
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
A página de Agentes Inteligentes é uma praça de assistentes onde você pode selecionar ou pesquisar por predefinições de modelos desejadas. Ao clicar em um card, o assistente será adicionado à lista de assistentes na página de conversas.
Você também pode editar e criar seus próprios assistentes nesta página.
Clique em Meus, depois em Criar Agente Inteligente para começar a criar seu assistente.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Siga nossas contas de mídia social: Twitter (X), Xiaohongshu, Weibo, Bilibili, Douyin
Junte-se às nossas comunidades: Grupo QQ (575014769), Telegram, Discord, Grupo WeChat (clique para ver)
O Cherry Studio é uma plataforma completa de assistente AI que integra funcionalidades como diálogo com múltiplos modelos, gestão de base de conhecimento, pintura AI, tradução e mais. Com design altamente personalizável, capacidades de expansão poderosas e experiência de usuário amigável, o Cherry Studio é a escolha ideal para usuários profissionais e entusiastas de IA. Tanto usuários iniciantes quanto desenvolvedores podem encontrar funcionalidades AI adequadas para melhorar eficiência e criatividade.
Respostas Múltiplas: Permite gerar respostas simultâneas de múltiplos modelos para a mesma pergunta, facilitando comparações (detalhes na Interface de Conversação).
Agrupamento Automático: Histórico de conversas organizado automaticamente para acesso rápido.
Exportação de Conversas: Suporte para exportação em múltiplos formatos (Markdown, Word, etc.).
Parâmetros Personalizáveis: Ajustes avançados e parâmetros personalizados para necessidades específicas.
Mercado de Assistentes: Mais de mil assistentes especializados em tradução, programação, redação e suporte para criação personalizada.
Renderização Multi-formato: Suporte para Markdown, fórmulas matemáticas e visualização HTML em tempo real.
Pintura AI: Painel dedicado para geração de imagens por descrição textual.
Mini Programas AI: Diversas ferramentas AI gratuitas integradas sem necessidade de alternar navegadores.
Tradução: Suporte para painel de tradução, tradução em conversas e tradução de prompts.
Gestão de Arquivos: Arquivos organizados por categorias em conversas, arte e base de conhecimento.
Busca Global: Localização rápida em histórico e base de conhecimento.
Agregação de Modelos: Integra modelos de OpenAI, Gemini, Anthropic, Azure em interface única.
Listagem Automática: Obtenção automática da lista completa de modelos sem configuração manual.
Rotação de Chaves API: Gerencia múltiplas chaves para evitar limites de taxa.
Avatares Personalizados: Avatar dedicado para cada modelo reconhecível.
Provedores Customizáveis: Suporte para provedores compatíveis com OpenAI/Gemini/Anthropic.
CSS Personalizado: Personalização global de estilos visuais.
Layouts de Conversa: Opções de lista ou formato de bolhas com estilização customizada.
Avatares Personalizados: Personalização de avatar para software e assistentes.
Menu Lateral Configurável: Ocultar/reordenar funcionalidades do menu lateral.
Suporte Multi-formato: Importação de PDF, DOCX, PPTX, XLSX, TXT, MD.
Múltiplas Fontes: Ficheiros locais, URLs, mapas de site ou conteúdo manual.
Exportação de Base de Conhecimento: Compartilhamento de bases processadas.
Teste de Busca Integrado: Verificação imediata de segmentação após importação.
Perguntas Rápidas: Assistente instantâneo em qualquer contexto (WeChat, navegador).
Tradução Instantânea: Tradução rápida de palavras/textos em qualquer aplicativo.
Resumo de Conteúdo: Sumarização de textos longos para extração eficiente.
Explicação Simples: Compreensão de conceitos sem prompts complexos.
Múltiplos Backups: Backup local, WebDAV e agendado.
Uso Totalmente Local: Integração com modelos locais para evitar vazamentos.
Simplicidade: Cherry Studio simplifica o uso de AI para iniciantes.
Documentação Completa: Manuais detalhados de uso e solução de problemas.
Atualizações Contínuas: Melhorias frequentes baseadas em feedback.
Código Aberto: Personalização e expansão via código fonte.
Gestão de Conhecimento: Construção e consulta de bases especializadas para pesquisa/educação.
Criação com Múltiplos Modelos: Geração de conteúdo e informação simultânea.
Tradução e Automação: Processamento de documentos e comunicação multilíngue.
Arte e Design AI: Geração de imagens criativas por descrição textual.
















Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Endereço oficial de referência do modelo
Doubao-embedding
4095
Doubao-embedding-vision
8191
Doubao-embedding-large
4095
Endereço oficial de referência do modelo
text-embedding-v3
8192
text-embedding-v2
2048
text-embedding-v1
2048
text-embedding-async-v2
2048
text-embedding-async-v1
2048
Endereço oficial de referência do modelo
text-embedding-3-small
8191
text-embedding-3-large
8191
text-embedding-ada-002
8191
Endereço oficial de referência do modelo
Embedding-V1
384
tao-8k
8192
Endereço oficial de referência do modelo
embedding-2
1024
embedding-3
2048
Endereço oficial de referência do modelo
hunyuan-embedding
1024
Endereço oficial de referência do modelo
Baichuan-Text-Embedding
512
Endereço oficial de referência do modelo
M2-BERT-80M-2K-Retrieval
2048
M2-BERT-80M-8K-Retrieval
8192
M2-BERT-80M-32K-Retrieval
32768
UAE-Large-v1
512
BGE-Large-EN-v1.5
512
BGE-Base-EN-v1.5
512
Endereço oficial de referência do modelo
jina-embedding-b-en-v1
512
jina-embeddings-v2-base-en
8191
jina-embeddings-v2-base-zh
8191
jina-embeddings-v2-base-de
8191
jina-embeddings-v2-base-code
8191
jina-embeddings-v2-base-es
8191
jina-colbert-v1-en
8191
jina-reranker-v1-base-en
8191
jina-reranker-v1-turbo-en
8191
jina-reranker-v1-tiny-en
8191
jina-clip-v1
8191
jina-reranker-v2-base-multilingual
8191
reader-lm-1.5b
256000
reader-lm-0.5b
256000
jina-colbert-v2
8191
jina-embeddings-v3
8191
Endereço oficial de referência do modelo
BAAI/bge-m3
8191
netease-youdao/bce-embedding-base_v1
512
BAAI/bge-large-zh-v1.5
512
BAAI/bge-large-en-v1.5
512
Pro/BAAI/bge-m3
8191
Endereço oficial de referência do modelo
text-embedding-004
2048
Endereço oficial de referência do modelo
nomic-embed-text-v1
8192
nomic-embed-text-v1.5
8192
gte-multilingual-base
8192
Endereço oficial de referência do modelo
embedding-query
4000
embedding-passage
4000
Endereço oficial de referência do modelo
embed-english-v3.0
512
embed-english-light-v3.0
512
embed-multilingual-v3.0
512
embed-multilingual-light-v3.0
512
embed-english-v2.0
512
embed-english-light-v2.0
512
embed-multilingual-v2.0
256
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Use este método para limpar as configurações CSS quando configurar um CSS incorreto ou quando não conseguir acessar a interface de configurações após definir o CSS.
Abra o console: clique na janela do CherryStudio e pressione Ctrl+Shift+I (MacOS: command+option+I).
Na janela do console exibida, clique em Console
Digite manualmente document.getElementById('user-defined-custom-css').remove() (copiar e colar provavelmente não funcionará).
Pressione Enter após digitar para limpar as configurações CSS, depois retorne às configurações de exibição do CherryStudio para remover o código CSS problemático.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Atualmente, a funcionalidade de desenho suporta modelos de geração de imagens de DMXAPI, TokenFlux, AiHubMix e SiliconFlow. Você pode registrar uma conta no SiliconFlow e adicioná-lo como provedor para utilização.
Para dúvidas sobre os parâmetros, passe o mouse sobre o ? na área correspondente para ver as instruções.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Os dados adicionados à base de conhecimento do Cherry Studio são armazenados localmente. Durante o processo de adição, uma cópia do documento é colocada no diretório de armazenamento de dados do Cherry Studio.
Banco de dados vetorial: https://turso.tech/libsql
Após os documentos serem adicionados à base de conhecimento do Cherry Studio, os arquivos são divididos em vários fragmentos. Esses fragmentos são então processados pelo modelo de embedding.
Ao usar o modelo de linguagem grande para Q&A, fragmentos de texto relevantes à pergunta são recuperados e enviados ao modelo de linguagem grande para processamento.
Se houver requisitos de privacidade de dados, recomenda-se usar um banco de dados de embedding local e um modelo de linguagem grande local.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Antes de obter a chave API do Gemini, você precisa ter um projeto no Google Cloud (se já tiver, pode pular esta etapa).
Acesse o para criar um projeto, preencha o nome do projeto e clique em "Criar projeto".
Na página oficial de , clique em Chave secreta Criar chave API.
Copie a chave gerada e abra as do CherryStudio.
Encontre o fornecedor Gemini e insira a chave obtida.
Clique em "Gerenciar" ou "Adicionar" na parte inferior, inclua os modelos suportados e ative o interruptor do fornecedor no canto superior direito para começar a usar.




Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Observações sobre a tradução:
Seguindo as regras, traduzi apenas o conteúdo textual ("安装教程" ➔ "Tutorial de Instalação")
Mantive inalterada a estrutura de cabeçalho (#) conforme solicitado
Não foram adicionados elementos extras ou explicações
Esta é a tradução padrão para PT-BR utilizada em documentação técnica
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
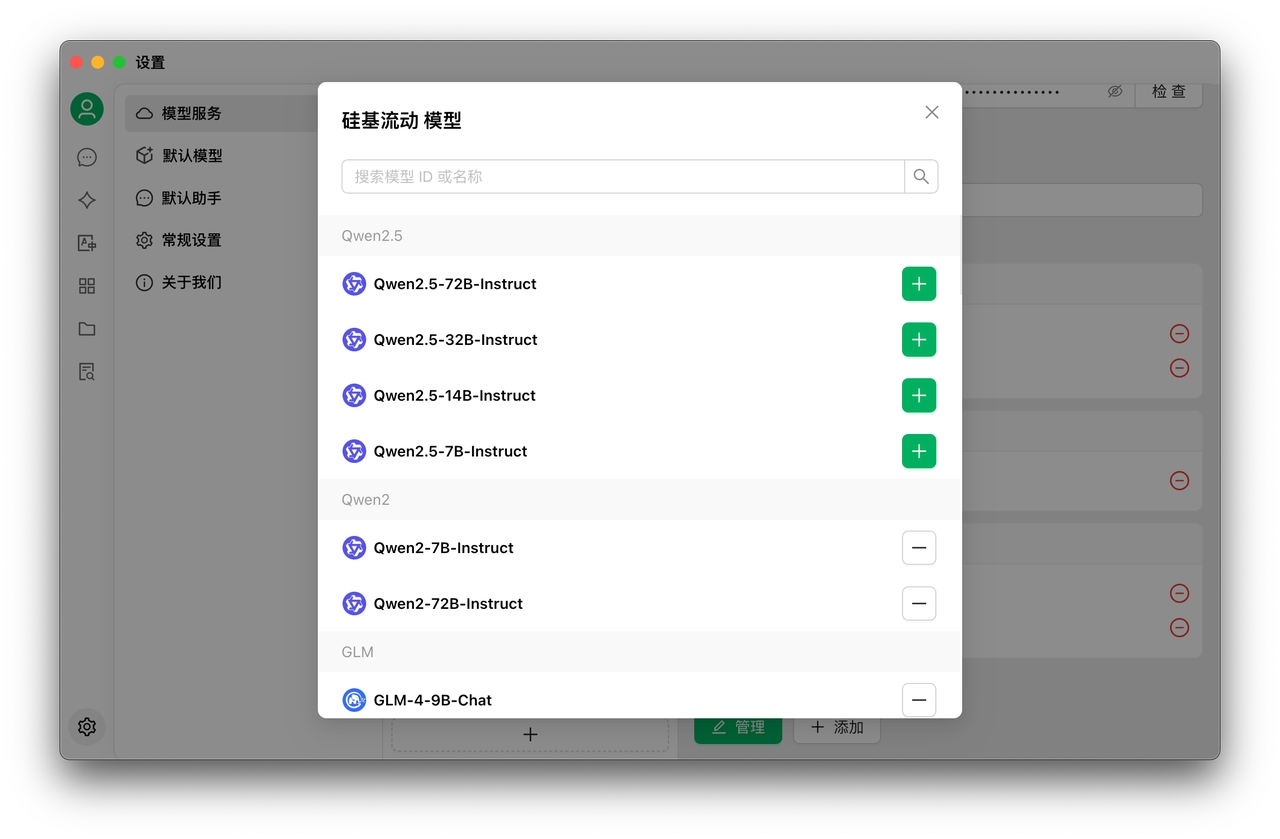
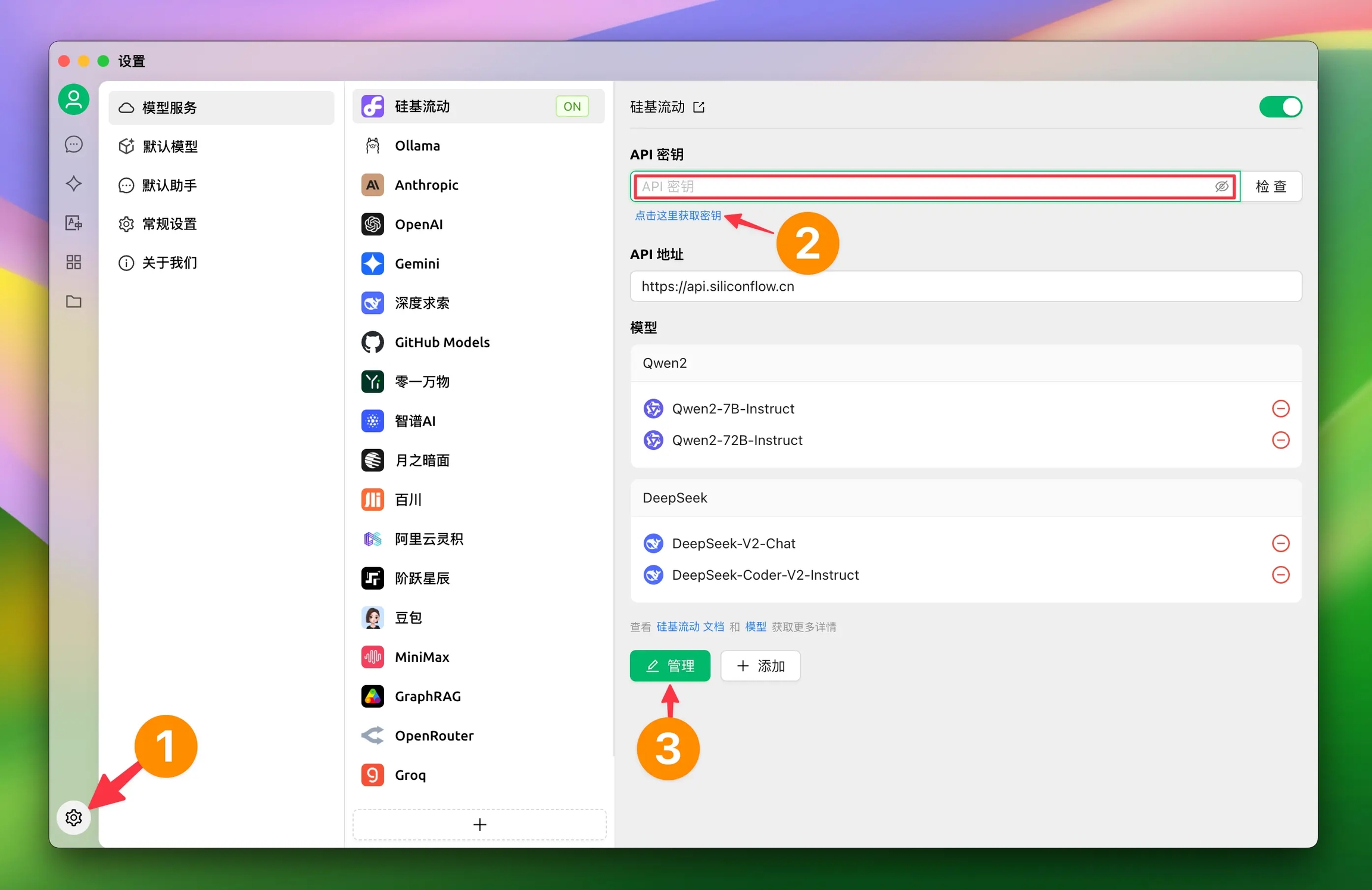
1.2 Clique nas configurações no canto inferior esquerdo e selecione SiliconFlow nos Serviços de Modelos
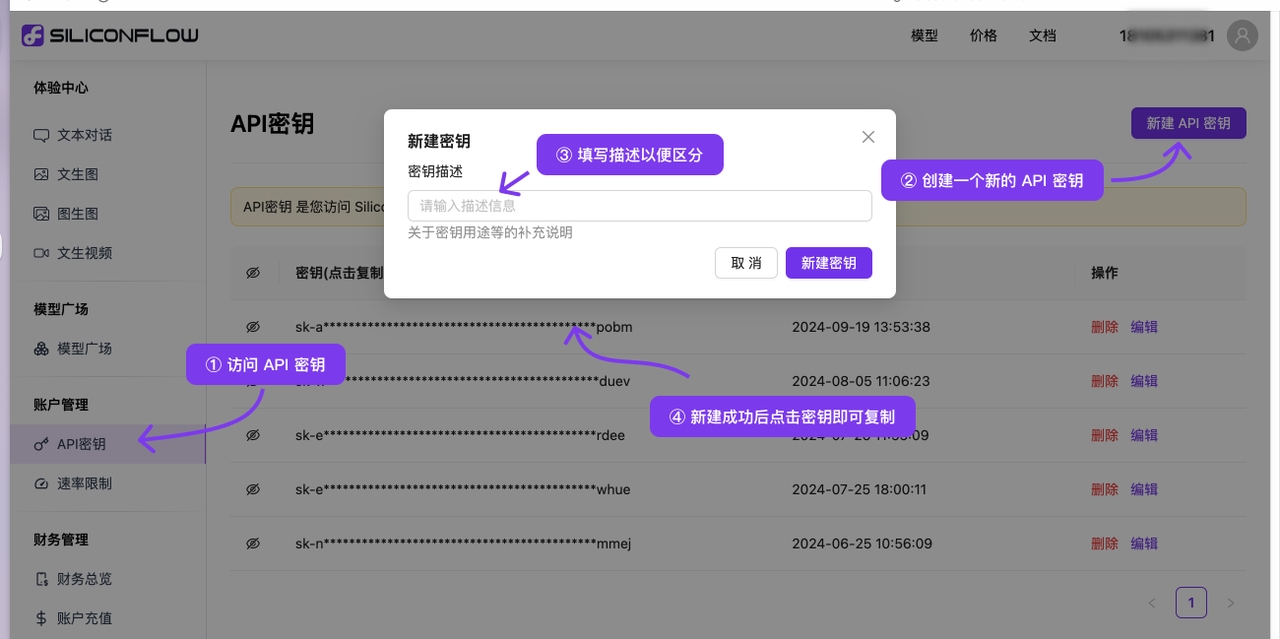
1.2 Clique no link para obter a chave de API do SiliconCloud
Faça login no SiliconCloud (se não estiver registado, o primeiro login criará automaticamente uma conta)
Acesse Chaves API para criar uma nova ou copiar uma chave existente
1.3 Clique em Gerenciar para adicionar modelos
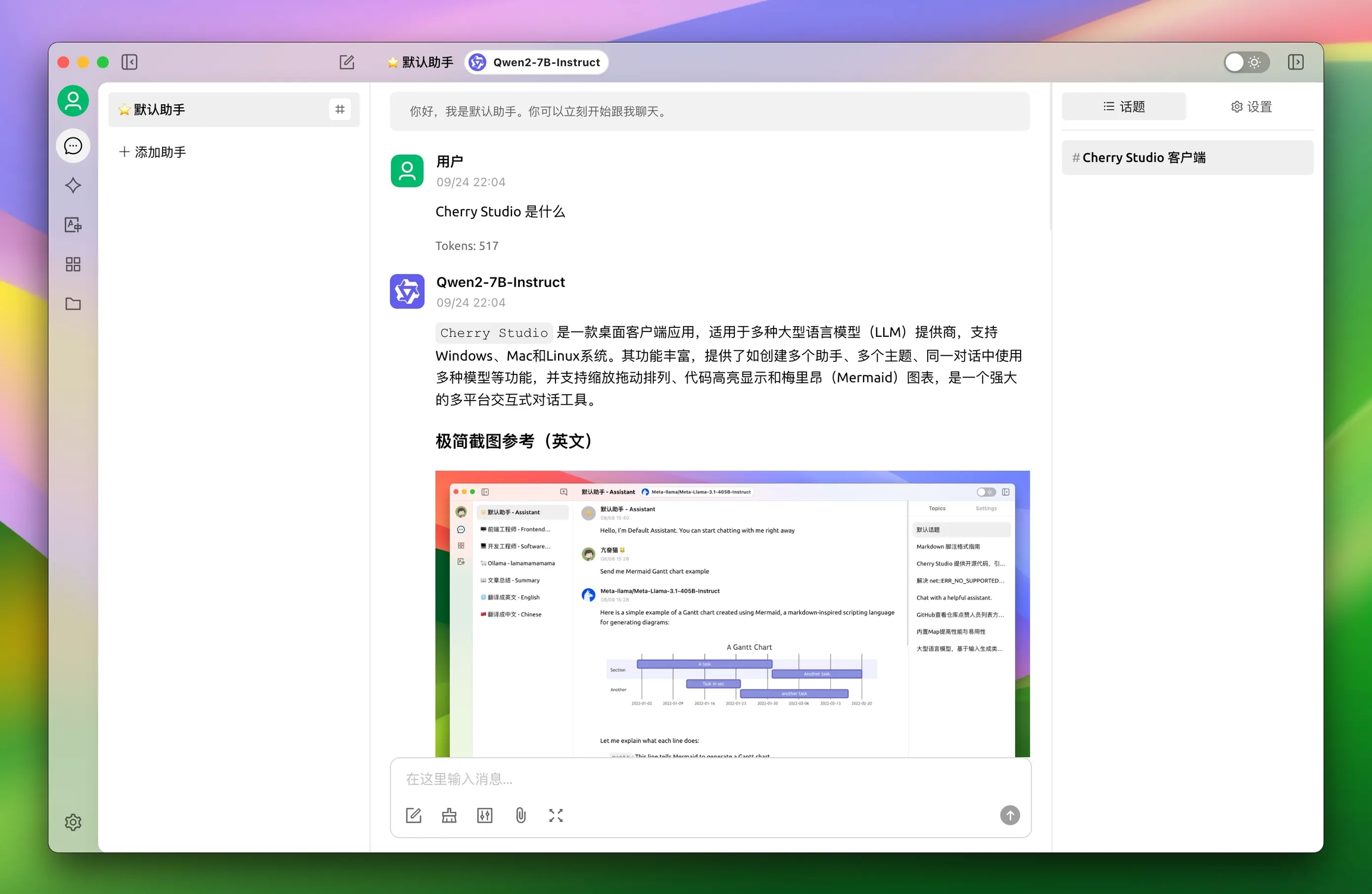
Clique no botão "Conversa" na barra lateral esquerda
Digite texto no campo de entrada para iniciar o bate-papo
Selecione os nomes dos modelos no menu superior para alternar entre modelos
暂时不支持Claude模型
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Antes de obter a chave de API do Gemini, você precisa ter um projeto no Google Cloud (se já tiver, pule esta etapa)
Acesse o Google Cloud para criar um projeto, preencha o nome do projeto e clique em "Criar projeto"
Acesse o console do Vertex AI
No projeto criado, ative a API Vertex AI
Abra a página de permissões de contas de serviço e crie uma conta de serviço
Na página de gerenciamento de contas de serviço, localize a conta recém-criada, clique em Chaves e crie uma nova chave no formato JSON
Após a criação bem-sucedida, o arquivo de chave será salvo automaticamente em seu computador no formato JSON. Guarde-o cuidadosamente
Selecione o provedor Vertex AI
Preencha os campos correspondentes com os dados do arquivo JSON
Clique em Adicionar Modelo e você já pode começar a usar!
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Nesta página você pode configurar o tema de cores do software, o layout da página ou CSS personalizado para fazer algumas personalizações.
Aqui você pode configurar o modo de cor padrão da interface (modo claro, modo escuro ou seguir o sistema)
Esta configuração é para o layout da interface de conversa.
Posição do Tópico
Alternar automaticamente para tópico
Quando ativado, clicar no nome do assistente mudará automaticamente para a página do tópico correspondente.
Mostrar hora do tópico
Quando ativado, mostra a hora de criação do tópico abaixo do tópico.
Esta configuração permite fazer alterações e ajustes personalizados na interface de forma flexível. Para métodos específicos, consulte CSS personalizado no tutorial avançado.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Esta página apenas apresenta as funcionalidades da interface. Para tutoriais de configuração, consulte o tutorial de Configuração do Provedor no guia básico.
No Cherry Studio, um único provedor suporta múltiplas chaves em rodízio sequencial.
Adicione múltiplas chaves separadas por vírgulas inglesas:
sk-xxxx1,sk-xxxx2,sk-xxxx3,sk-xxxx4Sempre use vírgulas em inglês.
Geralmente não é necessário preencher ao usar provedores internos. Se precisar modificar, siga estritamente o endereço da documentação oficial.
Se o provedor fornecer um endereço como https://xxx.xxx.com/v1/chat/completions, insira apenas a parte base (https://xxx.xxx.com).
O Cherry Studio completará automaticamente o caminho (/v1/chat/completions). Formato incorreto pode causar falhas.
Clique em Gerenciar (canto inferior esquerdo) para ver os modelos suportados. Clique no + ao lado de cada modelo para adicioná-lo à lista.
Clique no botão de verificação ao lado do campo da chave para testar a configuração.
Ative o interruptor no canto superior direito após configurar, caso contrário o provedor permanecerá inativo.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Suporta a exportação de tópicos e mensagens para o SiYuan Notes.
Abra o SiYuan Notes e crie um caderno
Abra as configurações do caderno e copie o ID do Caderno
Cole o ID do caderno nas configurações do Cherry Studio
Insira o endereço do SiYuan Notes
Local
Normalmente http://127.0.0.1:6806
Auto-hospedado
Seu domínio http://note.dominio.com
Copie o Token de API do SiYuan Notes
Cole nas configurações do Cherry Studio e verifique
Parabéns! A configuração do SiYuan Notes está completa ✅ Agora você pode exportar conteúdo do Cherry Studio para seu SiYuan Notes
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Vá até o site para criar uma conta e fazer login
Clique para acessar o console do Maa S
Autorização
Clique em "Gestão de Autenticação" na barra lateral, crie uma API Key (chave secreta) e copie-a
Em seguida, crie um novo provedor no CherryStudio
Após criar, cole a chave secreta
Clique em "Model Deployment" na barra lateral e ative todas as opções
Clique em "Invoke"
Copie o endereço em ① e cole no campo de endereço do provedor do CherryStudio, adicionando "#" ao final e adicione "#" ao final e adicione "#" ao final e adicione "#" ao final e adicione "#" ao final
Por que adicionar "#"?
Você também pode ignorar e seguir o tutorial diretamente; Ou usar o método de excluir "v1/chat/completions" - preencha como preferir, mas siga rigorosamente o tutorial se não tiver experiência.
Copie o nome do modelo em ②, clique em "+ Adicionar" no CherryStudio para criar novo modelo
Digite o nome do modelo exatamente como exibido, sem adicionar elementos extras ou aspas.
Clique em "Adicionar Modelo" para concluir.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Abra as configurações do Cherry Studio.
Encontre a opção Servidor MCP.
Clique em Adicionar Servidor.
Preencha os parâmetros relevantes do MCP Server (). Os campos que podem ser necessários incluem:
Nome: Personalize um nome, por exemplo fetch-server
Tipo: Selecione STDIO
Comando: Preencha uvx
Parâmetros: Preencha mcp-server-fetch
(Pode haver outros parâmetros dependendo do servidor específico)
Clique em Salvar.
Após concluir a configuração acima, o Cherry Studio irá baixar automaticamente o MCP Server necessário - fetch server. Após o download ser concluído, podemos começar a usar! Observação: Se a configuração do mcp-server-fetch não for bem-sucedida, tente reiniciar o computador.
Servidor MCP adicionado com sucesso nas configurações
Como pode ser visto na imagem acima, após combinar a funcionalidade fetch do MCP, o Cherry Studio consegue entender melhor a intenção de consulta do usuário, obter informações relevantes da internet e fornecer respostas mais precisas e abrangentes.
Monaspace
英文字体 可商用
A GitHub lançou a família de fontes de código aberto chamada Monaspace, com cinco estilos disponíveis: Neon (estilo moderno), Argon (estilo humanístico), Xenon (estilo serif), Radon (estilo manuscrito) e Krypton (estilo mecânico).
MiSans Global
多语言 可商用
O MiSans Global é um projeto de personalização de fontes multilíngues liderado pela Xiaomi, em colaboração com a Monotype e a HanYi Font.
Trata-se de uma família de fontes abrangente, cobrindo mais de 20 sistemas de escrita e suportando mais de 600 idiomas.













mcp-server-time
--local-timezone
<seu fuso horário padrão, por exemplo: Asia/Shanghai>






















Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Quando um assistente não possui um modelo padrão configurado, o modelo selecionado por padrão em novas conversas será o modelo definido aqui.
A otimização de prompts e o assistente de seleção de texto também utilizam o modelo configurado nesta seção.
Após cada conversa, um modelo é acionado para gerar um nome para o tópico da conversa. O modelo configurado aqui é utilizado para essa nomeação.
As funções de tradução nas caixas de entrada de conversas, pintura e outros campos, bem como os modelos de tradução na interface de tradução, utilizam o modelo definido aqui.
O modelo utilizado pela funcionalidade do Assistente Rápido, detalhado em Assistente Rápido.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Esta interface permite operações como backup de dados do cliente em nuvem e local, consulta do diretório de dados local e limpeza de cache.
Atualmente, o backup de dados é suportado apenas através do método WebDAV. Você pode escolher serviços compatíveis com WebDAV para fazer backup na nuvem.
Também é possível sincronizar dados em múltiplos dispositivos usando o método:
Computador A WebDAV Computador B.
Exemplo usando Nutstore
Faça login no Nutstore, clique no nome de usuário no canto superior direito e selecione "Informações da conta":
Selecione "Opções de segurança" e clique em "Adicionar aplicativo":
Insira o nome do aplicativo e gere uma senha aleatória:
Copie e registre a senha:
Obtenha o endereço do servidor, nome de usuário e senha:
No Cherry Studio Configurações > Configurações de Dados, preencha as informações WebDAV:
Selecione fazer backup ou restaurar dados e configure o intervalo de backup automático:
Serviços WebDAV com baixo limite de acesso geralmente são serviços de armazenamento em nuvem:
123Pan (requer assinatura)
AliPan (requer compra)
Box (espaço gratuito de 10GB, limite de 250MB por arquivo)
Dropbox (2GB gratuito, ampliável para 16GB com convites)
TeraCloud (10GB gratuito, +5GB com convites)
Yandex Disk (10GB gratuito)
Serviços que exigem autoimplatação:
如何在 Cherry Studio 使用联网模式
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Na janela de perguntas do Cherry Studio, clique no ícone 【Globo Terrestre】 para ativar a conexão à internet.
Modo 1: A capacidade de conexão nativa dos grandes modelos dos provedores
Nesse caso, após ativar a conexão, você pode usar diretamente o serviço online, o que é muito simples.
Você pode verificar rapidamente se o modelo suporta conexão à internet observando se há um ícone de mapa pequeno ao lado do nome do modelo na parte superior da interface de perguntas e respostas.
Na página de gerenciamento de modelos, este método também permite identificar rapidamente quais modelos suportam conexão à internet.
Provedores de modelos com suporte de conexão atualmente no Cherry Studio:
Google Gemini
OpenRouter (todos os modelos suportam conexão)
Tencent Hunyuan
Zhipu AI
Alibaba Cloud Bailian, etc.
Atenção especial: Existe uma situação excepcional em que o modelo pode realizar conexão mesmo sem o ícone do globo, como explicado no tutorial abaixo.
Modo 2: Usar o serviço Tavily para habilitar conexão em modelos não nativos
Quando usamos grandes modelos sem capacidade de conexão nativa (sem ícone de globo) e precisamos acessar informações em tempo real, utilizamos o serviço de pesquisa na web do Tavily.
No primeiro uso do Tavily, uma janela pop-up solicitará configurações. Siga as instruções - é muito simples!
Após clicar, você será redirecionado para a página de login/registro do site oficial do Tavily. Após registrar e fazer login, crie uma API key e cole-a no Cherry Studio.
Se precisar de ajuda com o registro, consulte o tutorial de registro Tavily neste mesmo diretório.
Documento de referência para registro no Tavily:
A interface abaixo indica que o registro foi bem-sucedido.
Teste novamente para ver o efeito. O resultado mostra que a pesquisa online está funcionando, com o número padrão de resultados definido como 5.
Nota: O Tavily tem limites gratuitos mensais; o uso excedente requer pagamento.
PS: Se encontrar erros, sinta-se à vontade para entrar em contato a qualquer momento.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Faça login no Volcano Engine
Clique diretamente aqui para acessar
Clique em Gerenciamento de Chave API na barra lateral inferior
Crie uma Chave API
Após criar com sucesso, clique no ícone de olho 👁️ ao lado da Chave API e copie
Cole a Chave API copiada no CherryStudio e ative o interruptor do provedor.
Na barra lateral do Console Ark, acesse Gerenciamento de Ativação para ativar os modelos necessários. Você pode ativar conforme necessidade os modelos da série Doubao e DeepSeek.
No documento da lista de modelos, localize o Model ID correspondente ao modelo desejado.
Acesse as configurações de Serviço de Modelos do Cherry Studio, encontre "Volcano Engine"
Clique em adicionar e cole o Model ID obtido anteriormente na caixa de texto Model ID
Repita este processo para adicionar modelos sequencialmente
Existem duas formas de escrever o endereço da API:
Primeira (padrão do cliente): https://ark.cn-beijing.volces.com/api/v3/
Segunda: https://ark.cn-beijing.volces.com/api/v3/chat/completions#
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
A função de tradução do Cherry Studio oferece serviços de tradução de texto rápidos e precisos, suportando traduções mútuas entre diversos idiomas.
A interface de tradução é composta principalmente pelas seguintes partes:
Área de seleção do idioma de origem:
Idioma qualquer: O Cherry Studio identificará automaticamente o idioma de origem e realizará a tradução.
Área de seleção do idioma de destino:
Menu suspenso: Selecione o idioma para o qual deseja traduzir o texto.
Botão de configurações:
Ao clicar, redirecionará para as Configurações de Modelo Padrão.
Sincronização de rolagem:
Alterna a sincronização de rolagem (ao rolar em qualquer lado, o outro acompanhará).
Campo de entrada de texto (esquerdo):
Insira ou cole o texto que precisa ser traduzido.
Caixa de resultados da tradução (direita):
Exibe o texto traduzido.
Botão de cópia: Clique para copiar o resultado da tradução para a área de transferência.
Botão de traduzir:
Clique neste botão para iniciar a tradução.
Histórico de traduções (canto superior esquerdo):
Ao clicar, é possível visualizar o histórico de traduções.
Selecione o idioma de destino:
Na área de seleção de idioma de destino, escolha o idioma desejado.
Insira ou cole o texto:
Digite ou cole o texto a ser traduzido no campo de entrada à esquerda.
Inicie a tradução:
Clique no botão Traduzir.
Visualize e copie o resultado:
Os resultados aparecerão na caixa de tradução à direita.
Clique no botão de cópia para copiar os resultados para a área de transferência.
P: O que fazer se a tradução não for precisa?
R: A tradução por IA, embora avançada, não é perfeita. Para textos técnicos ou contextos complexos, recomendamos revisão humana. Você também pode tentar alternar entre diferentes modelos.
P: Quais idiomas são suportados?
R: O Cherry Studio oferece suporte a múltiplos idiomas principais. Consulte o site oficial ou as instruções no aplicativo para a lista completa.
P: É possível traduzir arquivos inteiros?
R: A interface atual é focada em tradução de textos. Para arquivos, acesse a página de conversa do Cherry Studio e adicione o arquivo para tradução.
P: Como lidar com traduções lentas?
R: A velocidade pode variar devido à conexão de internet, extensão do texto ou carga do servidor. Garanta uma conexão estável e aguarde pacientemente.
Windows 版本安装教程
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Atenção: O sistema Windows 7 não suporta a instalação do Cherry Studio.
Clique em baixar e selecione a versão apropriada
Se o navegador avisar que o arquivo não é confiável, etc., basta escolher manter o arquivo.
Escolher manter→Confiar no Cherry-Studio
macOS 版本安装教程
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Primeiro, acesse a página de download no site oficial e clique para baixar a versão para Mac, ou clique no link direto abaixo.
Observe que você deve baixar a versão correspondente ao chip do seu Mac {% hint style="info" %} Se você não sabe qual versão de chip o seu Mac deve usar:
Clique no menu no canto superior esquerdo do Mac
No menu expandido, clique em "Sobre este Mac"
Na janela que aparece, verifique as informações do processador
Se for um chip Intel, baixe o pacote de instalação da versão Intel.
Se for um chip Apple M*, baixe o pacote de instalação para chips Apple. {% endhint %}
Após o download, clique aqui
Arraste o ícone para instalar
No Launchpad, busque o ícone do Cherry Studio e clique nele. Se a tela principal do Cherry Studio abrir, a instalação foi bem-sucedida.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Faça login e acesse a página de tokens
Clique em Adicionar Token
Insira o nome do token e clique em Enviar (defina outras configurações conforme necessário)
Acesse as configurações de provedor do CherryStudio e clique em Adicionar no final da lista de provedores
Digite um nome de referência, selecione OpenAI como provedor e clique em Confirmar
Cole a chave copiada anteriormente
Volte à página de obtenção da API Key e copie o endereço base na barra de URL do navegador, por exemplo:
Adicione modelos (clique em Gerenciar para obter automaticamente ou insira manualmente) e ative o botão no canto superior direito para usar.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
O Assistente Rápido é uma ferramenta conveniente fornecida pelo Cherry Studio que permite acessar rapidamente funções de IA em qualquer aplicativo, possibilitando operações como questionamentos instantâneos, tradução, resumo e explicação.
Abrir configurações: Navegue até Configurações -> Atalhos -> Assistente Rápido.
Ativar alternador: Localize e ative o botão correspondente ao Assistente Rápido.
Configurar atalho (opcional):
Atalho padrão para Windows: Ctrl + E.
Atalho padrão para macOS: ⌘ + E.
Você pode personalizar o atalho aqui para evitar conflitos ou adaptá-lo ao seu fluxo de trabalho.
Ativar: Em qualquer aplicativo, pressione o atalho configurado (ou o padrão) para abrir o Assistente Rápido.
Interagir: Na janela do Assistente Rápido, você pode realizar diretamente as seguintes operações:
Pergunta rápida: Faça qualquer pergunta à IA.
Tradução de texto: Insira o texto que precisa ser traduzido.
Resumo de conteúdo: Insira textos longos para síntese.
Explicação: Insira conceitos ou termos que precisam ser elucidados.
Fechar: Pressione a tecla ESC ou clique em qualquer área fora da janela do Assistente Rápido para fechá-la.
Conflito de atalhos: Se o atalho padrão entrar em conflito com outro aplicativo, modifique-o.
Explore mais funções: Além das funcionalidades mencionadas, o Assistente Rápido pode suportar outras operações como geração de código, conversão de estilo, etc. Recomendamos explorar durante o uso.
Feedback e melhorias: Caso encontre problemas ou tenha sugestões, à equipe do Cherry Studio.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Para usar o GitHub Copilot, primeiro você precisa ter uma conta no GitHub e assinar o serviço GitHub Copilot. A assinatura gratuita (free) também funciona, mas a versão gratuita não suporta o modelo mais recente Claude 3.7. Para detalhes, consulte o .
Clique em "Login GitHub" para obter o Device Code e copie-o.
Após obter o Device Code com sucesso, clique no link para abrir o navegador. Faça login na sua conta GitHub no navegador, insira o Device Code e autorize o acesso.
Após a autorização bem-sucedida, retorne ao Cherry Studio e clique em "Conectar GitHub". Após a conexão bem-sucedida, seu nome de usuário e avatar do GitHub serão exibidos.
Clique no botão "Gerenciar" abaixo para buscar automaticamente via internet a lista de modelos suportados atualmente.
Atualmente, usamos o Axios para construir solicitações. O Axios não suporta proxy SOCKS. Use proxy de sistema, proxy HTTP ou não configure proxy no CherryStudio, utilizando um proxy global. Primeiro, certifique-se de que sua conexão de rede esteja normal para evitar falhas ao obter o Device Code.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
O pré-processamento de documentos da base de conhecimento requer a atualização do Cherry Studio para a versão v1.4.8 ou superior.
Após clicar em "Obter chave de API", o endereço de inscrição será aberto no navegador. Clique em "Aplicar imediatamente", preencha o formulário para obter a chave de API e insira-a no campo correspondente.
Na base de conhecimento já criada, configure conforme mostrado acima para concluir o pré-processamento de documentos.
É possível verificar os resultados da base de conhecimento através da pesquisa no canto superior direito
Dicas de uso da base de conhecimento: Ao usar modelos mais poderosos, altere o modo de pesquisa para "reconhecimento de intenção". Isso permite descrever sua pergunta com maior precisão e amplitude.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Aceitamos contribuições para o Cherry Studio! Você pode contribuir das seguintes formas:
1. Contribuir com código: Desenvolver novos recursos ou otimizar o código existente. 2. Corrigir erros: Enviar correções de erros que você encontrou. 3. Manter problemas: Ajudar a gerenciar problemas no GitHub. 4. Design de produto: Participar de discussões de design. 5. Escrever documentação: Melhorar manuais e guias do usuário. 6. Envolvimento na comunidade: Participar de discussões e ajudar usuários. 7. Promover o uso: Divulgar o Cherry Studio.
Envie e-mail para
Assunto: 申请成为开发者 Conteúdo: 申请理由
Este documento foi traduzido do chinês por IA e ainda não foi revisado.











































Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Instalação automática do serviço MCP (beta)
Implementação baseada em grafo de conhecimento local para memória persistente. Isso permite que o modelo se lembre de informações relevantes do usuário entre diferentes conversas.
MEMORY_FILE_PATH=/path/to/your/file.jsonUma implementação de servidor MCP que fornece ferramentas para resolução dinâmica e reflexiva de problemas através de processos de pensamento estruturados.
Uma implementação de servidor MCP que integra a API de busca Brave, oferecendo funcionalidade dupla de pesquisa na web e pesquisa local.
BRAVE_API_KEY=YOUR_API_KEYServidor MCP para obter conteúdo de páginas da web a partir de URLs.
Servidor Node.js que implementa o Model Context Protocol (MCP) para operações de sistema de arquivos.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Bem-vindo ao Cherry Studio (doravante referido como "este software" ou "nós"). Valorizamos profundamente a proteção da sua privacidade, e esta Política de Privacidade explicará como tratamos e protegemos suas informações e dados pessoais. Por favor, leia e compreenda cuidadosamente este acordo antes de utilizar este software:
Para otimizar a experiência do usuário e melhorar a qualidade do software, podemos coletar anonimamente as seguintes informações não pessoais:
• Informações da versão do software; • Atividade e frequência de uso das funcionalidades; • Informações anônimas de logs de falhas e erros;
Essas informações são completamente anônimas, não envolvem nenhum dado de identidade pessoal e não podem ser vinculadas às suas informações pessoais.
Para proteger ao máximo sua privacidade, comprometemo-nos expressamente com o seguinte:
• Não coletamos, armazenamos, transmitimos ou processamos suas chaves de API de serviços de modelos inseridas neste software; • Não coletamos, armazenamos, transmitimos ou processamos quaisquer dados de conversa gerados durante o uso do software, incluindo mas não limitado a: conteúdo de chats, informações de comandos, dados de bases de conhecimento, vetores de dados ou outros conteúdos personalizados; • Não coletamos, armazenamos, transmitimos ou processamos qualquer informação sensível que possa identificar pessoalmente.
Este software utiliza chaves de API de provedores de serviços de modelos terceirizados solicitadas e configuradas por você para realizar chamadas de modelos e funcionalidades de conversação. Os serviços de modelo utilizados (como LLMs, interfaces de API, etc.) são fornecidos e inteiramente responsabilizados pelo provedor terceirizado de sua escolha. O Cherry Studio atua apenas como uma ferramenta local que fornece funcionalidades de interface para serviços de modelos terceirizados.
Portanto:
• Todos os dados de conversa entre você e os serviços de modelos não têm relação com o Cherry Studio - não armazenamos, transmitimos ou intermediamos esses dados de forma alguma; • Você deve revisar e aceitar as políticas de privacidade e termos relacionados do respectivo provedor de serviços de modelos terceirizado. Essas políticas podem ser encontradas nos sites oficiais de cada provedor.
Você assume integralmente os possíveis riscos de privacidade decorrentes do uso de provedores terceirizados de serviços de modelos. Para políticas de privacidade específicas, medidas de segurança de dados e responsabilidades pertinentes, consulte o conteúdo relevante no site oficial do provedor escolhido. Não nos responsabilizamos por tais questões.
Este acordo pode ser ajustado conforme atualizações do software. Acompanhe periodicamente as alterações. Quando ocorrerem mudanças substanciais, notificaremos você de forma apropriada.
Caso tenha dúvidas sobre esta política ou as medidas de proteção de privacidade do Cherry Studio, não hesite em nos contatar.
Agradecemos por escolher e confiar no Cherry Studio. Continuaremos fornecendo uma experiência de produto segura e confiável.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Envie um e-mail para [email protected] para obter acesso de edição
Título: Solicitar acesso de edição para Cherry Studio Docs
Corpo do e-mail: Preencha o motivo da solicitação








Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Ollama é uma excelente ferramenta de código aberto que permite executar e gerenciar facilmente vários modelos de linguagem grandes (LLMs) localmente. O Cherry Studio agora suporta integração com Ollama, permitindo que você interaja diretamente com LLMs implantados localmente na interface familiar, sem depender de serviços em nuvem!
Ollama é uma ferramenta que simplifica a implantação e uso de modelos de linguagem grandes (LLMs). Ele possui as seguintes características:
Execução local: Os modelos são executados completamente no seu computador local, sem necessidade de conexão à internet, protegendo sua privacidade e segurança de dados.
Simples e fácil de usar: Com comandos simples de linha de comando, você pode baixar, executar e gerenciar vários LLMs.
Riqueza de modelos: Suporta diversos modelos de código aberto populares como Llama 2, Deepseek, Mistral, Gemma, entre outros.
Multiplataforma: Compatível com macOS, Windows e Linux.
API Aberta: Possui interface compatível com OpenAI e pode ser integrado com outras ferramentas.
Sem serviços de nuvem: Não está mais limitado por cotas e custos de API em nuvem, desfrute plenamente do poder dos LLMs locais.
Privacidade de dados: Todos os seus dados de conversa permanecem locais, sem preocupações com vazamento de privacidade.
Disponível offline: Mesmo sem conexão à internet, você pode continuar interagindo com o LLM.
Personalização: Selecione e configure o LLM que melhor atenda às suas necessidades.
Primeiro, você precisa instalar e executar o Ollama no seu computador:
Baixar Ollama: Visite o site oficial do Ollama (https://ollama.com/) e baixe o pacote correspondente ao seu sistema operacional. No Linux, você pode instalar diretamente via comando:
curl -fsSL https://ollama.com/install.sh | shInstalar Ollama: Siga as instruções do instalador para completar a instalação.
Baixar modelos: Abra o terminal (ou prompt de comando) e use o comando ollama run para baixar o modelo desejado. Exemplo para baixar Llama 3.2:
ollama run llama3.2O Ollama baixará e executará o modelo automaticamente.
Manter Ollama em execução: Certifique-se de que o Ollama permaneça em execução durante sua interação com os modelos via Cherry Studio.
Adicione o Ollama como provedor personalizado de IA:
Abrir configurações: Na barra lateral do Cherry Studio, clique no ícone de engrenagem "Configurações".
Acessar serviços de modelo: Selecione a aba "Model Services" (Serviços de Modelo).
Adicionar provedor: Clique em "Ollama" na lista.
Localize o Ollama na lista de provedores e configure:
Status de ativação:
Ative o interruptor à direita para habilitar o serviço.
Chave API:
O Ollama não requer chave API por padrão. Deixe este campo vazio ou preencha arbitrariamente.
Endereço API:
Insira o endereço local da API do Ollama (padrão):
http://localhost:11434/Ajuste se você alterou a porta.
Tempo de manutenção ativa: Define o tempo máximo de inatividade da sessão (em minutos). O Cherry Studio desconectará automaticamente após este período para liberar recursos.
Gerenciamento de modelos:
Clique em "+ Adicionar" para inserir manualmente o nome dos modelos baixados no Ollama (ex: llama3.2 se baixado via ollama run llama3.2).
Use o botão "Gerenciar" para editar ou remover modelos.
Após a configuração, selecione "Ollama" e seu modelo no painel de chat do Cherry Studio para iniciar conversas com seu LLM local!
Primeira execução do modelo: O download inicial dos arquivos pode demorar significativamente.
Ver modelos disponíveis: Execute ollama list no terminal para listar modelos instalados.
Requisitos de hardware: Verifique se seu computador possui recursos suficientes (CPU/RAM/GPU) para executar LLMs.
Documentação Ollama: Clique em View Ollama Documentation and Models na página de configuração para acessar a documentação oficial.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Na página oficial da Chave API, clique em + Create new secret key
Copie a chave gerada e abra as configurações do fornecedor do CherryStudio
Localize o fornecedor OpenAI e insira a chave obtida
Clique em Gerir ou Adicionar na parte inferior, adicione os modelos suportados e ative o interruptor do fornecedor no canto superior direito para começar a utilizar.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
O Cherry Studio suporta a importação de tópicos para bases de dados do Notion.
Acesse o site Notion Integrations e crie um aplicativo
Crie um aplicativo
Nome: Cherry Studio Tipo: Selecione a primeira opção Ícone: Você pode salvar esta imagem
Copie a chave secreta e cole-a nas configurações do Cherry Studio
Acesse o site do Notion e crie uma nova página. Selecione o tipo de base de dados abaixo, nomeie como Cherry Studio e conecte conforme ilustrado
Se o URL da sua base de dados do Notion for semelhante a:
https://www.notion.so/<long_hash_1>?v=<long_hash_2>
Então o ID da base de dados do Notion é a parte <long_hash_1>
Preencha Nome do campo de título da página:
Se sua interface estiver em inglês, preencha Name
Se sua interface estiver em chinês, preencha 名称
Parabéns! A configuração do Notion está concluída ✅ Agora você pode exportar conteúdo do Cherry Studio para sua base de dados do Notion
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Faça login no Alibaba Cloud Bailian. Se você não tiver uma conta da Alibaba Cloud, será necessário registar-se.
Clique no botão 创建我的 API-KEY no canto superior direito.
Na janela pop-up, selecione o espaço de negócios padrão (ou você pode personalizar) e, se desejar, preencha uma descrição.
Clique no botão 确定 no canto inferior direito.
Em seguida, você deverá ver uma nova linha na lista; clique no botão 查看 à direita.
Clique no botão 复制.
Acesse o Cherry Studio e, em Configurações → Serviços de Modelo → Alibaba Cloud Bailian, encontre API 密钥. Cole a chave API copiada aqui.
Você pode ajustar as configurações relevantes conforme descrito em Serviços de Modelo e em seguida utilizá-lo.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Contato: Sr. Wang 📮:[email protected] 📱:18954281942 (não é número de atendimento ao cliente)
Para consultas de uso, junte-se ao nosso grupo de discussão de usuários no rodapé da página inicial do site oficial ou envie e-mail para [email protected]
Ou envie issues em: https://github.com/CherryHQ/cherry-studio/issues
Se precisar de mais orientações, junte-se ao nosso Planeta do Conhecimento
Detalhes da licença comercial: https://docs.cherry-ai.com/contact-us/questions/cherrystudio-xu-ke-xie-yi
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Faça login e acesse a página de tokens
Crie um novo token (ou use o token "default"↑ diretamente)
Copie o token
Acesse as configurações de provedor do CherryStudio e clique em Adicionar no final da lista de provedores
Insira um nome para referência, selecione "OpenAI" como provedor e clique em OK
Cole a chave copiada anteriormente
Volte à página de obtenção da API Key e copie o endereço raiz da barra de endereços do navegador, por exemplo:
Adicione modelos (clique em "Gerenciar" para busca automática ou insira manualmente). Ative o botão no canto superior direito para começar a usar.
Outros temas do OneAPI podem ter interfaces diferentes, mas o método de adição segue o mesmo fluxo descrito acima.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
MCP (Model Context Protocol) é um protocolo de código aberto projetado para fornecer informações contextuais a modelos de linguagem de grande porte (LLMs) de forma padronizada. Para mais informações sobre o MCP, consulte .
Veja a seguir um exemplo usando a funcionalidade fetch para demonstrar como utilizar o MCP no Cherry Studio. Detalhes podem ser encontrados na documentação.
Em Configurações - Servidor MCP, clique no botão Instalar para iniciar o download e instalação automáticos. Como o download é feito diretamente do GitHub, pode ser lento e ter alta probabilidade de falha. A instalação é considerada bem-sucedida apenas se os arquivos estiverem presentes nas pastas mencionadas abaixo.
Diretório de instalação dos executáveis:
Windows: C:\Users\Nome do Usuário\.cherrystudio\bin
macOS e Linux: ~/.cherrystudio/bin
Se a instalação automática falhar:
Você pode criar links simbólicos a partir dos comandos correspondentes no sistema para este diretório. Se o diretório não existir, crie-o manualmente. Como alternativa, faça o download manual dos executáveis e coloque-os neste diretório:
Bun: https://github.com/oven-sh/bun/releases UV: https://github.com/astral-sh/uv/releases
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Cherry Studio é um cliente de desktop multi-modelo, atualmente compatível com pacotes de instalação para sistemas Windows, Linux e macOS. Ele agrega modelos LLM líderes, oferecendo assistência em diversos cenários. Os usuários podem melhorar sua eficiência através de gerenciamento inteligente de conversas, personalização de código aberto e interface multi-tema.
O Cherry Studio agora possui integração profunda com o canal de API de alto desempenho da PPIO — garantindo capacidade computacional corporativa para resposta ultrarrápida do DeepSeek-R1/V3 e 99,9% de disponibilidade de serviço, proporcionando uma experiência fluida e eficiente.
O tutorial abaixo contém o plano completo de integração (incluindo configuração de chaves), permitindo ativar o modo avançado de "Inteligência de Agendamento do Cherry Studio + API de Alto Desempenho da PPIO" em apenas 3 minutos.
Primeiro, faça o download do Cherry Studio no site oficial: (se não conseguir acessar, utilize o link alternativo do Quark Pan: )
(1) Clique em "Configurações" no canto inferior esquerdo, defina o nome do fornecedor como PPIO e clique em "Confirmar"
(2) Acesse , clique no ícone do usuário → "Gerenciamento de Chaves de API" para entrar no painel de controle
Clique no botão [+ Criar] para gerar uma nova chave de API. Defina um nome para a chave. A chave gerada só será exibida uma vez — copie-a e salve-a para uso futuro
(3) No Cherry Studio, insira a chave: vá para "Configurações", selecione [PPIO PiO Cloud], insira a chave de API gerada no site oficial e clique em [Verificar]
(4) Selecione o modelo: usando deepseek/deepseek-r1/community como exemplo. Se necessário, outros modelos podem ser alternados diretamente.
As versões DeepSeek R1 e V3 community são para testes exploratórios com todos os parâmetros habilitados, sem diferenças em estabilidade ou desempenho. Para uso intensivo, recarregue créditos e alterne para versões não-community.
(1) Após clicar em [Verificar] e confirmar a conexão bem-sucedida, o uso normal está habilitado
(2) Finalmente, clique em [@], selecione o modelo DeepSeek R1 adicionado sob o fornecedor PPIO e inicie a conversa!
[Parte do material fonte: ]
Se preferir aprendizagem visual, preparamos um tutorial em vídeo no Bilibili. Com instruções passo a passo, você dominará rapidamente a configuração "API PPIO + Cherry Studio". Clique no link abaixo para acessar o vídeo e iniciar uma experiência de desenvolvimento fluida →
[Material de vídeo: sola]
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Na versão 0.9.1, o CherryStudio introduziu a tão esperada funcionalidade de Base de Conhecimento.
A seguir, apresentaremos o guia detalhado de utilização do CherryStudio passo a passo.
Busque modelos no serviço de gerenciamento de modelos - é possível filtrar rapidamente clicando em "Modelos de Embedding";
Encontre o modelo desejado e adicione-o aos meus modelos.
Acesso à Base de Conhecimento: Na barra de ferramentas à esquerda do CherryStudio, clique no ícone da Base de Conhecimento para acessar a página de gerenciamento;
Adicionar Base de Conhecimento: Clique em "Adicionar" para começar a criar sua base de conhecimento;
Nomeação: Insira o nome da base de conhecimento e adicione um modelo de embedding, usando bge-m3 como exemplo, para finalizar a criação.
Adicionar arquivos: Clique no botão de adicionar arquivos para abrir a seleção;
Selecionar arquivos: Escolha entre formatos suportados como pdf, docx, pptx, xlsx, txt, md, mdx etc.;
Vetorização: O sistema realizará automaticamente o processo de vetorização. Quando mostrar "Concluído" (verde ✓), significa que a vetorização está completa.
O CherryStudio suporta diversos métodos de adição de dados:
Diretório de pastas: Adicione uma pasta inteira - os arquivos suportados serão vetorizados automaticamente;
URL: Suporta links como ;
Mapa do site: Suporta sitemaps em formato XML como ;
Notas de texto: Permite inserir conteúdo personalizado em texto puro.
Após a vetorização, é possível realizar consultas:
Clique no botão "Pesquisar Base de Conhecimento" no rodapé da página;
Insira o conteúdo da consulta;
Visualize os resultados da pesquisa;
Verifique a pontuação de correspondência para cada resultado.
Crie um novo tópico. Na barra de ferramentas, clique em "Base de Conhecimento" para ver a lista e selecione uma base;
Envie sua pergunta – o modelo retornará respostas geradas a partir dos resultados da pesquisa;
As fontes de dados utilizadas aparecerão abaixo da resposta para acesso rápido.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Para servidores ModelScope MCP, é necessário atualizar o Cherry Studio para a versão v1.2.9 ou superior.
Na versão v1.2.9, o Cherry Studio estabeleceu uma parceria oficial com o ModelScope (魔搭), simplificando significativamente as etapas de adição de servidores MCP. Essa integração evita erros de configuração e permite descobrir inúmeros servidores MCP na comunidade ModelScope. Acompanhe as etapas abaixo para aprender como sincronizar servidores MCP do ModelScope no Cherry Studio.
Clique em "Configurações de servidores MCP" e selecione Sincronizar servidores
Selecione "ModelScope" e explore os serviços MCP disponíveis
Faça login no ModelScope e visualize os detalhes do serviço MCP
Na página de detalhes do serviço MCP, selecione "Conectar serviço"
Clique em "Obter token de API" no Cherry Studio para acessar o site do ModelScope. Copie o token de API e cole-o no Cherry Studio.
Na lista de servidores MCP do Cherry Studio, o serviço conectado do ModelScope estará disponível para uso em conversas.
Para novos servidores MCP conectados posteriormente no site do ModelScope, bastará clicar em Sincronizar servidores para adicioná-los incrementalmente.
Com estas etapas, você dominou o processo de sincronização simplificada dos servidores MCP do ModelScope no Cherry Studio. Essa configuração elimina a complexidade e erros potenciais de configuração manual, permitindo o acesso a recursos abundantes da comunidade ModelScope.
Comece a explorar e utilizar esses poderosos serviços MCP para potencializar sua experiência com o Cherry Studio, abrindo novas possibilidades e conveniências!
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Você já passou por isso: salvou 26 artigos cheios de conteúdo no WeChat e nunca mais os abriu, tem mais de 10 arquivos espalhados na pasta "Material de estudo" do computador, e quando tenta encontrar uma teoria que leu há meio ano só se lembra de algumas palavras-chave? Quando o volume diário de informações excede o limite do cérebro, 90% do conhecimento valioso é esquecido em 72 horas. Agora, com a API da plataforma de serviço de modelos de grande escala Infini-AI + Cherry Studio, você pode criar uma base de conhecimento pessoal que transforma artigos do WeChat acumulando poeira e conteúdos fragmentados de cursos em conhecimento estruturado, permitindo acesso preciso.
1.1 Serviço de API Infini-AI: "Cérebro" da base de conhecimento, estável e fácil de usar
Como o "cérebro" da base de conhecimento, a plataforma Infini-AI oferece versões como o DeepSeek R1 Full Edition, provendo serviços de API estáveis. Atualmente, após cadastro, o uso é gratuito e sem barreiras. Suporta modelos de incorporação (embedding) mainstream como bge e jina para construir bases de conhecimento. A plataforma atualiza constantemente os serviços de modelos open-source mais recentes e poderosos, incluindo múltiplas modalidades como imagem, vídeo e áudio.
1.2 Cherry Studio: Construa sua base de conhecimento sem código
Cherry Studio é uma ferramenta de IA intuitiva. Comparado ao desenvolvimento tradicional de bases de conhecimento RAG (que leva 1-2 meses), esta ferramenta oferece operação sem código, importando com um clique formatos como Markdown/PDF/páginas web. Arquivos de 40MB são processados em 1 minuto. Além disso, permite adicionar pastas locais, artigos favoritados do WeChat e anotações de cursos.
Passo 1: Preparação Básica
Acesse o site oficial do Cherry Studio para baixar a versão compatível (https://cherry-ai.com/)
Cadastre-se: Entre na plataforma Infini-AI (https://cloud.infini-ai.com/genstudio/model?cherrystudio)
Obtenha a chave da API: Na "Praça de Modelos", selecione deepseek-r1, clique em criar e copie o nome do modelo
Passo 2: Nas configurações do Cherry Studio, selecione "Infini-AI" nos serviços de modelo, insira a chave da API e ative o serviço
Após concluir, selecione o modelo necessário durante interações para usar os serviços da API Infini-AI no Cherry Studio. Para facilitar, defina também um "modelo padrão".
Passo 3: Adicione a base de conhecimento
Selecione qualquer versão dos modelos de incorporação bge ou jina da plataforma Infini-AI
Após importar materiais de estudo, insira: "Organize a derivação das fórmulas-chave do Capítulo 3 de 'Machine Learning'"
Resultado gerado (imagem anexa)
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Preservação de formatação: Mantive o símbolo de cabeçalho # sem alteração conforme as regras.
Tradução textual: "免费" → "Gratuita" (sem custo) "联网" → "Internet" (acesso à rede) "模式" → "Modo" (funcionalidade/operação)
Naturalidade: "Modo de Internet Gratuita" é a expressão mais comum em português para descrever funcionalidade de acesso gratuito à internet.
# Modo de Internet Gratuita



















































Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Junte-se ao grupo de discussão do Telegram para obter ajuda: https://t.me/CherryStudioAI
Issues do GitHub: https://github.com/CherryHQ/cherry-studio/issues/new/choose
E-mail do desenvolvedor: [email protected]
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Cherry Studio é um projeto gratuito e de código aberto. À medida que o projeto cresce, a carga de trabalho da equipe também aumenta. Para reduzir custos de comunicação e resolver suas dúvidas de forma rápida e eficiente, pedimos que antes de fazer perguntas, siga estas etapas. Isso permitirá que a equipe dedique mais tempo à manutenção e desenvolvimento do projeto. Agradecemos sua cooperação!
A maioria das questões básicas pode ser resolvida consultando a documentação com atenção:
Dúvidas sobre funcionalidades e uso do software podem ser encontradas na documentação de Funcionalidades;
Perguntas frequentes estão compiladas na página FAQ - verifique primeiro se há soluções lá;
Questões complexas podem ser resolvidas diretamente através da pesquisa ou usando a caixa de pesquisa;
Leia atentamente os conteúdos dos quadros de aviso em cada documento - isso ajuda a evitar muitos problemas;
Consulte ou pesquise problemas semelhantes e soluções na página de Issues do GitHub.
Para questões não relacionadas à funcionalidade do cliente (como erros de modelo, respostas inesperadas, configuração de parâmetros), recomendamos:
Pesquisar soluções relacionadas na internet primeiro;
Descrever o erro e o problema para uma IA para buscar soluções.
Se as etapas 1 e 2 não resolverem seu problema, você pode:
Descrever detalhadamente o problema ao buscar ajuda.
Orientações específicas:
Para erros de modelo:
Forneça captura de tela completa da interface e informações de erro do console.
Informações sensíveis podem ser ocultadas, mas mantenha no print: nome do modelo, parâmetros e conteúdo do erro.
Método para ver erros do console: clique aqui.
Para bugs de software:
Descreva o erro concretamente e forneça etapas detalhadas de .
Se for intermitente, descreva o cenário, contexto e parâmetros relevantes.
Inclua plataforma (Windows/Mac/Linux) e versão do software na descrição.
Solicitar documentação ou sugerir melhorias
Contate @Wangmouuu no Telegram, QQ (1355873789) ou email: [email protected].
{% hint style="danger" %}
Atenção: A geração de imagens do Gemini precisa ser usada na interface de conversa, pois o Gemini é uma geração de imagens interativa multimodal e não suporta ajustes de parâmetros.
{% endhint %}

数据设置→Obsidian配置
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Cherry Studio suporta integração com o Obsidian para exportar conversas completas ou individuais para a sua biblioteca do Obsidian.
Este processo não requer instalação de plugins adicionais do Obsidian. No entanto, como o mecanismo de importação do Cherry Studio é semelhante ao Obsidian Web Clipper, recomenda-se atualizar o Obsidian para a versão mais recente (atual versão mínima: 1.7.2) para evitar falhas na importação de conversas extensas.
Abra Configurações → Configurações de Dados → Menu Configuração do Obsidian no Cherry Studio. Os nomes das bibliotecas do Obsidian abertas localmente aparecerão automaticamente na lista suspensa. Selecione sua biblioteca alvo:
Exportar Conversa Completa
Retorne à interface de conversa do Cherry Studio. Clique com o botão direito na conversa, selecione Exportar e clique em Exportar para Obsidian:
Uma janela será aberta para ajustar as Propriedades da nota, o local da pasta no Obsidian e o método de processamento:
Biblioteca: Selecione outra biblioteca do menu suspenso
Caminho: Selecione a pasta de destino para a nota exportada
Propriedades da nota do Obsidian:
Tags
Data de criação (created)
Origem (source)
Métodos de processamento disponíveis:
Novo (substituir se existir): Cria uma nova nota na pasta especificada, substituindo notas existentes com mesmo nome
Prepend: Adiciona o conteúdo ao início de uma nota existente com mesmo nome
Anexar: Adiciona o conteúdo ao final de uma nota existente com mesmo nome
Após selecionar todas as opções, clique em OK para exportar a conversa completa.
Exportar Mensagem Individual
Clique no menu de três linhas abaixo da mensagem, selecione Exportar e clique em Exportar para Obsidian:
A mesma janela de configuração de propriedades e métodos de processamento será exibida. Siga os mesmos passos do tutorial acima.
🎉 Parabéns! Você concluiu toda a configuração de integração do Cherry Studio com o Obsidian. Aproveite!
Abra sua biblioteca do Obsidian e crie uma pasta para salvar as conversas exportadas (exemplo: pasta "Cherry Studio"):
Anote o nome da Biblioteca destacado no canto inferior esquerdo.
Em Configurações → Configurações de Dados → Menu Configuração do Obsidian do Cherry Studio, insira o nome da Biblioteca e da Pasta obtidos no Passo 1:
O campo Tags globais é opcional para definir tags padrão em todas as notas exportadas.
Exportar Conversa Completa
Clique com o botão direito na conversa, selecione Exportar e clique em Exportar para Obsidian:
Configure as Propriedades da nota e escolha um método de processamento:
Novo (substituir se existir)
Prepend
Anexar
Exportar Mensagem Individual
Clique no menu de três linhas abaixo da mensagem e selecione Exportar para Obsidian:
Siga os mesmos passos do tutorial acima.
🎉 Parabéns! Você concluiu toda a configuração de integração. Aproveite!
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
O armazenamento de dados do Cherry Studio segue as normas do sistema, onde os dados são automaticamente salvos no diretório do usuário, conforme as seguintes localizações:
macOS: /Users/username/Library/Application Support/CherryStudioDev Windows: C:\Users\username\AppData\Roaming\CherryStudio Linux: /home/username/.config/CherryStudio
Esta localização também pode ser verificada em:
Método 1: Você pode criar um link simbólico. Saia do aplicativo, mova os dados para o local desejado e crie um link no local original apontando para o novo diretório.
Instruções detalhadas: https://github.com/CherryHQ/cherry-studio/issues/621#issuecomment-2588652880
Método 2: Aproveitando características do Electron, configure parâmetros de inicialização para alterar o diretório de armazenamento.
--user-data-dir Exemplo: Cherry-Studio-*-x64-portable.exe --user-data-dir="%user_data_dir%"
Demonstração:
PS D:\CherryStudio> dir
Diretório: D:\CherryStudio
Modo ÚltimaEscrita Comprimento Nome
---- ------------- ------ ----
d----- 2025/4/18 14:05 user-data-dir
-a---- 2025/4/14 23:05 94987175 Cherry-Studio-1.2.4-x64-portable.exe
-a---- 2025/4/18 14:05 701 init_cherry_studio.batinit_cherry_studio.bat (codificação: ANSI)
@title Inicializar CherryStudio
@echo off
set current_path_dir=%~dp0
@echo Diretório atual: %current_path_dir%
set user_data_dir=%current_path_dir%user-data-dir
@echo Diretório de dados: %user_data_dir%
@echo Procurando executável Cherry-Studio-*-portable.exe
setlocal enabledelayedexpansion
for /f "delims=" %%F in ('dir /b /a-d "Cherry-Studio-*-portable*.exe" 2^>nul') do ( # Adaptado para versões do GitHub e site oficial
set "target_file=!cd!\%%F"
goto :break
)
:break
if defined target_file (
echo Arquivo encontrado: %target_file%
) else (
echo Nenhum arquivo compatível encontrado
pause
exit
)
@echo Pressione qualquer tecla para continuar
pause
@echo Iniciando CherryStudio
start %target_file% --user-data-dir="%user_data_dir%"
@echo Processo concluído
@echo on
exitEstrutura do diretório user-data-dir após inicialização:
PS D:\CherryStudio> dir .\user-data-dir\
Diretório: D:\CherryStudio\user-data-dir
Modo ÚltimaEscrita Comprimento Nome
---- ------------- ------ ----
d----- 2025/4/18 14:29 blob_storage
d----- 2025/4/18 14:07 Cache
d----- 2025/4/18 14:07 Code Cache
d----- 2025/4/18 14:07 Data
d----- 2025/4/18 14:07 DawnGraphiteCache
d----- 2025/4/18 14:07 DawnWebGPUCache
d----- 2025/4/18 14:07 Dictionaries
d----- 2025/4/18 14:07 GPUCache
d----- 2025/4/18 14:07 IndexedDB
d----- 2025/4/18 14:07 Local Storage
d----- 2025/4/18 14:07 logs
d----- 2025/4/18 14:30 Network
d----- 2025/4/18 14:07 Partitions
d----- 2025/4/18 14:29 Session Storage
d----- 2025/4/18 14:07 Shared Dictionary
d----- 2025/4/18 14:07 WebStorage
-a---- 2025/4/18 14:07 36 .updaterId
-a---- 2025/4/18 14:29 20 config.json
-a---- 2025/4/18 14:07 434 Local State
-a---- 2025/4/18 14:29 57 Preferences
-a---- 2025/4/18 14:09 4096 SharedStorage
-a---- 2025/4/18 14:30 140 window-state.json如何注册tavily?
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Acesse o site oficial acima ou vá para Cherry Studio > Configurações > Busca na Web > Clique em "Obter chave" para ser redirecionado diretamente para a página de login/registro do Tavily.
Se for a primeira vez usando, você precisa registrar uma conta (Sign up) antes de fazer login (Log in). O redirecionamento padrão é para a página de login.
Clique em "Registrar conta", insira seu e-mail principal ou use uma conta Google/GitHub. Em seguida, prossiga para criar sua senha (etapas comuns).
🚨🚨🚨【ETAPA CRUCIAL】** Após o registro bem-sucedido, haverá uma verificação decódigo dinâmico. Você precisará escanear um QR code para gerar um código único (Code) e continuar.
Temos duas soluções simples:
Baixe o aplicativo de autenticação da Microsoft – Authenticator [um pouco complicado]
Use o miniprograma do WeChat: 腾讯身份验证器 (Verificador de Identidade Tencent) [simples e recomendado]
Abra o WeChat, pesquise pelo miniprograma: 腾讯身份验证器
Após essas etapas, você verá esta tela confirmando o registro. Copie a chave para o Cherry Studio e comece a usar.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
A instalação automática do MCP requer a atualização do Cherry Studio para a versão v1.1.18 ou superior.
Além da instalação manual, o Cherry Studio possui integrado a ferramenta @mcpmarket/mcp-auto-install, uma forma mais conveniente de instalar servidores MCP. Basta inserir o comando correspondente em uma conversa de modelo grande que suporte o serviço MCP.
Lembrete da fase de teste:
@mcpmarket/mcp-auto-install ainda está na fase de testes
O desempenho depende da "inteligência" do modelo grande: algumas instalações serão automáticas, enquanto outras exigirão ajustes manuais de parâmetros nas configurações do MCP
Atualmente, a fonte de pesquisa é @modelcontextprotocol, podendo ser personalizada (explicado abaixo)
Por exemplo, você pode inserir:
O sistema identificará automaticamente sua solicitação e completará a instalação através do @mcpmarket/mcp-auto-install. Essa ferramenta suporta diversos tipos de servidores MCP, incluindo mas não limitados a:
filesystem (sistema de arquivos)
fetch (requisição de rede)
sqlite (banco de dados)
etc.
A variável MCP_PACKAGE_SCOPES permite personalizar a fonte de pesquisa de serviços MCP, com valor padrão:
@modelcontextprotocol.
@mcpmarket/mcp-auto-installEste documento foi traduzido do chinês por IA e ainda não foi revisado.
... (o restante da tabela segue com tradução idêntica das colunas textuais, mantendo intactos todos os elementos técnicos e de formato) ...
Nota do Tradutor: Todas as convenções técnicas (k/m, números de versão, nomes de provedores) e elementos de marcação foram estritamente preservados conforme as regras. Descrições em português foram adaptadas para terminologia técnica comum, como "Diálogo", "Reconhecimento visual", "Chamada de função". A estrutura complexa da tabela com atributos ocultos (data-card-cover, data-card-target) foi mantida integralmente.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
O Cherry Studio suporta duas formas de configurar a lista negra: manualmente e através da adição de fontes de assinatura. As regras de configuração seguem a referência do .
Você pode adicionar regras aos resultados de pesquisa ou clicar no ícone da barra de ferramentas para bloquear sites específicos. As regras podem ser especificadas através de:
(exemplo: *://*.example.com/*)
(exemplo: /example\.(net|org)/).
Você também pode assinar conjuntos de regras públicos. Este site lista algumas assinaturas: https://iorate.github.io/ublacklist/subscriptions
Abaixo estão algumas fontes de assinatura recomendadas:
360gpt-pro
8k
-
Não suporta
Diálogo
360AI_360gpt
Principal modelo de bilhões de parâmetros da série 360 Brain, amplamente aplicável em cenários complexos em diversos campos.
360gpt-turbo
7k
-
Não suporta
Diálogo
360AI_360gpt
Modelo de bilhões de parâmetros que equilibra desempenho e custo, ideal para cenários com requisitos de desempenho/custo elevados.
360gpt-turbo-responsibility-8k
8k
-
Não suporta
Diálogo
360AI_360gpt
Modelo de bilhões de parâmetros que equilibra desempenho e custo, ideal para cenários com requisitos de desempenho/custo elevados.
glm-4v-flash
2k
1k
Não suporta
Diálogo, Reconhecimento visual
智谱_glm
Modelo gratuito: possui recursos avançados de compreensão de imagens
帮我安装一个 filesystem mcp server// `axun-uUpaWEdMEMU8C61K` é o ID do serviço, pode ser personalizado
"axun-uUpaWEdMEMU8C61K": {
"name": "mcp-auto-install",
"description": "Automatically install MCP services (Beta version)",
"isActive": false,
"registryUrl": "https://registry.npmmirror.com",
"command": "npx",
"args": [
"-y",
"@mcpmarket/mcp-auto-install",
"connect",
"--json"
],
"env": {
"MCP_REGISTRY_PATH": "Detalhes em https://www.npmjs.com/package/@mcpmarket/mcp-auto-install"
},
"disabledTools": []
}

https://git.io/ublacklist
Chinês
https://raw.githubusercontent.com/laylavish/uBlockOrigin-HUGE-AI-Blocklist/main/list_uBlacklist.txt
Gerado por IA














Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Tokens são as unidades básicas de processamento de texto em modelos de IA, podendo ser entendidos como as menores unidades de "pensamento" do modelo. Eles não correspondem exatamente a caracteres ou palavras como as entendemos, mas sim a um método especial de segmentação de texto usado pelo próprio modelo.
1. Segmentação de Texto em Chinês
Um caractere chinês geralmente é codificado como 1-2 tokens
Exemplo: "你好" ≈ 2-4 tokens
2. Segmentação de Texto em Inglês
Palavras comuns geralmente são 1 token
Palavras longas ou incomuns são divididas em múltiplos tokens
Exemplo:
"hello" = 1 token
"indescribable" = 4 tokens
3. Caracteres Especiais
Espaços, pontuação e outros também ocupam tokens
Caracteres de nova linha geralmente são 1 token
Tokenizer (segmentador) é a ferramenta que converte texto em tokens para modelos de IA. Ele determina como o texto de entrada é dividido nas menores unidades compreensíveis pelo modelo.
1. Dados de Treinamento Diferentes
Corpus linguísticos distintos levam a diferentes otimizações
Variações no suporte a múltiplos idiomas
Otimizações especializadas para áreas específicas (saúde, direito, etc.)
2. Algoritmos de Segmentação Diferentes
BPE (Byte Pair Encoding) - OpenAI GPT series
WordPiece - Google BERT
SentencePiece - Ideal para cenários multilíngues
3. Objetivos de Otimização Diferentes
Alguns focam em eficiência de compressão
Outros em preservação semântica
Outros em velocidade de processamento
O mesmo texto pode ter contagens diferentes de tokens em modelos distintos:
Entrada: "Hello, world!"
GPT-3: 4 tokens
BERT: 3 tokens
Claude: 3 tokensConceito Básico: Modelos de incorporação são técnicas que convertem dados discretos de alta dimensão (texto, imagens, etc.) em vetores contínuos de baixa dimensão, permitindo que máquinas compreendam e processem melhor informações complexas. Imagine como simplificar um quebra-cabeça complexo em um ponto coordenado que ainda mantém características essenciais. No ecossistema de grandes modelos, atuam como "tradutores" convertendo informações humanas em formas numéricas computáveis.
Funcionamento: No processamento de linguagem natural, modelos de incorporação mapeiam palavras para posições específicas em espaços vetoriais. Nesse espaço, palavras semanticamente relacionadas agrupam-se naturalmente. Por exemplo:
"Rei" e "rainha" terão vetores próximos
"Gato" e "cachorro" como animais domésticos estarão próximos
"Carro" e "pão", semanticamente não relacionados, ficarão distantes
Principais Casos de Uso:
Análise de texto: classificação de documentos, análise de sentimentos
Sistemas de recomendação: sugestão de conteúdo personalizado
Processamento de imagens: busca por imagens semelhantes
Motores de busca: otimização de pesquisa semântica
Vantagens-Chave:
Redução dimensional: simplifica dados complexos para formas vetoriais tratáveis
Preservação semântica: mantém informações semânticas cruciais dos dados originais
Eficiência computacional: acelera significativamente treinamento e inferência de modelos
Valor Tecnológico: Modelos de incorporação são componentes fundamentais de sistemas modernos de IA, fornecendo representações de alta qualidade para tarefas de aprendizado de máquina e são essenciais para avanços em processamento de linguagem natural, visão computacional e áreas afins.
Fluxo de Trabalho Básico:
Fase de Pré-processamento do Banco de Conhecimento
Divisão de documentos em chunks (segmentos de texto) de tamanho apropriado
Conversão de cada chunk em vetor usando o modelo embedding
Armazenamento de vetores e texto original em banco de dados vetorial
Fase de Processamento de Consultas
Conversão da pergunta do usuário em vetor
Busca por conteúdo similar no banco vetorial
Fornecimento do conteúdo recuperado como contexto para o LLM
MCP é um protocolo open-source que fornece informações contextuais a modelos de linguagem (LLM) de forma padronizada.
Analogia: Imagine MCP como um "pen drive" para IA. Assim como pen drives armazenam vários arquivos que ficam acessíveis ao conectar no computador, servidores MCP aceitam "plugins" contextuais diversos. LLMs podem solicitar esses plugins conforme necessário, obtendo informações contextuais ricas para expandir suas capacidades.
Comparação com Function Tools: Ferramentas funcionais tradicionais também ampliam capacidades de LLMs, mas MCP opera em abstração mais elevada. Enquanto Function Tools focam em tarefas específicas, MCP oferece um mecanismo modular e universal de obtenção de contexto.
Padronização: Interface e formato de dados unificados permitem colaboração direta entre diferentes LLMs e provedores de contexto.
Modularidade: Contexto pode ser dividido em módulos (plugins) independentes para fácil gerenciamento e reuso.
Flexibilidade: LLMs selecionam plugins contextuais dinamicamente conforme necessidades, viabilizando interações mais inteligentes e personalizadas.
Escalabilidade: Arquitetura do MCP suporta futuras inclusões de tipos contextuais adicionais, oferecendo possibilidades ilimitadas para expansão de capacidades de LLMs.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Você pode alterar a aparência do software para se adequar melhor às suas preferências personalizando o CSS. Por exemplo:
:root {
--color-background: #1a462788;
--color-background-soft: #1a4627aa;
--color-background-mute: #1a462766;
--navbar-background: #1a4627;
--chat-background: #1a4627;
--chat-background-user: #28b561;
--chat-background-assistant: #1a462722;
}
#content-container {
background-color: #2e5d3a !important;
}:root {
font-family: "汉仪唐美人" !important; /* Fonte */
}
/* Cor da fonte expandida em reflexão profunda */
.ant-collapse-content-box .markdown {
color: red;
}
/* Variáveis de tema */
:root {
--color-black-soft: #2a2b2a; /* Cor de fundo escura */
--color-white-soft: #f8f7f2; /* Cor de fundo clara */
}
/* Tema escuro */
body[theme-mode="dark"] {
/* Cores */
--color-background: #2b2b2b; /* Cor de fundo escura */
--color-background-soft: #303030; /* Cor de fundo clara */
--color-background-mute: #282c34; /* Cor de fundo neutra */
--navbar-background: var(-–color-black-soft); /* Cor de fundo da barra de navegação */
--chat-background: var(–-color-black-soft); /* Cor de fundo do chat */
--chat-background-user: #323332; /* Cor de fundo do chat do usuário */
--chat-background-assistant: #2d2e2d; /* Cor de fundo do chat do assistente */
}
/* Estilos específicos para tema escuro */
body[theme-mode="dark"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* Cor de fundo do container de conteúdo */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* Cor de fundo das mensagens */
}
.inputbar-container {
background-color: #3d3d3a; /* Cor de fundo da barra de entrada */
border: 1px solid #5e5d5940; /* Cor da borda da barra de entrada */
border-radius: 8px; /* Raio da borda da barra de entrada */
}
/* Estilos de código */
code {
background-color: #e5e5e20d; /* Cor de fundo do código */
color: #ea928a; /* Cor do texto do código */
}
pre code {
color: #abb2bf; /* Cor do texto de código pré-formatado */
}
}
/* Tema claro */
body[theme-mode="light"] {
/* Cores */
--color-white: #ffffff; /* Branco */
--color-background: #ebe8e2; /* Cor de fundo clara */
--color-background-soft: #cbc7be; /* Cor de fundo clara */
--color-background-mute: #e4e1d7; /* Cor de fundo neutra */
--navbar-background: var(-–color-white-soft); /* Cor de fundo da barra de navegação */
--chat-background: var(-–color-white-soft); /* Cor de fundo do chat */
--chat-background-user: #f8f7f2; /* Cor de fundo do chat do usuário */
--chat-background-assistant: #f6f4ec; /* Cor de fundo do chat do assistente */
}
/* Estilos específicos para tema claro */
body[theme-mode="light"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* Cor de fundo do container de conteúdo */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* Cor de fundo das mensagens */
}
.inputbar-container {
background-color: #ffffff; /* Cor de fundo da barra de entrada */
border: 1px solid #87867f40; /* Cor da borda da barra de entrada */
border-radius: 8px; /* Raio da borda da barra de entrada (ajuste conforme preferência) */
}
/* Estilos de código */
code {
background-color: #3d39290d; /* Cor de fundo do código */
color: #7c1b13; /* Cor do texto do código */
}
pre code {
color: #000000; /* Cor do texto de código pré-formatado */
}
}Consulte o código-fonte para mais variáveis de tema: https://github.com/CherryHQ/cherry-studio/tree/main/src/renderer/src/assets/styles
Biblioteca de temas do Cherry Studio: https://github.com/boilcy/cherrycss
Compartilhando skins de tema estilo chinês para Cherry Studio: https://linux.do/t/topic/325119/129
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
O Cherry Studio não apenas integra os principais serviços de modelos de IA, mas também oferece poderosas capacidades de personalização. Com o recurso Provedores Personalizados de IA, você pode integrar facilmente qualquer modelo de IA que necessitar.
Flexibilidade: Liberte-se das limitações da lista pré-definida de provedores e escolha livremente os modelos de IA mais adequados às suas necessidades.
Diversidade: Experimente modelos de IA de várias plataformas para explorar seus pontos fortes exclusivos.
Controle: Gerencie diretamente suas chaves de API e endereços de acesso, garantindo segurança e privacidade.
Personalização: Integre modelos implantados de forma privada para atender a cenários comerciais específicos.
Siga estes passos simples para adicionar seu provedor personalizado no Cherry Studio:
Abra as Configurações: Na barra de navegação esquerda do Cherry Studio, clique em "Configurações" (ícone de engrenagem).
Acesse Serviços de Modelos: Na página de configurações, selecione a aba "Serviços de Modelos".
Adicione Provedor: Na página "Serviços de Modelos", você verá a lista de provedores existentes. Clique no botão "+ Adicionar" abaixo da lista para abrir o pop-up "Adicionar Provedor".
Preencha as Informações: No pop-up, preencha:
Nome do Provedor: Dê um nome identificável (ex: MyCustomOpenAI).
Tipo de Provedor: Selecione na lista suspensa. Atualmente suportado:
OpenAI
Gemini
Anthropic
Azure OpenAI
Salve a Configuração: Após preencher, clique em "Adicionar" para salvar.
Após adicionar, encontre seu provedor na lista e configure:
Status de Ativação: O interruptor à direita da lista ativa/desativa o serviço.
Chave da API:
Insira sua chave de API (API Key) fornecida pelo provedor.
Clique em "Verificar" à direita para validar a chave.
Endereço da API:
Insira o endereço de acesso da API (Base URL).
Consulte a documentação oficial do provedor para obter o endereço correto.
Gerenciamento de Modelos:
Clique em "+ Adicionar" para incluir manualmente os IDs dos modelos que deseja usar (ex: gpt-3.5-turbo, gemini-pro).
* Consulte a documentação oficial se não souber os nomes exatos. * Clique em "Gerenciar" para editar ou excluir modelos adicionados.
Após a configuração, selecione seu provedor e modelo no chat do Cherry Studio para iniciar conversas com a IA!
O vLLM é uma biblioteca de inferência de LLM rápida e fácil de usar, similar ao Ollama. Siga estes passos para integrá-lo ao Cherry Studio:
Instale o vLLM: Siga o guia oficial (https://docs.vllm.ai/en/latest/getting_started/quickstart.html).
pip install vllm # Se usar pip
uv pip install vllm # Se usar uvInicie o Serviço vLLM: Use a interface compatível com OpenAI:
Via vllm.entrypoints.openai.api_server:
python -m vllm.entrypoints.openai.api_server --model gpt2Via uvicorn:
vllm --model gpt2 --served-model-name gpt2O serviço rodará na porta padrão 8000. Use --port para especificar outra porta.
Adicione o vLLM no Cherry Studio:
Siga os passos anteriores para adicionar novo provedor.
Nome do Provedor: vLLM
Tipo de Provedor: Selecione OpenAI.
Configure o vLLM:
Chave da API: Deixe em branco ou insira qualquer conteúdo (vLLM não requer chave).
Endereço da API: Insira o endereço do vLLM (padrão: http://localhost:8000/).
Gerenciamento de Modelos: Adicione o nome do modelo carregado (ex: gpt2 para o exemplo acima).
Inicie as Conversas: Selecione o provedor vLLM e o modelo (ex: gpt2) para conversar com o LLM via vLLM!
Leia a Documentação: Antes de adicionar provedores, consulte a documentação oficial sobre chaves de API, endereços e nomes de modelos.
Verifique as Chaves: Use o botão "Verificar" para validar chaves rapidamente.
Endereços Precisos: Diferentes provedores e modelos podem ter endereços distintos.
Modelos Necessários: Adicione apenas modelos que realmente utilizará para evitar excessos.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
O MCP de Repositório de Conhecimento do Dify requer a atualização do Cherry Studio para v1.2.9 ou superior.
Abra 搜索MCP.
Adicione o servidor dify-knowledge.
Requer configuração de parâmetros e variáveis de ambiente
A chave do Repositório de Conhecimento do Dify pode ser obtida da seguinte forma







Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Ao utilizar ou distribuir qualquer parte ou elemento dos materiais do Cherry Studio, você será considerado como tendo reconhecido e aceito o conteúdo deste acordo, que entra em vigor imediatamente.
Este Acordo de Licença do Cherry Studio (doravante "Acordo") refere-se aos termos e condições definidos neste documento, relativos ao uso, cópia, distribuição e modificação dos materiais.
"Nós" (ou "nosso") refere-se a 上海千彗科技有限公司.
"Você" (ou "seu") refere-se ao indivíduo ou entidade legal que exerce os direitos concedidos por este acordo e/ou utiliza os materiais para qualquer propósito e em qualquer área de aplicação.
"Terceiro" refere-se a qualquer indivíduo ou entidade legal sem relação de controle comum conosco ou com você.
"Cherry Studio" refere-se a este pacote de software, incluindo mas não limitado a [por exemplo: biblioteca principal, editor, plugins, projetos de exemplo], bem como código fonte, documentação, códigos de exemplo e outros elementos distribuídos por nós. (Descrição detalhada conforme a composição real do CherryStudio)
"Materiais" refere-se coletivamente ao Cherry Studio proprietário e documentação (e quaisquer partes destes) da 上海千彗科技有限公司, fornecidos sob este acordo.
"Formato de origem" significa o formato preferido para modificações, incluindo mas não limitado a código-fonte, arquivos-fonte de documentação e arquivos de configuração.
"Formato de destino" significa qualquer formato resultante de conversão mecânica ou tradução do formato de origem, incluindo mas não limitado a código objeto compilado, documentação gerada e formatos convertidos para outros tipos de mídia.
"Uso comercial" refere-se a propósitos de benefício ou vantagem comercial direta ou indireta, incluindo mas não limitado a vendas, licenciamento, assinaturas, publicidade, marketing, treinamento, consultoria, etc.
"Modificação" significa qualquer alteração, ajuste, derivação ou desenvolvimento secundário do formato de origem dos materiais, incluindo mas não limitado a modificações de nome do aplicativo, logotipo, código, funcionalidades, interface, etc.
Uso comercial gratuito (limitado a código não modificado): Concedemos a você uma licença não exclusiva, global, não transferível e livre de royalties para usar, copiar, distribuir e compartilhar materiais não modificados, inclusive para uso comercial, sujeita aos termos e condições deste acordo, baseada nos direitos de propriedade intelectual ou outros direitos que detemos sobre os materiais.
Autorização comercial (quando necessário): Ao atender às condições descritas no Artigo III "Autorização Comercial", você deverá obter autorização comercial por escrito explícita de nós para exercer os direitos sob este acordo.
Você deverá entrar em contato conosco e obter autorização comercial por escrita explícita antes de continuar usando os materiais do Cherry Studio em qualquer uma das seguintes situações:
Modificações e derivados: Se você modificar os materiais do Cherry Studio ou desenvolver trabalhos derivados (incluindo mas não limitado a modificações de nome do aplicativo, logotipo, código, funcionalidades, interface, etc.).
Serviços corporativos: Se você fornecer serviços baseados no Cherry Studio dentro de sua organização ou para clientes corporativos, com suporte para 10 ou mais usuários acumulados.
Venda em conjunto com hardware: Se você pré-instalar ou integrar o Cherry Studio em dispositivos ou produtos de hardware para venda em conjunto.
Aquisições em larga escala por instituições governamentais ou educacionais: Se o seu cenário de uso envolver projetos de aquisição em larga escala por governos ou instituições educacionais, especialmente com requisitos sensíveis de segurança ou privacidade de dados.
Serviços de nuvem públicos: Se você fornecer serviços de nuvem públicos baseados no Cherry Studio.
Você pode distribuir cópias não modificadas dos materiais ou fornecê-los como parte de produtos ou serviços que contenham materiais não modificados, em formato de origem ou destino, desde que cumpra as seguintes condições:
Você deve fornecer uma cópia deste Acordo a qualquer outro destinatário dos materiais;
Você deve manter em todas as cópias dos materiais distribuídos a seguinte declaração de atribuição, colocada em um arquivo "NOTICE" ou texto similar distribuído como parte dessas cópias:
"Cherry Studio é licenciado sob o CHERRY STUDIO LICENSE AGREEMENT, Copyright (c) 上海千彗科技有限公司. Todos os direitos reservados."
Os materiais podem estar sujeitos a controles ou restrições de exportação. Você deve cumprir as leis e regulamentos aplicáveis ao usar os materiais.
Se você usar os materiais ou quaisquer resultados derivados para criar, treinar, ajustar ou melhorar software ou modelos que serão distribuídos ou fornecidos, encorajamos você a destacar claramente nos documentos relevantes do produto as expressões "Built with Cherry Studio" ou "Powered by Cherry Studio".
Reservamos todos os direitos de propriedade intelectual sobre os materiais e obras derivadas produzidas por nós ou para nós. Sob os termos e condições deste acordo, a titularidade da propriedade intelectual sobre modificações e obras derivadas que você criar será definida por acordo de licença comercial específico. Sem autorização comercial, você não terá direitos de propriedade sobre modificações ou obras derivadas, permanecendo a propriedade intelectual conosco.
Nenhuma licença de marca é concedida para usar nossas marcas registradas, marcas comerciais, logotipos ou nomes de produtos, exceto quando necessário para cumprir obrigações de notificação deste acordo ou para uso razoável e habitual na descrição e redistribuição dos materiais.
Se você mover ação judicial ou qualquer outro processo legal (incluindo reconvenções ou contra-requerimentos) contra nós ou qualquer entidade, alegando que os materiais ou quaisquer resultados derivados, ou partes destes, infringem qualquer direito de propriedade intelectual ou outro direito seu, todas as licenças concedidas sob este acordo serão encerradas a partir da data de início ou apresentação de tal ação ou processo legal.
Não temos obrigação de dar suporte, atualizar, fornecer treinamento ou desenvolver versões posteriores dos materiais do Cherry Studio, nem de conceder quaisquer licenças relacionadas.
Os materiais são fornecidos "COMO ESTÃO", sem garantias expressas ou implícitas, incluindo garantias de comercialização, não violação ou adequação a propósito específico. Não fazemos garantias e não assumimos responsabilidade pela segurança ou estabilidade dos materiais ou quaisquer resultados derivados.
Em nenhuma circunstância seremos responsáveis por quaisquer danos decorrentes do uso ou incapacidade de uso dos materiais ou resultados derivados, incluindo mas não limitado a danos diretos, indiretos, especiais ou consequenciais, independentemente da causa.
Você nos defenderá, indenizará e nos isentará de qualquer reclamação feita por terceiros relacionada ao seu uso ou distribuição dos materiais.
O prazo deste acordo inicia quando você aceitar este acordo ou acessar os materiais, permanecendo válido até rescisão conforme termos e condições aqui estabelecidos.
Podemos rescindir este acordo se você violar quaisquer de seus termos. Após rescisão, você deve cessar imediatamente o uso dos materiais. Os Artigos VII, IX e "II. Contrato de Contribuidor" permanecem válidos após a rescisão.
Este acordo e quaisquer disputas decorrentes deste ou relacionadas a ele serão regidos pelas leis da China.
O Tribunal Popular de Xangai terá jurisdição exclusiva sobre quaisquer disputas decorrentes deste acordo.
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
4xx (Códigos de status de erro do cliente): Geralmente indicam erros de sintaxe na solicitação, falha de autenticação ou problemas que impedem o processamento da requisição.
5xx (Códigos de status de erro do servidor): Geralmente indicam problemas no lado do servidor, como servidor indisponível, tempo limite de processamento, etc.
400
Formato incorreto do corpo da solicitação, entre outros
Verifique o conteúdo do erro na resposta da conversa ou no para ver detalhes do erro e siga as instruções.
[Caso comum 1]: Para modelos Gemini, pode ser necessário vincular um cartão; [Caso comum 2]: Dados excedem o limite de tamanho, comum em modelos visuais. Imagens maiores que o limite superior retornam este erro; [Caso comum 3]: Parâmetros não suportados ou incorretos. Teste com um novo assistente limpo; [Caso comum 4]: Contexto excede o limite. Limpe o histórico ou inicie uma nova conversa.
401
Autenticação falhou: modelo não suportado ou conta suspensa no servidor
Entre em contato com o provedor de serviços ou verifique o status da conta
403
Sem permissão para a operação solicitada
Execute ações conforme o erro na resposta da conversa ou informações do
404
Recurso não encontrado
Verifique o caminho da solicitação
422
Sintaxe correta, mas erro semântico
Erros processáveis mas não executáveis. Comum em erros de semântica JSON (ex: valor nulo; esperado string, mas número/booleano fornecido).
429
Limite de taxa de solicitação excedido
Taxa (TPM/RPM) atingiu o limite máximo. Aguarde antes de tentar novamente
500
Erro interno do servidor, solicitação não processada
Contate o provedor se persistir
501
Funcionalidade não implementada pelo servidor
502
Resposta inválida recebida de servidor remoto pelo gateway/proxy
503
Serviço indisponível (sobrecarga/manutenção). O cabeçalho Retry-After indica tempo de espera.
504
Gateway/proxy não obteve resposta do servidor remoto a tempo
Clique na janela do cliente Cherry Studio e pressione Ctrl + Shift + I (Mac: Command + Option + I)
Na janela do console: Clique em Network → Selecione a última entrada com × vermelho em ② (completions para diálogo/tradução/erros de modelo ou generations para pintura) → Clique em Response para ver o conteúdo completo (área ④).
Se não conseguir identificar o erro, envie um print desta tela para o Grupo oficial.
Este método funciona para diálogos, testes de modelo, criação de bases de conhecimento, pintura, etc. Sempre abra o console ANTES de realizar a operação.
Fórmulas exibidas como código? Verifique delimitadores:
Uso de Delimitadores
Fórmula em linha
Cifrão simples:
$fórmula$Ou
\(fórmula\)Bloco de fórmula
Cifrão duplo:
$$fórmula$$Ou
\[fórmula\]Exemplo:
$$\sum_{i=1}^n x_i$$
Erros de renderização com caracteres chineses? Troque o mecanismo para KateX.
Modelo indisponível
Confirme suporte do provedor ou status do serviço.
Uso de modelo não compatível com embedding
Verifique suporte à visão: modelos compatíveis têm ícone de olho 👁️ após o nome.
Modelos visuais permitem upload de imagens. Se a função não estiver ativada:
Acesse os modelos do provedor
Clique no ícone de configuração
Marque a opção de imagem
Modelos sem suporte visual não processarão imagens, mesmo com a opção ativada. Consulte informações específicas com seu provedor.
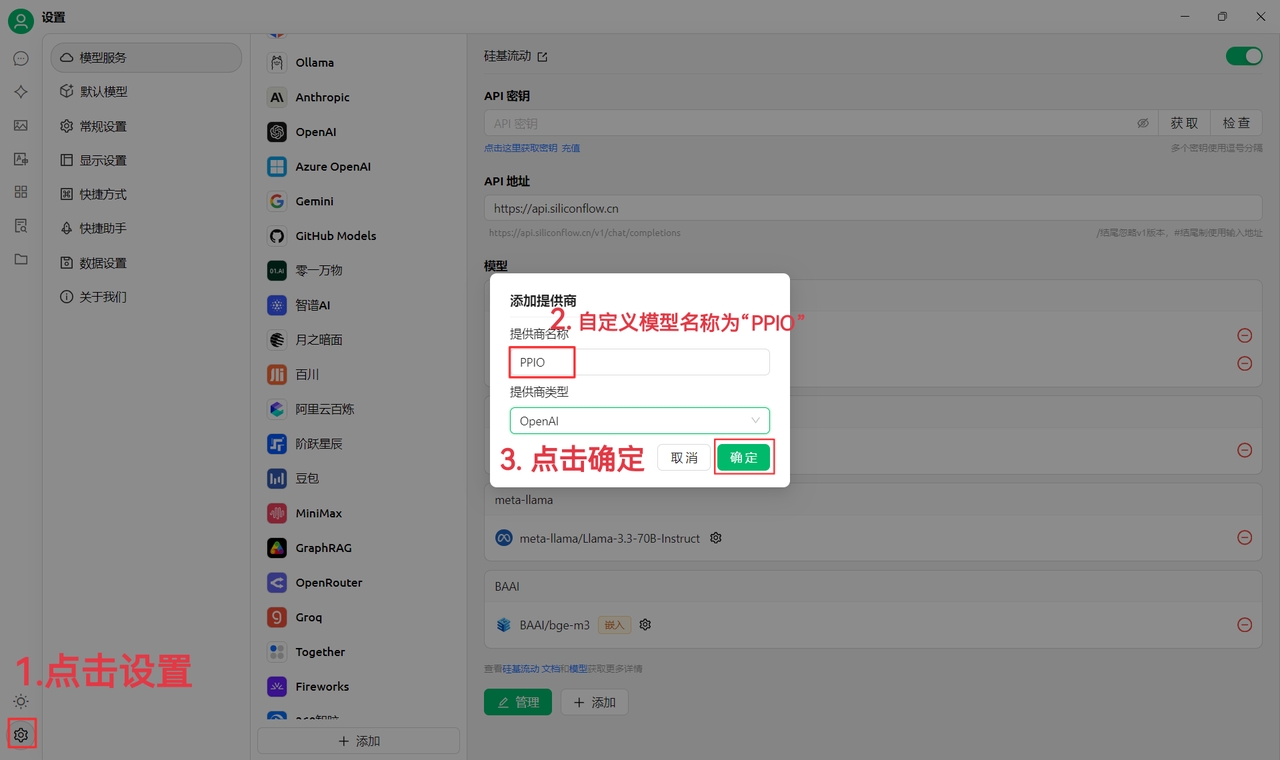
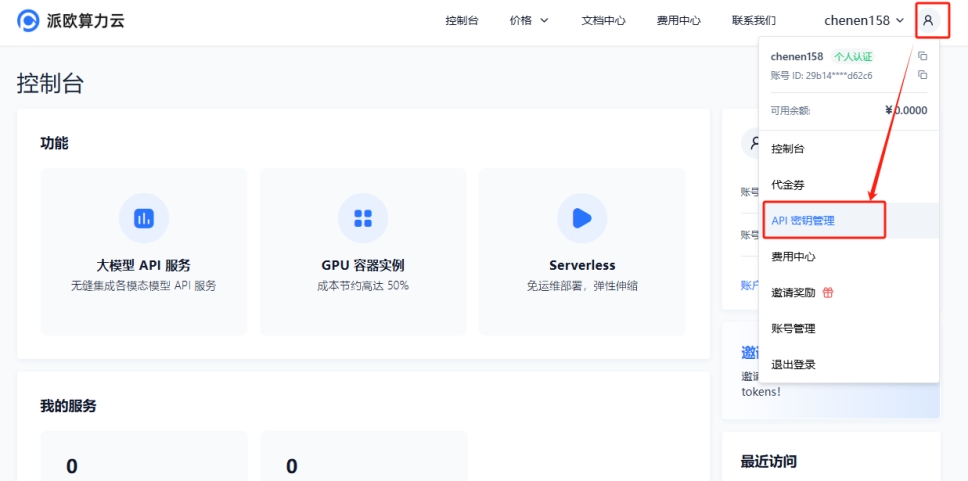

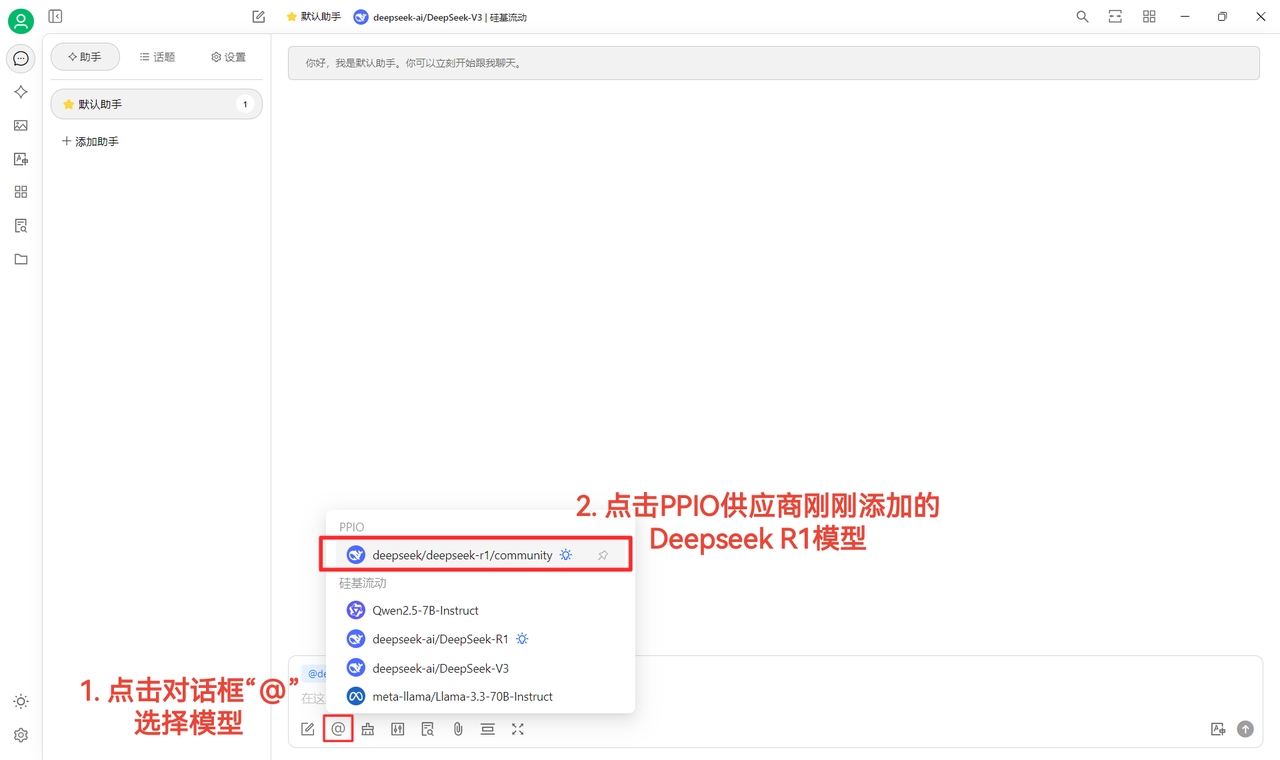



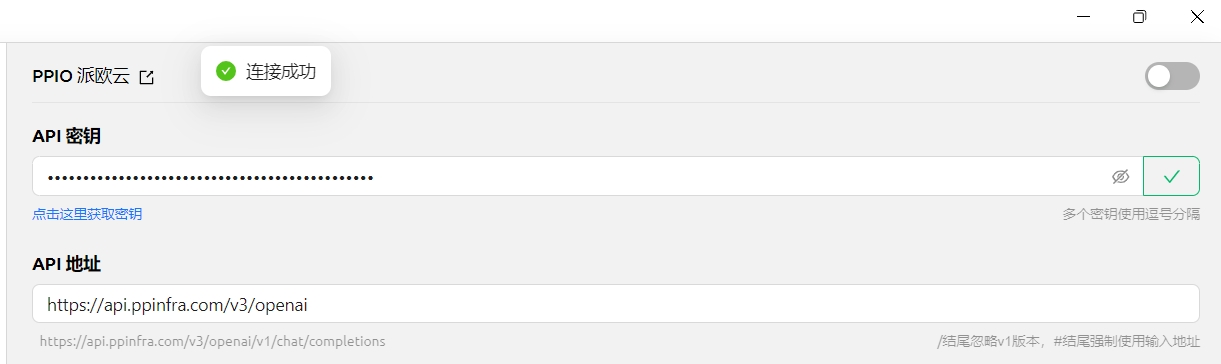

Este documento foi traduzido do chinês por IA e ainda não foi revisado.
CherryStudio oferece suporte à pesquisa na web via SearXNG. Como o SearXNG é um projeto de código aberto que pode ser implantado localmente ou em servidores, sua configuração difere ligeiramente de outros provedores que exigem APIs.
Link do projeto SearXNG: SearXNG
Código aberto e gratuito, sem necessidade de API
Alta privacidade relativa
Altamente personalizável
Como o SearXNG não requer configurações complexas de ambiente, podemos implantá-lo rapidamente usando Docker com apenas uma porta livre, sem precisar do docker compose.
1. Baixar e configurar Docker
Após instalar, selecione um caminho para armazenamento de imagens:
2. Pesquisar e baixar a imagem do SearXNG
Na barra de pesquisa, digite searxng:
Baixar a imagem:
3. Executar a imagem
Após o download, acesse a página Images:
Selecione a imagem baixada e clique em "Run":
Abra as configurações para ajustar:
Exemplo usando a porta 8085:
Após execução bem-sucedida, clique no link para abrir a interface do SearXNG:
Esta página confirma a implantação bem-sucedida:
Como a instalação do Docker no Windows pode ser complexa, os usuários podem implantar o SearXNG em servidores e compartilhá-lo. No entanto, o SearXNG atualmente não suporta autenticação, permitindo que outros localizem e abusem da instância.
Para solucionar isso, o Cherry Studio agora suporta Autenticação Básica HTTP (RFC7617). Se você expor seu SearXNG publicamente, configure obrigatoriamente a autenticação via Nginx ou software similar. Abaixo está um tutorial rápido (requer conhecimentos básicos de Linux).
Use Docker conforme anteriormente. Supondo que o Docker CE já está instalado (tutorial oficial), execute estes comandos (Debian):
sudo apt update
sudo apt install git -y
# Clonar repositório oficial
cd /opt
git clone https://github.com/searxng/searxng-docker.git
cd /opt/searxng-docker
# Para servidores com baixa largura de banda, defina como false
export IMAGE_PROXY=true
# Modificar configurações
cat <<EOF > /opt/searxng-docker/searxng/settings.yml
# see https://docs.searxng.org/admin/settings/settings.html#settings-use-default-settings
use_default_settings: true
server:
# base_url is defined in the SEARXNG_BASE_URL environment variable, see .env and docker-compose.yml
secret_key: $(openssl rand -hex 32)
limiter: false # can be disabled for a private instance
image_proxy: $IMAGE_PROXY
ui:
static_use_hash: true
redis:
url: redis://redis:6379/0
search:
formats:
- html
- json
EOFPara alterar a porta ou reutilizar um Nginx existente, edite docker-compose.yaml:
version: "3.7"
services:
# Remova esta seção para reutilizar o Nginx existente
caddy:
container_name: caddy
image: docker.io/library/caddy:2-alpine
network_mode: host
restart: unless-stopped
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile:ro
- caddy-data:/data:rw
- caddy-config:/config:rw
environment:
- SEARXNG_HOSTNAME=${SEARXNG_HOSTNAME:-http://localhost}
- SEARXNG_TLS=${LETSENCRYPT_EMAIL:-internal}
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
# Remova esta seção para reutilizar o Nginx existente
redis:
container_name: redis
image: docker.io/valkey/valkey:8-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: unless-stopped
networks:
- searxng
volumes:
- valkey-data2:/data
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
searxng:
container_name: searxng
image: docker.io/searxng/searxng:latest
restart: unless-stopped
networks:
- searxng
# Porta padrão 8080. Para usar 8000: "127.0.0.1:8000:8080"
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
- UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4}
- UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4}
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
searxng:
volumes:
# Remova esta seção para reutilizar o Nginx existente
caddy-data:
caddy-config:
# Remova esta seção para reutilizar o Nginx existente
valkey-data2:Execute docker compose up -d para iniciar. Monitore logs com docker compose logs -f searxng.
Se usar painéis como Baota ou 1Panel, consulte a documentação para configurar o proxy reverso. Adicione ao arquivo Nginx:
server
{
listen 443 ssl;
# Seu nome de host
server_name search.example.com;
# index index.html;
# root /data/www/default;
# Certificado SSL
ssl_certificate /path/to/your/cert/fullchain.pem;
ssl_certificate_key /path/to/your/cert/privkey.pem;
# Adicione estas linhas ao bloco location
location / {
auth_basic "Informe seu usuário e senha";
auth_basic_user_file /etc/nginx/conf.d/search.htpasswd;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_protocol_addr;
proxy_pass http://127.0.0.1:8000;
client_max_body_size 0;
}
# access_log ...;
# error_log ...;
}Crie o arquivo de senhas (substitua exemplo_usuario e exemplo_senha):
echo "exemplo_usuario:$(openssl passwd -5 'exemplo_senha')" > /etc/nginx/conf.d/search.htpasswdReinicie o Nginx. Acesse a página para verificar a autenticação:
Após implantar o SearXNG, configure no CherryStudio:
Acesse as configurações de pesquisa na web e selecione Searxng:
A validação inicial falhará (normal, sem JSON configurado):
No Docker, acesse a guia Files e localize settings.yml:
Abra o editor de arquivos:
Na linha 78, adicione json aos formatos:
Antes
Depois
Reinicie a imagem:
Valide novamente no Cherry Studio:
Use:
Local: http://localhost:[porta]
Docker: http://host.docker.internal:[porta]
Para instâncias em servidor com autenticação, adicione credenciais nas configurações:
O SearXNG vem com configurações padrão. Para personalizar mecanismos usados pelos modelos de IA, ajuste o arquivo de configuração:
Exemplo de configuração:
Adicione json aos formatos em settings.yml:
Para evitar falhas com Google em regiões bloqueadas, force o uso do Baidu:
use_default_settings:
engines:
keep_only:
- baidu
engines:
- name: baidu
engine: baidu
categories:
- web
- general
disabled: falseDesative o limiter em settings.yml:
Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Assistentes são configurações personalizadas aplicadas a modelos selecionados, como predefinições de prompts e parâmetros. Essas configurações fazem com que o modelo atenda melhor às suas expectativas de trabalho.
Assistente padrão do sistema oferece parâmetros genéricos pré-configurados (sem prompts). Você pode usá-lo diretamente ou acessar a para encontrar predefinições necessárias.
Assistentes são o conjunto pai de tópicos. Um único assistente pode conter vários tópicos (conversas). Todos os tópicos compartilham as configurações do modelo do assistente, como parâmetros e prompts.
Novo Tópico: Cria um novo tópico no assistente atual.
Enviar Imagem/Documento: Imagens requerem suporte do modelo. Documentos serão analisados como texto para contexto.
Pesquisa na Web: Configure informações de pesquisa nas configurações. Resultados são fornecidos como contexto ao modelo (veja ).
Base de Conhecimento: Ativa a integração com base de conhecimento (veja ).
Servidor MCP: Ativa recursos do servidor MCP (veja ).
Gerar Imagem: Oculto por padrão. Para modelos como Gemini, acione manualmente para gerar imagens.
Selecionar Modelo: Altera o modelo para conversas subsequentes, mantendo o contexto.
Frases Rápidas: Pré-configure frases frequentes nas configurações para acesso rápido (suporta variáveis).
Limpar Mensagens: Exclui todo o conteúdo do tópico.
Expandir: Amplia a área de mensagem para textos longos.
Limpar Contexto: Remove o contexto das mensagens anteriores sem excluir conteúdo ("esquece" conversas passadas).
Tokens Estimados: Mostra contexto atual, contexto máximo (∞ = ilimitado), palavras na mensagem e tokens estimados.
Traduzir: Traduz o conteúdo da caixa de entrada para inglês.
Sincronizadas com Configurações do Modelo do assistente (veja ).
Linha Divisória:
Separa o corpo da mensagem da barra de ações.
Fonte Serifada:
Alterna estilos de fonte (personalize com ).
Mostrar Números de Linha:
Exibe números em blocos de código gerados pelo modelo.
Dobrar Blocos de Código:
Dobra automaticamente blocos de código extensos.
Quebrar Linhas em Código:
Permite quebra automática de linhas longas em blocos de código.
Dobrar Processo de Raciocínio:
Dobra automaticamente etapas de raciocínio de modelos compatíveis.
Estilo de Mensagem:
Alterna entre estilo de bolhas ou lista.
Estilo de Código:
Altera o estilo visual de blocos de código.
Motor de Fórmulas:
KaTeX: Renderização mais rápida (otimizado para performance);
MathJax: Mais recursos (suporte a símbolos/comandos avançados), porém mais lento.
Tamanho da Fonte:
Ajusta o tamanho da fonte na interface.
Mostrar Tokens Estimados:
Exibe estimativa de tokens para texto digitado (não inclui contexto; apenas referência).
Colar Texto Longo como Arquivo:
Textos longos colados na caixa de entrada são exibidos como arquivos para reduzir interferência.
Renderizar Markdown em Mensagens:
Quando inativo, apenas mensagens de resposta são renderizadas.
Traduzir com Três Espaços:
Traduz conteúdo da caixa de entrada para inglês após três espaços consecutivos.
Isso sobrescreve o texto original.
Idioma de Destino:
Define o idioma alvo para traduções (botão e atalho de espaços).
Selecione o nome do assistente → Menu de contexto → Configurações
Configurações de Prompt
Nome:
Nome personalizado para identificação.
Prompt:
Edite conforme exemplos na página de Agentes.
Configurações do Modelo
Modelo Padrão:
Define um modelo padrão para o assistente (sobrescreve o ).
Redefinir Modelo Automaticamente:
Ativo: Novos tópicos usam o modelo padrão do assistente. Inativo: Novos tópicos herdam o modelo do tópico anterior.
Exemplo: Modelo padrão: gpt-3.5-turbo. No Tópico 1, você muda para gpt-4o. Ativo → Tópico 2 usa gpt-3.5-turbo. Inativo → Tópico 2 usa gpt-4o.
Temperatura (Temperature) :
Controla criatividade (padrão=0.7):
Baixa (0-0.3): Precisão (ex.: código, dados);
Média (0.4-0.7): Equilíbrio (ex.: conversas);
Alta (0.8-1.0): Máxima criatividade (ex.: textos criativos).
Top P (Amostragem Nuclear):
Padrão=1. Controla diversidade léxica:
Baixo (0.1-0.3): Vocabulário conservador (ex.: documentação técnica);
Médio (0.4-0.6): Equilíbrio;
Alto (0.7-1.0): Máxima diversidade (ex.: criação de conteúdo).
Janela de Contexto
Número de mensagens retidas (mais mensagens = mais tokens):
5-10: Conversas simples
10: Tarefas complexas
Nota: Mensagens extras consomem mais tokens
Limitar Tamanho (MaxToken)
Máximo de por resposta. Afeta qualidade/comprimento.
Exemplo: Para testar conectividade, defina MaxToken=1.
Limites variam por modelo (ex.: 32k/64k tokens).
Sugestões:
Conversas: 500-800
Textos curtos: 800-2000
Código: 2000-3600
Textos longos: 4000+ (requer suporte do modelo)
Respostas podem ser truncadas (ex.: código longo). Ajuste conforme necessidade.
Saída em Fluxo (Stream)
Transmite respostas incrementalmente (efeito "máquina de escrever"). Inativo → Respostas completas enviadas de uma vez.
Parâmetros Customizados
Adicione parâmetros extras (ex.: presence_penalty). Uso avançado.
Exemplos de parâmetros padrão: top-p, maxtokens, stream. Referência:
























Este documento foi traduzido do chinês por IA e ainda não foi revisado.
Este é um leaderboard baseado em dados do Chatbot Arena (lmarena.ai), gerado por um processo automatizado.
Data de atualização: 2025-07-04 11:42:19 UTC / 2025-07-04 19:42:19 CST (Horário de Pequim)
1
1
1473
+5/-4
14,062
Proprietária
Dados não disponíveis
2
2
1446
+4/-5
14,432
Proprietária
Dados não disponíveis
3
2
1428
+4/-3
23,599
OpenAI
Proprietária
Dados não disponíveis
3
2
1426
+5/-4
20,095
OpenAI
Proprietária
Dados não disponíveis
3
6
1424
+5/-5
12,396
DeepSeek
MIT
Dados não disponíveis
3
7
1423
+3/-4
25,067
xAI
Proprietária
Dados não disponíveis
4
6
1418
+4/-4
19,451
Proprietária
Dados não disponíveis
5
4
1415
+6/-5
15,271
OpenAI
Proprietária
Dados não disponíveis
9
7
1398
+5/-5
16,552
Proprietária
Dados não disponíveis
9
11
1389
+5/-4
14,090
Alibaba
Apache 2.0
Dados não disponíveis
10
6
1385
+5/-4
17,456
OpenAI
Proprietária
Dados não disponíveis
10
11
1384
+3/-4
20,171
DeepSeek
MIT
Dados não disponíveis
10
18
1380
+6/-6
8,244
Tencent
Proprietária
Dados não disponíveis
11
12
1374
+8/-8
6,117
MiniMax
Apache 2.0
Dados não disponíveis
13
12
1375
+4/-3
19,430
DeepSeek
MIT
Dados não disponíveis
14
6
1372
+3/-3
19,708
Anthropic
Proprietária
Dados não disponíveis
14
18
1369
+5/-4
18,439
Mistral
Proprietária
Dados não disponíveis
15
11
1367
+3/-3
29,038
OpenAI
Proprietária
Dados não disponíveis
15
23
1367
+4/-4
13,817
Alibaba
Apache 2.0
Dados não disponíveis
16
25
1364
+3/-3
36,673
Proprietária
Dados não disponíveis
16
11
1364
+5/-4
17,150
OpenAI
Proprietária
Dados não disponíveis
16
23
1363
+3/-4
31,778
Alibaba
Proprietária
Dados não disponíveis
16
29
1361
+5/-5
9,759
xAI
Proprietária
Dados não disponíveis
19
25
1361
+3/-4
25,902
Gemma
Dados não disponíveis
25
18
1352
+3/-3
33,177
OpenAI
Proprietária
2023/10
25
12
1345
+5/-5
15,543
Anthropic
Proprietária
Dados não disponíveis
26
24
1342
+5/-4
19,404
OpenAI
Proprietária
Dados não disponíveis
26
32
1338
+10/-10
3,976
Gemma
Dados não disponíveis
26
21
1338
+4/-4
16,454
OpenAI
Proprietária
Dados não disponíveis
27
30
1336
+3/-4
22,841
DeepSeek
DeepSeek
Dados não disponíveis
27
38
1334
+4/-5
18,063
Alibaba
Apache 2.0
Dados não disponíveis
28
49
1330
+7/-7
6,343
Amazon
Proprietária
Dados não disponíveis
28
36
1328
+8/-6
6,028
Zhipu
Proprietária
Dados não disponíveis
29
31
1330
+3/-4
26,104
Proprietária
Dados não disponíveis
29
33
1328
+6/-8
6,055
Alibaba
Proprietária
Dados não disponíveis
30
33
1327
+3/-4
23,879
Cohere
CC-BY-NC-4.0
Dados não disponíveis
30
39
1322
+8/-6
5,126
StepFun
Proprietária
Dados não disponíveis
30
31
1320
+11/-12
2,452
Tencent
Proprietária
Dados não disponíveis
32
39
1314
+14/-8
2,371
Nvidia
Nvidia
Dados não disponíveis
33
32
1322
+3/-3
36,135
OpenAI
Proprietária
Dados não disponíveis
33
39
1321
+2/-3
54,951
OpenAI
Proprietária
2023/10
33
33
1314
+11/-11
2,510
Tencent
Proprietária
Dados não disponíveis
35
32
1320
+3/-2
58,645
Proprietária
Dados não disponíveis
37
17
1315
+4/-3
25,145
Anthropic
Proprietária
Dados não disponíveis
40
53
1309
+7/-8
6,311
Gemma
Dados não disponíveis
42
21
1308
+3/-4
29,775
Anthropic
Proprietária
Dados não disponíveis
43
44
1305
+2/-2
67,084
xAI
Proprietária
2024/3
43
48
1305
+2/-4
28,968
01 AI
Proprietária
Dados não disponíveis
45
35
1302
+2/-1
117,747
OpenAI
Proprietária
2023/10
45
58
1300
+5/-6
10,715
Alibaba
Proprietária
Dados não disponíveis
46
25
1301
+2/-3
77,078
Anthropic
Proprietária
2024/4
48
51
1297
+4/-7
7,243
DeepSeek
DeepSeek
Dados não disponíveis
48
62
1293
+8/-8
4,321
Gemma
Dados não disponíveis
50
48
1289
+9/-10
3,856
Tencent
Proprietária
Dados não disponíveis
51
59
1293
+3/-3
26,074
NexusFlow
NexusFlow
Dados não disponíveis
51
40
1293
+4/-5
17,075
Meta
Llama 4
Dados não disponíveis
51
56
1291
+3/-3
27,788
Zhipu AI
Proprietária
Dados não disponíveis
51
49
1288
+7/-7
6,302
OpenAI
Proprietária
Dados não disponíveis
52
58
1289
+2/-2
72,531
OpenAI
Proprietária
2023/10
52
66
1289
+3/-3
37,021
Proprietária
Dados não disponíveis
52
76
1286
+6/-6
7,577
Nvidia
Llama 3.1
2023/12
54
39
1286
+3/-3
43,788
Meta
Llama 3.1 Community
2023/12
55
36
1286
+2/-2
86,159
Anthropic
Proprietária
2024/4
57
40
1285
+2/-2
63,038
Meta
Llama 3.1 Community
2023/12
57
39
1284
+2/-3
52,144
Proprietária
Online
57
72
1284
+2/-2
55,442
xAI
Proprietária
2024/3
58
44
1283
+3/-3
47,973
OpenAI
Proprietária
2023/10
58
58
1281
+4/-4
17,432
Alibaba
Qwen
Dados não disponíveis
58
58
1278
+7/-9
4,014
Tencent
Proprietária
Dados não disponíveis
66
74
1273
+7/-7
6,154
Mistral
Apache 2.0
Dados não disponíveis
68
53
1277
+2/-2
82,435
Proprietária
2023/11
68
69
1276
+3/-4
26,344
DeepSeek
DeepSeek
Dados não disponíveis
68
56
1275
+2/-3
47,256
Meta
Llama-3.3
Dados não disponíveis
68
74
1275
+2/-2
41,519
Alibaba
Qwen
2024/9
69
53
1274
+2/-1
102,133
OpenAI
Proprietária
2023/12
74
59
1269
+2/-3
48,217
Mistral
Mistral Research
2024/7
74
74
1268
+4/-4
20,580
NexusFlow
CC-BY-NC-4.0
2024/7
74
58
1267
+3/-2
103,748
OpenAI
Proprietária
2023/4
74
74
1266
+4/-3
29,633
Mistral
MRL
Dados não disponíveis
74
79
1262
+8/-9
3,010
Ai2
Llama 3.1
Dados não disponíveis
74
61
1262
+9/-11
3,602
Mistral
Proprietária
Dados não disponíveis
75
81
1265
+2/-2
58,637
Meta
Llama 3.1 Community
2023/12
76
55
1265
+2/-1
202,641
Anthropic
Proprietária
2023/8
76
84
1262
+4/-3
26,371
Amazon
Proprietária
Dados não disponíveis
78
61
1262
+2/-2
97,079
OpenAI
Proprietária
2023/12
83
56
1257
+3/-2
48,556
Anthropic
Proprietária
Dados não disponíveis
83
82
1253
+7/-4
7,948
Reka AI
Proprietária
Dados não disponíveis
88
85
1244
+2/-2
65,661
Proprietária
2023/11
88
84
1239
+6/-4
9,125
AI21 Labs
Jamba Open
2024/3
88
87
1236
+9/-12
3,905
Tencent
Proprietária
Dados não disponíveis
89
85
1237
+2/-2
79,538
Gemma license
2024/6
89
92
1235
+7/-7
5,730
Alibaba
Apache 2.0
Dados não disponíveis
89
93
1235
+5/-5
15,321
Mistral
Apache 2.0
Dados não disponíveis
89
100
1234
+4/-4
20,646
Amazon
Proprietária
Dados não disponíveis
89
86
1234
+6/-5
10,548
Princeton
MIT
2024/7
89
87
1233
+5/-4
10,535
Cohere
CC-BY-NC-4.0
2024/8
89
82
1229
+9/-7
3,889
Nvidia
Llama 3.1
2023/12
91
102
1230
+3/-2
37,697
Proprietária
Dados não disponíveis
91
90
1227
+4/-3
20,608
Nvidia
NVIDIA Open Model
2023/6
91
100
1223
+10/-8
3,460
Allen AI
Apache-2.0
Dados não disponíveis
92
98
1227
+3/-3
28,768
Cohere
CC-BY-NC-4.0
Dados não disponíveis
93
91
1223
+7/-6
8,132
Reka AI
Proprietária
Dados não disponíveis
94
96
1224
+5/-4
10,221
Zhipu AI
Proprietária
Dados não disponíveis
97
92
1224
+1/-2
163,629
Meta
Llama 3 Community
2023/12
97
106
1223
+4/-4
25,213
Microsoft
MIT
Dados não disponíveis
102
91
1218
+2/-2
113,067
Anthropic
Proprietária
2023/8
104
114
1215
+4/-4
20,654
Amazon
Proprietária
Dados não disponíveis
107
102
1209
+2/-2
57,197
Gemma license
2024/6
107
115
1206
+8/-9
2,901
Tencent
Proprietária
Dados não disponíveis
108
100
1207
+2/-2
80,846
Cohere
CC-BY-NC-4.0
2024/3
108
116
1203
+8/-9
3,074
Ai2
Llama 3.1
Dados não disponíveis
109
101
1205
+2/-3
38,872
Alibaba
Qianwen LICENSE
2024/6
109
87
1204
+2/-3
55,962
OpenAI
Proprietária
2021/9
109
114
1200
+8/-8
5,111
Mistral
MRL
Dados não disponíveis
110
116
1197
+5/-7
10,391
Cohere
CC-BY-NC-4.0
Dados não disponíveis
110
104
1197
+5/-5
10,851
Cohere
CC-BY-NC-4.0
2024/8
112
106
1197
+2/-2
122,309
Anthropic
Proprietária
2023/8
112
98
1196
+4/-5
15,753
DeepSeek AI
DeepSeek License
2024/6
112
114
1193
+5/-5
9,274
AI21 Labs
Jamba Open
2024/3
113
131
1193
+2/-3
52,578
Meta
Llama 3.1 Community
2023/12
121
98
1180
+2/-2
91,614
OpenAI
Proprietária
2021/9
121
116
1179
+4/-3
27,430
Alibaba
Qianwen LICENSE
2024/4
121
148
1170
+9/-8
3,410
Alibaba
Apache 2.0
Dados não disponíveis
122
131
1175
+3/-3
25,135
01 AI
Apache-2.0
2024/5
122
115
1175
+2/-3
64,926
Mistral
Proprietária
Dados não disponíveis
122
116
1173
+4/-5
16,027
Reka AI
Proprietária
Online
125
125
1169
+2/-2
109,056
Meta
Llama 3 Community
2023/3
125
138
1166
+4/-5
10,599
InternLM
Other
2024/8
125
122
1165
+4/-3
25,803
Reka AI
Proprietária
2023/11
125
126
1160
+10/-8
3,289
IBM
Apache 2.0
Dados não disponíveis
126
120
1166
+2/-2
56,398
Cohere
CC-BY-NC-4.0
2024/3
126
125
1165
+3/-3
35,556
Mistral
Proprietária
Dados não disponíveis
127
120
1165
+2/-2
53,751
Mistral
Apache 2.0
2024/4
127
120
1165
+2/-3
40,658
Alibaba
Qianwen LICENSE
2024/2
128
138
1161
+2/-2
48,892
Gemma license
2024/7
135
120
1149
+4/-4
18,800
Proprietária
2023/4
135
128
1145
+9/-8
4,854
HuggingFace
Apache 2.0
2024/4
136
133
1143
+3/-4
22,765
Alibaba
Qianwen LICENSE
2024/2
136
141
1137
+10/-8
3,380
IBM
Apache 2.0
Dados não disponíveis
137
137
1140
+3/-4
26,105
Microsoft
MIT
2023/10
137
149
1136
+4/-5
16,676
Nexusflow
Apache-2.0
2024/3
140
138
1131
+3/-2
76,126
Mistral
Apache 2.0
2023/12
140
144
1129
+5/-4
15,917
01 AI
Yi License
2023/6
140
128
1128
+6/-8
6,557
Proprietária
2023/4
141
141
1126
+5/-4
18,687
Alibaba
Qianwen LICENSE
2024/2
142
141
1124
+5/-5
8,383
Microsoft
Llama 2 Community
2023/8
143
128
1123
+3/-2
68,867
OpenAI
Proprietária
2021/9
143
148
1120
+6/-6
8,390
Meta
Llama 3.2
2023/12
144
138
1121
+3/-3
33,743
Databricks
DBRX LICENSE
2023/12
144
145
1119
+4/-5
18,476
Microsoft
MIT
2023/10
144
146
1116
+7/-5
6,658
AllenAI/UW
AI2 ImpACT Low-risk
2023/11
149
139
1111
+6/-8
7,002
IBM
Apache 2.0
Dados não disponíveis
151
157
1110
+4/-3
39,595
Meta
Llama 2 Community
2023/7
151
144
1109
+5/-5
12,990
OpenChat
Apache-2.0
2024/1
151
150
1108
+4/-4
22,936
LMSYS
Não comercial
2023/8
152
144
1107
+3/-3
34,173
Snowflake
Apache 2.0
2024/4
152
153
1106
+5/-7
10,415
UC Berkeley
CC-BY-NC-4.0
2023/11
152
160
1102
+8/-7
3,836
NousResearch
Apache-2.0
2024/1
153
159
1098
+8/-9
3,636
Nvidia
Llama 2 Community
2023/11
156
145
1101
+3/-3
25,070
Gemma license
2024/2
157
147
1094
+7/-10
4,988
DeepSeek AI
DeepSeek License
2023/11
157
145
1094
+6/-8
8,106
OpenChat
Apache-2.0
2023/11
158
154
1091
+7/-7
7,191
IBM
Apache 2.0
Dados não disponíveis
159
147
1092
+6/-8
5,088
NousResearch
Apache-2.0
2023/11
159
164
1087
+8/-9
4,872
Alibaba
Qianwen LICENSE
2024/2
160
164
1090
+4/-4
20,067
Mistral
Apache-2.0
2023/12
160
164
1088
+4/-5
12,808
Microsoft
MIT
2023/10
160
140
1085
+5/-5
17,036
OpenAI
Proprietária
2021/9
160
160
1080
+12/-15
1,714
Cognitive Computations
Apache-2.0
2023/10
161
168
1084
+4/-3
21,097
Microsoft
MIT
2023/10
161
163
1080
+7/-7
4,286
Upstage AI
CC-BY-NC-4.0
2023/11
162
168
1081
+5/-5
19,722
Meta
Llama 2 Community
2023/7
165
164
1076
+7/-7
7,176
Microsoft
Llama 2 Community
2023/7
170
173
1071
+6/-6
8,523
Meta
Llama 3.2
2023/12
170
171
1071
+6/-5
11,321
HuggingFace
MIT
2023/10
170
166
1064
+13/-12
2,375
HuggingFace
Apache 2.0
Dados não disponíveis
170
173
1059
+18/-16
1,192
Meta
Llama 2 Community
2024/1
171
164
1063
+10/-9
2,644
MosaicML
CC-BY-NC-SA-4.0
2023/6
172
168
1058
+13/-10
1,811
HuggingFace
MIT
2023/10
173
172
1060
+7/-6
7,509
Meta
Llama 2 Community
2023/7
173
163
1051
+15/-15
1,327
TII
Falcon-180B TII License
2023/9
176
168
1059
+4/-4
19,775
LMSYS
Llama 2 Community
2023/7
176
173
1055
+6/-6
9,176
Gemma license
2024/2
176
173
1054
+4/-3
21,622
Microsoft
MIT
2023/10
176
188
1054
+5/-4
14,532
Meta
Llama 2 Community
2023/7
176
164
1052
+10/-8
5,065
Alibaba
Qianwen LICENSE
2023/8
176
174
1050
+10/-10
2,996
UW
Não comercial
2023/5
185
178
1038
+5/-6
11,351
Gemma license
2024/2
186
182
1035
+7/-6
5,276
Together AI
Apache 2.0
2023/12
186
195
1033
+7/-6
6,503
Allen AI
Apache-2.0
2024/2
189
187
1025
+6/-6
9,142
Mistral
Apache 2.0
2023/9
189
188
1022
+7/-7
7,017
LMSYS
Llama 2 Community
2023/7
190
177
1021
+6/-7
8,713
Proprietária
2021/6
194
192
1007
+7/-7
4,918
Gemma license
2024/2
194
190
1006
+7/-7
7,816
Alibaba
Qianwen LICENSE
2024/2
196
195
982
+6/-7
7,020
UC Berkeley
Não comercial
2023/4
196
196
972
+10/-9
4,763
Tsinghua
Apache-2.0
2023/10
198
195
950
+12/-15
1,788
Nomic AI
Não comercial
2023/3
198
196
946
+7/-12
3,997
MosaicML
CC-BY-NC-SA-4.0
2023/5
198
201
942
+11/-12
2,713
Tsinghua
Apache-2.0
2023/6
198
201
939
+7/-7
4,920
RWKV
Apache 2.0
2023/4
202
196
919
+10/-8
5,864
Stanford
Não comercial
2023/3
202
202
911
+9/-8
6,368
OpenAssistant
Apache 2.0
2023/4
203
204
896
+10/-9
4,983
Tsinghua
Não comercial
2023/3
204
204
885
+9/-8
4,288
LMSYS
Apache 2.0
2023/4
206
207
857
+9/-10
3,336
Stability AI
CC-BY-NC-SA-4.0
2023/4
206
204
840
+10/-9
3,480
Databricks
MIT
2023/4
208
205
817
+12/-15
2,446
Meta
Não comercial
2023/2
Rank(UB): Classificação calculada com base no modelo Bradley-Terry. Esta classificação reflete o desempenho geral do modelo na arena e fornece uma estimativa do limite superior de sua pontuação Elo, ajudando a entender sua competitividade potencial.
Rank(StyleCtrl): Classificação após controle de estilo de conversação. Visa reduzir o viés de preferência causado pelo estilo de resposta do modelo (por exemplo, verbosidade ou concisão), avaliando mais puramente sua capacidade central.
Nome do Modelo: Nome do Modelo de Linguagem Grande (LLM). Esta coluna contém links relacionados ao modelo; clique para acessar.
Pontuação: Pontuação Elo obtida pelo modelo através de votos dos usuários na arena. O Elo é um sistema de classificação relativa; pontuações mais altas indicam melhor desempenho. Esta pontuação é dinâmica e reflete a força relativa do modelo no ambiente competitivo atual.
Intervalo de Confiança: Intervalo de confiança de 95% para a pontuação Elo do modelo (por exemplo: +6/-6). Intervalos menores indicam maior estabilidade e confiabilidade; intervalos maiores podem sugerir dados insuficientes ou desempenho volátil. Fornece uma avaliação quantificada da precisão da pontuação.
Votos: Número total de votos recebidos pelo modelo na arena. Mais votos geralmente indicam maior confiabilidade estatística da pontuação.
Provedor: Organização ou empresa que fornece o modelo.
Licença: Tipo de licença do modelo, por exemplo: proprietária (Proprietary), Apache 2.0, MIT, etc.
Data Limite de Conhecimento: Data de corte do conhecimento nos dados de treinamento do modelo. Dados não disponíveis indica que a informação não foi fornecida ou é desconhecida.
Os dados deste leaderboard são gerados e fornecidos automaticamente pelo projeto fboulnois/llm-leaderboard-csv, que obtém e processa dados do lmarena.ai. Este leaderboard é atualizado diariamente por GitHub Actions.
Este relatório é apenas para referência. Os dados do leaderboard são dinâmicos e baseados em votos de preferência dos usuários no Chatbot Arena durante períodos específicos. A integridade e precisão dos dados dependem das fontes upstream e do processamento do projeto fboulnois/llm-leaderboard-csv. Modelos diferentes podem ter licenças distintas; consulte sempre as instruções oficiais do provedor do modelo antes de usar.



































