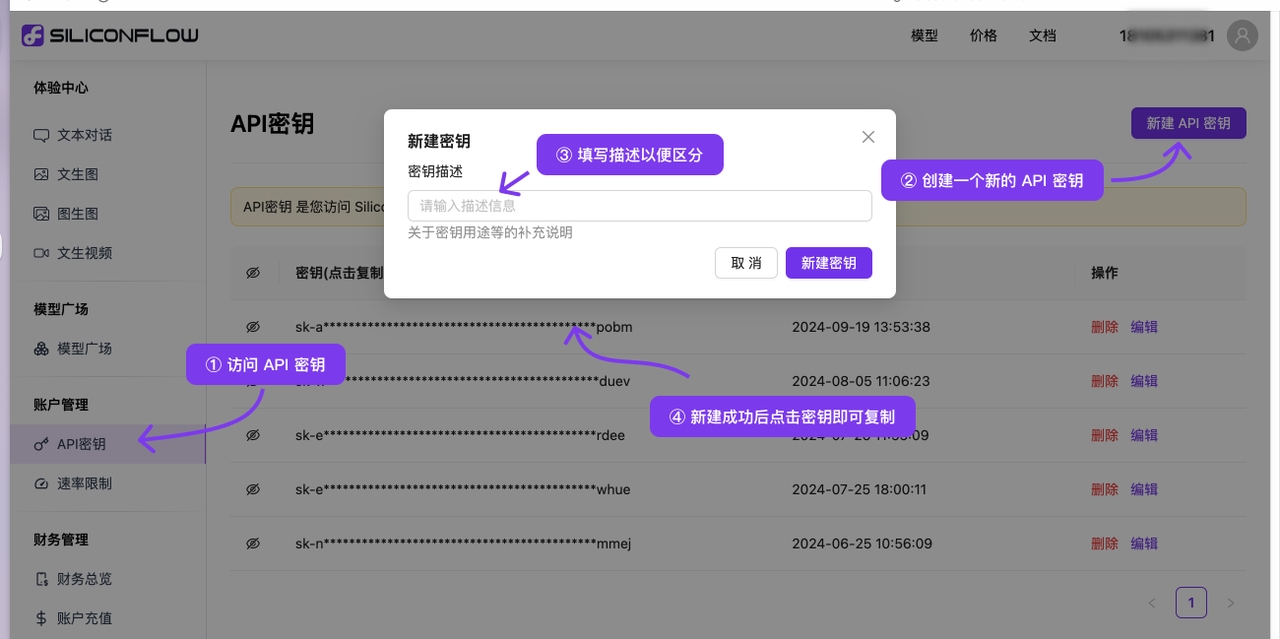
點擊側邊欄下方的 API Key 管理
建立 API Key
建立成功後,點擊已建立 API Key 後的眼睛圖示開啟並複製
將複製的 API Key 填入 Cherry Studio 後,開啟服務商開關
在方舟控制台側邊欄最下方的 開通管理 開通需要使用的模型,可依需求開通豆包系列和 DeepSeek 等模型
在 模型列表文件 中,找到所需模型對應的 模型ID
開啟 Cherry Studio 的 模型服務 設定找到火山引擎
點擊新增,將取得的 模型ID 複製至 模型ID 文字輸入框
依此流程逐一新增模型
API 地址有兩種寫法:
第一種為客戶端預設的:https://ark.cn-beijing.volces.com/api/v3/
第二種寫法為:https://ark.cn-beijing.volces.com/api/v3/chat/completions#
此文件由 AI 從中文翻譯而來,尚未經過審閱。
ModelScope 是新一代開源模型即服務(MaaS)共享平台,致力於為泛 AI 開發者提供靈活、易用、低成本的一站式模型服務解決方案,讓模型應用更簡單!
通過 API-Inference 服務化能力,平台將開源模型標準化為可調用的 API 介面,開發者可輕量、快速地整合模型能力至各類 AI 應用,支援工具調用、原型開發等創新場景。
✅ 免費額度:每日提供 2000 次免費 API 調用額度(計費規則)
✅ 豐富模型庫:覆蓋 NLP、CV、語音、多模態等 1000+ 開源模型
✅ 即開即用:無需部署,通過 RESTful API 快速調用
登入平台
造訪 ModelScope 官網 → 點擊右上角登入 → 選擇認證方式
開啟 Cherry Studio → 設定 → 模型服務 → ModelScope
在 API 金鑰 欄貼上複製的令牌
點擊 保存 完成授權
查找支援 API 的模型
篩選條件:勾選 API-Inference(或認準模型卡片上的 API 圖示)
API-Inference 覆蓋的模型範圍,主要根據模型在魔搭社群中的關注程度(參考了點讚、下載等數據)來判斷。因此,在能力更強、關注度更高的下一代開源模型發佈之後,支援的模型清單也會持續迭代。
獲取模型 ID
進入目標模型詳情頁 → 複製 Model ID(格式如 damo/nlp_structbert_sentiment-classification_chinese-base)
填入 Cherry Studio
在模型服務設定頁的 模型 ID 欄輸入 ID → 選擇任務類型 → 完成設定
🎫 免費額度:每位用戶 每日 2000 次 API 調用(以官網最新規則為準)
🔁 額度重置:每日 UTC+8 00:00 自動重置,不支援跨日累計或升級
💡 超額處理:
達到當日上限後 API 將返回 429 錯誤
解決方案:切換備用帳號 / 使用其他平台 / 優化調用頻率
登入 ModelScope → 點擊右上角 用戶名 → API 使用情況
⚠️ 注意:推論 API-Inference 每天提供 2000 次的免費調用額度。更多調用需求可考慮使用阿里雲百煉等雲端服務。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 資料備份支援透過 WebDAV 的方式進行備份。你可以選擇合適的 WebDAV 服務來進行雲端備份。
基於 WebDAV 可以通過 A電腦 WebDAV B電腦 的方式來實現多端資料同步。
登入堅果雲,點擊右上角使用者名稱,選擇「帳戶資訊」:
選擇「安全選項」,點擊「新增應用」
輸入應用名稱,生成隨機密碼;
複製記錄密碼;
取得伺服器地址、帳戶和密碼;
在 Cherry Studio 設定——資料設定中,填寫 WebDAV 資訊;
選擇備份或者恢復資料,並可以設定自動備份的時間週期。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
自動安裝 MCP 需要將 Cherry Studio 升級至 v1.1.18 或更高版本。
除了手動安裝外,Cherry Studio 還內建了 @mcpmarket/mcp-auto-install 工具,這是一個更便捷的 MCP 伺服器安裝方式。你只需要在支援 MCP 服務的大型模型對話中輸入相應的指令即可。
測試階段提醒:
@mcpmarket/mcp-auto-install 目前仍處於測試階段
效果依賴大型模型的「智商」,有些會自動添加,有些還是需要在 MCP 設定中再手動更改某些參數
目前搜尋來源是從 @modelcontextprotocol 中進行搜尋,可以自行設定(下方說明)
例如,你可以輸入:
幫我安裝一個 filesystem mcp server系統會自動識別你的需求,並透過 @mcpmarket/mcp-auto-install 完成安裝。這個工具支援多種類型的 MCP 伺服器,包括但不限於:
filesystem(檔案系統)
fetch(網路請求)
sqlite(資料庫)
等等...
MCP_PACKAGE_SCOPES 變數可以自訂 MCP 服務搜尋來源,預設值為:
@modelcontextprotocol,可以自訂設定。
@mcpmarket/mcp-auto-install 函式庫的介紹此文件由 AI 從中文翻譯而來,尚未經過審閱。
為了讓每一位開發者和用戶都能輕鬆體驗前沿大模型的能力,智譜免費向 Cherry Studio 的用戶開放 GLM-4.5-Air 模型。作為專為智能體(Agent)應用打造的高效基礎模型,GLM-4.5-Air 在性能與成本之間實現了出色平衡,是構建智能應用的理想選擇。
🚀 什麼是 GLM-4.5-Air?
GLM-4.5-Air 是智譜最新推出的高性能語言模型,採用先進的混合專家架構(Mixture-of-Experts, MoE),在保持卓越推理能力的同時,顯著降低計算資源消耗。
總參數量:1060 億
激活參數量:120 億
通過精簡設計,GLM-4.5-Air 實現了更高的推理效率,適合在資源受限環境下部署,同時仍能勝任複雜任務處理。
📚 統一訓練流程,夯實智能基礎
GLM-4.5-Air 與旗艦系列共享一致的訓練流程,確保其具備扎實的通用能力基礎:
大規模預訓練:在高達 15 萬億 token 的通用語料上完成訓練,建構廣泛的知識理解能力;
專項領域優化:在程式碼生成、邏輯推理、智能體互動等關鍵任務上進行強化訓練;
長上下文支援:上下文長度擴展至 128K tokens,可處理長文件、複雜對話或大型程式碼項目;
強化學習增強:通過 RL 優化模型在推理規劃、工具調用等方面的決策能力。
這一訓練體系為 GLM-4.5-Air 賦予了出色的泛化能力和任務適應性。
⚙️ 專為智能體優化的核心能力
GLM-4.5-Air 針對智能體應用場景進行了深度適配,具備以下實用能力:
✅ 工具調用支援:可通過標準化介面調用外部工具,實現任務自動化 ✅ 網頁瀏覽與資訊提取:可配合瀏覽器外掛程式完成動態內容理解與互動 ✅ 軟體工程輔助:支援需求解析、程式碼生成、缺陷識別與修復 ✅ 前端開發支援:對 HTML、CSS、JavaScript 等前端技術有良好理解與生成能力
該模型可靈活整合至 Claude Code、Roo Code 等程式碼智能體框架,也可作為任意自訂 Agent 的核心引擎使用。
💡 智能「思考模式」,靈活響應各類請求
GLM-4.5-Air 支援混合推理模式,用戶可通過 thinking.type 參數控制是否啟用深度思考:
enabled:啟用思考,適合需要分步推理或規劃的複雜任務
disabled:禁用思考,用於簡單查詢或即時響應
預設設定為 動態思考模式,模型自動判斷是否需要深入分析
🌟 高效低成本,部署更輕鬆
GLM-4.5-Air 在性能與成本之間實現了優秀平衡,特別適合實際業務部署:
⚡ 生成速度超 100 tokens/秒,響應迅速,支援低延遲互動
💰 API 成本極低:輸入僅 0.8 元/百萬 tokens,輸出 2 元/百萬 tokens
🖥️ 激活參數少,算力需求低,易於在本地或雲端高並發運行
真正實現「高性能、低門檻」的 AI 服務體驗。
🧠 聚焦實用能力:智能程式碼生成
GLM-4.5-Air 在程式碼生成方面表現穩定,支援:
覆蓋 Python、JavaScript、Java 等主流語言
根據自然語言指令生成結構清晰、可維護性強的程式碼
減少模板化輸出,貼近真實開發場景需求
適用於快速原型建構、自動化補全、Bug 修復等高頻開發任務。
立即免費體驗 GLM-4.5-Air,開啟你的智能體開發之旅! 無論你是想打造自動化助手、程式設計夥伴,還是探索下一代 AI 應用,GLM-4.5-Air 都將是你高效可靠的 AI 引擎。
📘 立即接入,釋放創造力!
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Ollama 是一款優秀的開源工具,讓您可以在本地輕鬆執行和管理各種大型語言模型(LLMs)。Cherry Studio 現已支援 Ollama 整合,讓您可以在熟悉的介面中,直接與本地部署的 LLM 進行互動,無需依賴雲端服務!
Ollama 是一個簡化大型語言模型(LLM)部署和使用的工具。它具有以下特點:
本地執行: 模型完全在您的本地電腦上執行,無需連網,保護您的隱私和資料安全。
簡單易用: 通過簡單的命令列指令,即可下載、執行和管理各種 LLM。
模型豐富: 支援 Llama 2、Deepseek、Mistral、Gemma 等多種流行的開源模型。
跨平台: 支援 macOS、Windows 和 Linux 系統。
開放API:支援與OpenAI兼容的介面,可以和其他工具整合。
無需雲端服務: 不再受限於雲端 API 的配額和費用,盡情體驗本地 LLM 的強大功能。
資料隱私: 您的所有對話資料都保留在本地,無需擔心隱私洩露。
離線可用: 即使在沒有網路連線的情況下,也能繼續與 LLM 進行互動。
客製化: 可以根據您的需求,選擇和配置最適合您的 LLM。
首先,您需要在您的電腦上安裝並執行 Ollama。請按照以下步驟操作:
下載 Ollama: 瀏覽 Ollama 官網(),根據您的作業系統下載對應的安裝包。 在 Linux 下,可直接執行命令安裝ollama:
安裝 Ollama: 按照安裝程式的指引完成安裝。
下載模型: 開啟終端機(或命令提示字元),使用 ollama run 指令下載您想要使用的模型。例如,要下載 Llama 2 模型,可以執行:
Ollama 會自動下載並執行該模型。
保持 Ollama 執行: 在您使用 Cherry Studio 與 Ollama 模型互動期間,請確保 Ollama 保持執行狀態。
接下來,在 Cherry Studio 中添加 Ollama 作為自訂 AI 服務商:
開啟設定: 在 Cherry Studio 介面左側導覽列中,點擊「設定」(齒輪圖示)。
進入模型服務: 在設定頁面中,選擇「模型服務」選項卡。
添加供應商: 點擊清單中的 Ollama。
在服務商清單中找到剛剛添加的 Ollama,並進行詳細配置:
啟用狀態:
確保 Ollama 服務商最右側的開關已開啟,表示已啟用。
API 密鑰:
Ollama 預設不需要 API 密鑰。您可以將此欄位留空,或者填寫任意內容。
API 地址:
填寫 Ollama 提供的本地 API 地址。通常情況下,地址為:
如果修改了連接埠,請自行更改。
保持活躍時間: 此選項是設定工作階段的保持時間,單位是分鐘。如果在設定時間內沒有新的對話,Cherry Studio 會自動斷開與 Ollama 的連線,釋放資源。
模型管理:
點擊「+ 添加」按鈕,手動添加您在 Ollama 中已經下載的模型名稱。
比如您已經通過ollama run llama3.2下載了llama3.2模型, 那麼此處可以填入llama3.2
點擊「管理」按鈕,可以對已添加的模型進行編輯或刪除。
完成以上配置後,您就可以在 Cherry Studio 的聊天介面中,選擇 Ollama 服務商和您已下載的模型,開始與本地 LLM 進行對話了!
首次執行模型: 第一次執行某個模型時,Ollama 需要下載模型檔案,可能需要較長時間,請耐心等待。
檢視可用模型: 在終端機中執行 ollama list 命令,可以檢視您已下載的 Ollama 模型清單。
硬體要求: 執行大型語言模型需要一定的計算資源(CPU、記憶體、GPU),請確保您的電腦配置滿足模型的要求。
Ollama 文件: 可以點擊配置頁面中的查看Ollama文件及模型連結快速跳轉至Ollama官網文件。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 是一款多模型桌面客戶端,目前支援:Windows、Linux、MacOS 系列電腦安裝包。它聚合主流 LLM 模型,提供多場景輔助。使用者可透過智慧會話管理、開源訂製、多主題介面來提升工作效率。
Cherry Studio 現已與 PPIO 高效能 API 通道深度適配——透過企業級算力保障,實現 DeepSeek-R1/V3 高速響應 與 99.9% 服務可用性,帶給您快速流暢的體驗。
下方教學包含完整接入方案(含金鑰配置),3 分鐘開啟「Cherry Studio 智慧調度 + PPIO 高效能 API」的進階模式。
首先前往官網下載 Cherry Studio: (如果進不去可以開啟下方的夸克網盤連結下載需要的版本:
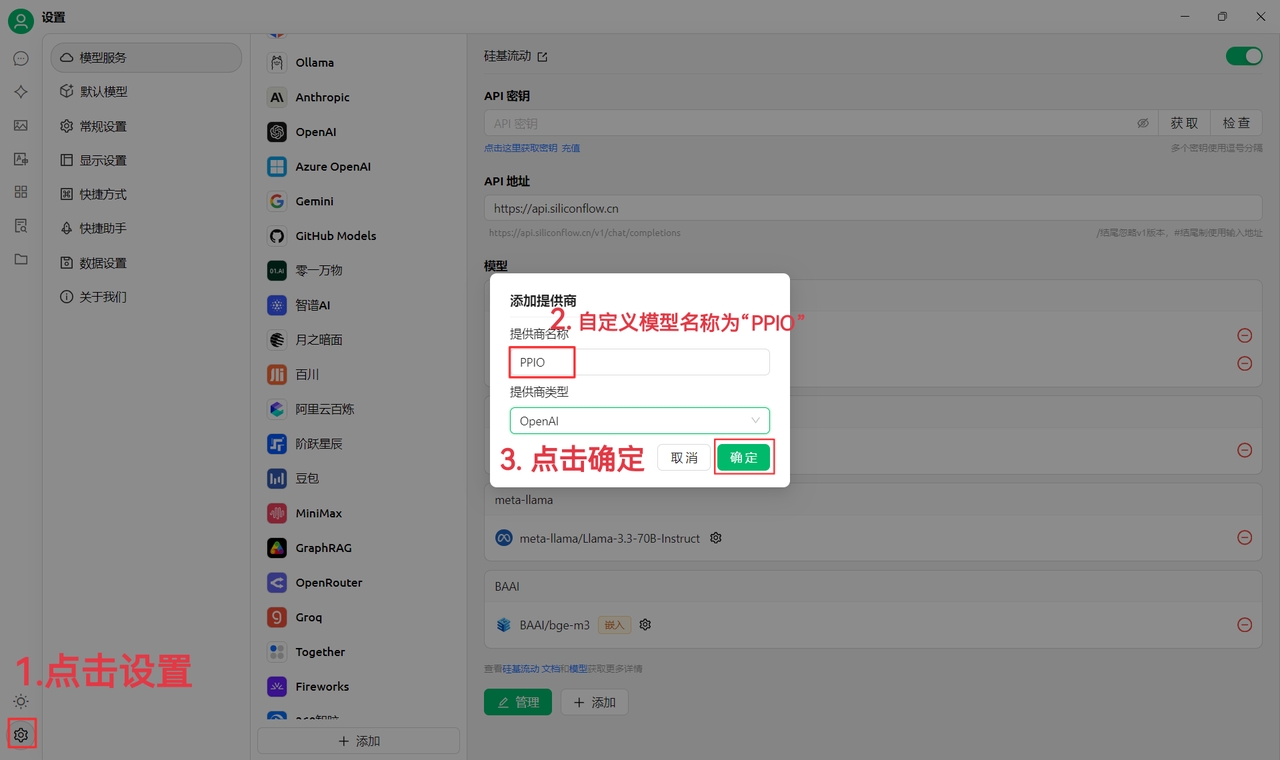
(1)先點選左下角設定,自訂提供商名稱為:PPIO,點選「確定」
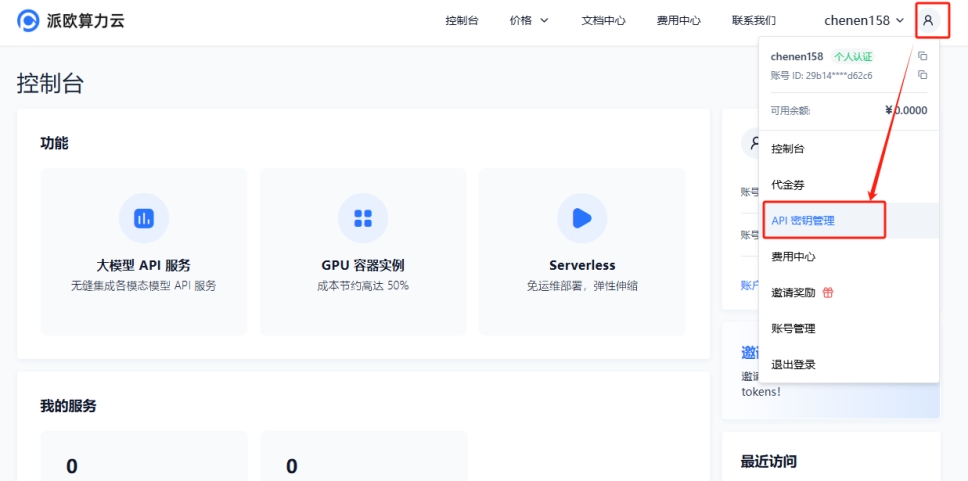
(2)前往 ,點選【使用者頭像】—【API 金鑰管理】進入控制檯
點選【+ 建立】按鈕來建立新的 API 金鑰。自訂一個金鑰名稱,產生的金鑰僅在產生時呈現,務必複製並儲存到文件中,以免影響後續使用
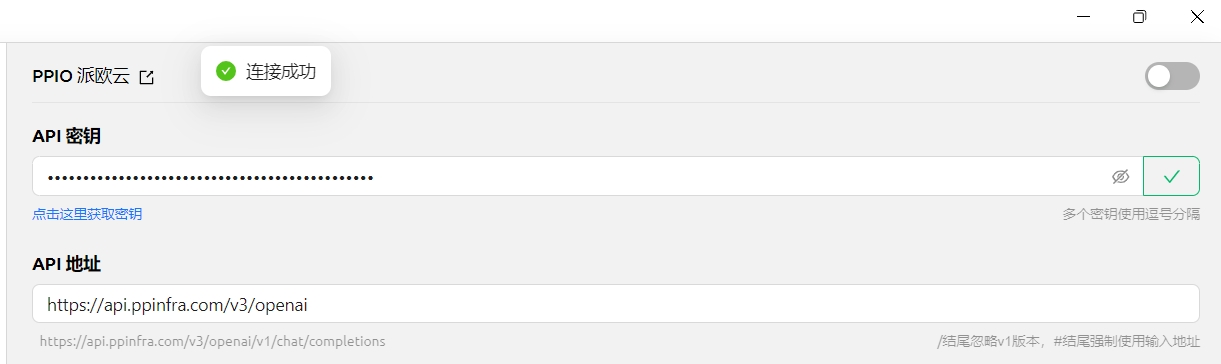
(3)在 CherryStudio 填入金鑰 點選設定,選擇【PPIO 派歐雲】,輸入官網產生的 API 金鑰,最後點選【檢查】
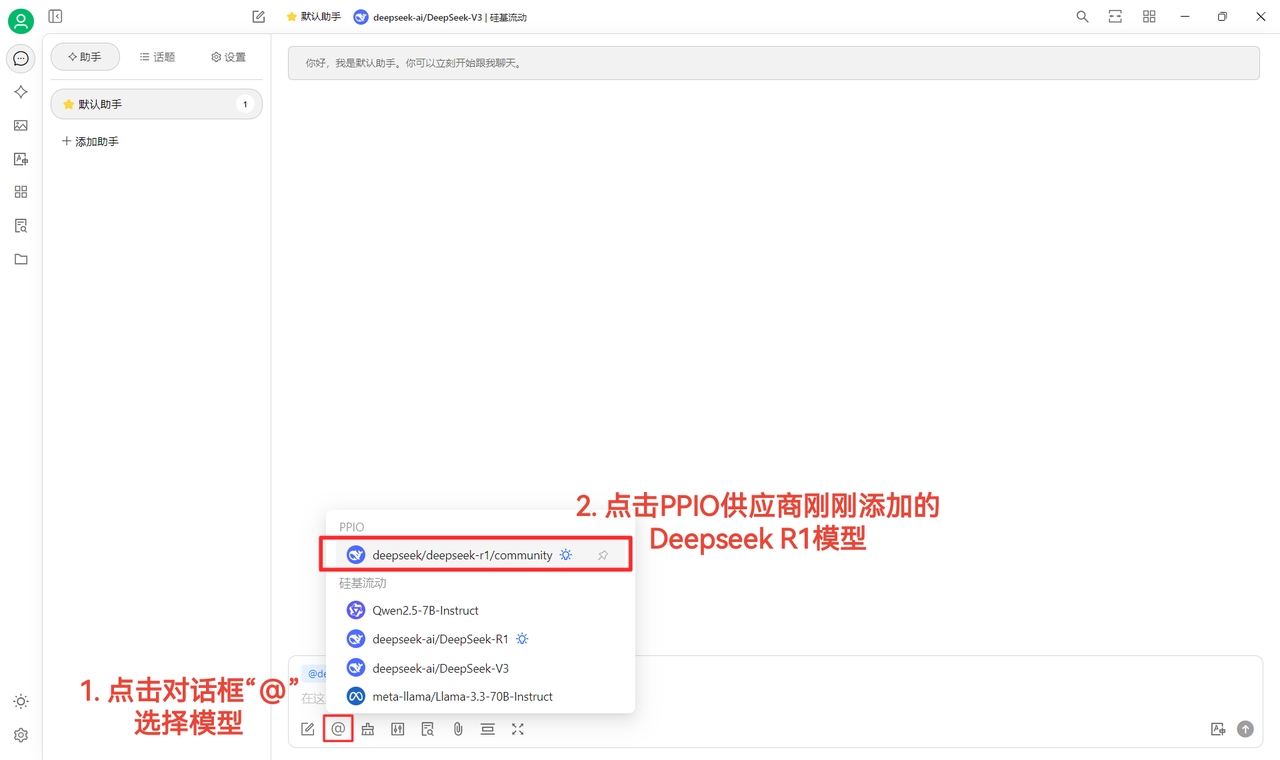
(4)選擇模型:以 deepseek/deepseek-r1/community 為例,如需更換其他模型,可直接更換。
DeepSeek R1 和 V3 community 版本僅供大家嘗鮮,也是全參數滿血版模型,穩定性和效果無差異,如需大量呼叫則須 充值並切換到非 community 版本。
(1)點選【檢查】顯示連線成功後即可正常使用
(2)最後點選【@】選擇 PPIO 供應商下剛剛新增的 DeepSeek R1 模型,即可成功開始聊天~
【部分素材來源:】
若您更傾向直觀學習,我們在 B 站準備了影片教學。透過手把手教學,助您快速掌握「PPIO API+Cherry Studio」的配置方法,點選下方連結直達影片,開啟流暢開發體驗 →
【影片素材來源:sola】
此文件由 AI 從中文翻譯而來,尚未經過審閱。
知名 MaaS 服務平台「矽基流動」為大家免費提供 Qwen3-8B 模型的調用服務。作為通義千問 Qwen3 系列中的高性價比成員,Qwen3-8B 以小巧體積實現強大能力,是智能應用與高效開發的理想選擇。
🚀 什麼是 Qwen3-8B?
Qwen3-8B 是阿里巴巴於 2025 年 4 月發佈的通義千問第三代大模型系列中的 80 億參數密集模型,採用 Apache 2.0 開源協議,可自由用於商業與研究場景。
總參數量:80 億
架構類型:Dense(純稠密結構)
上下文長度:128K tokens
支援多語言:涵蓋 119 種語言和方言
儘管體積小巧,Qwen3-8B 在推理、程式碼、數學和 Agent 能力方面表現穩定,性能媲美前代更大的模型,在實際應用中展現出極高的實用性。
📚 強大訓練基礎,小模型也有大智慧
Qwen3-8B 基於 約 36 萬億 token 的高質量多語言數據完成預訓練,涵蓋網頁文本、技術文件、程式碼庫與專業領域合成數據,知識覆蓋面廣。
其後訓練階段引入了四階段強化流程,特別優化了以下能力:
✅ 自然語言理解與生成 ✅ 數學推理與邏輯分析 ✅ 多語言翻譯與表達 ✅ 工具調用與任務規劃
得益於訓練體系的全面升級,Qwen3-8B 的實際表現接近甚至超越 Qwen2.5-14B,實現顯著的參數效率躍遷。\
💡 混合推理模式:思考 or 快速回應?
Qwen3-8B 支援 「思考模式」與「非思考模式」 的靈活切換,用戶可根據任務複雜度自主選擇回應方式。
通過以下方式控制模式:
API 參數設置:enable_thinking=True/False
提示詞指令:在輸入中添加 /think 或 /no_think
該設計讓用戶在回應速度與推理深度之間自由權衡,提升使用體驗。
⚙️ 原生支援 Agent 能力,賦能智能應用
Qwen3-8B 具備出色的 Agent 化能力,可輕鬆整合到各類自動化系統中:
🔹 函數調用(Function Calling):支援結構化工具調用 🔹 MCP 協議相容:原生支援模型上下文協議,便於擴展外部能力 🔹 多工具協同:可接入搜索、計算器、程式碼執行等插件
推薦結合 Qwen-Agent 框架 使用,快速建構具備記憶、規劃與執行能力的智能助手。
🌐 廣泛語言支援,面向全球應用
Qwen3-8B 支援包括中文、英文、阿拉伯語、西班牙語、日語、韓語、印尼語等在內的 119 種語言和方言,適用於國際化產品開發、跨語言客服、多語種內容生成等場景。
對中文理解尤為出色,支援簡體、繁體及粵語表達,適用於港澳台及海外華人市場。
🧠 實用能力強,場景覆蓋廣
Qwen3-8B 在多個高頻應用場景中表現優異:
✅ 程式碼生成:支援 Python、JavaScript、Java 等主流語言,能根據需求生成可運行程式碼 ✅ 數學推理:在 GSM8K 等基準中表現穩定,適合教育類應用 ✅ 內容創作:撰寫郵件、報告、文案,結構清晰、語言自然 ✅ 智能助手:可建構個人知識庫問答、日程管理、信息提取等輕量級 AI 助手
現在就通過 矽基流動 免費體驗 Qwen3-8B,開啟你的輕量 AI 應用之旅!\
📘 立即使用,讓 AI 觸手可及!
数据设置→Obsidian配置
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 支援與 Obsidian 聯動,將完整對話或單條對話匯出到 Obsidian 庫中。
該過程無需安裝額外的 Obsidian 外掛。但由於 Cherry Studio 匯入到 Obsidian 採用的原理與 Obsidian Web Clipper 類似,因此建議使用者最好將 Obsidian 升級至最新版本(當前 Obsidian 版本至少應大於 1.7.2),以免。
開啟 Cherry Studio 的_設定_ → 資料設定 → _Obsidian 設定_選單,下拉選單中會自動出現在本機開啟過的 Obsidian 庫名,選擇你的目標 Obsidian 庫:
匯出完整對話
回到 Cherry Studio 的對話介面,右鍵點擊對話,選擇_匯出_,點擊_匯出到 Obsidian_:
此時會彈出一個視窗,用於調整這條匯出到 Obsidian 中的對話筆記的 Properties(屬性)、所放置在Obsidian的資料夾位置以及匯出到 Obsidian 中的處理方式:
保管庫:點擊下拉選單可以選擇其他 Obsidian 庫
路徑:點擊下拉選單可以選擇存放匯出對話筆記的資料夾
作為 Obsidian 筆記屬性(Properties):
標籤(tags)
建立時間(created)
來源(source)
匯出到 Obsidian 中的處理方式有以下三種可選:
新建(如果存在就覆蓋):在路徑處填寫的資料夾 裡新建一篇對話筆記,如果存在同名筆記則會覆蓋舊筆記
前置:在已存在同名筆記的情況下,將選中的對話內容匯出新增到該筆記的開頭
追加:在已存在同名筆記的情況下,將選中的對話內容匯出新增到該筆記的末尾
選擇完所有選項後,點選確定即可匯出完整對話到對應的 Obsidian 庫的對應資料夾。
匯出單條對話
對於單條對話的匯出,則點擊對話下方的_三條槓選單_,選擇_匯出_,點擊_匯出到 Obsidian_:
之後也會彈出與匯出完整對話時一樣的視窗,要求你配置筆記屬性與筆記的處理方式,一樣按照完成即可。
🎉 到這裡,恭喜你完成了 Cherry Studio 聯動 Obsidian 的所有配置,並完整地將匯出流程走了一遍,enjoy yourselves!
開啟 Obsidian 庫,建立一個用於儲存匯出對話的資料夾(圖中以 Cherry Studio 資料夾為例):
注意記住左下角框出來的文字,這裡是你的保管庫名。
在 Cherry Studio 的_設定_ → 資料設定 → _Obsidian 設定_選單中,輸入在中獲取到的保管庫名與資料夾名:
全域標籤處是可選的,可設定所有對話匯出後在 Obsidian 中的標籤,按需填寫。
匯出完整對話
回到 Cherry Studio 的對話介面,右鍵點擊對話,選擇_匯出_,點擊_匯出到 Obsidian_。
此時會彈出一個視窗,用於調整這條匯出到 Obsidian 中的對話筆記的 Properties(屬性),以及匯出到 Obsidian 中的處理方式。匯出到 Obsidian 中的處理方式有以下三種可選:
新建(如果存在就覆蓋):在中填寫的資料夾 裡新建一篇對話筆記,如果存在同名筆記則會覆蓋舊筆記
前置:在已存在同名筆記的情況下,將選中的對話內容匯出新增到該筆記的開頭
追加:在已存在同名筆記的情況下,將選中的對話內容匯出新增到該筆記的末尾
匯出單條對話
對於單條對話的匯出,則點擊對話下方的_三條槓選單_,選擇_匯出_,點擊_匯出到 Obsidian_。
之後也會彈出與匯出完整對話時一樣的視窗,要求你配置筆記屬性與筆記的處理方式,一樣按照完成即可。
🎉 到這裡,恭喜你完成了 Cherry Studio 聯動 Obsidian 的所有配置,並完整地將匯出流程走了一遍,enjoy yourselves!
如何在 Cherry Studio 使用联网模式
此文件由 AI 從中文翻譯而來,尚未經過審閱。
在 Cherry Studio 的提問視窗,點擊 【小地球】 圖示即可開啟連網。
模式1:模型服務商的大模型自帶連網功能
這種情況下,開啟連網後,直接就可以使用連網服務了,非常簡單。
可以透過問答介面上方,模型名字後面是否帶有小地圖標記,迅速判斷該模型是否支援連網。
在模型管理頁面,這個方法也可以讓你快速分辨出哪些模型支援連網,哪些不支援。
Cherry Studio 目前已支援的連網模型服務商有
Google Gemini
OpenRouter(全部模型支援連網)
騰訊混元
智譜AI
阿里雲百煉等
特別注意:
存在一種特殊的情況,即便模型上沒帶小地球標記,但是它也能實現連網,比如下面這個攻略教學解釋的情況。
模式2:模型不帶連網功能,使用 Tavily服務 實現連網功能
當我們使用一個不帶連網功能的大模型時(名字後面沒有小地球圖示),而我們又需要它獲取一些即時性的訊息進行處理,此時就需要用到Tavily網絡搜尋服務。
初次使用Tavily服務,會彈窗提示去設定一些資訊,請根據指引操作即可-非常簡單!
點擊獲取密鑰後,會自動跳轉到tavily的官網登入註冊頁面,註冊並登入後,建立APIkey,然後複製key到Cherry Studio即可。
不會註冊,參考本文檔同目錄下tavily連網登入註冊教學。
tavily註冊參考文件:
顯示下面的介面表示註冊成功。
再來試一次看看效果。結果表明,已經正常連網搜尋了,並且搜尋結果數是我們設定的預設值:5個。
注意:tavily 每個月有免費限制,超過了要付費~~
PS:如果發現錯誤,歡迎大家隨時聯絡。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio 資料儲存遵循系統規範,資料會自動放置在使用者目錄下,具體目錄位置如下:
macOS: /Users/username/Library/Application Support/CherryStudioDev
Windows: C:\Users\username\AppData\Roaming\CherryStudio
Linux: /home/username/.config/CherryStudio
也可以在以下位置查看:
方法一:
可以透過建立軟連結的方式實現。先退出軟體,將資料移動到您希望儲存的位置,然後在原位置建立一個指向新位置的連結即可。
具體操作步驟請參考:
方法二: 基於 Electron 應用特性,透過設定啟動參數修改儲存位置。
--user-data-dir 如: Cherry-Studio-*-x64-portable.exe --user-data-dir="%user_data_dir%"
範例:
init_cherry_studio.bat (編碼格式: ANSI)
目錄 user-data-dir 初始化後的結構:
curl -fsSL https://ollama.com/install.sh | shollama run llama3.2http://localhost:11434/
思考模式
複雜推理、數學題、規劃類任務
- 求解幾何問題 - 編寫完整項目架構
非思考模式
快速問答、翻譯、摘要
- 查詢天氣 - 中英文互譯







































此文件由 AI 從中文翻譯而來,尚未經過審閱。
Tokens 是 AI 模型處理文本的基本單位,可以理解為模型"思考"的最小單元。它不完全等同於我們理解的字符或單詞,而是模型自己的一種特殊的文本分割方式。
1. 中文分詞
一個漢字通常會被編碼為 1-2 個 tokens
例如:"你好" ≈ 2-4 tokens
2. 英文分詞
常見單詞通常是 1 個 token
較長或不常見的單詞會被分解成多個 tokens
例如:
"hello" = 1 token
"indescribable" = 4 tokens
3. 特殊字符
空格、標點符號等也會佔用 tokens
換行符通常是 1 個 token
Tokenizer(分詞器)是 AI 模型將文本轉換為 tokens 的工具。它決定了如何把輸入文本切分成模型可以理解的最小單位。
1. 訓練數據不同
不同的語料庫導致優化方向不同
多語言支援程度差異
特定領域(醫療、法律等)的專門優化
2. 分詞算法不同
BPE (Byte Pair Encoding) - OpenAI GPT 系列
WordPiece - Google BERT
SentencePiece - 適合多語言場景
3. 優化目標不同
有的注重壓縮效率
有的注重語意保留
有的注重處理速度
同樣的文本在不同模型中的 token 數量可能不同:
輸入:"Hello, world!"
GPT-3: 4 tokens
BERT: 3 tokens
Claude: 3 tokens基本概念: 嵌入模型是一種將高維離散數據(文本、圖像等)轉換為低維連續向量的技術,這種轉換讓機器能更好地理解和處理複雜數據。想像一下,就像把複雜的拼圖簡化成一個簡單的座標點,但這個點仍然保留了拼圖的關鍵特徵。在大模型生態中,它作為"翻譯官",將人類可理解的信息轉換為 AI 可計算的數字形式。
工作原理: 以自然語言處理為例,嵌入模型可以將詞語映射到向量空間中的特定位置。在這個空間裡,語義相近的詞會自動聚集在一起。比如:
"國王"和"王后"的向量會很接近
"貓"和"狗"這樣的寵物詞也會距離相近
而"汽車"和"麵包"這樣語義無關的詞則會距離較遠
主要應用場景:
文本分析:文件分類、情感分析
推薦系統:個性化內容推薦
圖像處理:相似圖片檢索
搜索引擎:語義搜索優化
核心優勢:
降維效果:將複雜數據簡化為易處理的向量形式
語義保持:保留原始數據中的關鍵語義信息
計算效率:顯著提升機器學習模型的訓練和推理效率
技術價值: 嵌入模型是現代 AI 系統的基礎組件,為機器學習任務提供了高質量的數據表示,是推動自然語言處理、計算機視覺等領域發展的關鍵技術。
基本工作流程:
知識庫預處理階段
將文件分割成適當大小的 chunk(文本塊)
使用 embedding 模型將每個 chunk 轉換為向量
將向量和原文存儲到向量數據庫中
查詢處理階段
將用戶問題轉換為向量
在向量庫中檢索相似內容
將檢索到的相關內容作為上下文提供給 LLM
MCP 是一種開源協議,旨在以標準化的方式向大型語言模型(LLM)提供上下文信息。
類比理解: 可以把 MCP 想像成 AI 領域的「U盤」。我們知道,U盤可以存儲各種文件,插入電腦後就能直接使用。類似地,MCP Server 上可以「插」上各種提供上下文的「插件」,LLM 可以根據需要向 MCP Server 請求這些插件,從而獲取更豐富的上下文信息,增強自身能力。
與 Function Tool 的對比: 傳統的 Function Tool(函數工具)也可以為 LLM 提供外部功能,但 MCP 更像是一種更高維度的抽象。Function Tool 更多的是針對具體任務的工具,而 MCP 則提供了一種更通用的、模塊化的上下文獲取機制。
標準化: MCP 提供了統一的接口和數據格式,使得不同的 LLM 和上下文提供者可以無縫協作。
模塊化: MCP 允許開發者將上下文信息分解為獨立的模塊(插件),方便管理和複用。
靈活性: LLM 可以根據自身需求動態選擇所需的上下文插件,實現更智能、更個性化的互動。
可擴展性: MCP 的設計支援未來添加更多類型的上下文插件,為 LLM 的能力拓展提供了無限可能。










此文件由 AI 從中文翻譯而來,尚未經過審閱。
使用或分發 Cherry Studio 素材之任何部分或元素,即視為您已認知並接受本協議內容,本協議立即生效。
本 Cherry Studio 授權協議(以下簡稱「協議」)應指由本協議定義之關於素材使用、複製、分發及修改的條款與條件。
「我們」(或「我方」)應指 上海千彗科技有限公司。
「您」(或「貴方」)應指行使本協議授予之權利,及/或為任何目的及於任何使用領域使用素材之自然人或法人實體。
「第三方」應指與我們或您均無共同控制權之個人或法人實體。
「Cherry Studio」應指本軟體套件,包含但不限於 [範例:核心庫、編輯器、外掛、範例專案],以及原始碼、文件、範例程式碼與我們分發之上開各項其他元素。(請依據 CherryStudio 實際構成詳述)
「素材」應統指上海千彗科技有限公司之專有 Cherry Studio 及文件(及其任何部分),依本協議提供。
「原始」形式應指進行修改之偏好形式,包含但不限於原始碼、文件來源檔案及設定檔。
「目標」形式應指原始形式經機械轉換或翻譯後產生之任何形式,包含但不限於編譯後目的碼、生成文件及轉換為其他媒體類型之形式。
「商業用途」指為直接或間接商業利益或商業優勢之目的,包含但不限於銷售、授權、訂閱、廣告、行銷、培訓、諮詢服務等。
「修改」指對素材原始形式進行任何變更、調整、衍生或二次開發,包含但不限於修改應用名稱、標誌、程式碼、功能、介面等。
免費商業使用(限未修改程式碼):我們依此根據我方擁有或體現於素材中之智慧財產權或其他權利,授予您一項非專屬、全球範圍、不可轉讓、免權利金之授權,以使用、複製、分發、拷貝及分發未經修改之素材,包含商業用途,惟須遵守本協議條款與條件。
商業授權(必要時):在滿足第三條「商業授權」所述條件時,您需從我方取得明確書面商業授權,方可行使本協議項下之權利。
於下列任一情形,您需聯繫我們並取得明確書面商業授權後,方可繼續使用 Cherry Studio 素材:
修改與衍生:您對 Cherry Studio 素材進行修改或基於其進行衍生開發(包含但不限於修改應用名稱、標誌、程式碼、功能、介面等)。
企業服務:於您企業內部,或為企業客戶提供基於 Cherry Studio 之服務,且該服務支援 10 人及以上累計使用者。
硬體綑綁銷售:您將 Cherry Studio 預裝或整合至硬體設備或產品中進行綑綁銷售。
政府或教育機構大規模採購:您之使用情境屬政府或教育機構大規模採購專案,尤涉及安全、資料隱私等敏感需求時。
公眾雲端服務:基於 Cherry Studio 提供面向公眾之雲端服務。
您可以分發未經修改之素材副本,或將其作為包含未修改素材之產品或服務的一部分提供,以原始形式或目標形式分發,但您須滿足下列條件:
您應向素材之任何其他接收者提供本協議副本;
您應於分發之所有素材副本中,保留下列署名聲明,並置於此類副本分發之「NOTICE」或類似文字檔內:`"Cherry Studio is licensed under the Cherry Studio LICENSE AGREEMENT, Copyright (c) 上海千彗科技有限公司. All Rights Reserved."` (Cherry Studio 依 Cherry Studio 授權協議取得授權,版權所有 (c) 上海千彗科技有限公司。保留所有權利。)
素材可能受出口管制或限制。您使用素材時應遵守適用法律法規。
若您使用素材或其任何輸出結果建立、訓練、微調或改進將被分發或提供之軟體或模型,我們鼓勵您於相關產品文件中顯著標示「Built with Cherry Studio」或「Powered by Cherry Studio」。
我們保留對素材及由我方或為我方製作之衍生作品所有智慧財產權之所有權。在遵守本協議條款與條件之前提下,對於您製作之素材修改與衍生作品,其智慧財產權歸屬將依具體商業授權協議約定。在未獲商業授權情況下,您對素材之修改與衍生作品不享有所有權,其智慧財產權仍歸屬我方。
除履行本協議項下通知義務或在描述與再分發素材時合理慣常使用所必需外,未授予使用我方商號、商標、服務標誌或產品名稱之商標授權。
若您對我方或任何實體提起訴訟或其他法律程序(包含訴訟中之反訴或反請求),主張素材或其任何輸出,或上述任何部分侵害您擁有或可授權之智慧財產權或其他權利,則本協議授予您之一切授權應自該訴訟或法律程序開始或提起之日起終止。
我們無義務支援、更新、提供培訓或開發任何 CherryStudio 素材之新版,亦無義務授予任何相關授權。
素材依「現狀」提供,不附帶任何明示或暗示保證,包含對適售性、不侵權性或特定用途適用性之保證。對於素材及其任何輸出之安全性或穩定性,我們不作任何保證,亦不承擔任何責任。
在任何情況下,對於因您使用或無法使用素材或其任何輸出引起之損害(包含但不限於直接、間接、特殊或後續損害),無論其如何引起,我們均不對您承擔責任。
對於任何第三方因您使用或分發素材引起或與之相關之索賠,您將為我們辯護、賠償並使我們免受損害。
本協議效期自您接受本協議或存取素材時起算,並將持續有效直至依本協議條款終止。
若您違反本協議任何條款,我們可終止本協議。協議終止後,您須停止使用素材。第七條、第九條及「二. 貢獻者協議」於本協議終止後持續有效。
本協議及因本協議引起或與之相關之任何爭議,均受中國法律管轄。
上海市人民法院對因本協議引起之任何爭議具有專屬管轄權。
簡單任務(建議關閉思考)
- 查詢「智譜AI的成立時間」 - 翻譯「I love you」為中文
中等任務(建議啟用思考)
- 比較飛機與高鐵從北京到上海的優劣 - 解釋木星為何有較多衛星
複雜任務(強烈建議啟用思考)
- 說明 MoE 模型中專家如何協作 - 基於市場資訊分析是否應買入ETF
:root {
--color-background: #1a462788;
--color-background-soft: #1a4627aa;
--color-background-mute: #1a462766;
--navbar-background: #1a4627;
--chat-background: #1a4627;
--chat-background-user: #28b561;
--chat-background-assistant: #1a462722;
}
#content-container {
background-color: #2e5d3a !important;
}:root {
font-family: "汉仪唐美人" !important; /* 字體 */
}
/* 深度思考展開字體顏色 */
.ant-collapse-content-box .markdown {
color: red;
}
/* 主題變數 */
:root {
--color-black-soft: #2a2b2a; /* 深色背景色 */
--color-white-soft: #f8f7f2; /* 淺色背景色 */
}
/* 深色主題 */
body[theme-mode="dark"] {
/* 顏色 */
--color-background: #2b2b2b; /* 深色背景色 */
--color-background-soft: #303030; /* 淺色背景色 */
--color-background-mute: #282c34; /* 中性背景色 */
--navbar-background: var(-–color-black-soft); /* 導覽列背景色 */
--chat-background: var(–-color-black-soft); /* 聊天背景色 */
--chat-background-user: #323332; /* 使用者聊天背景色 */
--chat-background-assistant: #2d2e2d; /* 助手聊天背景色 */
}
/* 深色主題特定樣式 */
body[theme-mode="dark"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* 內容容器背景色 */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* 訊息背景色 */
}
.inputbar-container {
background-color: #3d3d3a; /* 輸入框背景色 */
border: 1px solid #5e5d5940; /* 輸入框邊框顏色 */
border-radius: 8px; /* 輸入框邊框圓角 */
}
/* 程式碼樣式 */
code {
background-color: #e5e5e20d; /* 程式碼背景色 */
color: #ea928a; /* 程式碼文字顏色 */
}
pre code {
color: #abb2bf; /* 預格式化程式碼文字顏色 */
}
}
/* 淺色主題 */
body[theme-mode="light"] {
/* 顏色 */
--color-white: #ffffff; /* 白色 */
--color-background: #ebe8e2; /* 淺色背景色 */
--color-background-soft: #cbc7be; /* 淺色背景色 */
--color-background-mute: #e4e1d7; /* 中性背景色 */
--navbar-background: var(-–color-white-soft); /* 導覽列背景色 */
--chat-background: var(-–color-white-soft); /* 聊天背景色 */
--chat-background-user: #f8f7f2; /* 使用者聊天背景色 */
--chat-background-assistant: #f6f4ec; /* 助手聊天背景色 */
}
/* 淺色主題特定樣式 */
body[theme-mode="light"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* 內容容器背景色 */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* 訊息背景色 */
}
.inputbar-container {
background-color: #ffffff; /* 輸入框背景色 */
border: 1px solid #87867f40; /* 輸入框邊框顏色 */
border-radius: 8px; /* 輸入框邊框圓角,修改為您喜歡的大小 */
}
/* 程式碼樣式 */
code {
background-color: #3d39290d; /* 程式碼背景色 */
color: #7c1b13; /* 程式碼文字顏色 */
}
pre code {
color: #000000; /* 預格式化程式碼文字顏色 */
}
}PS D:\CherryStudio> dir
目錄: D:\CherryStudio
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:05 user-data-dir
-a---- 2025/4/14 23:05 94987175 Cherry-Studio-1.2.4-x64-portable.exe
-a---- 2025/4/18 14:05 701 init_cherry_studio.bat@title CherryStudio 初始化
@echo off
set current_path_dir=%~dp0
@echo 目前路徑:%current_path_dir%
set user_data_dir=%current_path_dir%user-data-dir
@echo CherryStudio 資料路徑:%user_data_dir%
@echo 搜尋目前路徑下的 Cherry-Studio-*-portable.exe
setlocal enabledelayedexpansion
for /f "delims=" %%F in ('dir /b /a-d "Cherry-Studio-*-portable*.exe" 2^>nul') do ( #此程式碼適用於 GitHub 和官網下載版本,其他版本請自行修改
set "target_file=!cd!\%%F"
goto :break
)
:break
if defined target_file (
echo 找到檔案: %target_file%
) else (
echo 未找到符合檔案,結束腳本執行
pause
exit
)
@echo 確認執行請繼續
pause
@echo 啟動 CherryStudio
start %target_file% --user-data-dir="%user_data_dir%"
@echo 操作完成
@echo on
exitPS D:\CherryStudio> dir .\user-data-dir\
目錄: D:\CherryStudio\user-data-dir
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:29 blob_storage
d----- 2025/4/18 14:07 Cache
d----- 2025/4/18 14:07 Code Cache
d----- 2025/4/18 14:07 Data
d----- 2025/4/18 14:07 DawnGraphiteCache
d----- 2025/4/18 14:07 DawnWebGPUCache
d----- 2025/4/18 14:07 Dictionaries
d----- 2025/4/18 14:07 GPUCache
d----- 2025/4/18 14:07 IndexedDB
d----- 2025/4/18 14:07 Local Storage
d----- 2025/4/18 14:07 logs
d----- 2025/4/18 14:30 Network
d----- 2025/4/18 14:07 Partitions
d----- 2025/4/18 14:29 Session Storage
d----- 2025/4/18 14:07 Shared Dictionary
d----- 2025/4/18 14:07 WebStorage
-a---- 2025/4/18 14:07 36 .updaterId
-a---- 2025/4/18 14:29 20 config.json
-a---- 2025/4/18 14:07 434 Local State
-a---- 2025/4/18 14:29 57 Preferences
-a---- 2025/4/18 14:09 4096 SharedStorage
-a---- 2025/4/18 14:30 140 window-state.json此文件由 AI 從中文翻譯而來,尚未經過審閱。
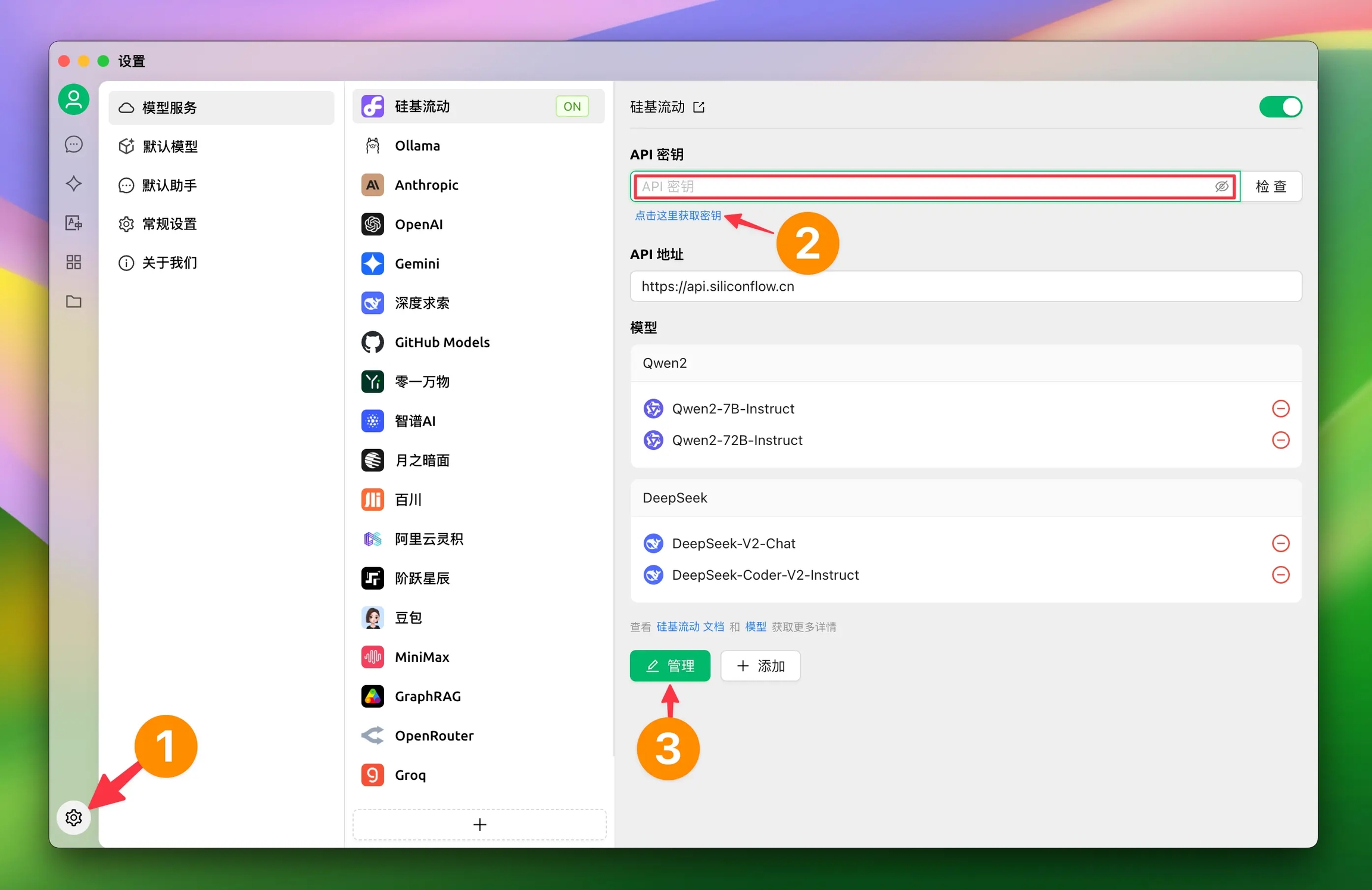
Cherry Studio 不僅整合了主流的 AI 模型服務,還賦予您強大的自訂能力。透過 自訂 AI 服務供應商 功能,您可以輕鬆接入任何您需要的 AI 模型。
靈活性: 不再受限於預置的供應商清單,自由選擇最適合您需求的 AI 模型。
多樣性: 嘗試各種不同平台的 AI 模型,發掘它們的獨特優勢。
可控性: 直接管理您的 API 金鑰和訪問地址,確保安全和隱私。
客製化: 接入私有化部署的模型,滿足特定業務場景的需求。
只需簡單幾步,即可在 Cherry Studio 中新增您的自訂 AI 服務供應商:
開啟設定: 在 Cherry Studio 介面左側導覽列中,點擊「設定」(齒輪圖示)。
進入模型服務: 在設定頁面中,選擇「模型服務」標籤頁。
新增供應商: 在「模型服務」頁面中,您會看到現有的供應商清單。點擊清單下方的「+ 新增」按鈕,開啟「新增供應商」彈窗。
填寫資訊: 在彈窗中,您需要填寫以下資訊:
供應商名稱: 為您的自訂供應商取一個易於識別的名稱(例如:MyCustomOpenAI)。
供應商類型: 從下拉清單中選擇您的供應商類型。目前支援:
OpenAI
Gemini
Anthropic
Azure OpenAI
儲存設定: 填寫完畢後,點擊「新增」按鈕儲存您的設定。
新增完成後,您需要在清單中找到您剛剛新增的供應商,並進行詳細設定:
啟用狀態 自訂供應商清單最右側有一個啟用開關,開啟代表啟用該自訂服務。
API 金鑰:
填寫您的 AI 服務供應商提供的 API 金鑰(API Key)。
點擊右側的「檢查」按鈕,可以驗證金鑰的有效性。
API 地址:
填寫 AI 服務的 API 存取地址(Base URL)。
請務必參考您的 AI 服務供應商提供的官方文件,取得正確的 API 地址。
模型管理:
點擊「+ 新增」按鈕,手動新增此供應商下您想要使用的模型ID。例如 gpt-3.5-turbo、gemini-pro 等。
如果您不確定具體的模型名稱,請參考您的 AI 服務供應商提供的官方文件。
點擊「管理」按鈕,可以對已經新增的模型進行編輯或者刪除。
完成以上設定後,您就可以在 Cherry Studio 的對話介面中,選擇您自訂的 AI 服務供應商和模型,開始與 AI 進行對話了!
vLLM 是一個類似 Ollama 的快速且易於使用的 LLM 推理庫。以下是如何將 vLLM 整合到 Cherry Studio 中的步驟:
安裝 vLLM: 按照 vLLM 官方文件(https://docs.vllm.ai/en/latest/getting_started/quickstart.html)安裝 vLLM。
pip install vllm # 如果你使用 pip
uv pip install vllm # 如果你使用 uv啟動 vLLM 服務: 使用 vLLM 提供的 OpenAI 相容介面啟動服務。主要有兩種方式,分別如下:
使用vllm.entrypoints.openai.api_server啟動
python -m vllm.entrypoints.openai.api_server --model gpt2使用uvicorn啟動
vllm --model gpt2 --served-model-name gpt2確保服務成功啟動,並監聽在預設連接埠 8000 上。當然,您也可以透過參數--port指定 vLLM 服務的連接埠號。
在 Cherry Studio 中新增 vLLM 供應商:
按照前面描述的步驟,在 Cherry Studio 中新增一個自訂 AI 服務供應商。
供應商名稱: vLLM
供應商類型: 選擇 OpenAI。
設定 vLLM 供應商:
API 金鑰: 因為 vLLM 不需要 API 金鑰,可以將此欄位留空,或者填寫任意內容。
API 地址: 填寫 vLLM 服務的 API 地址。預設情況下,地址為: http://localhost:8000/(如果使用了不同的連接埠,請相應地修改)。
模型管理: 新增您在 vLLM 中加載的模型名稱。在上面執行python -m vllm.entrypoints.openai.api_server --model gpt2的例子中,應該在此處填入gpt2
開始對話: 現在,您可以在 Cherry Studio 中選擇 vLLM 供應商和 gpt2 模型,開始與 vLLM 驅動的 LLM 進行對話了!
仔細閱讀文件: 在新增自訂供應商之前,請務必仔細閱讀您所使用的 AI 服務供應商的官方文件,了解 API 金鑰、訪問地址、模型名稱等關鍵資訊。
檢查 API 金鑰: 使用「檢查」按鈕可以快速驗證 API 金鑰的有效性,避免因金鑰錯誤導致無法使用。
關注 API 地址: 不同的 AI 服務供應商和模型,API 地址可能有所不同,請務必填寫正確的地址。
按需新增模型: 請只新增您實際上會用到的模型,避免新增過多無用模型。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
在 0.9.1 版本中,CherryStudio 帶來了期待已久的知識庫功能。
下面我們將按步驟呈現 CherryStudio 的詳細使用說明。
在模型管理服務中查找模型,可以點擊「嵌入模型」快速篩選;
找到需要的模型,添加到我的模型。
知識庫入口:在 CherryStudio 左側工具欄,點擊知識庫圖標,即可進入管理頁面;
添加知識庫:點擊添加,開始創建知識庫;
命名:輸入知識庫的名稱並添加嵌入模型,以 bge-m3 為例,即可完成創建。
添加文件:點擊添加文件的按鈕,打開文件選擇;
選擇文件:選擇支援的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,並打開;
向量化:系統會自動進行向量化處理,當顯示完成時(綠色 ✓),代表向量化已完成。
CherryStudio 支援多種添加數據的方式:
文件夾目錄:可以添加整個文件夾目錄,該目錄下支援格式的文件會被自動向量化;
網址連結:支援網址 url,如;
站點地圖:支援 xml 格式的站點地圖,如;
純文本筆記:支援輸入純文本的自定義內容。
當文件等資料向量化完成後,即可進行查詢:
點擊頁面下方的搜索知識庫按鈕;
輸入查詢的內容;
呈現搜索的結果;
並顯示該條結果的匹配分數。
創建一個新的話題,在對話工具欄中,點擊知識庫,會展開已經創建的知識庫列表,選擇需要引用的知識庫;
輸入並發送問題,模型即返回通過檢索結果生成的答案;
同時,引用的數據來源會附在答案下方,可快捷查看源文件。
此文件由 AI 從中文翻譯而來,尚未經過審閱。
4xx(客戶端錯誤狀態碼):一般為請求語法錯誤、鑒權失敗或認證失敗等無法完成請求。
5xx(伺服器錯誤狀態碼):一般為服務端錯誤,伺服器宕機、請求處理超時等。
點擊 Cherry Studio 客戶端窗口後按下快捷鍵 Ctrl + Shift + I(Mac端:Command + Option + I)
在彈出的控制台窗口中點擊 Network → 點擊查看②處最後一個標有紅色 × 的 completions(對話類、翻譯、模型連通性檢查等遇到錯誤時) 或 generations(繪畫遇到錯誤時) → 點擊Response查看完整的返回內容(圖中④的區域)。
如果你無法判斷該錯誤的原因,請將該界面截圖發送到 中尋求幫助。
該檢查方法不僅在對話時可以獲取錯誤信息,在模型測試時、添加知識庫時、繪畫時等都可以使用。無論哪種情況下都需要先打開調試窗口,再進行請求操作來獲取請求信息。
公式未被渲染而是直接顯示的公式的程式碼時檢查公式是否有定界符
定界符用法
行內公式
使用單個美元符號:
$formula$或使用
\(和\),如:\(formula\)獨立公式塊
使用雙美元符號:
$$formula$$或使用
\[formula\]示例:
$$\sum_{i=1}^n x_i$$
公式渲染錯誤/亂碼 常見在公式內包含中文內容時,嘗試切換公式引擎為 KateX。
模型狀態不可用
確認服務商是否支援該模型或確認服務商該模型服務狀態是否正常。
2.使用了非嵌入模型
首先需要確認模型是否支援識圖,熱門模型 Cherry Studio 會對其分類,模型名稱後帶小眼睛圖標的即支援識圖。
識圖模型會支援圖像文件的上傳,如果模型功能未被正確匹配可在對應服務商的模型列表當中找到該模型,點擊其名稱後的設置按鈕並勾選圖像選項。
模型具體的信息可以到對應服務商找到其信息查閱。同嵌入模型一樣,不支援視覺的模型不需要強制開啟圖像功能,勾選了圖像的選項也沒有作用。
Tools
此文件由 AI 從中文翻譯而來,尚未經過審閱。
Cherry Studio v1.5.7 版本引入了操作簡易且功能強大的 Code Agent 功能,可直接啟動和管理多種 AI 編程agent。本教程將引導您完成設定和啟動的完整流程。
首先,請確保您的 Cherry Studio 已升級至 v1.5.7 或更高版本。您可前往 或官方網站下載最新版本。
為方便使用頂部標籤頁功能,建議將導航列調整至頂部。
操作路徑:設定 -> 顯示設定 -> 導航列設定
將「導航列位置」選項設為 頂部。
點選介面頂部的「+」號圖標,新增空白標籤頁。
在新標籤頁中點擊 Code(或 </>)圖標,進入 Code Agent 設定介面。
根據需求及持有的 API Key 選擇要使用的 Code Agent 工具。目前支援以下幾種:
Claude Code
Gemini CLI
Qwen Code
OpenAI Codex
在下拉式選單中選擇與 CLI 工具相容的模型。(詳細模型相容性說明請參考下方「重要注意事項」)
點擊「選擇目錄」按鈕,為 Agent 指定工作目錄。Agent 將具備存取此目錄下所有檔案及子目錄的權限,以便理解專案脈絡、讀取檔案及執行程式碼。
自動配置:您在步驟 6(模型)和步驟 7(工作目錄)的選擇會自動生成相應環境變數。
自訂新增:若 Agent 或專案需特定環境變數(如 PROXY_URL 等),可在此區域自訂新增。
內建可執行檔:Cherry Studio 已整合上述所有 Code Agent 執行檔,多數情況下無需連網即可直接使用。
自動更新:若希望 Agent 始終維持最新版本,可勾選 檢查更新並安裝最新版本 選項。勾選後每次啟動時會自動連網檢查並更新 Agent 工具。
完成所有設定後點擊 啟動 按鈕。Cherry Studio 將自動呼叫系統 Terminal(終端機),載入所有環境變數後運行所選 Code Agent。現在您可在彈出的終端機視窗中與 AI Agent 互動。
模型相容性說明:
Claude Code:需選擇支援 Anthropic API Endpoint 格式的模型。目前官方支援模型包含:
Claude 系列模型
DeepSeek V3.1 (官方 API 平台)
Kimi K2 (官方 API 平台)
智譜 GLM 4.5 (官方 API 平台)
注意:當前許多第三方服務商(如 One API, New API 等)針對 DeepSeek, Kimi, GLM 的 API 接口多數僅支援 OpenAI Chat Completions 格式,可能需等待服務商逐步適配後方能與 Claude Code 相容。
Gemini CLI:需選擇 Google 的 Gemini 系列模型。
Qwen Code:支援 OpenAI Chat Completions API 格式模型,強烈建議使用 Qwen3 Coder 系列模型以獲得最佳程式碼生成效果。
OpenAI Codex:支援 GPT 系列模型(如 gpt-4o, gpt-5 等)。
依賴與環境衝突:
Cherry Studio 內建獨立 Node.js 運行環境、Code Agent 執行檔及環境變數配置,旨在提供開箱即用的潔淨環境。
若啟動 Agent 時遇到依賴衝突或異常錯誤,建議暫時解除安裝或停用系統內相關全域依賴(如 Node.js 或特定工具鏈)以排除衝突。
API Token 消耗警示:
Code Agent 的 API Token 消耗量極大。處理複雜任務時,Agent 需反覆思考、規劃並生成程式碼,可能產生大量請求導致 Token 快速耗盡。
請務必依據自身 API 額度及預算量力而為,密切關注 Token 使用狀況以防預算超支。
希望本教學能協助您快速掌握 Cherry Studio 強大的 Code Agent 功能!










400
請求體格式錯誤等
查看對話返回的錯誤內容或 控制台 查看報錯內容,根據提示操作。 【常見情況1】:如果是gemini模型,可能需要進行綁卡操作; 【常見情況2】:數據體積超限,常見於視覺模型,圖片體積超過上游單個請求流量上限會返回該錯誤碼; 【常見情況3】:加了不支援的參數或參數填寫錯誤。嘗試新建一個純淨的助手測試是否正常; 【常見情況4】:上下文超過限制,清除上下文或新建對話或減少上下文條數。
401
認證失敗:模型不被支援或服務端帳戶被封禁等
聯繫或查看對應服務商帳戶狀態
403
請求操作無權限
根據對話返回的錯誤信息或控制台錯誤信息提示進行相應操作
404
無法找到請求資源
檢查請求路徑等
422
請求格式正確,但語義錯誤
這類錯誤服務端能解析,但無法處理。常見於JSON語義錯誤(如:空值;要求值為字符串,但寫成了數字或布爾值等情況)。
429
請求速率達到上限
請求速率(TPM 或 RPM)達到上限,冷靜一會再用
500
伺服器內部錯誤,無法完成請求
持續出現的話聯繫上游服務商
501
伺服器不支援請求的功能,無法完成請求
502
作為網關或者代理工作的伺服器嘗試執行請求時,從遠端伺服器接收到了一個無效的回應
503
由於超載或系統維護,伺服器暫時的無法處理客戶端的請求。延時的長度可包含在伺服器的Retry-After頭信息中
504
充當網關或代理的伺服器,未及時從遠端伺服器獲取請求


















此文件由 AI 從中文翻譯而來,尚未經過審閱。
Doubao-embedding
4095
Doubao-embedding-vision
8191
Doubao-embedding-large
4095
text-embedding-v3
8192
text-embedding-v2
2048
text-embedding-v1
2048
text-embedding-async-v2
2048
text-embedding-async-v1
2048
text-embedding-3-small
8191
text-embedding-3-large
8191
text-embedding-ada-002
8191
Embedding-V1
384
tao-8k
8192
embedding-2
1024
embedding-3
2048
hunyuan-embedding
1024
Baichuan-Text-Embedding
512
M2-BERT-80M-2K-Retrieval
2048
M2-BERT-80M-8K-Retrieval
8192
M2-BERT-80M-32K-Retrieval
32768
UAE-Large-v1
512
BGE-Large-EN-v1.5
512
BGE-Base-EN-v1.5
512
jina-embedding-b-en-v1
512
jina-embeddings-v2-base-en
8191
jina-embeddings-v2-base-zh
8191
jina-embeddings-v2-base-de
8191
jina-embeddings-v2-base-code
8191
jina-embeddings-v2-base-es
8191
jina-colbert-v1-en
8191
jina-reranker-v1-base-en
8191
jina-reranker-v1-turbo-en
8191
jina-reranker-v1-tiny-en
8191
jina-clip-v1
8191
jina-reranker-v2-base-multilingual
8191
reader-lm-1.5b
256000
reader-lm-0.5b
256000
jina-colbert-v2
8191
jina-embeddings-v3
8191
BAAI/bge-m3
8191
netease-youdao/bce-embedding-base_v1
512
BAAI/bge-large-zh-v1.5
512
BAAI/bge-large-en-v1.5
512
Pro/BAAI/bge-m3
8191
text-embedding-004
2048
nomic-embed-text-v1
8192
nomic-embed-text-v1.5
8192
gte-multilingual-base
8192
embedding-query
4000
embedding-passage
4000
embed-english-v3.0
512
embed-english-light-v3.0
512
embed-multilingual-v3.0
512
embed-multilingual-light-v3.0
512
embed-english-v2.0
512
embed-english-light-v2.0
512
embed-multilingual-v2.0
256
此文件由 AI 從中文翻譯而來,尚未經過審閱。
助手 是對所選模型進行個性化設置的配置,如提示詞預設和參數預設等,通過這些設置讓模型更符合預期的工作方式。
系統預設助手 提供通用參數(無提示詞),您可直接使用或到 智能體頁面 尋找所需預設。
助手 是 話題 的父集合,單個助手可建立多個話題(對話),所有 話題 共享助手的參數設置和提示詞 (prompt) 等模型配置。
新話題 在當前助手內建立新話題。
上傳圖片或文件 需模型支援圖片解析,上傳文件會自動解析為文字作為上下文。
網路搜尋 需先在設定中配置,搜尋結果將作為上下文提供給模型,詳見 聯網模式。
知識庫 開啟知識庫功能,詳見 知識庫教學。
MCP 伺服器 開啟 MCP 伺服器功能,詳見 MCP 使用教學。
產生圖片 預設隱藏,對支援產生圖片的模型(如 Gemini),需手動點亮按鈕才可生成圖片。
選擇模型 為後續對話切換指定模型,保留上下文。
快捷短語 需先在設定中預設常用短語,此處可直接調用,支援變數。
清空訊息 刪除該話題所有內容。
展開 擴大對話框,方便輸入長文。
清除上下文 在不刪除內容情況下截斷模型能獲取的上下文,使模型"忘記"先前對話。
預估 Token 數 顯示預估數據:當前上下文數、最大上下文數(∞ 表示無限制)、當前輸入框訊息字數、預估 Token 數。
翻譯 將輸入框內容翻譯成英文。
參數與助手設定中的 模型設定 同步,詳見 編輯助手。
訊息分隔線:分隔訊息正文與操作欄。
使用襯線字體:切換字體樣式,也可透過 自訂css 更換字體。
程式碼顯示行號:模型輸出程式碼時顯示行號。
程式碼塊可折疊:程式碼過長時自動折疊區塊。
程式碼塊自動換行:單行程式碼超出視窗時自動換行。
思考內容自動折疊:支援思考的模型完成後自動折疊思考過程。
訊息樣式:切換氣泡樣式或清單樣式。
程式碼風格:切換程式碼片段顯示風格。
數學公式引擎:KaTeX:渲染速度更快,針對效能優化
MathJax:功能更完整,支援更多數學符號(渲染較慢)
訊息字體大小:調整對話介面字體大小。
顯示預估 Token 數:輸入框顯示預估消耗 Token 數(僅供參考)。
長文字貼上為文件:貼上長文字時自動顯示為文件樣式,減少干擾。
Markdown 渲染輸入訊息:關閉時僅渲染模型回覆,不渲染發送訊息。
快速敲擊3次空白鍵翻譯:輸入內容後連敲三次空白鍵可翻譯為英文。
注意:此操作會覆蓋原始內容。
目標語言:設定翻譯按鈕和快速翻譯的目標語言。
在助手介面右鍵點選助手名稱→選擇設定選項
名稱:自訂助手辨識名稱。
提示詞:即 prompt ,可參考智能體頁面格式編輯。
預設模型:為助手固定預設模型。未設定時採用 全域預設模型。
自動重置模型:開啟時-切換模型後新建話題會重置為助手預設模型;關閉時新建話題沿用上個話題模型。
範例:助手預設模型為gpt-3.5-turbo,在話題1切換gpt-4o後:
開啟自動重置:話題2將使用gpt-3.5-turbo
關閉自動重置:話題2將使用gpt-4o
溫度 (Temperature) :控制輸出隨機性(預設0.7):
低值(0-0.3):精確輸出,適合程式碼生成
中值(0.4-0.7):平衡創造力,推薦日常對話
高值(0.8-1.0):高創造力,適合創意寫作
Top P (核採樣):控制詞彙選擇範圍(預設1):
小值(0.1-0.3):保守輸出,適合技術文件
中值(0.4-0.6):平衡多樣性
大值(0.7-1.0):多樣化表達,適合創意場景
上下文數量 (Context Window)保留的上下文訊息數量:
5-10:普通對話
10:複雜任務(消耗更多 token)
注意:訊息越多消耗 token 越多
開啟訊息長度限制 (MaxToken)單次回答最大 Token 數:
範例:測試模型連通性時可設 MaxToken=1
多數模型上限為32k Tokens(部分支援更高)
建議值:
普通聊天:500-800
短文生成:800-2000
程式碼生成:2000-3600
長文生成:4000+ (需模型支援)
過低限制可能導致輸出截斷或不完整。
流式輸出(Stream)資料即時傳輸處理方式:
開啟:逐字輸出(打字機效果)
關閉:整段一次性輸出
自訂參數在請求體(body)中添加額外參數(如 presence_penalty)。
填寫格式:參數名稱—類型—值,參考 OpenAI 文件


























此文件由 AI 從中文翻譯而來,尚未經過審閱。
<极不支持> ```html
360gpt-pro
8k
-
不支援
對話
360AI_360gpt
360智腦系列效果最好的主力千億級大模型,廣泛適用於各領域複雜任務場景。
360gpt-turbo
7k
-
不支援
對話
360AI_360gpt
兼顧性能和效果的百億級大模型,適合對性能/成本要求較高的場景。
360gpt-turbo-responsibility-8k
8k
-
不支援
對話
360AI_360gpt
兼顧性能和效果的百億級大模型,適合對性能/成本要求較高的場景。
360gpt2-pro
8k
-
不支援
對話
360AI_360gpt
360智腦系列效果最好的主力千億級大模型,廣泛適用於各領域複雜任務場景。
claude-3-5-sonnet-20240620
200k
16k
不支援
對話,識圖
Anthropic_claude
於2024年6月20日發佈的快照版本,Claude 3.5 Sonnet是一個平衡了性能和速度的模型,在保持高速度的同時提供頂級性能,支援多模態輸入。
claude-3-5-haiku-20241022
200k
16k
不支援
對話
Anthropic_claude
於2024年10月22日發佈的快照版本,Claude 3.5 Haiku在各項技能上都有所提升,包括編碼、工具使用和推理。作為Anthropic系列中速度最快的模型,它提供快速響應時間,適用於需要高互動性和低延遲的應用,如面向用戶的聊天機器人和即時代碼補全。它在數據提取和即時內容審核等專業任務中也表現出色,使其成為各行業廣泛應用的多功能工具。它不支援圖像輸入。
claude-3-5-sonnet-20241022
200k
8K
不支援
對話,識圖
Anthropic_claude
於2024年10月22日發佈的快照版本,Claude 3.5 Sonnet 提供了超越 Opus 的能力和比 Sonnet 更快的速度,同時保持與 Sonnet 相同的價格。Sonnet 特別擅長編程、數據科學、視覺處理、代理任務。
claude-3-5-sonnet-latest
200K
8k
不支援
對話,識圖
Anthropic_claude
動態指向最新的Claude 3.5 Sonnet版本,Claude 3.5 Sonnet提供了超越 Opus 的能力和比 Sonnet 更快的速度,同時保持與 Sonnet 相同的價格。Sonnet 特別擅長編程、數據科學、視覺處理、代理任務,該模型指向最新的版本。
claude-3-haiku-20240307
200k
4k
不支援
對話,識圖
Anthropic_claude
Claude 3 Haiku 是 Anthropic 的最快且最緊湊的模型,旨在實現近乎即時的響應。它具有快速且準確的定向性能。
claude-3-opus-20240229
200k
4k
不支援
對話,識圖
Anthropic_claude
Claude 3 Opus 是 Anthropic 用於處理高度複雜任務的最強大模型。它在性能、智能、流暢性和理解力方面表現卓越。
claude-3-sonnet-20240229
200k
8k
不支援
對話,識圖
Anthropic_claude
於2024年2月29日發佈的快照版本,Sonnet 特別擅長於: - 編碼:能夠自主編寫、編輯和運行程式碼,並具備推理和故障排除能力 - 數據科學:增強人類的數據科學專業知識;在使用多種工具獲取洞察時,能夠處理非結構化數據 - 視覺處理:擅長解讀圖表、圖形和圖像,準確轉錄文本以獲取超越文本本身的洞察 - 代理任務:工具使用出色,非常適合處理代理任務(即需要與其他系統交互的複雜多步驟問題解決任務)
google/gemma-2-27b-it
8k
-
不支援
對話
Google_gamma
Gemma 是由 Google 開發的輕量級、最先進的開放模型系列,採用與 Gemini 模型相同的研究和技術建構。這些模型是僅解碼器的大型語言模型,支援英語,提供預訓練和指令微調兩種變體的開放權重。Gemma 模型適用於各種文本生成任務,包括問答、摘要和推理。
google/gemma-2-9b-it
8k
-
不支援
對話
Google_gamma
Gemma 是 Google 開發的輕量級、最先進的開放模型系列之一。它是一個僅解碼器的大型語言模型,支援英語,提供開放權重、預訓練變體和指令微調變體。Gemma 模型適用於各種文本生成任務,包括問答、摘要和推理。該 9B 模型是通過 8 萬億個 tokens 訓練而成。
gemini-1.5-pro
2m
8k
不支援
對話
Google_gemini
Gemini 1.5 Pro 的最新穩定版本。作為一個強大的多模態模型,它可以處理長達6 萬行程式碼或 2,000 頁文本。特別適合需要複雜推理的任務。
gemini-1.0-pro-001
33k
8k
不支援
對話
Google_gemini
這是 Gemini 1.0 Pro 的穩定版本。作為一個 NLP 模型,它專門處理多輪文本和程式碼聊天以及程式碼生成等任務。該模型將於 2025 年 2 月 15 日停用,建議遷移到 1.5 系列模型。
gemini-1.0-pro-002
32k
8k
不支援
對話
Google_gemini
這是 Gemini 1.0 Pro 的穩定版本。作為一個 NLP 模型,它專門處理多輪文本和程式碼聊天以及程式碼生成等任務。該模型將於 2025 年 2 月 15 日停用,建議遷移到 1.5 系列模型。
gemini-1.0-pro-latest
33k
對話,已廢棄或即將廢棄
Google_gemini
這是 Gemini 1.0 Pro 的最新版本。作為一個 NLP 模型,它專門處理多輪文本和程式碼聊天以及程式碼生成等任務。該模型將於 2025 年 2 月 15 日停用,建議遷移到 1.5 系列模型。
gemini-1.0-pro-vision-001
16k
2k
不支援
對話
Google_gemini
這是 Gemini 1.0 Pro 的視覺版本。該模型將於 2025 年 2 月 15 日停用,建議遷移到 1.5 系列模型。
gemini-1.0-pro-vision-latest
16k ```html
識圖
Google_gemini
這是 Gemini 1.0 Pro 的視覺最新版本。該模型將於 2025 年 2 月 15 日停用,建議遷移到 1.5 系列模型。
gemini-1.5-flash
1m
8k
不支援
對話,識圖
Google_gemini
這是 Gemini 1.5 Flash 的最新穩定版本。作為一個平衡的多模態模型,它可以處理音頻、圖片、影片和文本輸入。
glm-4v-flash
2k
1k
不支援
對話,識圖
智譜_glm
免費模型:具備強大的圖片理解能力
```






此文件由 AI 從中文翻譯而來,尚未經過審閱。
CherryStudio 支援透過 SearXNG 進行網絡搜索,SearXNG 是一個可本地部署也可在伺服器上部署的開源項目,所以與其他需要 API 供應商的配置方式略有不同。
SearXNG 項目鏈接:SearXNG
開源免費,無需 API
隱私性相對較高
可高度定制化
由於 SearXNG 不需要複雜的環境配置,可以不用 docker compose,只需要簡單提供一個空閒端口即可部署,所以最快捷的方式可以使用 Docker 直接拉取鏡像進行部署。
1. 下載安裝並配置 docker
安裝後選擇一個鏡像存儲路徑:
2. 搜索並拉取 SearXNG 鏡像
搜索欄輸入 searxng:
拉取鏡像:
3. 運行鏡像
拉取成功後來到 images 頁面:
選擇拉取的鏡像點擊運行:
打開設置項進行配置:
以 8085 端口為例:
運行成功後點擊鏈接即可打開 SearXNG 的前端界面:
出現這個頁面說明部署成功:
鑒於 Windows 下安裝 Docker 是一件較為麻煩的事情,使用者可以將 SearXNG 部署在伺服器上,也可藉此共享給其他人使用。但是很遺憾,SearXNG 自身暫不支援鑒權,導致他人可以透過技術手段掃描到並濫用你部署的實例。
為此,Cherry Studio 目前已支援配置 HTTP 基本認證(RFC7617),如果使用者欲將自己部署的 SearXNG 暴露在公網環境下,請務必透過 Nginx 等反向代理軟件配置 HTTP 基本認證。下面提供簡要教程,需要你有基本的 Linux 運維知識。
類似地,仍然使用 Docker 部署。假設你已按照官方教程在伺服器上安裝好了最新版 Docker CE,以下提供一條龍命令,適用於 Debian 系統下全新安裝:
sudo apt update
sudo apt install git -y
# 拉取官方倉庫
cd /opt
git clone https://github.com/searxng/searxng-docker.git
cd /opt/searxng-docker
# 如果你的伺服器頻寬很小, 可以設置為 false
export IMAGE_PROXY=true
# 修改配置文件
cat <<EOF > /opt/searxng-docker/searxng/settings.yml
# see https://docs.searxng.org/admin/settings/settings.html#settings-use-default-settings
use_default_settings: true
server:
# base_url is defined in the SEARXNG_BASE_URL environment variable, see .env and docker-compose.yml
secret_key: $(openssl rand -hex 32)
limiter: false # can be disabled for a private instance
image_proxy: $IMAGE_PROXY
ui:
static_use_hash: true
redis:
url: redis://redis:6379/0
search:
formats:
- html
- json
EOF如果你需要修改本地監聽端口、復用本地已有的 nginx,可以編輯 docker-compose.yaml 文件,參考如下:
version: "3.7"
services:
# 如果不需要 Caddy 而復用本地已有的 Nginx, 就把下面的去掉. 我們默認不需要 Caddy.
caddy:
container_name: caddy
image: docker.io/library/caddy:2-alpine
network_mode: host
restart: unless-stopped
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile:ro
- caddy-data:/data:rw
- caddy-config:/config:rw
environment:
- SEARXNG_HOSTNAME=${SEARXNG_HOSTNAME:-http://localhost}
- SEARXNG_TLS=${LETSENCRYPT_EMAIL:-internal}
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
# 如果不需要 Caddy 而復用本地已有的 Nginx, 就把上面的去掉. 我們默認不需要 Caddy.
redis:
container_name: redis
image: docker.io/valkey/valkey:8-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: unless-stopped
networks:
- searxng
volumes:
- valkey-data2:/data
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
searxng:
container_name: searxng
image: docker.io/searxng/searxng:latest
restart: unless-stopped
networks:
- searxng
# 默認映射到宿主機 8080 端口, 假如你想監聽 8000 就改成 "127.0.0.1:8000:8080"
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
- UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4}
- UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4}
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
searxng:
volumes:
# 如果不需要 Caddy 而復用本地已有的 Nginx, 就把下面的去掉
caddy-data:
caddy-config:
# 如果不需要 Caddy 而復用本地已有的 Nginx, 就把上面的去掉
valkey-data2:執行 docker compose up -d 啟動。執行 docker compose logs -f searxng 可以看到日誌。
如果你使用了一些伺服器面板程序,例如寶塔面板或 1Panel,請參閱其文檔添加網站並配置 nginx 反向代理,隨後找到修改 nginx 配置文件的地方, 參考下面的範例進行修改:
server
{
listen 443 ssl;
# 這行是你的主機名
server_name search.example.com;
# index index.html;
# root /data/www/default;
# 如果配置了 SSL 應該有這兩行
ssl_certificate /path/to/your/cert/fullchain.pem;
ssl_certificate_key /path/to/your/cert/privkey.pem;
# HSTS
# add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload";
# 默認情況下透過面板配置反向代理, 默認的 location 塊就是這樣
location / {
# 只需要在 location 塊添加下面兩行, 其他保留原狀就行.
# 此處範例假設你的配置文件保存在 /etc/nginx/conf.d/ 目錄下.
# 如果是寶塔應該是保存在 /www 之類的目錄下, 需要注意.
auth_basic "Please enter your username and password";
auth_basic_user_file /etc/nginx/conf.d/search.htpasswd;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_protocol_addr;
proxy_pass http://127.0.0.1:8000;
client_max_body_size 0;
}
# access_log ...;
# error_log ...;
}假設 Nginx 配置文件保存於 /etc/nginx/conf.d 下,我們將將密碼文件保存在同目錄下。
執行命令(自行將 example_name、example_password 替換為你將要設定的用戶名和密碼):
echo "example_name:$(openssl passwd -5 'example_password')" > /etc/nginx/conf.d/search.htpasswd重啓 Nginx(重載配置也可以)。
這時可以打開一下網頁,已經會提示你輸入用戶名和密碼,請輸入前面設定的用戶名和密碼查看能否成功進入 SearXNG 搜索頁面,藉此檢查配置是否正確。
SearXNG 本地或在伺服器部署成功後,接下來是 CherryStudio 的相關配置。
來到網絡搜索設置頁面,選擇 Searxng:
直接輸入本地部署的鏈接發現驗證失敗,此時不用擔心:
因為直接部署後默認並沒有配置 json 返回類型,所以無法獲取數據,需要修改配置文件。
回到 Docker,來到 Files 標籤頁找到鏡像中找到帶標籤的文件夾:
展開後繼續往下翻,會發現另一個帶標籤的文件夾:
繼續展開,找到 settings.yml 配置文件:
點擊打開文件編輯器:
找到 78 行,可以看到類型只有一個 html
添加 json 類型後保存,重新運行鏡像
重新回到 Cherry Studio 進行驗證,驗證成功:
地址既可以填寫本地:http://localhost:端口號 也可以填寫 docker 地址:http://host.docker.internal:端口號
如果使用者遵循前面的範例在伺服器上部署並正確配置了反向代理,已經開啟了 json 返回類型。輸入地址後進行驗證,由於已給反向代理配置了 HTTP 基本認證,此時驗證則應返回 401 錯誤碼:
在客戶端配置 HTTP 基本認證,輸入剛才設定的用戶名與密碼:
進行驗證,應當驗證成功。
此時 SearXNG 已具備默認聯網搜索能力,如需定制搜索引擎需要自行進行配置
需要注意的是此處首選項並不能影響大模型調用時的配置
如需配置需要大模型調用的搜索引擎,需在配置文件中設置:
配置語言參考:
若內容太長直接修改不方便,可將其複製到本地 IDE 中,修改後粘貼到配置文件中即可。
在配置文件中將返回格式加上 json:
Cherry Studio 會默認選取 categories 同時包含 web general 的引擎進行搜索,默認情況下會選中 google 等引擎,由於大陸無法直接訪問 google 等網站導致失敗。增加以下配置使得 searxng 強制使用 baidu 引擎,即可解決問題:
use_default_settings:
engines:
keep_only:
- baidu
engines:
- name: baidu
engine: baidu
categories:
- web
- general
disabled: falsesearxng 的 limiter 配置阻礙了 API 訪問,請嘗試將其在設置中設為 false:
此文件由 AI 從中文翻譯而來,尚未經過審閱。
這是一個基於 Chatbot Arena (lmarena.ai) 數據的排行榜,通過自動化流程生成。
數據更新時間: 2025-09-11 11:40:35 UTC / 2025-09-11 19:40:35 CST (北京時間)
排名(UB):基於 Bradley-Terry 模型計算的排名。此排名反映了模型在競技場中的綜合表現,並提供了其 Elo 分數的 上界 估計,幫助理解模型的潛在競爭力。
排名(StyleCtrl):經過對話風格控制後的排名。此排名旨在減少因模型回覆風格(例如冗長、簡潔)帶來的偏好偏差,更純粹地評估模型的核心能力。
模型名:大型語言模型 (LLM) 的名稱。此列已嵌入模型相關連結,點擊可跳轉。
分數:模型在競技場中通過用戶投票獲得的 Elo 評分。Elo 評分是一種相對排名系統,分數越高表示模型表現越好。該分數是動態變化的,反映了模型在當前競爭環境中的相對實力。
置信區間:模型 Elo 評分的95%置信區間(例如:+6/-6)。這個區間越小,表示模型的評分越穩定可靠;反之,區間越大可能意味著數據量不足或模型表現波動較大。它提供了對評分準確性的量化評估。
票數:該模型在競技場中收到的總投票數量。投票數越多,通常意味著其評分的統計可靠性越高。
服務商:提供該模型的組織或公司。
許可協議:模型的許可協議類型,例如專有 (Proprietary)、Apache 2.0、MIT 等。
知識截止日期:模型訓練數據的知識截止日期。暫無數據 表示相關資訊未提供或未知。
本排行榜數據由 項目自動生成並提供,該項目從 獲取並處理數據。此排行榜由 GitHub Actions 每天自動更新。
本報告僅供參考。排行榜數據是動態變化的,並基於特定時間段內用戶在 Chatbot Arena 上的偏好投票。數據的完整性和準確性取決於上游數據源及 fboulnois/llm-leaderboard-csv 項目的更新和處理。不同模型可能採用不同的許可協議,使用時請務必參考模型提供商的官方說明。
1
1
1470
+5/-5
26,019
Proprietary
nan
2
2
1446
+6/-6
13,715
Proprietary
nan
3
2
1434
+9/-9
4,112
Z.ai
MIT
nan
4
2
1434
+6/-6
13,058
xAI
Proprietary
nan
5
3
1429
+4/-4
30,777
OpenAI
Proprietary
nan
6
3
1428
+4/-4
32,033
OpenAI
Proprietary
nan
7
3
1427
+9/-9
4,154
Alibaba
Apache 2.0
nan
8
3
1427
+5/-5
18,284
DeepSeek
MIT
nan
9
4
1423
+4/-4
31,757
xAI
Proprietary
nan
10
8
1416
+4/-4
26,604
Meta
nan
nan
11
8
1415
+5/-5
15,271
OpenAI
Proprietary
nan
12
7
1413
+9/-9
3,715
Alibaba
Apache 2.0
nan
13
8
1412
+6/-6
13,837
xAI
Proprietary
nan
14
10
1411
+4/-4
31,359
Proprietary
nan
15
15
1397
+4/-4
27,552
Proprietary
nan极小
... (中間行數省略以節省空間,實際翻譯應包含完整表格)
255
253
978
+11/-11
4,763
Tsinghua
Apache-2.0
2023/10
256
254
963
+11/-11
3,997
MosaicML
CC-BY-NC-SA-4.0
2023/5
257
254
962
+15/-15
1,788
Nomic AI
Non-commercial
2023/3
258
254
956
+11/-11
4,920
RWKV
Apache 2.0
2023/4
259
255
947
+13/-13
2,713
Tsinghua
Apache-2.0
2023/6
260
255
940
+11/-11
5,864
Stanford
Non-commercial
2023/3
261
258
925
+12/-12
4,983
Tsinghua
Non-commercial
2023/3
262
258
923
+10/-10
6,368
OpenAssistant
Apache 2.0
202极早期
263
260
[FastChat-T5-3B](极早模型版](https://huggingface.co/lmsys/fastchat-t5-3b-v1.0)
901
+12/-12
4,288
LMSYS
Apache 2.0
2023/4
264
263
873
+12/-12
3,336
Stability AI
CC-BY-NC-SA-4.0
2023/4
265
263
857
+13/-13
3,480
Databricks
MIT
2023/4
266
264
840
+16/-16
2,446
Meta
Non-commercial
2023/2