Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
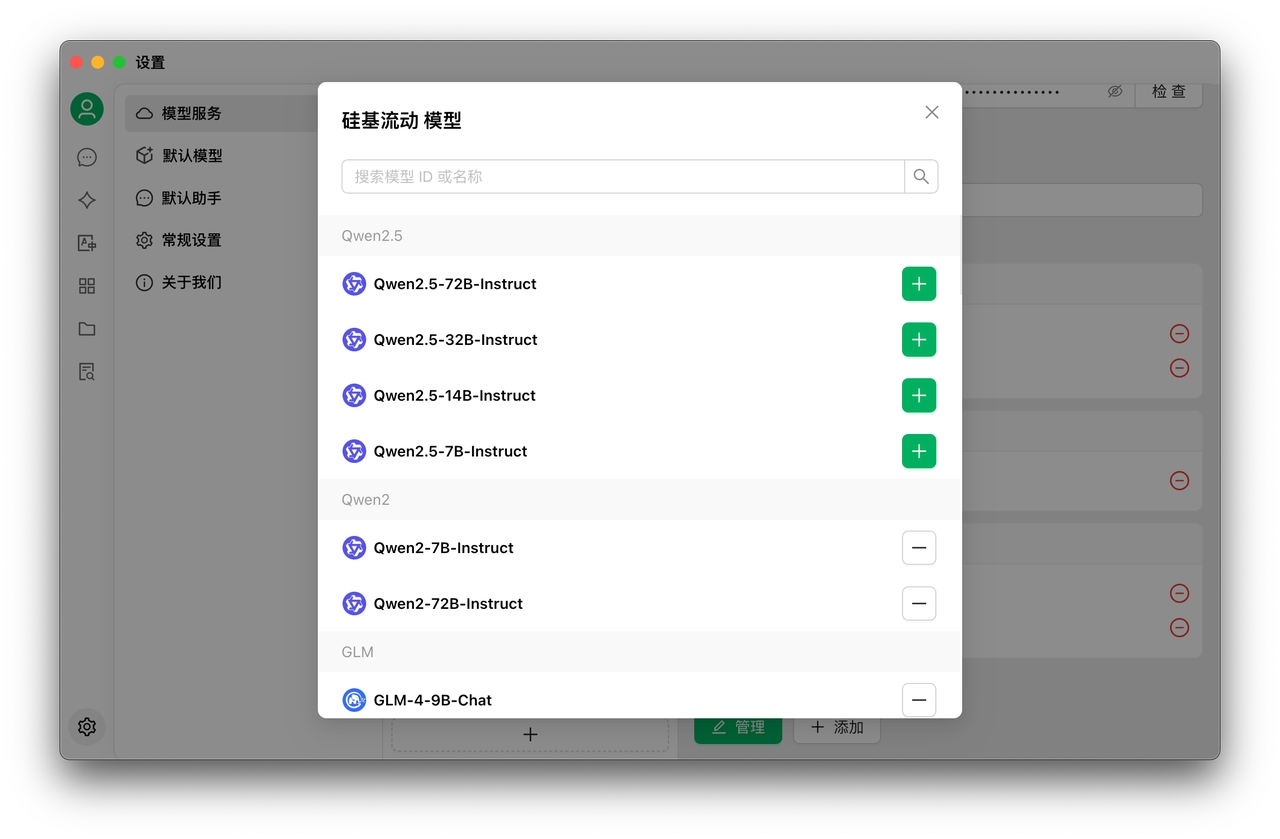
絵画機能は現在、DMXAPI、TokenFlux、AiHubMix、および硅基流动の描画モデルをサポートしています。硅基流动にアカウントを登録し、サービスプロバイダーに追加して使用することができます。
パラメータに関する疑問は、対応する領域の?アイコンにマウスオーバーすることで説明を確認できます。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
編集者権限を取得するには、[email protected] までメールでご連絡ください。
件名:Cherry Studio Docs 編集者権限の申請
本文:申請理由をご記入ください
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studioの翻訳機能は、迅速かつ正確なテキスト翻訳サービスを提供し、複数言語間の相互翻訳をサポートします。
翻訳インターフェースは主に以下の部分で構成されます:
原文言語選択エリア:
任意の言語:Cherry Studio が自動的に原文言語を認識して翻訳します。
目標言語選択エリア:
プルダウンメニュー:テキストを翻訳したい言語を選択します。
設定ボタン:
クリックすると デフォルトモデル設定 に移動します。
スクロール同期:
クリックでスクロール同期を切り替え(どちらか一方でスクロールすると、もう一方も連動してスクロール)。
テキスト入力ボックス(左側):
翻訳が必要なテキストを入力または貼り付けます。
翻訳結果ボックス(右側):
翻訳後のテキストを表示。
コピーボタン:クリックで翻訳結果をクリップボードにコピーします。
翻訳ボタン:
クリックで翻訳を開始します。
翻訳履歴(左上):
クリックで翻訳履歴を確認できます。
目標言語を選択:
目標言語選択エリアで翻訳したい言語を選択します。
テキストを入力または貼り付け:
左側のテキスト入力ボックスに翻訳したいテキストを入力または貼り付けます。
翻訳を開始:
翻訳 ボタンをクリックします。
結果の確認とコピー:
翻訳結果が右側の翻訳結果ボックスに表示されます。
コピーボタンをクリックすると翻訳結果をクリップボードにコピーできます。
Q: 翻訳が正確でない場合は?
A: AI翻訳は強力ですが完璧ではありません。専門分野や複雑な文脈のテキストは、手動での校正をお勧めします。別のモデルに切り替えることもお試しください。
Q: 対応言語は?
A: Cherry Studioの翻訳機能は主要な多言語に対応しています。具体的な対応言語リストは、Cherry Studio公式サイトまたはアプリ内説明をご参照ください。
Q: ファイル全体の翻訳は可能ですか?
A: 現在のインターフェースはテキスト翻訳が主な用途です。ファイル翻訳については、Cherry Studioの会話ページでファイルを追加して翻訳する必要があります。
Q: 翻訳速度が遅い場合は?
A: 翻訳速度はネットワーク接続状況、テキストの長さ、サーバー負荷などの影響を受ける可能性があります。ネットワーク接続が安定していることを確認し、お待ちください。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
SNSアカウントをフォロー:Twitter(X)、シャオホンシュー、ウェイボー、ビリビリ、抖音
コミュニティに参加:QQグループ(575014769)、Telegram、Discord、WeChatグループ(クリックして確認)
Cherry Studioは、マルチモデル対話、ナレッジベース管理、AI絵画、翻訳などの機能を統合したオールインワンAIアシスタントプラットフォームです。 高度にカスタマイズ可能な設計、強力な拡張性、ユーザーフレンドリーな操作性により、プロフェッショナルユーザーやAI愛好家に最適な選択肢となっています。ゼロから始めるユーザーでも開発者でも、Cherry Studioでニーズに合ったAI機能を見つけ、作業効率と創造性を高めることができます。
一問多答:同一質問に対して複数モデルから同時に回答を生成可能。詳細は対話インターフェースをご覧ください。
自動グループ化:アシスタントごとの対話履歴が自動的にグループ管理され、検索が容易です。
対話エクスポート:完全または部分的な対話をMarkdown、Wordなど複数形式でエクスポート可能。
高度なパラメータカスタマイズ:基本パラメータ調整に加え、カスタムパラメータ設定で個別ニーズに対応。
アシスタントマーケット:翻訳、プログラミング、執筆など業界特化型アシスタントを1000以上内蔵し、カスタム作成も可能。
多様な形式レンダリング:Markdownレンダリング、数式レンダリング、HTMLリアルタイムプレビューなどに対応。
AI絵画:自然言語記述から高品質画像を生成する専用パネル。
AIアプリ:Webベースの無料AIツールを統合し、ブラウザ切り替え不要。
翻訳機能:専用翻訳パネル、対話翻訳、プロンプト翻訳など多様な翻訳シーンに対応。
ファイル管理:対話、絵画、ナレッジベースのファイルを一元管理。
グローバル検索:履歴とナレッジベースの高速検索で作業効率向上。
プロバイダー集約:OpenAI、Gemini、Anthropic、Azureなど主要プロバイダーのモデルを統合利用。
自動モデル取得:ワンクリックで全モデルリスト取得、手動設定不要。
マルチAPIキーローテーション:複数APIキーのローテーション利用でレート制限回避。
アイコン自動マッチング:モデルごとに専用アイコンを自動割当て。
カスタムプロバイダー:OpenAI/Gemini/Anthropic互換サードパーティプロバイダー対応。
CSSカスタマイズ:グローバルスタイル設定で独自UIを構築。
対話レイアウトカスタマイズ:リスト/バブルスタイル選択とメッセージスタイル設定。
カスタムアバター:ソフトウェアとアシスタントのアバターを個別設定可能。
サイドバーメニューカスタマイズ:機能の表示/非表示と順序変更で使用体験を最適化。
多様なフォーマット対応:PDF/DOCX/PPTX/XLSX/TXT/MDなど幅広い形式をサポート。
多様なデータソース:ローカルファイル、URL、サイトマップ、手動入力などをソースとして利用。
ナレッジベースエクスポート:処理済みナレッジベースを共有可能。
検証機能:インポート後、リアルタイムでセグメント結果を確認。
クイックQA:任意のコンテキストでワンクリックアシスタントを起動。
クイック翻訳:外部テキストを瞬間翻訳。
コンテンツ要約:長文を素早く要約し情報抽出効率化。
説明機能:複雑なプロンプト不要で理解を深めます。
多様なバックアップ:ローカル/WebDAV/スケジュールバックアップでデータ保護。
データセキュリティ:ローカルLLM連携で完全ローカル環境運用可能。
初心者フレンドリー:技術的ハードルを低く設定し、創作に集中可能。
充実ドキュメント:詳細な使用ガイドとFAQで問題解決を支援。
継続的アップデート:ユーザーフィードバックを基に機能改善。
OSSと拡張性:オープンソースでカスタマイズと拡張を実現。
知識管理・検索:研究/教育分野向け専用ナレッジベース構築。
マルチモデル対話・創作:コンテンツ生成や情報収集を効率化。
翻訳・オフィス業務:多言語対応と文書自動処理を実現。
AI描画・デザイン:創作的デザイン要望に自然言語で対応。
Windows 版本安装教程






















このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
バージョン0.9.1で、CherryStudioは待望のナレッジベース機能を提供しました。
以下では、ステップごとにCherryStudioの詳細な使用説明を紹介します。
モデル管理サービスで「埋め込みモデル」をクリックして迅速にフィルタリングし、必要なモデルを検索します;
必要なモデルを見つけたら、「マイモデル」に追加します。
ナレッジベースのエントリー:CherryStudioの左側ツールバーでナレッジベースアイコンをクリックし、管理ページに進みます;
ナレッジベースの追加:「追加」をクリックしてナレッジベースの作成を開始します;
命名:ナレッジベースの名前を入力し、bge-m3などの埋め込みモデルを追加すると作成が完了します。
ファイルの追加:ファイル追加ボタンをクリックしてファイル選択画面を開きます;
ファイルの選択:pdf、docx、pptx、xlsx、txt、md、mdxなどのサポート形式を選択し、開きます;
ベクトル化:システムが自動的にベクトル化処理を行い、完了マーク(緑の✓)が表示されたらベクトル化が終了しています。
CherryStudioは複数のデータ追加方法をサポートしています:
フォルダーディレクトリ:サポート形式のファイルを含むフォルダー全体を追加でき、自動的にベクトル化されます;
URLリンク:https://docs.siliconflow.cn/introduction などのウェブURLをサポート;
サイトマップ:https://docs.siliconflow.cn/sitemap.xml などのXML形式サイトマップをサポート;
プレーンテキストノート:カスタムコンテンツのプレーンテキスト入力をサポート。
ファイルのベクトル化が完了すると、クエリを実行できます:
ページ下部の「ナレッジベースを検索」ボタンをクリック;
検索内容を入力;
検索結果を表示;
各結果のマッチングスコアを表示。
新規トピックを作成し、会話ツールバーで「ナレッジベース」をクリック。作成済みナレッジベースリストが展開されるので、参照したいナレッジベースを選択;
質問を入力して送信すると、モデルが検索結果に基づいた回答を返信;
同時に、参照元データが回答の下に表示され、ソースファイルをすぐに確認できます。
如何在 Cherry Studio 使用联网模式
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studioの質問ウィンドウで、地球のアイコンをクリックするとオンライン機能を開始できます。
モード1:モデルプロバイダーの大規模モデルにデフォルトでオンライン機能が組み込まれている
この場合、オンライン機能を開始するだけで、簡単に利用できます。
質問インターフェースの上部、モデル名の後に小さな地球マークが表示されているかどうかで、そのモデルがオンライン機能をサポートしているかをすばやく判断できます。
モデル管理ページでも、この方法で、どのモデルがオンライン機能をサポートしているか一目でわかります。
現在、Cherry Studioでオンライン機能をサポートしているモデルプロバイダーは以下の通りです
Google Gemini
OpenRouter(すべてのモデルでオンライン機能をサポート)
Tencent Hunyuan
Zhipu AI
Alibaba Cloud Bailianなど
特別注意: モデルに地球マークがない場合でもオンライン機能が利用できるケースがあります。以下の攻略チュートリアルで説明されています。
モード2:モデルにオンライン機能がなく、Tavilyサービスで実現する
オンライン機能を持たない大規模モデルを使用している場合(名前の後に地球マークがない)、リアルタイム情報を取得したいときにTavilyネットワーク検索サービスが必要です。
初めてTavilyサービスを使用する際、ポップアップが表示され設定を案内します。指示に従って操作してください - 非常に簡単です!
APIキーの取得をクリックすると、自動的にTavily公式サイトのログインページにリダイレクトされます。登録し、ログイン後、APIキーを作成し、そのキーをCherry Studioにコピーしてください。
登録方法がわからない場合は、本ドキュメントの同じディレクトリにあるtavily登録チュートリアルを参照してください。
tavily登録参考ドキュメント:
以下のインターフェイスが表示され、登録成功を示しています。
再度試して効果を確認しましょう。結果は、正常にオンライン検索が行われ、デフォルトで5件の検索結果が取得されています。
注意:Tavilyには毎月の無料利用制限があり、超過すると課金が必要です〜
PS:問題を見つけた場合は、お気軽にお問い合わせください。




















このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
担当者:王様 📮:[email protected] 📱:18954281942(カスタマーサービス電話ではありません)
利用に関するお問い合わせは、公式サイトフッターのユーザー交流グループに参加いただくか、[email protected] までメールでお願いいたします。
または issues を提出してください:https://github.com/CherryHQ/cherry-studio/issues
より詳しいガイダンスが必要な場合は、当社の知識コミュニティにご参加ください。
商用ライセンス詳細:https://docs.cherry-ai.com/contact-us/questions/cherrystudio-xu-ke-xie-yi
数据设置→Obsidian配置
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry StudioはObsidianとの連携をサポートしており、完全な会話または単一の会話をObsidianライブラリにエクスポートできます。
このプロセスでは追加のObsidianプラグインをインストールする必要はありません。ただし、Cherry StudioからObsidianへのインポートはObsidian Web Clipperと同様の原理を使用しているため、可能性を避けるために、Obsidianを最新バージョンにアップグレードすることをお勧めします(現在のObsidianバージョンは少なくとも1.7.2より大きい必要があります)。
Cherry Studioの_設定_ → データ設定 → _Obsidian設定_メニューを開きます。ドロップダウンボックスには、ローカルで開いたことがあるObsidianライブラリ名が自動的に表示されます。目標とするObsidianライブラリを選択してください:
完全な会話をエクスポート
Cherry Studioの会話インターフェースに戻り、会話を右クリックして_エクスポート_を選択し、_Obsidianにエクスポート_をクリックします:
ポップアップウィンドウが表示され、Obsidianにエクスポートするこの会話ノートの Properties(属性)、Obsidian内のフォルダ位置、およびエクスポート時の処理方法を調整できます:
Vault(保管庫): ドロップダウンメニューをクリックして他のObsidianライブラリを選択できます
Path(パス): ドロップダウンメニューをクリックしてエクスポートされた会話ノートを保存するフォルダを選択できます
Obsidianノートのプロパティ(Properties)として:
タグ(tags)
作成時間(created)
出典(source)
Obsidianへのエクスポートにおける処理方法には、以下の3つのオプションがあります:
新規作成(存在する場合は上書き): Pathで指定したフォルダに新しい会話ノートを作成し、同じ名前のノートが存在する場合は古いノートを上書きします
先頭に追加: 同じ名前のノートが既に存在する場合、選択した会話内容をエクスポートしてそのノートの先頭に追加します
末尾に追加: 同じ名前のノートが既に存在する場合、選択した会話内容をエクスポートしてそのノートの末尾に追加します
すべてのオプションを選択したら、「確定」をクリックすると、完全な会話が対応するObsidianライブラリの対応フォルダにエクスポートされます。
単一会話をエクスポート
単一会話をエクスポートするには、会話の下にある_三本線メニュー_をクリックし、_エクスポート_を選択して、_Obsidianにエクスポート_をクリックします:
その後、完全な会話をエクスポートする場合と同じウィンドウがポップアップし、ノートプロパティとノートの処理方法を設定するよう求められます。同じくに従って完了してください。
🎉 これで、Cherry StudioとObsidianの連携設定がすべて完了し、エクスポート手順を最初から最後まで実行しました。お楽しみください!
Obsidianライブラリを開き、エクスポートされた会話を保存するためのフォルダを作成します(図ではCherry Studioフォルダを例としています):
左下角に枠で囲まれたテキストに注意してください。これがあなたの保管庫名です。
Cherry Studioの_設定_ → データ設定 → _Obsidian設定_メニューで、で取得した保管庫名とフォルダ名を入力します:
グローバルタグはオプションで、すべての会話をエクスポートした後、Obsidian内でのタグを設定できます。必要に応じて記入してください。
完全な会話をエクスポート
Cherry Studioの会話インターフェースに戻り、会話を右クリックして_エクスポート_を選択し、_Obsidianにエクスポート_をクリックします。
ポップアップウィンドウが表示され、Obsidianにエクスポートするこの会話ノートの Properties(属性)とエクスポート時の処理方法を調整できます。Obsidianへのエクスポートにおける処理方法には、以下の3つのオプションがあります:
新規作成(存在する場合は上書き): で指定したフォルダに新しい会話ノートを作成し、同じ名前のノートが存在する場合は古いノートを上書きします
先頭に追加: 同じ名前のノートが既に存在する場合、選択した会話内容をエクスポートしてそのノートの先頭に追加します
末尾に追加: 同じ名前のノートが既に存在する場合、選択した会話内容をエクスポートしてそのノートの末尾に追加します
単一会話をエクスポート
単一会話をエクスポートするには、会話の下にある_三本線メニュー_をクリックし、_エクスポート_を選択して、_Obsidianにエクスポート_をクリックします。
その後、完全な会話をエクスポートする場合と同じウィンドウがポップアップし、ノートプロパティとノートの処理方法を設定するよう求められます。同じくに従って完了してください。
🎉 これで、Cherry StudioとObsidianの連携設定がすべて完了し、エクスポート手順を最初から最後まで実行しました。お楽しみください!
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
# ナレッジベース
ナレッジベースの使用方法については、上級チュートリアル内の[ナレッジベースチュートリアル](../../knowledge-base/knowledge-base.md)を参照してください。---
icon: cherries
---
# 設定{% hint style="danger" %}
注意:Gemini画像生成は対話インターフェイスで使用する必要があります。Geminiはマルチモーダルでインタラクティブな画像生成を行い、パラメータ調整もサポートしていません。
{% endhint %}













このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
このインターフェースでは、データのローカルおよびクラウドバックアップ・復元、ローカルデータディレクトリの確認・キャッシュクリア、エクスポート設定、サードパーティ接続などの操作が可能です。
データバックアップには現在、ローカルバックアップ、WebDAVバックアップ、S3互換ストレージ(オブジェクトストレージ)バックアップの3つの方法をサポートしています。詳細な説明とチュートリアルは以下のドキュメントをご参照ください:
エクスポート設定では、エクスポートメニューに表示されるエクスポートオプションの設定や、Markdownエクスポートのデフォルトパス、表示スタイルなどを設定できます。
サードパーティ接続では、Cherry Studioとサードパーティアプリケーションを接続し、チャット内容を素早く使い慣れたナレッジ管理アプリにエクスポートすることができます。現在サポートされているアプリケーションは:Notion、Obsidian、思源笔记、语雀、Joplinです。具体的な設定方法は以下のドキュメントをご参照ください:
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
アシスタントがデフォルトのアシスタントモデルを設定していない場合、新しい会話でデフォルトで選択されるモデルはここで設定されたモデルです。 プロンプト最適化やテキスト選択アシスタントでも、この設定が使用されます。
各会話終了後に、会話のトピック名を生成するために呼び出されるモデルです。ここで設定されたモデルが命名時に使用されます。
会話やAI絵画などの入力ボックスでの翻訳機能、翻訳インターフェースで使用される翻訳モデルは、すべてここで設定されたモデルが使用されます。
クイックアシスタント機能で使用されるモデルです。詳細は クイックアシスタント を参照してください。
暂时不支持Claude模型
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
GeminiのAPI Keyを取得する前に、Google Cloudプロジェクトが必要です(既にお持ちの場合はこの手順をスキップ可)
Google Cloudでプロジェクトを作成し、プロジェクト名を入力して「プロジェクトを作成」をクリック
Vertex AIコンソールにアクセス
作成したプロジェクトでVertex AI APIを有効化
サービスアカウント権限ページでサービスアカウントを作成
サービスアカウント管理ページで作成したアカウントを選択し、「鍵」をクリックして新規JSON形式鍵を作成
作成成功後、鍵ファイルがJSON形式で自動的にPCに保存されます。必ず安全に保管してください
Vertex AIプロバイダを選択
JSONファイルの対応するフィールドに入力
モデルを追加をクリックすると、すぐに使い始められます!
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
ナレッジベース文書の前処理を行うには、Cherry Studioをv1.4.8以降にアップグレードする必要があります。
「API KEYを取得」をクリックすると申請ページが表示されます。「今すぐ申請」をクリックしてフォームを記入し、発行されたAPI KEYを設定画面に入力します。
作成済みのナレッジベースで上記の設定を行うことで、文書前処理の設定が完了します。
右上の検索機能でナレッジベースの結果確認が可能
ナレッジベース利用Tips: 能力の高いモデルを使用する場合、検索モードを「意図認識」に変更すると、質問内容をより正確かつ広範に解釈できます。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
トピックやメッセージを思源ノートにエクスポートすることができます。
思源ノートを開き、新しいノートブックを作成します
ノートブックの設定を開き、ノートブックIDをコピーします
コピーしたノートブックIDを Cherry Studio の設定に貼り付けます
思源ノートのアドレスを入力します
ローカル環境
通常は http://127.0.0.1:6806
自己ホスティング
あなたのドメイン http://note.domain.com
思源ノートの APIトークン をコピーします
Cherry Studio の設定に貼り付けて確認します
おめでとうございます。思源ノートの設定が完了しました ✅ これでCherry Studioの内容をあなたの思源ノートにエクスポートすることができます
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
ログインし、トークンページに進む
新しいトークンを作成(または既存のdefaultトークン↑を直接使用可)
トークンをコピー
CherryStudioのプロバイダ設定を開き、プロバイダリスト最下部の追加をクリック
表示名を入力後、プロバイダでOpenAIを選択し[確定]をクリック
コピーしたキーを入力
API Key取得ページに戻り、ブラウザのアドレスバーからルートアドレスをコピー(例):
モデルを追加([管理]で自動取得/手動入力)し右上トグルを有効化
OneAPIのテーマによってインターフェースが異なる場合がありますが、追加手順は上記と同様です。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
保持した要素:
マークダウン構造(#見出し、画像タグ、リンク構文)
技術用語(Cherry Studio, ベクトルデータベース, 埋め込みモデル, LLM)
URLとファイルパス(https://turso.tech/libsql, ../.gitbook/assets/...)
画像の代替テキストとキャプション(alt属性は空、キャプションのみ翻訳)
コードブロックではないため全テキストを翻訳
図の説明文「知識庫処理フローチャート」→「ナレッジベース処理フローチャート」に自然変換
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studioは、手動設定とフィード購読の2通りの方法でブラックリストを設定できます。設定ルールはを参照してください。
検索結果にルールを追加するか、ツールバーアイコンをクリックして特定のサイトをブロックできます。ルールは以下の方法で指定可能です:(例: *://*.example.com/*) または(例: /example\.(net|org)/)。
パブリックなルールセットを購読することも可能です。購読可能なリストは以下のサイトで公開されています: https://iorate.github.io/ublacklist/subscriptions
以下におすすめの購読リンクを紹介します:
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
MCPサービスの自動インストール(ベータ版)
ローカルナレッジグラフベースの持続的メモリ基盤の実装。これにより、モデルは異なる会話間でユーザーの関連情報を記憶できます。
構造化された思考プロセスを通じて動的かつ反射的な問題解決を可能にするツールを提供するMCPサーバーの実装。
Brave検索APIを統合したMCPサーバーの実装で、ウェブ検索とローカル検索の両機能を提供します。
URLのウェブコンテンツを取得するためのMCPサーバー。
ファイルシステム操作を実装するモデルコンテキストプロトコル(MCP)のNode.jsサーバー。
# データストレージ説明
Cherry Studioのナレッジベースに追加されたデータはすべてローカルに保存され、追加プロセスでドキュメントのコピーがCherry Studioデータストレージディレクトリに保管されます。
<figure><img src="../.gitbook/assets/mermaid-diagram-1739241680067.png" alt=""><figcaption><p>ナレッジベース処理フローチャート</p></figcaption></figure>
ベクトルデータベース:[https://turso.tech/libsql](https://turso.tech/libsql)
ドキュメントがCherry Studioナレッジベースに追加されると、ファイルは複数の断片に分割され、これらの断片が埋め込みモデルによって処理されます
大規模言語モデルを使用した質問応答時には、質問に関連するテキスト断片を検索して大規模言語モデルに渡します
データプライバシーに要件がある場合は、ローカルの埋め込みデータベースとローカルの大規模言語モデルを利用することを推奨しますMEMORY_FILE_PATH=/path/to/your/file.jsonBRAVE_API_KEY=YOUR_API_KEY















https://git.io/ublacklist
中国語(中国語)
https://raw.githubusercontent.com/laylavish/uBlockOrigin-HUGE-AI-Blocklist/main/list_uBlacklist.txt
AI生成








mcp-server-time
--local-timezone
<あなたの標準タイムゾーン、例:Asia/Shanghai>











このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studioは無料のオープンソースプロジェクトであり、プロジェクトが成長するにつれて開発チームの作業負荷も増加しています。コミュニケーションコストを削減し、皆様の問題を迅速かつ効率的に解決するため、質問する前に以下の手順に従って問題に対処いただき、チームがプロジェクトのメンテナンスと開発に集中できる時間を確保していただきますようお願いします。ご協力に感謝いたします。
ほとんどの基本的な問題は、ドキュメントを注意深く確認することで解決できます。
ソフトウェアの機能や使用方法に関する問題は機能紹介ドキュメントをご確認ください。
よくある質問はよくある質問ページにまとめていますので、まず解決策があるかどうか確認してください。
複雑な問題は、検索または検索ボックスで質問することで直接解決できます。
各ドキュメントのヒントボックスを必ず注意深くお読みください。これにより多くの問題を回避できます。
GitHubのIssueページで類似の問題や解決策があるかどうか確認または検索してください。
モデルの使用などクライアント機能に関係ない問題(モデルエラー、期待通りの回答が得られない、パラメータ設定など)については、まずWebで関連する解決策を検索するか、エラー内容と問題をAIに説明して解決策を探すことをお勧めします。
上記の手順1・2で答えが見つからなかった場合や問題が解決しない場合は、公式tgチャンネル、Discordチャンネル、(ワンクリック参加)で問題を詳細に説明し、助けを求めてください。
モデルエラーの場合:画面全体のスクリーンショットとコンソールのエラー情報を提供してください。機密情報はマスク処理できますが、モデル名、パラメータ設定、エラー内容はスクリーンショットに残しておいてください。コンソールエラー情報の確認方法はこちらをご覧ください。
ソフトウェアのバグの場合:具体的なエラーの説明と詳細な再現手順を提供し、開発者がデバッグや修正を行いやすくしてください。偶発的な問題で再現できない場合は、問題発生時の関連シナリオ、背景、設定パラメータなどを可能な限り詳細に説明してください。また、プラットフォーム情報(Window、MacまたはLinux)、ソフトウェアバージョン番号なども問題説明に含めてください。
ドキュメントのリクエストや提案
tgチャンネル @Wangmouuu、QQ(1355873789)、またはメール:[email protected] までご連絡ください。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Telegram 討論グループでヘルプを入手:https://t.me/CherryStudioAI
Github Issues:https://github.com/CherryHQ/cherry-studio/issues/new/choose
開発者へのメール連絡:[email protected]
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studio(以下「本ソフトウェア」または「当社」といいます)をご利用いただきありがとうございます。当社はユーザーのプライバシー保護を重視しており、本ポリシーは当社がお客様の個人情報とデータをどのように取り扱い保護するかを説明します。本ソフトウェアをご利用になる前に、本ポリシーをよくお読みください。
ユーザーエクスペリエンスの最適化およびソフトウェア品質向上のため、当社は以下の匿名化された非個人情報のみを収集する可能性があります:
• ソフトウェアバージョン情報; • ソフトウェア機能の利用頻度、活性度; • 匿名化されたクラッシュ・エラーログ情報;
上記情報は完全に匿名化され、個人を特定できるデータを含まず、お客様の個人情報と紐付けることもできません。
ユーザーのプライバシー保護を最大化するため、当社は以下の情報を厳格に取り扱わないことを明示します:
• 本ソフトウェアに入力されたモデルサービスAPIキー情報を収集・保存・送信・処理しません; • 本ソフトウェア利用中に生成されるいかなる対話データ(チャット内容、指示情報、ナレッジベース情報、ベクトルデータ、カスタムコンテンツ等を含む)も収集・保存・送信・処理しません; • 個人を特定できる機微情報を一切収集・保存・送信・処理しません。
本ソフトウェアは、ユーザー自身が申請・設定したサードパーティ製モデルサービスプロバイダーのAPIキーを使用して、関連モデルの呼び出しと対話機能を実現します。利用されるモデルサービス(大規模言語モデル、APIインターフェース等)はユーザーが選択したサードパーティプロバイダーが提供し、その責任を完全に負います。Cherry Studioはあくまでローカルツールとして、サードパーティモデルサービスとの連携機能を提供するものです。
従って:
• 大規模モデルサービスとの対話で生成される全データはCherry Studioに関与せず、当社はデータ保存に参与せず、いかなる形式のデータ転送・中継も行いません; • 対応するサードパーティプロバイダーのプライバシーポリシーについては、各プロバイダー公式サイトでご確認ください。
サードパーティモデルサービス利用に伴うプライバシーリスクはユーザー自身が負担します。具体的なプライバシー対策、データセキュリティ措置および関連責任については、利用プロバイダーの公式規約をご参照ください。当社はこれらについて一切の責任を負いません。
本ポリシーはソフトウェアアップデートに伴い適宜改訂される可能性があります。定期的なご確認をお願いします。実質的な変更が発生した場合、当社は適切な方法で通知します。
本ポリシー内容またはCherry Studioのプライバシー保護措置についてご質問がある場合は、お気軽にお問い合わせください。
Cherry Studioをご選択・ご信頼いただき感謝申し上げます。今後も安全で信頼性の高い製品体験を提供してまいります。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
このページではインターフェース機能についてのみ紹介しています。設定チュートリアルについては、基本チュートリアルのプロバイダー構成を参照してください。
Cherry Studio では、単一のプロバイダーが複数のキーをローテーション方式で使用でき、ローテーションはリストの先頭から末尾へ循環する方法で行われます。
複数のキーを追加する際は、英語のカンマで区切ります。以下の例の形式で入力します:
sk-xxxx1,sk-xxxx2,sk-xxxx3,sk-xxxx4必ず 英語 のカンマを使用してください。
組み込みプロバイダーを使用する際は、通常APIアドレスを入力する必要はありません。変更が必要な場合は、対応する公式ドキュメントに記載されているアドレスを厳密に従って入力してください。
プロバイダーから提供されたアドレスが https://xxx.xxx.com/v1/chat/completions という形式である場合、ルートアドレス部分(https://xxx.xxx.com)のみ入力すればよいです。
Cherry Studio が自動的に残りのパス(/v1/chat/completions)を追加します。指示通りに入力しないと正常に使用できない可能性があります。
通常、プロバイダー設定ページの左下隅の管理ボタンをクリックすると、そのプロバイダーがサポートするすべての呼び出し可能なモデルが自動的に取得されます。取得したリストから+アイコンをクリックしてモデルリストに追加します。
APIシークレットキー入力ボックスの後のチェックボタンをクリックすると、設定が成功したかどうかをテストできます。
設定が成功したら、必ず右上のスイッチをオンにしてください。そうしないと、このプロバイダーは引き続き無効状態のままであり、モデルリストで対応するモデルを見つけることができません。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
クイックアシスタントは、Cherry Studio が提供する便利なツールです。あらゆるアプリケーション内からAI機能に素早くアクセスし、即時質問、翻訳、要約、解説などの操作を可能にします。
設定を開く: 設定 > ショートカット > クイックアシスタントに移動します。
トグルを有効化: クイックアシスタントの対応するボタンをオンにします。
ショートカットキーの設定(任意):
Windows デフォルト: Ctrl + E
macOS デフォルト: ⌘ + E
競合の回避や使用習慣に合わせてカスタマイズ可能です。
呼び出し: 任意のアプリケーションで設定済みのショートカットキー(またはデフォルト)を押します。
操作: クイックアシスタントウィンドウで直接実行可能な操作:
クイック質問: AIに任意の質問
テキスト翻訳: 翻訳対象テキストの入力
コンテンツ要約: 長文テキストの要約
概念説明: 説明が必要な概念や用語の入力
終了: ESCキーを押すか、ウィンドウ外をクリックします。
ショートカットキーの競合: 他アプリケーションと競合する場合は変更推奨
機能の探索: ドキュメント記載機能以外に、コード生成やスタイル変換などが可能な場合があります
フィードバック: 問題発生時や改善提案はCherry Studioチームへフィードバックしてください
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
阿里云百炼にログインしてください。アカウントをお持ちでない場合は登録が必要です。
右上の 创建我的 API-KEY ボタンをクリックしてください。
ポップアップウィンドウで、デフォルトの業務スペースを選択します(カスタマイズも可能です)。必要に応じて説明を入力できます。
右下の 确定 ボタンをクリックしてください。
リストに新規行が追加されるので、右側の 查看 ボタンをクリックしてください。
复制 ボタンをクリックします。
Cherry Studioで 设置 → 模型服务 → 阿里云百炼 を選択し、API 密钥 欄にコピーしたAPIキーを貼り付けます。
モデルサービスの説明に従って設定を調整し、使用を開始してください。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Gemini の API キーを取得する前に、Google Cloud プロジェクトが必要です(すでに所有している場合、この手順はスキップできます)。
Google Cloud にアクセスし、プロジェクトを作成します。プロジェクト名を入力し、「プロジェクトを作成」をクリックしてください。
公式の API Keyページ で、鍵 APIキーを作成 をクリックしてください。
生成されたキーをコピーし、CherryStudio の サービスプロバイダ設定 を開いてください。
サービスプロバイダ Gemini を選択し、取得したキーを入力してください。
最下部の「管理」または「追加」をクリックし、サポートされているモデルを追加し、右上のサービスプロバイダスイッチをオンにすると、使用可能になります。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
MCP(Model Context Protocol) は、大規模言語モデル(LLM)に標準化された方法でコンテキスト情報を提供することを目的としたオープンソースプロトコルです。MCPの詳細についてはを参照してください。
以下はfetch機能を例に、Cherry StudioでMCPを使用する方法をデモンストレーションします。詳細はドキュメントでご確認ください。
設定 - MCPサーバーでインストールボタンをクリックすると、自動的にダウンロードとインストールが行われます。GitHubから直接ダウンロードするため、速度が遅かったり失敗する可能性があります。インストールが成功したかどうかは、後述するフォルダにファイルが存在するかで確認してください。
実行可能ファイルのインストールディレクトリ:
Windows: C:\Users\ユーザー名\.cherrystudio\bin
macOS、Linux: ~/.cherrystudio/bin
正常にインストールできない場合:
システム内の対応するコマンドをシンボリックリンクでこのディレクトリにリンクすることができます。ディレクトリが存在しない場合は手動で作成してください。または手動で実行可能ファイルをダウンロードし、このディレクトリに配置することも可能です:
Bun: https://github.com/oven-sh/bun/releases UV: https://github.com/astral-sh/uv/releases
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
アシスタント は、選択したモデルをカスタマイズするための設定です。プロンプトのプリセットやパラメーターのプリセットなど、これらの設定により、選択したモデルが期待通りに動作するよう調整されます。
システムデフォルトのアシスタント は、比較的汎用的なパラメーター(プロンプトなし)をプリセットしています。直接使用するか、 で必要なプリセットを探して使用できます。
アシスタント は トピック の親集合です。1つのアシスタントの下に複数のトピック(つまり対話)を作成でき、すべての トピック は アシスタント のパラメーター設定やプリセットされたプロンプトなどのモデル設定を共有します。
新規トピック: 現在のアシスタント内に新しいトピックを作成します。
画像またはドキュメントをアップロード: 画像のアップロードはモデルのサポートが必要です。ドキュメントのアップロードは自動的にテキストに解析され、モデルにコンテキストとして提供されます。
ウェブ検索: 設定でウェブ検索関連情報を構成する必要があります。検索結果はコンテキストとして大規模モデルに返されます。詳細は をご覧ください。
ナレッジベース: ナレッジベースを有効にします。詳細は をご覧ください。
MCP サーバー: MCP サーバー機能を有効にします。詳細は をご覧ください。
画像を生成: デフォルトでは表示されません。画像生成をサポートするモデル(例: Gemini)の場合、手動でアイコンをタップして有効にする必要があります。
モデルを選択: 次の対話で、指定したモデルに切り替え、コンテキストを保持します。
クイックフレーズ: 設定で事前に一般的なフレーズをプリセットし、ここで呼び出して直接入力します。変数をサポートします。
メッセージをクリア: このトピックの下のすべての内容を削除します。
拡大: 対話ボックスを大きくして、長文の入力を可能にします。
コンテキストをクリア: 内容を削除せずに、モデルが取得できるコンテキストを切り詰めます。つまり、モデルは以前の対話内容を「忘れ」ます。
推定トークン数: 推定トークン数を表示します。4つのデータはそれぞれ 現在のコンテキスト数、最大コンテキスト数(∞ は無制限のコンテキストを意味)、現在の入力ボックス内のメッセージ数、推定トークン数 です。
翻訳: 現在の入力ボックス内の内容を英語に翻訳します。
モデル設定はアシスタント設定の モデル設定 パラメーターと同期します。詳細は をご覧ください。
メッセージ区切り線:
区切り線を使用して、メッセージ本文と操作バーを分離します。
セリフ体フォントを使用:
フォントスタイルを切り替えます。現在は でフォントを変更することもできます。
コードに行番号を表示:
モデル出力のコードスニペットにコードブロックの行番号を表示します。
コードブロックを折り畳み可能:
オンにすると、コードスニペットが長い場合、自動的にコードブロックが折り畳まれます。
コードブロックを折り返し可能:
オンにすると、コードスニペットの1行が長い場合(ウィンドウを超える)、自動的に折り返されます。
思考内容を自動折り畳み:
オンにすると、思考をサポートするモデルで思考が完了した後、思考プロセスが自動的に折り畳まれます。
メッセージスタイル:
対話インターフェースをバブルスタイルまたはリストスタイルに切り替えられます。
コードスタイル:
コードスニペットの表示スタイルを切り替えます。
数式レンダリングエンジン:
KaTeX: レンダリング速度が速く、パフォーマンス最適化用に設計されています。
MathJax: レンダリングが遅いですが、より多くの数学記号とコマンドをサポートし、機能が豊富です。
メッセージフォントサイズ:
対話インターフェースのフォントサイズを調整します。
推定トークン数を表示:
入力ボックスに入力テキストで推定消費されるトークン数を表示します(実際のコンテキスト消費トークンではなく、参考用です)。
長いテキストをファイルとして貼り付け:
他の場所から長いテキストをコピーして入力ボックスに貼り付けると、自動的にファイルスタイルで表示され、後続の入力の妨げを減らします。
入力メッセージをMarkdownでレンダリング:
オフの場合、モデルの応答メッセージのみをレンダリングし、送信メッセージはレンダリングしません。
スペースを3回素早く連打して翻訳:
対話インターフェースの入力ボックスでメッセージを入力した後、スペースを3回連続で連打すると、入力内容を英語に翻訳します。
注意:この操作は原文を上書きします。
ターゲット言語:
入力ボックスの翻訳ボタンとスペース3回連打翻訳のターゲット言語を設定します。
アシスタントインターフェースで設定するアシスタント名を選択→右クリックメニューで対応する設定を選択
プロンプト設定
名称:
便利に識別できるようにアシスタント名をカスタマイズできます。
プロンプト:
プロンプトのことです。エージェントページのプロンプトの書き方を参照して内容を編集できます。
モデル設定
デフォルトモデル:
このアシスタントにデフォルトモデルを固定できます。エージェントページから追加するか、アシスタントをコピーする場合、初期モデルがこのモデルになります。この項目を設定しない場合、初期モデルはグローバル初期モデル(つまり )になります。
モデルを自動リセット:
オン時 – そのトピックの使用中に他のモデルに切り替えた場合、新規トピックを作成すると新規トピックのモデルがアシスタントのデフォルトモデルにリセットされます。オフ時は、新規トピックのモデルは前のトピックで使用したモデルを引き継ぎます。
例:アシスタントのデフォルトモデルが gpt-3.5-turbo の場合、そのアシスタントの下でトピック1を作成し、トピック1の対話中に gpt-4o に切り替えた場合:
自動リセットが有効:新規トピック2を作成すると、トピック2のデフォルト選択モデルは gpt-3.5-turbo;
自動リセットが無効:新規トピック2を作成すると、トピック2のデフォルト選択モデルは gpt-4o。
温度 (Temperature) :
温度パラメーターは、モデルが生成するテキストのランダム性と創造性を制御します(デフォルト値 0.7)。具体的には:
低温度値(0-0.3):
出力がより確定的で集中したものになる
コード生成、データ分析など精度が必要なシナリオに適する
最も確率の高い単語を選択する傾向がある
中程度温度値(0.4-0.7):
創造性と一貫性のバランスが取れる
日常会話、一般的な執筆に適する
チャットボット対話に推奨 (0.5 前後)
高温度値(0.8-1.0):
より創造的で多様性のある出力を生成
創造的執筆、ブレインストーミングなどのシナリオに適する
ただし、テキストの一貫性が低下する可能性あり
Top P (核サンプリング):
デフォルト値は 1。値が小さいほど、AI が生成する内容は単調になり、理解しやすくなります。値が大きいほど、AI の応答の語彙範囲が広がり、多様性が増します。
核サンプリングは、単語選択の確率しきい値を制御して出力に影響します:
小さい値(0.1-0.3):
最高確率の単語のみを考慮
出力が保守的で制御可能
コードコメント、技術文書などのシナリオに適する
中程度値(0.4-0.6):
単語多様性と精度のバランス
一般的な対話や執筆タスクに適する
大きい値(0.7-1.0):
より広範な単語選択を考慮
より豊富で多様な内容を生成
表現の多様性が必要な創造的執筆などに適する
コンテキスト数 (Context Window)
コンテキストに保持するメッセージの数。値が大きいほど、コンテキストが長くなり、消費されるトークンが増えます:
5-10:通常の対話に適する
>10:より長いメモリが必要な複雑なタスク(例:執筆アウトラインに沿って段階的に長文を生成するタスクで、生成されたコンテキストの論理的一貫性を確保
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
以下の経験はありませんか:WeChatに保存した26本の有益記事はその後開かれることがなく、PCに散らばる「学習資料」フォルダ内の10以上のファイル、半年前に読んだ理論を探したいのに数個のキーワードしか覚えていない。そして日々の情報量が脳の処理限界を超えると、貴重な知識の90%が72時間以内に忘却されます。 今、Infinite Core大規模モデルプラットフォームAPI + Cherry Studioで構築する個人ナレッジベースなら、WeChat記事や断片的な教材を構造化知識に変換し、精密な呼び出しを実現できます。
1. Infinite Core APIサービス:「思考中枢」として使いやすく安定
ナレッジベースの「思考中枢」として、Infinite Core大規模モデルプラットフォームはDeepSeek R1フルスペック版などのモデルを提供し、安定したAPIサービスを提供。現在登録後は無条件・無料で利用可能。主流の埋め込みモデルbge・jinaモデルでのナレッジベース構築をサポートし、プラットフォームは最新・最強のオープンソースモデルサービスを継続的に更新。画像・動画・音声などマルチモーダル対応。
2. Cherry Studio:ノーコードで構築可能
Cherry Studioは使いやすいAIツール。RAGナレッジベース開発に1~2ヶ月かかるのに対し、本ツールはノーコード操作を特長。Markdown/PDF/Webページなどをワンクリックでインポート可能(40MBファイルは1分で解析)。PCのローカルフォルダ・WeChat保存記事URL・講義ノートも追加可能です。
Step 1:基本準備
Cherry Studio公式サイトからOS対応版をダウンロード(https://cherry-ai.com/)
アカウント登録:Infinite Core大規模モデルプラットフォームにログイン(https://cloud.infini-ai.com/genstudio/model?cherrystudio)
APIキー取得:「モデル広場」でdeepseek-r1を選択→作成クリックでAPIKEYを生成→モデル名をコピー
Step 2:CherryStudio設定で「モデルサービス」にInfinite Coreを選択し、APIキーを入力して有効化
上記完了後、使用時に大規模モデルを選択すればCherryStudioからInfinite Core APIを利用可能。 利便性向上のため「デフォルトモデル」設定を推奨
Step 3:ナレッジベース追加
Infinite Coreプラットフォームの埋め込みモデルからbgeシリーズまたはjinaシリーズの任意バージョンを選択
学習資料インポート後、「『機械学習』第3章の核心公式導出を整理」と入力
▼生成結果例
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
にログイン
ここを
サイドバーの下にある をクリック
APIキーを作成
作成が成功したら、作成したAPIキーの隣にある目のアイコンをクリックして表示し、コピー
コピーしたAPIキーをCherry Studioに入力後、プロバイダーのスイッチをオンにする
方舟コンソールのサイドバーの一番下にあるで、必要なモデルを有効化(豆包シリーズやDeepSeekなど)
で、必要なモデルの対応するモデルIDを確認
Cherry Studioの設定で火山エンジンを選択
「追加」をクリックし、取得したモデルIDをモデルID欄にペースト
この手順で各モデルを順次追加
APIエンドポイントの記述方法は2種類あります:
クライアントデフォルト:https://ark.cn-beijing.volces.com/api/v3/
別の記述方法:https://ark.cn-beijing.volces.com/api/v3/chat/completions#
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studio はトピックを Notion データベースにインポートすることをサポートしています。
ウェブサイト を開き、アプリケーションを作成します
アプリケーションを作成します
名前:Cherry Studio
タイプ:最初のオプションを選択
アイコン:この画像を保存してください
秘密鍵をコピーして Cherry Studio の設定に記入します
ウェブサイトを開き、新しいページを作成し、下の方でデータベースタイプを選択します。名前には Cherry Studio と記入し、図のように操作して接続します
Notion データベースの URL が以下のようになっている場合:
https://www.notion.so/<long_hash_1>?v=<long_hash_2>
Notion データベース ID は <long_hash_1> の部分です
ページタイトルフィールド名 を記入してください:
ウェブページが英語の場合は Name と記入
ウェブページが中国語の場合は 名称 と記入
おめでとうございます、Notion の設定が完了しました ✅ これで Cherry Studio のコンテンツをあなたの Notion データベースにエクスポートできるようになります
如何注册tavily?
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
上記公式サイトにアクセスするか、cherry studioの[設定]→[ネットワーク検索]→[APIキーを取得]をクリックすると、tavilyのログイン/登録ページに直接ジャンプします。
初めてご利用の場合は、まず(Sign up)でアカウントを登録してから、ログイン(Log in)して使用してください。デフォルトではログインページにジャンプします。
[アカウント登録]をクリックし、以下の画面で普段使っているメールアドレスを入力するか、Google/GitHubアカウントで登録し、次のステップでパスワードを設定します(通常の手順です)。
🚨🚨🚨【重要ステップ】 登録成功後、動的認証コードのステップが発生します。QRコードをスキャンしてワンタイムコードを生成する必要があります。
解決方法は2つあります:
Microsoft製の認証アプリ「Authenticator」をダウンロード【やや面倒】
WeChatミニプログラム「腾讯身份验证器(Tencent認証ツール)」を使用【簡単・おすすめ】
WeChatミニプログラムで「腾讯身份验证器」を検索
上記手順完了後、以下の画面が表示されれば登録成功です。APIキーをコピーしてcherry studioに貼り付ければ、すぐに使い始められます。
































































このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
本契約書に定義されるCherry Studioの素材(一部または全部)を利用または配布することにより、利用者は本契約の内容を承諾し、本契約は直ちに発効するものと見なされます。
本Cherry Studioライセンス契約(以下「契約」)は、素材の利用、複製、配布および変更に関する条項を定義します。
「当社」(または「弊社」)とは、上海千彗科技有限公司を指します。
「利用者」(または「貴社」)とは、本契約で付与される権利を行使し、および/またはあらゆる目的および利用分野で素材を使用する自然人または法人を指します。
「第三者」とは、当社または利用者のいずれとも支配関係にない個人または法人を指します。
「Cherry Studio」とは、本ソフトウェアスイートを指し、[例:コアライブラリ、エディタ、プラグイン、サンプルプロジェクト]を含みますがこれらに限定されず、ソースコード、ドキュメント、サンプルコードおよび当社が配布する上記要素で構成されます。(実際の構成に基づき詳細を記述)
「素材」とは、上海千彗科技有限公司の専有物であるCherry Studioとドキュメント(その一部を含む)の総称で、本契約に基づき提供されるものを指します。
「ソース形式」とは、変更を加えるのに最適な形式を指し、ソースコード、ドキュメントソースファイル、設定ファイルなどを含みますがこれらに限定されません。
「ターゲット形式」とは、ソース形式を機械変換または翻訳して生成される形式を指し、コンパイル済みオブジェクトコード、生成ドキュメント、他メディアタイプへ変換した形式などを含みますがこれらに限定されません。
「商用利用」とは、直接的または間接的な商業的利益または優位性を目的とする利用を指し、販売、ライセンス、サブスクリプション、広告、マーケティング、トレーニング、コンサルティングサービスなどを含みますがこれらに限定されません。
「改変」とは、アプリケーション名、ロゴ、コード、機能、インターフェースなどを含みますがこれらに限定されない、素材のソース形式に対する変更、調整、派生物作成または二次開発を指します。
無償商用利用(未改変コードに限定):当社は、当社が保有する素材に組み込まれた知的財産権その他の権利に基づき、非独占的、全世界規模、譲渡不可、ロイヤリティフリーのライセンスを付与します。これにより利用者は、未改変の素材を商用利用を含め利用、複製、配布、コピーできますが、本契約の条項に従う必要があります。
商用ライセンス(必要な場合):第3条「商用ライセンス」の条件を満たす場合、利用者は本契約の権利を行使するために当社から明示的な書面による商用ライセンスを取得する必要があります。
以下のいずれかに該当する場合、利用者はCherry Studio素材を引き続き使用する前に当社に連絡し明示的な書面による商用ライセンスを取得する必要があります:
改変と派生物:Cherry Studio素材を改変、または素材に基づいた派生物を開発する場合(アプリケーション名、ロゴ、コード、機能、インターフェースなどの変更を含む)。
企業向けサービス:利用者の組織内、または企業顧客に対してCherry Studioベースのサービスを提供し、かつ10人以上の累積ユーザーをサポートする場合。
ハードウェア同梱販売:Cherry Studioをハードウェアデバイスまたは製品にプリインストール/統合して同梱販売する場合。
政府/教育機関の大規模調達:利用シーンが政府または教育機関の大規模調達プロジェクトであり、特にセキュリティ、データプライバシーなどの機密性の高い要件を含む場合。
公開クラウドサービス:Cherry Studioを基盤に公衆向けクラウドサービスを提供する場合。
利用者は未改変の素材コピーを配布、または未改変素材を含む製品/サービスの一部として提供できます(ソース形式またはターゲット形式)。ただし以下の条件を満たす必要があります:
素材の受領者全員に本契約のコピーを提供すること。
配布する全素材コピーに以下の帰属表示を保持し、「NOTICE」または類似のテキストファイルに記載すること:
"Cherry Studio is licensed under the Cherry Studio LICENSE AGREEMENT, Copyright (c) 上海千彗科技有限公司. All Rights Reserved."
素材は輸出規制の対象となる可能性があります。利用者は素材を使用する際に適用される法令を遵守する責任があります。
素材またはその出力結果を使用して配布/提供されるソフトウェアまたはモデルを作成/訓練/微調整/改善する場合、関連製品ドキュメントに「Built with Cherry Studio」または「Powered by Cherry Studio」を明示することを推奨します。
当社は素材および当社が作成した派生物に関する全知的財産権の所有権を留保します。本契約の条項に従うことを条件に、利用者が作成した素材の改変物/派生物の知的財産権帰属は商用ライセンス契約で定めます。商用ライセンスを取得せずに作成した改変物/派生物の所有権は利用者に帰属せず、当社が保有します。
商号、商標、サービスロゴ、製品名の使用は、本契約の通知義務履行または素材の合理的な説明/再配布に必要な範囲を除き、一切認められません。
素材/その出力の全体または一部が利用者またはライセンサーの知的財産権を侵害すると主張する訴訟/法的手続きを提起した場合、本契約に基づく全ライセンスは当該手続開始時点で終了します。
当社はCherry Studio素材のサポート、更新、トレーニング提供、バージョンアップ開発義務を負いません。
素材は「現状有姿」で提供され、商品性、非侵害性、特定目的適合性の黙示的保証を含む一切の保証を伴いません。素材およびその出力の安全性/安定性について保証せず、一切の責任を負いません。
いかなる場合も、素材(またはその出力)の使用/不能使用に起因する損害(直接的/間接的/特別損害または結果損害を含む)について一切の責任を負いません。
利用者の素材使用/配布に起因する第三者からの請求から当社を防御し、賠償責任を負います。
本契約は利用者が契約を承諾または素材にアクセスした時点で効力を生じ、本契約の条項に基づき終了するまで有効です。
契約条項に違反した場合、当社は本契約を終了できます。契約終了後は直ちに素材の使用を停止する必要があります。第7条、第9条および「二. コントリビューター契約」は終了後も効力を有します。
本契約および本契約に起因する紛争は中華人民共和国法の適用を受けます。
本契約に起因する紛争については上海市人民法院が専属的管轄権を有します。

このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studioのデータバックアップは、WebDAV方式によるバックアップをサポートしています。適切なWebDAVサービスを選択してクラウドバックアップを行えます。
WebDAVを使用すると、Aコンピュータ WebDAV Bコンピュータ の方法で、複数のデバイス間のデータ同期を実現できます。
Nutstoreにログインし、右上のユーザー名をクリックして「アカウント情報」を選択:
「セキュリティオプション」を選択し、「アプリを追加」をクリック
アプリ名を入力し、ランダムパスワードを生成:
パスワードをコピーして保存:
サーバーアドレス、アカウント、パスワードを取得:
Cherry Studio設定→データ設定でWebDAV情報を入力:
データのバックアップまたは復元を選択し、自動バックアップの時間間隔を設定できます
導入が比較的容易なWebDAVサービスは主にクラウドストレージです:
123 Pan(会員制)
Alibaba Cloud Drive(購入が必要)
Box (無料容量10GB、単一ファイル制限250MB)
Dropbox (基本無料2GB、招待で最大16GBまで拡張可能)
TeraCloud (無料容量10GB、招待で5GB追加可能)
Yandex Disk (無料ユーザー向け容量10GB)
次に、自己ホスティングが必要なサービス:
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studio はマルチモデル対応のデスクトップクライアントで、Windows、Linux、MacOS 各プラットフォーム向けに提供されています。主要LLMモデルを統合し、多彩なシナリオをサポートするAIアシスタントです。インテリジェントなチャット管理、オープンソースカスタマイズ、マルチテーマUIで生産性を向上させます。
Cherry Studio は現在 PPIO 高性能APIチャネルと正式連携——エンタープライズ級のコンピューティングリソースにより DeepSeek-R1/V3の高速応答と99.9%のサービス可用性を実現し、スムーズなユーザー体験を提供します。
以下のチュートリアルではAPIキーの設定を含む完全な統合手順を解説します。「Cherry Studioインテリジェント制御+PPIO高性能API」の進化版を3分で構築可能です。
公式サイトからCherry Studioをダウンロード:https://cherry-ai.com/download(アクセスできない場合はQuarkクラウドリンクを利用:https://pan.quark.cn/s/c8533a1ec63e#/list/share)
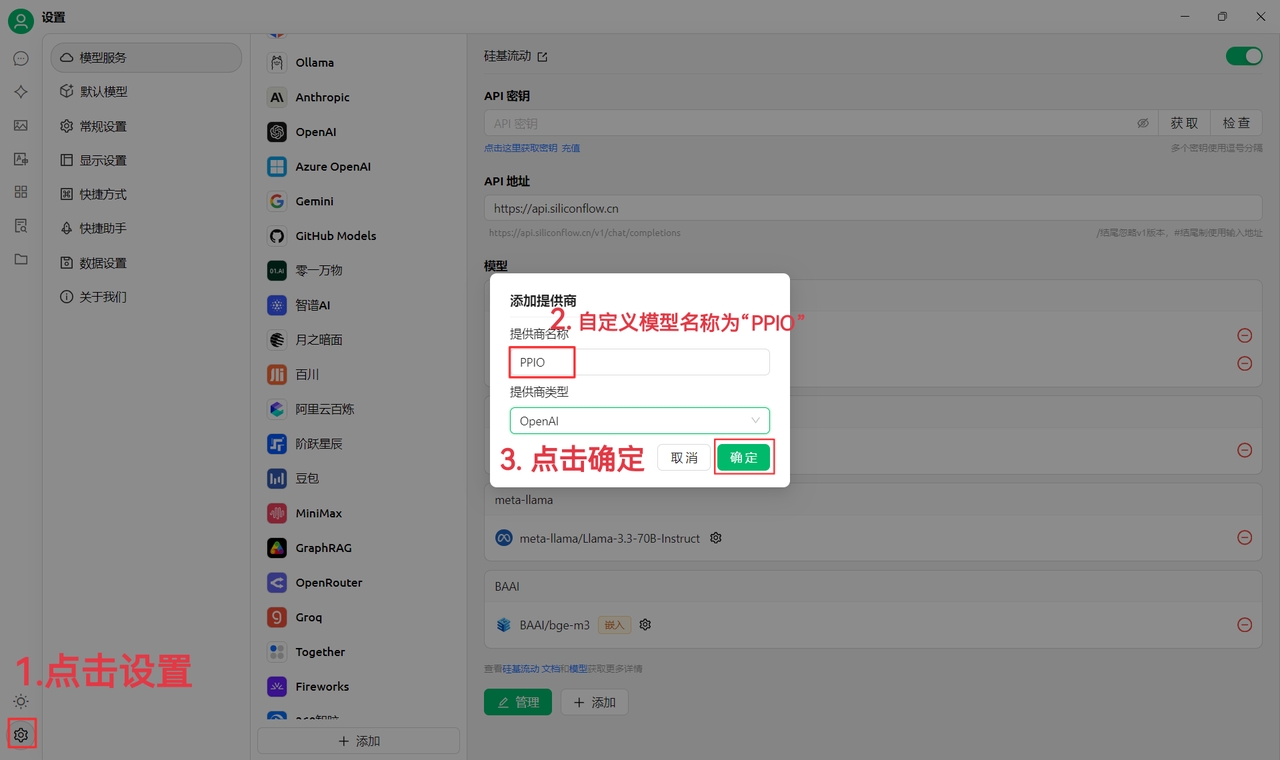
(1)左下の設定アイコンをクリックし、プロバイダー名をPPIOと入力 →「確定」
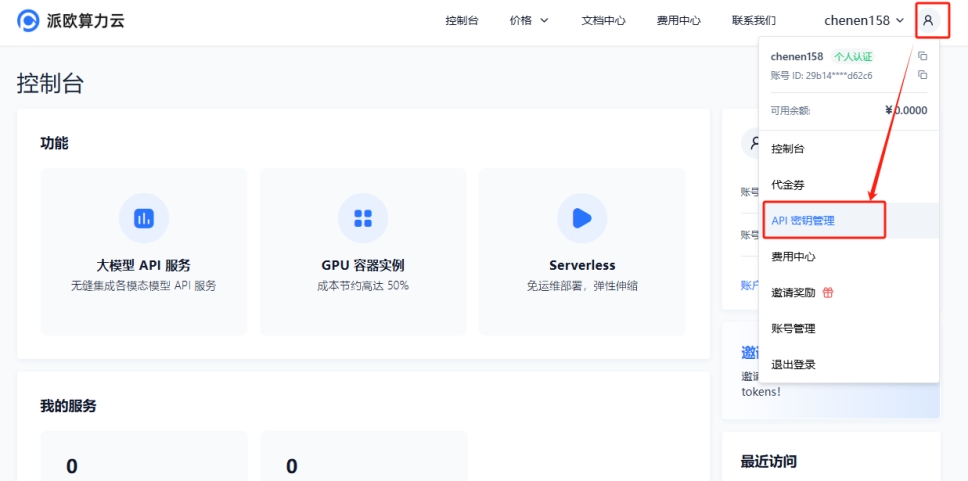
(2)パイオー算力雲 APIキー管理にアクセス →【ユーザーアイコン】→【APIキー管理】でコンソール画面へ
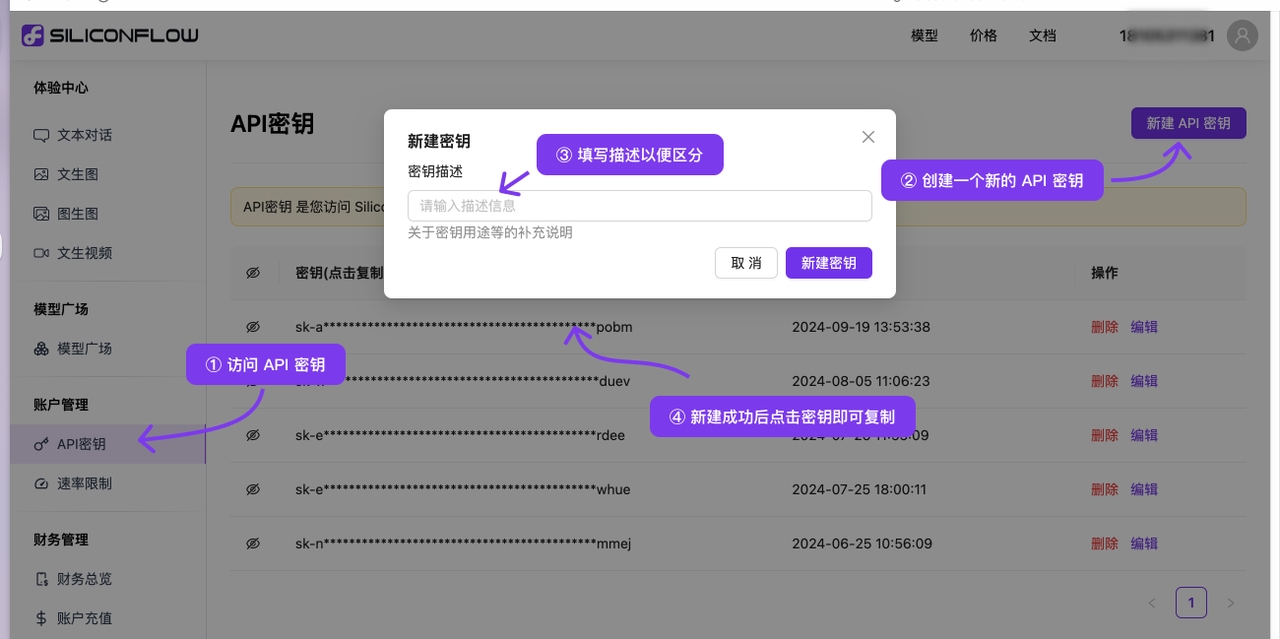
【+作成】をクリックし、APIキー名を入力します。生成されたキーはその場でのみ表示されるため、必ずコピーして保存してください
(3)Cherry Studioでキーを登録:設定画面で【PPIO パイオー・クラウド】を選択し、生成したAPIキーを入力 →【チェック】
(4)モデル選択:例として「deepseek/deepseek-r1/community」を選択(他モデルへ切り替える場合は直接変更可能)
DeepSeek R1/V3 community版は全パラメーター対応の無料体験版です(性能・安定性は有料版と同じ)。継続利用の場合は課金後に非community版へ切り替えが必要です。
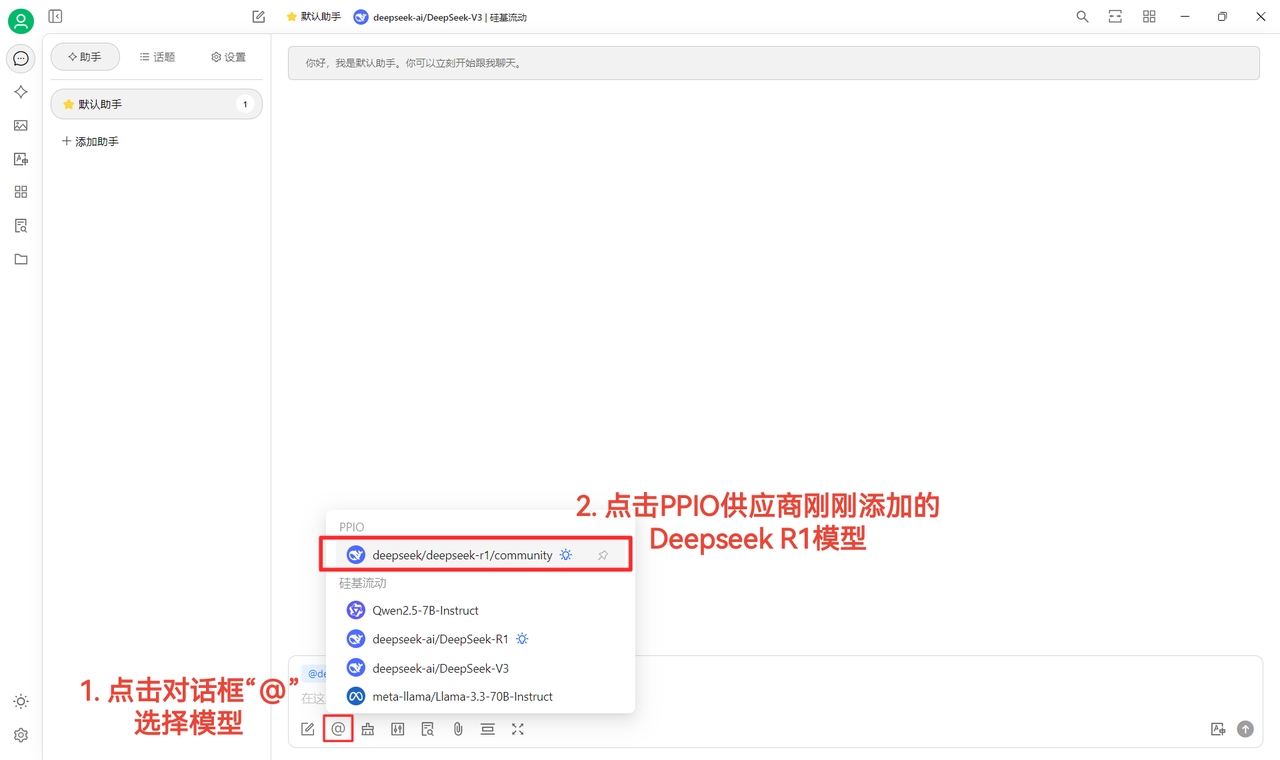
(1)【チェック】で接続成功を確認後、正常使用可能に
(2)最後に【@】をクリック → PPIOプロバイダー配下のDeepSeek R1モデルを選択 → チャット開始!
【参考素材:陳恩】
ビジュアル学習をご希望の場合はBilibili動画をご利用ください。「PPIO API+Cherry Studio」の設定手法を手順解説:→ 《【DeepSeekがクルクル回ってイライラする?】PPIO+DeepSeek フルスペック版 = 渋滞解消,爆速起動》
【動画素材提供:sola】
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
MCPの自動インストールには、Cherry Studioをv1.1.18以上にアップグレードする必要があります。
手動インストールに加えて、Cherry Studioには@mcpmarket/mcp-auto-installツールが組み込まれており、より便利なMCPサーバーのインストール方法を提供します。MCPサービスをサポートする大規模モデルチャットで対応するコマンドを入力するだけで使用できます。
テスト段階に関する注意:
@mcpmarket/mcp-auto-installは現在もテスト段階です
効果は大規模モデルの「知能」に依存し、自動的に追加される場合もあれば、MCP設定で特定のパラメータを手動で変更する必要がある場合もあります
現在の検索ソースは@modelcontextprotocolから行っており、自身で設定可能です(下記説明)
例えば、以下のように入力できます:
帮我安装一个 filesystem mcp serverシステムは自動的に要件を認識し、@mcpmarket/mcp-auto-installを通じてインストールを完了します。このツールは以下のような複数タイプのMCPサーバーをサポートしています:
filesystem(ファイルシステム)
fetch(ネットワークリクエスト)
sqlite(データベース)
など...
MCP_PACKAGE_SCOPES変数でMCPサービス検索ソースをカスタマイズ可能で、デフォルト値は
@modelcontextprotocolです。
@mcpmarket/mcp-auto-installライブラリの紹介このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Ollamaは優れたオープンソースツールで、ローカル環境で様々な大規模言語モデル(LLMs)を簡単に実行・管理できます。Cherry StudioはOllamaとの統合をサポートし、使い慣れたインターフェースからローカルにデプロイされたLLMと直接対話可能。クラウドサービスへの依存が不要です!
Ollamaは大規模言語モデル(LLM)のデプロイメントと使用を簡素化するツールです。主な特徴:
ローカル実行: モデルは完全にローカルマシン上で動作し、ネットワーク接続不要、プライバシーとデータセキュリティを保護
簡単操作: シンプルなコマンドライン指令で様々なLLMのダウンロード・実行・管理が可能
豊富なモデル: Llama 2、Deepseek、Mistral、Gemmaなど人気オープンソースモデルを多数サポート
クロスプラットフォーム: macOS、Windows、Linuxシステムに対応
オープンAPI: OpenAI互換インターフェースをサポートし、他のツールとの統合が可能
クラウドサービス不要: クラウドAPIの制限や費用から解放され、ローカルLLMの強力な機能を満喫
データプライバシー: 全ての対話データがローカルに保存され、プライバシー漏洩の心配なし
オフライン利用可能: ネットワーク接続がない環境でもLLMとの対話を継続可能
カスタマイズ性: ニーズに応じて最適なLLMを選択・設定可能
まずコンピューターにOllamaをインストールし実行する必要があります:
Ollamaのダウンロード: Ollama公式サイト()にアクセスし、OSに合わせてインストーラーをダウンロード Linux環境では次のコマンドで直接インストール可能:
Ollamaのインストール: インストーラーの指示に従ってインストール完了
モデルのダウンロード: ターミナルでollama runコマンドを使用し、必要なモデルをダウンロード
例:Llama 3.2モデルをダウンロードする場合:
Ollamaが自動的にモデルをダウンロード・実行します
Ollamaの実行状態維持: Cherry StudioでOllamaモデルを使用する間は、Ollamaが実行状態であることを確認してください
次に、OllamaをカスタムAIプロバイダーとして追加:
設定を開く: Cherry Studioインターフェース左側ナビゲーションバーの「設定」(歯車アイコン)をクリック
モデルサービスへ移動: 設定ページで「モデルサービス」タブを選択
プロバイダーを追加: リスト中のOllamaをクリック
追加したOllamaプロバイダーを詳細設定:
有効状態:
Ollamaプロバイダー右端のスイッチがオン(有効状態)であることを確認
APIキー:
OllamaはデフォルトでAPIキーを必要としません。このフィールドは空欄のまま、または任意の内容を入力可
APIアドレス:
Ollamaが提供するローカルAPIアドレスを入力。通常は次のアドレス:
ポート番号を変更した場合は適宜修正
キープアライブ時間: セッションの保持時間を分単位で設定。設定時間内に新しい対話がない場合、Cherry Studioは自動的にOllamaとの接続を切断しリソースを解放
モデル管理:
「+ 追加」ボタンをクリックし、Ollamaでダウンロード済みのモデル名を手動入力
例:ollama run llama3.2でllama3.2モデルをダウンロードした場合、ここにllama3.2と入力
「管理」ボタンで追加済みモデルの編集・削除が可能
上記設定完了後、Cherry StudioのチャットインターフェースでOllamaプロバイダーとダウンロード済みモデルを選択し、ローカルLLMとの対話を開始できます!
モデル初回実行時: 初めて特定のモデルを実行する場合、Ollamaはモデルファイルをダウンロードするため時間がかかります。しばらくお待ちください
利用可能モデルの確認: ターミナルでollama listコマンドを実行すると、ダウンロード済みOllamaモデルを一覧表示可能
ハードウェア要件: 大規模言語モデルの実行には相当な計算リソース(CPU、メモリ、GPU)が必要です。お使いのコンピューターがモデル要件を満たしていることを確認ください
Ollamaドキュメント: 設定ページのOllamaドキュメントとモデルを表示リンクをクリックすると、Ollama公式ドキュメントに直接アクセス可能
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
TokensはAIモデルがテキストを処理する基本的な単位であり、モデルが「思考」する最小ユニットと理解できます。これは我々が理解する文字や単語とは完全には一致せず、モデル独自の特殊なテキスト分割方法です。
1. 中国語の分かち書き
1つの漢字は通常1~2トークンにエンコードされる
例:"你好" ≈ 2-4トークン
2. 英語の分かち書き
一般的な単語は通常1トークン
長い単語や珍しい単語は複数トークンに分割される
例:
"hello" = 1トークン
"indescribable" = 4トークン
3. 特殊文字
スペースや句読点もトークンを消費
改行文字は通常1トークン
Tokenizer(トークナイザー)はAIモデルがテキストをtokensに変換するツールです。入力テキストをモデルが理解できる最小単位にどう分割するかを決定します。
1. トレーニングデータの違い
異なるコーパスによる最適化方向の違い
多言語サポートレベルの差異
医療・法律など特定分野向けの最適化
2. 分かち書きアルゴリズムの違い
BPE (Byte Pair Encoding) - OpenAI GPTシリーズ
WordPiece - Google BERT
SentencePiece - 多言語シナリオ向け
3. 最適化目標の違い
圧縮効率を重視するもの
意味保持を重視するもの
処理速度を重視するもの
同じテキストでもモデルによってトークン数が異なる可能性:
基本概念: 埋め込みモデルは、高次元の離散データ(テキスト、画像など)を低次元の連続ベクトルに変換する技術です。この変換により、機械が複雑なデータをより良く理解・処理できるようになります。複雑なパズルを単純な座標点に簡略化するイメージで、パズルの主要な特徴を保持します。大規模モデル生態系では「翻訳者」として機能し、人間が理解可能な情報をAIが計算可能な数値形式に変換します。
動作原理: 自然言語処理を例にすると、埋め込みモデルは単語をベクトル空間内の特定位置にマッピングします。この空間では、意味的に類似した単語が自動的に近くに集まります。例:
「王様」と「女王」のベクトルは近い
「猫」と「犬」などのペット関連語も距離が近い
一方で「車」と「パン」など無関係な語は距離が遠い
主な応用シナリオ:
テキスト分析:文書分類、感情分析
推薦システム:パーソナライズドコンテンツ推薦
画像処理:類似画像検索
検索エンジン:意味検索の最適化
コアメリット:
次元削減効果:複雑データを扱いやすいベクトル形式に簡略化
意味保存:元データの重要な意味情報を保持
計算効率:機械学習モデルの学習・推論効率を大幅向上
技術的価値: 埋め込みモデルは現代AIシステムの基盤コンポーネントであり、機械学習タスクに高品質なデータ表現を提供するため、自然言語処理やコンピュータビジョンなどの分野発展を推進する鍵技術です。
基本的ワークフロー:
知識ベース前処理段階
ドキュメントを適切なサイズのchunk(テキスト塊)に分割
embeddingモデルで各chunkをベクトルに変換
ベクトルと原文をベクトルデータベースに保存
クエリ処理段階
ユーザー質問をベクトルに変換
ベクトルデータベースで類似内容を検索
検索された関連内容を文脈としてLLMに提供
MCPは標準化された方法で大規模言語モデル(LLM)にコンテキスト情報を提供することを目的としたオープンソースプロトコルです。
比喩的理解: MCPはAI分野の「USBメモリ」と想像できます。USBメモリが様々なファイルを保存し、コンピュータに挿入すれば即時使用可能となるように、MCP Serverには様々なコンテキスト提供「プラグイン」を「挿入」できます。LLMは必要に応じてMCP Serverにこれらのプラグインを要求し、豊富なコンテキスト情報を取得して自身の能力を強化できます。
Function Toolとの比較: 従来のFunction Tool(関数ツール)もLLMに外部機能を提供しますが、MCPはより高次元の抽象化と見なせます。Function Toolが特定タスク向けのツールであるのに対し、MCPはより汎用的でモジュール化されたコンテキスト取得メカニズムを提供します。
標準化: 統一インターフェースとデータ形式を提供し、異なるLLMとコンテキストプロバイダーのシームレスな連携を可能に
モジュール化: コンテキスト情報を独立モジュール(プラグイン)に分解可能で、管理と再利用が容易
柔軟性: LLMが自身のニーズに応じて動的に必要なコンテキストプラグインを選択可能で、よりスマートで個別化されたインタラクションを実現
拡張性: MCPの設計は将来の多様なコンテキストプラグイン追加をサポートし、LLMの能力拡張に無限の可能性を提供
---
icon: cherries
---
# ファーウェイクラウド
一、[ファーウェイクラウド](https://auth.huaweicloud.com/authui/login)でアカウントを作成してログインする
二、[このリンク](https://console.huaweicloud.com/modelarts/?region=cn-southwest-2#/model-studio/homepage)をクリックし、ModelArtsコントロールパネルに進む
三、認可
<details>
<summary>認可手順(既に認可済みの場合はスキップ)</summary>
1. (二)のリンクページに進んだ後、案内に従って認可ページへ進む(IAMサブユーザー → 委託新規作成 → 一般ユーザー)
.png>)
2. 作成をクリック後、(二)のリンクページに戻る
3. アクセス権限が不十分な旨が表示されるため、メッセージ内の「ここをクリック」を押す
4. 既存の認可を追加して確定する
.png>)
注意:この方法は初心者向けで、内容を深く理解する必要がなく、案内に従ってクリックするだけで完了します。一度で認可を成功させられる場合はご自身の方法で行ってください。
</details>
四、サイドバーの認証管理をクリックし、API Key(シークレットキー)を作成してコピーする
<figure><img src="../../.gitbook/assets/微信截图_20250214034650.png" alt=""><figcaption></figcaption></figure>
続いてCherryStudioで新しいプロバイダーを作成
<figure><img src="../../.gitbook/assets/image (1) (2).png" alt="" width="300"><figcaption></figcaption></figure>
作成完了後、シークレットキーを入力する
五、サイドバーのモデルデプロイメントをクリックし、全てを取得する
<figure><img src="../../.gitbook/assets/微信截图_20250214034751.png" alt=""><figcaption></figcaption></figure>
六、呼び出しをクリック
<figure><img src="../../.gitbook/assets/image (1) (2) (1).png" alt=""><figcaption></figcaption></figure>
①のアドレスをコピーし、CherryStudioのプロバイダーアドレス欄に貼り付け、末尾に「#」を追加
末尾に「#」を追加
末尾に「#」を追加
末尾に「#」を追加
末尾に「#」を追加
「#」を追加する理由は[こちらを参照](https://docs.cherry-ai.com/cherrystudio/preview/settings/providers#api-di-zhi)
> もちろん、そちらを見なくても直接チュートリアル通り操作可能です;
>
> v1/chat/completionsを削除する方法で入力しても構いません。入力方法が分かればご自身の方法で実施してください。分からない場合は必ずチュートリアル通り操作してください。
<figure><img src="../../.gitbook/assets/image (2) (3).png" alt=""><figcaption></figcaption></figure>
次に②のモデル名をコピーし、CherryStudioで「+追加」ボタンをクリックして新規モデルを作成
<figure><img src="../../.gitbook/assets/image (4) (3).png" alt=""><figcaption></figcaption></figure>
モデル名を入力(余計な変更・引用符追加せず、サンプル通りそのまま入力)
<figure><img src="../../.gitbook/assets/image (3) (3).png" alt=""><figcaption></figcaption></figure>
「モデルを追加」ボタンをクリックして完了
{% hint style="info" %}
ファーウェイクラウドでは各モデルのアドレスが異なるため、各モデルごとに新しいプロバイダーを作成する必要があります。上記手順を繰り返し実施してください。
{% endhint %}入力:"Hello, world!"
GPT-3: 4トークン
BERT: 3トークン
Claude: 3トークンcurl -fsSL https://ollama.com/install.sh | shollama run llama3.2http://localhost:11434/









このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studio は主要なAIモデルサービスを統合しているだけでなく、強力なカスタマイズ機能も提供します。カスタムAIプロバイダー機能を使用することで、必要なあらゆるAIモデルを簡単に接続できます。
柔軟性: 事前設定されたプロバイダーリストに制限されず、ニーズに最適なAIモデルを自由に選択可能
多様性: 様々なプラットフォームのAIモデルを試し、それぞれの特徴を活用できる
制御性: APIキーやアクセスアドレスを直接管理し、セキュリティとプライバシーを確保
カスタマイズ性: プライベートデプロイメントのモデルを接続し、特定の業務要件に対応
Cherry StudioにカスタムAIプロバイダーを追加するのは簡単な数ステップで完了します:
設定を開く: Cherry Studioの左サイドバーで「設定」(歯車アイコン)をクリック
モデルサービスに移動: 設定ページで「モデルサービス」タブを選択
プロバイダーを追加: 「モデルサービス」ページで既存プロバイダーリストを確認し、下部の「+追加」ボタンクリック
情報を入力: ポップアップで以下の情報を入力:
プロバイダー名: 識別しやすい名前(例:MyCustomOpenAI)
プロバイダータイプ: ドロップダウンから選択(現在対応:OpenAI, Gemini, Anthropic, Azure OpenAI)
設定を保存: 「追加」ボタンをクリックして設定を保存
追加後、リストからプロバイダーを選択して詳細設定を実施:
有効化状態: リスト右端のトグルスイッチでサービスの有効/無効を切り替え
APIキー:
AIプロバイダーから提供されたAPIキーを入力
右側の「チェック」ボタンでキーの有効性を確認
APIアドレス:
AIサービスのベースURLを入力
公式ドキュメントを参照し正確なアドレスを入力
モデル管理:
「+追加」ボタンで使用したいモデルIDを入力(例:gpt-3.5-turbo, gemini-pro)
モデル名が不明な場合は公式ドキュメントを参照
「管理」ボタンで既存モデルの編集・削除を実施
上記設定完了後、チャットインターフェースでカスタムAIプロバイダーとモデルを選択し、AIとの対話を開始できます!
vLLMはOllamaのような高速で使いやすいLLM推論ライブラリです。Cherry Studioとの統合手順:
vLLMをインストール: 公式ドキュメント(https://docs.vllm.ai/en/latest/getting_started/quickstart.html)に従いインストール
pip install vllm # pipを使用する場合
uv pip install vllm # uvを使用する場合vLLMサービスを起動: OpenAI互換インターフェースで起動(2種類の方法):
vllm.entrypoints.openai.api_serverでの起動
python -m vllm.entrypoints.openai.api_server --model gpt2uvicornでの起動
vllm --model gpt2 --served-model-name gpt2デフォルトポート8000で起動を確認(--portパラメータでポート変更可)
Cherry StudioにvLLMプロバイダーを追加:
前述の手順で新規プロバイダーを追加
プロバイダー名: vLLM
プロバイダータイプ: OpenAIを選択
vLLMプロバイダーを設定:
APIキー: vLLMはキー不要なので空欄または任意の値を入力
APIアドレス: vLLMサービスのアドレス(例:http://localhost:8000/)
モデル管理: vLLMでロードしたモデル名を入力(例:gpt2)
対話開始: vLLMプロバイダーとモデルを選択し、LLMとの対話を開始
ドキュメントを精読: プロバイダー追加前に公式ドキュメントでAPIキー・アドレス・モデル名を確認
APIキーチェック: 「チェック」ボタンでキーの有効性を検証
APIアドレス注意: プロバイダーやモデルによりアドレスが異なるので正確に入力
モデル選択: 実際に使用するモデルのみ追加し、無用な追加を避ける



このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
このドキュメントは中国語から翻訳されており、現在レビューされていません。翻訳が適切かどうか、順次確認する予定です。
Cherry Studioのデータバックアップは、S3互換ストレージ(オブジェクトストレージ)方式をサポートしています。代表的なS3互換ストレージサービスには、AWS S3、Cloudflare R2、Alibaba Cloud OSS、Tencent Cloud COS、およびMinIOなどがあります。
S3互換ストレージを利用することで、Aコンピュータ S3ストレージ Bコンピュータ の形式でマルチデバイスデータ同期を実現できます。
オブジェクトストレージバケット(Bucket)を作成し、バケット名を記録します。※バックアップデータ漏洩防止のため、バケットはプライベート読み書きモードに設定することを強く推奨します!
各クラウドサービスのドキュメントを参照し、管理コンソールから以下のS3互換ストレージ情報を取得します:
Endpoint:S3互換ストレージのアクセスURL(例: https://<bucket-name>.<region>.amazonaws.com または https://<ACCOUNT_ID>.r2.cloudflarestorage.com)
Region:バケットのリージョン(例: us-west-1, ap-southeast-1)。Cloudflare R2の場合はautoを入力
Bucket:バケット名
Access Key ID と Secret Access Key:認証用クレデンシャル
Root Path(オプション):バックアップ時のルートパス(デフォルトは空)
関連ドキュメント
Cloudflare R2:Access Key IDとSecret Access Keyの取得方法
Alibaba Cloud OSS:Access Key IDとAccess Key Secretの取得方法
Tencent Cloud COS:SecretIdとSecretKeyの取得方法
S3バックアップ設定に上記情報を入力後、「バックアップ」ボタンで実行、「管理」ボタンでバックアップファイルの一覧確認・管理が可能です。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studioへの貢献を歓迎します!以下の方法で貢献できます:
1. コード貢献:开新機能の開発や既存コードの最適化。
2. バグ修正:提見つけたバグの修正を提出。
3. Issue管理:帮GitHub Issueの管理支援。
4. 製品デザイン:参デザイン議論への参加。
5. ドキュメント作成:改ユーザーマニュアルやガイドの改善。
6. コミュニティ参加:加議論への参加やユーザー支援。
7. プロモーション:宣Cherry Studioの普及活動。
メール送信: [email protected]
メールタイトル:開発者として申請 メール本文:申請理由
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studio のデータ保存はシステム仕様に従い、データはユーザーディレクトリ下に自動的に保存されます。具体的なディレクトリの場所は以下の通りです:
macOS: /Users/username/Library/Application Support/CherryStudioDev
Windows: C:\Users\username\AppData\Roaming\CherryStudio
Linux: /home/username/.config/CherryStudio
以下の場所でも確認できます:
方法1:
シンボリックリンクを作成することで実現できます。ソフトウェアを終了し、データを保存したい場所に移動した後、元の場所に移動先を指すリンクを作成します。
具体的な操作手順はこちらを参照してください:https://github.com/CherryHQ/cherry-studio/issues/621#issuecomment-2588652880
方法2: Electron アプリの特性を利用し、起動パラメータの設定で保存場所を変更します。
--user-data-dir 例: Cherry-Studio-*-x64-portable.exe --user-data-dir="%user_data_dir%"
実行例:
PS D:\CherryStudio> dir
ディレクトリ: D:\CherryStudio
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:05 user-data-dir
-a---- 2025/4/14 23:05 94987175 Cherry-Studio-1.2.4-x64-portable.exe
-a---- 2025/4/18 14:05 701 init_cherry_studio.batinit_cherry_studio.bat (encoding: ANSI)
@title CherryStudio 初期化
@echo off
set current_path_dir=%~dp0
@echo 現在のパス:%current_path_dir%
set user_data_dir=%current_path_dir%user-data-dir
@echo CherryStudio データパス:%user_data_dir%
@echo カレントパスで Cherry-Studio-*-portable.exe を検索中
setlocal enabledelayedexpansion
for /f "delims=" %%F in ('dir /b /a-d "Cherry-Studio-*-portable*.exe" 2^>nul') do ( #このコードは、GitHubおよび公式サイトからダウンロードしたバージョンに適応します。その他の場合はご自身で修正してください
set "target_file=!cd!\%%F"
goto :break
)
:break
if defined target_file (
echo ファイルを検出: %target_file%
) else (
echo 該当ファイルが見つかりません、スクリプトを終了します
pause
exit
)
@echo 続行するには確認してください
pause
@echo CherryStudio を起動します
start %target_file% --user-data-dir="%user_data_dir%"
@echo 操作が完了しました
@echo on
exituser-data-dir ディレクトリの初期化後構造:
PS D:\CherryStudio> dir .\user-data-dir\
ディレクトリ: D:\CherryStudio\user-data-dir
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:29 blob_storage
d----- 2025/4/18 14:07 Cache
d----- 2025/4/18 14:07 Code Cache
d----- 2025/4/18 14:07 Data
d----- 2025/4/18 14:07 DawnGraphiteCache
d----- 2025/4/18 14:07 DawnWebGPUCache
d----- 2025/4/18 14:07 Dictionaries
d----- 2025/4/18 14:07 GPUCache
d----- 2025/4/18 14:07 IndexedDB
d----- 2025/4/18 14:07 Local Storage
d----- 2025/4/18 14:07 logs
d----- 2025/4/18 14:30 Network
d----- 2025/4/18 14:07 Partitions
d----- 2025/4/18 14:29 Session Storage
d----- 2025/4/18 14:07 Shared Dictionary
d----- 2025/4/18 14:07 WebStorage
-a---- 2025/4/18 14:07 36 .updaterId
-a---- 2025/4/18 14:29 20 config.json
-a---- 2025/4/18 14:07 434 Local State
-a---- 2025/4/18 14:29 57 Preferences
-a---- 2025/4/18 14:09 4096 SharedStorage
-a---- 2025/4/18 14:30 140 window-state.jsonこのドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
4xx(クライアントエラーステータスコード):一般的にリクエスト構文エラー、認証失敗、認証エラーなどでリクエストを完了できません。
5xx(サーバーエラーステータスコード):一般的にサーバー側のエラーで、サーバーダウン、リクエスト処理のタイムアウトなどが発生します。
400
リクエストボディの形式エラーなど
対話が返したエラー内容を確認、またはでエラー内容を確認し、指示に従って操作してください。
【よくある状況1】:Geminiモデルの場合、カード登録が必要な可能性があります; 【よくある状況2】:データ容量超過(画像モデルで頻発)。画像サイズがプロバイダーの単一リクエスト上限を超えた場合に発生; 【よくある状況3】:非対応パラメータ追加またはパラメータ入力ミス。新しいアシスタントで再テストを推奨; 【よくある状況4】:コンテキスト制限超過。コンテキスト消去、新規対話作成、コンテキスト件数削減で対応。
401
認証失敗:非対応モデルまたはサーバーアカウント停止など
該当プロバイダーのアカウント状態を確認
403
操作権限なし
対話が返したエラー情報またはエラーに従って対応
404
リクエストリソースが見つからない
リクエストパスなどを確認
422
リクエスト形式は正しいが意味的にエラー
サーバーが解釈可能だが処理不能なケース(例:空値必須箇所でのnull、文字列必須箇所での数値/ブール値入力など)
429
リクエストレート制限到達
TPM/RPM上限到達。一時休止後に再試行
500
サーバー内部エラーでリクエスト完了不能
継続発生時はプロバイダーに連絡
501
サーバーがリクエスト機能をサポートせず
502
ゲートウェイ/プロキシサーバーが無効なアップストリーム応答を受信
503
過負荷/メンテナンス中のため一時的に処理不可。再試行タイミングはRetry-Afterヘッダー参照
504
ゲートウェイ/プロキシサーバーがアップストリームから応答を時間内に受信できず
Cherry Studioクライアントウィンドウをアクティブにした状態でショートカットCtrl+Shift+I(Mac:Command+Option+I)
起動したコンソールでNetwork → 赤×表示の最後のcompletions(対話/翻訳/モデルチェック時のエラー) またはgenerations(画像生成エラー) を選択 → Responseタブで完全なレスポンスを確認(図④のエリア)。
エラー原因が不明な場合は、該当画面のスクリーンショットを 公式交流グループ へ送信し支援を依頼してください。
この方法は対話時だけでなく、モデルテスト・ナレッジベース追加・画像生成などでも有効です。いずれの場合もデバッグウィンドウ起動後にリクエスト操作を行う必要があります。
数式コードが直接表示される場合、デリミタの有無を確認
デリミタ利用ガイド
インライン数式
単一ドル記号:
$数式$または
\(と\):例\(数式\)独立数式ブロック
二重ドル記号:
$$数式$$または
\[数式\]例:
$$\sum_{i=1}^n x_i$$
数式レンダリングエラー/文字化けは中国語を含む場合に頻発。数式エンジンをKateXに切り替えてください。
モデル利用不可
プロバイダーがモデルをサポートしているか、およびサービスの正常性を確認してください。
非埋め込みモデルの使用
最初にモデルが画像認識に対応しているか確認します。人気モデルはCherry Studioが自動分類し、モデル名横の👁️アイコンが画像認識対応を示します。
画像認識モデルは画像アップロードをサポートします。モデル分類が誤っている場合は、該当プロバイダーのモデルリストで対象モデル名横の設定ボタンから「画像」オプションを有効化してください。
モデル詳細は各プロバイダーの情報ページで確認できます。埋め込みモデルと同様、画像非対応モデルで画像オプションを有効化しても効果はありません。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
このページでは、ソフトウェアのカラーテーマ、ページレイアウト、またはカスタム CSSを設定して、パーソナライズ設定を行うことができます。
ここではデフォルトのインターフェースカラーモード(ライトモード、ダークモード、またはシステム設定に従う)を設定できます。
この設定は対話インターフェースのレイアウトに関する設定です。
トピックの位置
トピックへの自動切り替え
この設定を有効にすると、アシスタント名をクリックした際に対応するトピックページに自動的に切り替わります。
トピック時間の表示
有効にするとトピックの下にトピック作成時間が表示されます。
この設定によりインターフェースに柔軟なカスタマイズ変更を加えることができます。具体的な方法は上級チュートリアルのカスタム CSSを参照してください。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
GitHub Copilotを使用するには、まずGitHubアカウントを持ち、GitHub Copilotサービスをサブスクリプションする必要があります。free版のサブスクリプションも可能ですが、free版は最新のClaude 3.7モデルをサポートしていません。詳細はGitHub Copilot公式サイトを参照してください。
「GitHubにログイン」をクリックし、Device Codeを取得してコピーします。
Device Codeを取得したら、リンクをクリックしてブラウザを開きます。GitHubアカウントでログインし、Device Codeを入力して認証します。
認証が成功したら、Cherry Studioに戻り「GitHubに接続」をクリックします。成功するとGitHubユーザー名とアバターが表示されます。
下部の「管理」ボタンをクリックすると、現在サポートされているモデルリストが自動的に取得されます。
現在のリクエストはAxiosで構築されていますが、Axiosはsocksプロキシをサポートしていません。システムプロキシまたはHTTPプロキシを使用するか、CherryStudioでプロキシを設定せずにグローバルプロキシを使用してください。まずネットワーク接続が正常であることを確認し、Device Codeの取得失敗を防いでください。

このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Cherry Studioの設定を開く
MCPサーバーオプションを探す
サーバーを追加をクリック
MCP Serverの関連パラメータを入力()。入力が必要な内容:
名前:任意の名前(例:fetch-server)
タイプ:STDIOを選択
コマンド:uvxと入力
パラメータ:mcp-server-fetchと入力
(他のパラメータが存在する場合もあり、具体的なServerによる)
保存をクリック
上記設定完了後、Cherry Studioは自動的に必要なMCP Server - fetch serverをダウンロードします。ダウンロード完了後、使用を開始できます。注意:mcp-server-fetchの設定が成功しない場合、PCの再起動をお試しください。
MCPサーバー設定でMCPサーバーの追加に成功
上図から分かるように、MCPのfetch機能を組み合わせることで、Cherry Studioはユーザーのクエリ意図をより良く理解し、ウェブから関連情報を取得して、より正確で包括的な回答を提供できます。
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
1.2 左下の設定をクリックし、モデルサービスで【SiliconFlow】を選択
1.2 リンクをクリックしてSiliconCloud APIキーを取得
にログイン(未登録の場合は初回ログイン時に自動でアカウントが登録されます)
にアクセスし、新規キーを作成または既存キーをコピー
1.3 管理をクリックしてモデルを追加
左側メニューバーの「対話」ボタンをクリック
入力ボックスにテキストを入力してチャットを開始
上部メニューのモデル名を選択してモデルを切り替え
















このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
Doubao-embedding
4095
Doubao-embedding-vision
8191
Doubao-embedding-large
4095
text-embedding-v3
8192
text-embedding-v2
2048
text-embedding-v1
2048
text-embedding-async-v2
2048
text-embedding-async-v1
2048
text-embedding-3-small
8191
text-embedding-3-large
8191
text-embedding-ada-002
8191
Embedding-V1
384
tao-8k
8192
embedding-2
1024
embedding-3
2048
hunyuan-embedding
1024
Baichuan-Text-Embedding
512
M2-BERT-80M-2K-Retrieval
2048
M2-BERT-80M-8K-Retrieval
8192
M2-BERT-80M-32K-Retrieval
32768
UAE-Large-v1
512
BGE-Large-EN-v1.5
512
BGE-Base-EN-v1.5
512
jina-embedding-b-en-v1
512
jina-embeddings-v2-base-en
8191
jina-embeddings-v2-base-zh
8191
jina-embeddings-v2-base-de
8191
jina-embeddings-v2-base-code
8191
jina-embeddings-v2-base-es
8191
jina-colbert-v1-en
8191
jina-reranker-v1-base-en
8191
jina-reranker-v1-turbo-en
8191
jina-reranker-v1-tiny-en
8191
jina-clip-v1
8191
jina-reranker-v2-base-multilingual
8191
reader-lm-1.5b
256000
reader-lm-0.5b
256000
jina-colbert-v2
8191
jina-embeddings-v3
8191
BAAI/bge-m3
8191
netease-youdao/bce-embedding-base_v1
512
BAAI/bge-large-zh-v1.5
512
BAAI/bge-large-en-v1.5
512
Pro/BAAI/bge-m3
8191
text-embedding-004
2048
nomic-embed-text-v1
8192
nomic-embed-text-v1.5
8192
gte-multilingual-base
8192
embedding-query
4000
embedding-passage
4000
embed-english-v3.0
512
embed-english-light-v3.0
512
embed-multilingual-v3.0
512
embed-multilingual-light-v3.0
512
embed-english-v2.0
512
embed-english-light-v2.0
512
embed-multilingual-v2.0
256
:root {
--color-background: #1a462788;
--color-background-soft: #1a4627aa;
--color-background-mute: #1a462766;
--navbar-background: #1a4627;
--chat-background: #1a4627;
--chat-background-user: #28b561;
--chat-background-assistant: #1a462722;
}
#content-container {
background-color: #2e5d3a !important;
}:root {
font-family: "汉仪唐美人" !important; /* フォント */
}
/* 深い思考展開時のフォントカラー */
.ant-collapse-content-box .markdown {
color: red;
}
/* テーマ変数 */
:root {
--color-black-soft: #2a2b2a; /* ダーク背景色 */
--color-white-soft: #f8f7f2; /* ライト背景色 */
}
/* ダークテーマ */
body[theme-mode="dark"] {
/* カラー */
--color-background: #2b2b2b; /* ダーク背景色 */
--color-background-soft: #303030; /* ライト背景色 */
--color-background-mute: #282c34; /* ニュートラル背景色 */
--navbar-background: var(-–color-black-soft); /* ナビゲーションバー背景色 */
--chat-background: var(–-color-black-soft); /* チャット背景色 */
--chat-background-user: #323332; /* ユーザーチャット背景色 */
--chat-background-assistant: #2d2e2d; /* アシスタントチャット背景色 */
}
/* ダークテーマ固有スタイル */
body[theme-mode="dark"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* コンテンツコンテナ背景色 */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* メッセージ背景色 */
}
.inputbar-container {
background-color: #3d3d3a; /* 入力バー背景色 */
border: 1px solid #5e5d5940; /* 入力バーボーダーカラー */
border-radius: 8px; /* 入力バーボーダー角丸 */
}
/* コードスタイル */
code {
background-color: #e5e5e20d; /* コード背景色 */
color: #ea928a; /* コード文字色 */
}
pre code {
color: #abb2bf; /* プリフォーマットコード文字色 */
}
}
/* ライトテーマ */
body[theme-mode="light"] {
/* カラー */
--color-white: #ffffff; /* ホワイト */
--color-background: #ebe8e2; /* ライト背景色 */
--color-background-soft: #cbc7be; /* ライト背景色 */
--color-background-mute: #e4e1d7; /* ニュートラル背景色 */
--navbar-background: var(-–color-white-soft); /* ナビゲーションバー背景色 */
--chat-background: var(-–color-white-soft); /* チャット背景色 */
--chat-background-user: #f8f7f2; /* ユーザーチャット背景色 */
--chat-background-assistant: #f6f4ec; /* アシスタントチャット背景色 */
}
/* ライトテーマ固有スタイル */
body[theme-mode="light"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* コンテンツコンテナ背景色 */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* メッセージ背景色 */
}
.inputbar-container {
background-color: #ffffff; /* 入力バー背景色 */
border: 1px solid #87867f40; /* 入力バーボーダーカラー */
border-radius: 8px; /* 入力バーボーダー角丸(お好みのサイズに調整可) */
}
/* コードスタイル */
code {
background-color: #3d39290d; /* コード背景色 */
color: #7c1b13; /* コード文字色 */
}
pre code {
color: #000000; /* プリフォーマットコード文字色 */
}
}



このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
ModelScope MCPサーバーを利用するには、Cherry Studio を v1.2.9 以上にアップグレードしてください。
v1.2.9 バージョンでは、Cherry Studio が ModelScope 魔搭 との公式提携を実現し、MCPサーバー追加の操作手順が大幅に簡素化されました。これにより設定ミスの防止が可能となり、ModelScope コミュニティで膨大な MCPサーバーを発見できます。以下では、Cherry Studio で ModelScope の MCPサーバーを同期する手順をご説明します。
設定内の MCPサーバー設定をクリックし、サーバーを同期 を選択します。
ModelScope を選択し、MCPサービスを閲覧・発見します。
ModelScope に登録・ログイン後、MCPサービスの詳細を確認します。
MCPサービス詳細画面で、サービスに接続 を選択します。
Cherry Studio で APIを取得 トークンをクリックし、ModelScope 公式サイトにリダイレクトします。APIトークンをコピーし、Cherry Studio に戻って貼り付けます。
Cherry Studio の MCPサーバーリストで、ModelScope 接続済みの MCPサービスが表示され、会話中に呼び出せます。
ModelScope ウェブサイトで後から新たに接続する MCPサーバーは、サーバーを同期 をクリックするだけで増分的に追加できます。
この手順で、Cherry Studio で ModelScope 上の MCPサーバーを簡単に同期する方法を習得しました。設定プロセスが大幅に簡略化され、手動設定の複雑さや潜在エラーを回避し、ModelScope コミュニティの豊富な MCPサーバーリソースをシームレスに活用できるようになります。
これらの強力な MCPサービスを探索して活用し、Cherry Studio の使用体験にさらなる利便性と可能性をもたらしましょう!
このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
誤ったCSSを設定した場合や、CSS設定後に設定画面に入れなくなった場合に、この方法でCSS設定をクリアできます。
コンソールを開く:CherryStudioウィンドウをクリックし、Ctrl+Shift+Iキー(MacOS:command+option+I)を押します。
表示されたコンソールウィンドウで、Consoleタブをクリックします
手動でdocument.getElementById('user-defined-custom-css').remove()と入力します(コピー&ペーストでは通常実行されません)。
入力後Enterキーを押すとCSS設定がクリアされます。その後、改めてCherryStudioの表示設定画面で問題のあるCSSコードを削除してください。










このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
CherryStudio は SearXNG を介したウェブ検索をサポートしています。SearXNG はローカル環境またはサーバーにデプロイ可能なオープンソースプロジェクトであるため、APIプロバイダーを必要とする他の設定方法とは異なります。
SearXNG プロジェクトリンク: SearXNG
オープンソースで無料、API不要
比較的高いプライバシー性
高度なカスタマイズが可能
SearXNG は複雑な環境設定を必要としないため、docker compose を使用せずに空いているポートを提供するだけでデプロイできます。最も迅速な方法は Docker を使用して直接イメージをプルしデプロイすることです。
1. docker のダウンロードとインストール
インストール後にイメージ保存パスを選択:
2. SearXNG イメージの検索とプル
検索バーに searxng と入力:
イメージをプル:
3. イメージの実行
プル後、images ページに移動:
プルしたイメージを選択して実行:
設定を開いて構成:
8085 ポートを例に:
実行成功後にリンクをクリックすると SearXNG のフロントエンドインターフェースが開きます:
このページが表示されればデプロイ成功:
Windows に Docker をインストールするのは面倒なため、ユーザーは SearXNG をサーバーにデプロイし、他の人と共有することも可能です。ただし、残念ながら SearXNG 自体は現在認証をサポートしていないため、技術的手段であなたがデプロイしたインスタンスをスキャンして悪用される可能性があります。
このため、Cherry Studio は現在 HTTP基本認証(RFC7617) の設定をサポートしています。デプロイした SearXNG を公網環境に公開する場合は、必ず Nginx などのリバースプロキシソフトウェアで HTTP基本認証を設定してください。基本的な Linux 運用知識が必要ですが、以下に簡単なチュートリアルを提供します。
同様に、Docker を使用してデプロイします。サーバーに最新の Docker CE を公式チュートリアルに従ってインストール済みと仮定し、Debian システムでの新規インストール向けのワンステップコマンドを提供します:
sudo apt update
sudo apt install git -y
# 公式リポジトリをクローン
cd /opt
git clone https://github.com/searxng/searxng-docker.git
cd /opt/searxng-docker
# サーバーの帯域幅が小さい場合は false に設定可能
export IMAGE_PROXY=true
# 設定ファイルを編集
cat <<EOF > /opt/searxng-docker/searxng/settings.yml
# see https://docs.searxng.org/admin/settings/settings.html#settings-use-default-settings
use_default_settings: true
server:
# base_url is defined in the SEARXNG_BASE_URL environment variable, see .env and docker-compose.yml
secret_key: $(openssl rand -hex 32)
limiter: false # can be disabled for a private instance
image_proxy: $IMAGE_PROXY
ui:
static_use_hash: true
redis:
url: redis://redis:6379/0
search:
formats:
- html
- json
EOFローカルリスニングポートの変更や既存の nginx の再利用が必要な場合は、docker-compose.yaml ファイルを編集してください。参考例:
version: "3.7"
services:
# Caddy が必要なく、既存の Nginx を再利用する場合は以下を削除
caddy:
container_name: caddy
image: docker.io/library/caddy:2-alpine
network_mode: host
restart: unless-stopped
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile:ro
- caddy-data:/data:rw
- caddy-config:/config:rw
environment:
- SEARXNG_HOSTNAME=${SEARXNG_HOSTNAME:-http://localhost}
- SEARXNG_TLS=${LETSENCRYPT_EMAIL:-internal}
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
# Caddy が必要なく、既存の Nginx を再利用する場合は以上を削除
redis:
container_name: redis
image: docker.io/valkey/valkey:8-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: unless-stopped
networks:
- searxng
volumes:
- valkey-data2:/data
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
searxng:
container_name: searxng
image: docker.io/searxng/searxng:latest
restart: unless-stopped
networks:
- searxng
# ホストの8080ポートにマッピング。8000ポートをリスンしたい場合は "127.0.0.1:8000:8080" に変更
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
- UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4}
- UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4}
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
searxng:
volumes:
# Caddy が必要なく、既存の Nginx を再利用する場合は以下を削除
caddy-data:
caddy-config:
# Caddy が必要なく、既存の Nginx を再利用する場合は以上を削除
valkey-data2:docker compose up -d を実行して起動します。docker compose logs -f searxng でログを確認できます。
宝塔パネルや1Panelなどのサーバーパネルを使用している場合は、ドキュメントを参照してサイトを追加し、nginxリバースプロキシを設定した後、nginx設定ファイルを修正してください。 以下の例を参考に修正します:
server
{
listen 443 ssl;
# ホスト名
server_name search.example.com;
# index index.html;
# root /data/www/default;
# SSL設定がある場合
ssl_certificate /path/to/your/cert/fullchain.pem;
ssl_certificate_key /path/to/your/cert/privkey.pem;
# HSTS
# add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload";
# パネルでリバースプロキシを設定すると、デフォルトでlocationブロックは以下のようになる
location / {
# locationブロックに以下の2行を追加し、他はそのままに
# 設定ファイルが/etc/nginx/conf.d/に保存されていると仮定
# 宝塔パネルの場合は/wwwなどのディレクトリに保存されるため注意
auth_basic "ユーザー名とパスワードを入力してください";
auth_basic_user_file /etc/nginx/conf.d/search.htpasswd;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_protocol_addr;
proxy_pass http://127.0.0.1:8000;
client_max_body_size 0;
}
# access_log ...;
# error_log ...;
}Nginx設定ファイルが/etc/nginx/conf.dに保存されていると仮定し、パスワードファイルを同じディレクトリに保存します。
コマンドを実行(example_name、example_passwordを設定するユーザー名とパスワードに置き換え):
echo "example_name:$(openssl passwd -5 'example_password')" > /etc/nginx/conf.d/search.htpasswdNginxを再起動(設定のリロードでも可)。
ウェブページを開くと、ユーザー名とパスワードの入力が求められます。設定したユーザー名とパスワードを入力して、SearXNG検索ページに正常にアクセスできるか確認してください。
SearXNGをローカルまたはサーバーにデプロイしたら、CherryStudioの関連設定を行います。
ネットワーク検索設定ページでSearxngを選択:
ローカルデプロイのリンクを入力すると検証が失敗しますが、問題ありません:
直接デプロイ後、デフォルトではjson戻り型が設定されていないため、データを取得できません。設定ファイルを修正する必要があります。
Dockerに戻り、Filesタブでタグ付きフォルダを探します:
展開後、別のタグ付きフォルダを探します:
さらに展開し、settings.yml設定ファイルを見つけます:
ファイルエディターを開く:
78行目を見ると、タイプがhtmlのみです:
jsonタイプを追加して保存し、イメージを再実行:
Cherry Studioに戻って検証すると成功します:
アドレスはローカル: http://localhost:ポート番号 またはDockerアドレス: http://host.docker.internal:ポート番号 が使用可能です。
前述の例に従ってサーバーにデプロイし、リバースプロキシを正しく設定し、json戻り型を有効にしている場合、アドレスを入力して検証すると、HTTP基本認証が設定されているため401エラーコードが返されます:
クライアント側でHTTP基本認証を設定し、設定したユーザー名とパスワードを入力します:
検証を実行すると成功します。
これでSearXNGはデフォルトのネットワーク検索能力を備えています。検索エンジンのカスタマイズが必要な場合は各自設定してください。
ここでのプリファレンス設定は、大規模モデル呼び出し時の設定には影響しないことに注意してください。
大規模モデル呼び出し用の検索エンジンを設定するには、設定ファイルで設定する必要があります:
設定言語のリファレンス:
内容が長すぎて直接編集が不便な場合は、ローカルのIDEにコピーし、修正後に設定ファイルに貼り付けることができます。
設定ファイルで戻り形式にjsonを追加します:
Cherry Studio はデフォルトで categories に web general を含むエンジンを選択し、デフォルトでは google などのエンジンを選択します。大陸では google などのサイトに直接アクセスできないため失敗します。以下の設定を追加することで searxng が強制的に baidu エンジンを使用するようになり、問題が解決します:
use_default_settings:
engines:
keep_only:
- baidu
engines:
- name: baidu
engine: baidu
categories:
- web
- general
disabled: falsesearxng の limiter 設定が API アクセスを妨げるため、設定で false に設定してください:









このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
360gpt-pro
8k
-
非対応
対話
360AI_360gpt
360智脳シリーズで最高性能の主力千億パラメータ大規模モデル。各分野の複雑タスクに広く適用
360gpt-turbo
7k
-
非対応
対話
360AI_360gpt
性能と効果を両立した百億パラメータモデル。性能/コスト要件が高い場面に適する
360gpt-turbo-responsibility-8k
8k
-
非対応
対話
360AI_360gpt
性能と効果を両立した百億パラメータモデル。性能/コスト要件が高い場面に適する
360gpt2-pro
8k
-
非対応
対話
360AI_360gpt
360智脳シリーズで最高性能の主力千億パラメータ大規模モデル。各分野の複雑タスクに広く適用
claude-3-5-sonnet-20240620
200k
16k
非対応
対話,画像認識
Anthropic_claude
2024年6月20日リリースのスナップショット版。Claude 3.5 Sonnetは性能と速度のバランスを実現し、高速性を保ちつつトップクラスの性能を提供。マルチモーダル入力対応
claude-3-5-haiku-20241022
200k
16k
非対応
対話
Anthropic_claude
2024年10月22日リリースのスナップショット版。Claude 3.5 Haikuはコーディング、ツール使用、推論など全技能を向上。Anthropicシリーズ最速モデルとして高速応答を実現し、ユーザー向けチャットボットやリアルタイムコード補完など高インタラクティブ性・低遅延が求められるアプリケーションに最適。データ抽出やリアルタイムコンテンツ審査でも優れた性能を示す汎用ツール。画像入力非対応
claude-3-5-sonnet-20241022
200k
8K
非対応
対話,画像認識
Anthropic_claude
2024年10月22日リリースのスナップショット版。Claude 3.5 SonnetはOpusを超える能力を提供しながらSonnetより高速で同じ価格帯を維持。特にプログラミング、データサイエンス、ビジュアル処理、エージェントタスクに優れる
claude-3-5-sonnet-latest
200K
8k
非対応
対話,画像認識
Anthropic_claude
最新版Claude 3.5 Sonnetを動的に指すモデル。プログラミング、データサイエンス、ビジュアル処理、エージェントタスクに特に優れ、常に最新バージョンを指す
claude-3-haiku-20240307
200k
4k
非対応
対話,画像認識
Anthropic_claude
Anthropic最速・最コンパクトモデル。即時応答を実現。高速かつ正確な指向性性能を持つ
claude-3-opus-20240229
200k
4k
非対応
対話,画像認識
Anthropic_claude
Anthropicの高度複雑タスク処理用最強モデル。性能、知能、流暢さ、理解力で卓越
claude-3-sonnet-20240229
200k
8k
非対応
対話,画像認識
Anthropic_claude
2024年2月29日スナップショット版。Sonnetは特に以下に優れる: - コーディング:自律的なコード記述・編集・実行、推論とトラブルシューティング能力 - データサイエンス:人間の専門知識強化。多様なツールによる洞察取得時に非構造化データを処理可能 - ビジュアル処理:チャート・グラフ・画像の解釈に優れ、洞察を得るための正確なテキスト転記が可能 - エージェントタスク:優れたツール使用能力(他システムとの連携が必要な複数ステップの問題解決タスク)
google/gemma-2-27b-it
8k
-
非対応
対話
Google_gamma
Google開発の軽量最先端オープンモデルファミリー。Geminiモデルと同じ研究技術を採用。英語対応デコーダー型大規模言語モデル。プレトレーニング・指示チューニング変種をオープンウェイト提供。質問応答、要約、推論など多様なテキスト生成タスクに適用
google/gemma-2-9b-it
8k
-
非対応
対話
Google_gamma
Google開発の軽量最先端オープンモデルシリーズ。英語対応デコーダー型大規模言語モデル。オープンウェイト、プレトレーン変種と指示チューニング変種を提供。質問応答、要約、推論など多様なテキスト生成タスクに適用。8兆tokensで学習
gemini-1.5-pro
2m
8k
非対応
対話
Google_gemini
Gemini 1.5 Pro 最新安定版。強力なマルチモーダルモデル。6万行コードまたは2,000ページテキストを処理可能。複雑な推論タスクに特に適する
gemini-1.0-pro-001
33k
8k
非対応
対話
Google_gemini
Gemini 1.0 Pro 安定版。NLPモデルとして多輪テキスト/コードチャット・コード生成タスクを専門処理。2025年2月15日廃止予定(1.5シリーズ移行推奨)
gemini-1.0-pro-002
32k
8k
非対応
対話
Google_gemini
Gemini 1.0 Pro 安定版。NLPモデルとして多輪テキスト/コードチャット・コード生成タスクを専門処理。2025年2月15日廃止予定(1.5シリーズ移行推奨)
gemini-1.0-pro-latest
33k
8k
非対応
対話,廃止予定
Google_gemini
Gemini 1.0 Pro 最新版。NLPモデルとして多輪テキスト/コードチャット・コード生成タスクを専門処理。2025年2月15日廃止予定(1.5シリーズ移行推奨)
gemini-1.0-pro-vision-001
16k
2k
非対応
対話
Google_gemini
Gemini 1.0 Pro 画像版。2025年2月15日廃止予定(1.5シリーズ移行推奨)
gemini-1.0-pro-vision-latest
16k
2k
非対応
画像認識
Google_gemini
Gemini 1.0 Pro 画像最新版。2025年2月15日廃止予定(1.5シリーズ移行推奨)
gemini-1.5-flash
1m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Flash 最新安定版。バランス型マルチモーダルモデル。音声、画像、動画、テキスト入力を処理可能
gemini-1.5-flash-001
1m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Flash 安定版。gemini-1.5-flashと同等の基本機能を提供するがバージョン固定で本番環境に適す
gemini-1.5-flash-002
1m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Flash 安定版。gemini-1.5-flashと同等の基本機能を提供するがバージョン固定で本番環境に適す
gemini-1.5-flash-8b
1m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Flash-8BはGoogle最新のマルチモーダルAIモデル。大規模タスク効率的処理向け設計。80億パラメータでテキスト、画像、音声、動画入力対応。チャット、文字起こし、翻訳など多様なシナリオ適用可能。他のGeminiモデル比で速度とコスト効率を最適化しコスト重視ユーザーに最適。レート制限2倍化により大規模タスク効率処理実現。「知識蒸留(ナレッジディスティレーション)」技術でより大規模モデルから核心知識を抽出し、中核能力維持・軽量化・効率化を両立
gemini-1.5-flash-exp-0827
1m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Flash 試験版。最新改良を定期的に反映。探索的テスト・プロトタイプ開発向け(本番環境非推奨)
gemini-1.5-flash-latest
1m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Flash 最先端版。最新改良を定期的に反映。探索的テスト・プロトタイプ開発向け(本番環境非推奨)
gemini-1.5-pro-001
2m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Pro 安定版。固定モデル動作・性能特性を提供。安定性が必要な本番環境に適す
gemini-1.5-pro-002
2m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Pro 安定版。固定モデル動作・性能特性を提供。安定性が必要な本番環境に適す
gemini-1.5-pro-exp-0801
2m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Pro 試験版。強力なマルチモーダルモデル。6万行コードまたは2,000ページテキストを処理可能。複雑な推論タスクに特に適する
gemini-1.5-pro-exp-0827
2m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Pro 試験版。強力なマルチモーダルモデル。6万行コードまたは2,000ページテキストを処理可能。複雑な推論タスクに特に適する
gemini-1.5-pro-latest
2m
8k
非対応
対話,画像認識
Google_gemini
Gemini 1.5 Pro 最新版。最新スナップショットを動的に指す
gemini-2.0-flash
1m
8k
非対応
対話,画像認識
Google_gemini
Gemini 2.0 FlashはGoogle最新モデル。1.5版に比べ初回応答時間(TTFT)短縮し、Gemini Pro 1.5相当品質を維持。マルチモーダル理解、コード能力、複雑指令実行、関数呼び出しを向上させ、より滑潤で強力な知能体験を提供
gemini-2.0-flash-exp
100k
8k
対応
対話,画像認識
Google_gemini
Gemini 2.0 Flash はマルチモーダルリアルタイムAPI導入、速度・性能向上、品質向上、エージェント能力強化、画像生成と音声変換機能追加
gemini-2.0-flash-l




Monaspace
英語フォント 商用可能
GitHub は Monaspace というオープンソースのフォントファミリーを公開しました。5つのスタイルが選択可能です:Neon(モダンスタイル)、Argon(ヒューマニストスタイル)、Xenon(セリフスタイル)、Radon(ハンドライティングスタイル)、Krypton(メカニカルスタイル)。
MiSans Global
多言語 商用可能
MiSans Global は小米が主導し、モナタイプや漢儀字庫と共同で開発した多言語フォントカスタマイズプロジェクトです。
20以上の書字システムをカバーし、600以上の言語をサポートする大規模なフォントファミリーです。

このドキュメントはAIによって中国語から翻訳されており、まだレビューされていません。
これは Chatbot Arena (lmarena.ai) のデータに基づくランキングで、自動化プロセスにより生成されます。
データ更新日時: 2025-08-20 11:41:39 UTC / 2025-08-20 19:41:39 CST (北京時間)
1
1
1470
+5/-5
26,019
Proprietary
nan
2
2
1446
+6/-6
13,715
Proprietary
nan
3
2
1434
+9/-9
4,112
Z.ai
MIT
nan
4
2
1434
+6/-6
13,058
xAI
Proprietary
nan
5
3
1429
+4/-4
30,777
OpenAI
Proprietary
nan
6
3
1428
+4/-4
32,033
OpenAI
Proprietary
nan
7
3
1427
+9/-9
4,154
Alibaba
Apache 2.0
nan
8
3
1427
+5/-5
18,284
DeepSeek
MIT
nan
9
4
1423
+4/-4
31,757
xAI
Proprietary
nan
10
8
1416
+4/-4
26,604
Meta
nan
nan
11
8
1415
+5/-5
15,271
OpenAI
Proprietary
nan
12
7
1413
+9/-9
3,715
Alibaba
Apache 2.0
nan
13
8
1412
+6/-6
13,837
xAI
Proprietary
nan
14
10
1411
+4/-4
31,359
Proprietary
nan
15
15
1397
+4/-4
27,552
Proprietary
nan
16
15
1397
+5/-5
20,120
Proprietary
nan
17
15
1396
+5/-5
18,655
Proprietary
nan
18
15
1393
+9/-9
4,306
Z.ai
MIT
nan
19
15
1391
+5/-5
24,372
Alibaba
Apache 2.0
nan
20
15
1389
+4/-4
23,657
Proprietary
nan
21
15
1389
+4/-4
23,858
OpenAI
Proprietary
nan
22
19
1381
+3/-3
40,509
OpenAI
Proprietary
nan
23
18
1380
+6/-6
11,676
Moonshot
Modified MIT
nan
24
19
1380
+5/-5
24,834
OpenAI
Proprietary
nan
25
16
[Qwen3-30B-A3B-Instruct-2507](https极简模式验证中,继续输出完整翻译:
26
22
1379
+5/-5
17,328
Proprietary
nan
...(中略)...
266
264
840
+16/-16
2,446
Meta
Non-commercial
2023/2
順位(UB):Bradley-Terry モデルに基づく順位。アリーナにおけるモデルの総合的なパフォーマンスを反映し、Eloスコアの上限推定値を提供。モデルの潜在的な競争力を理解するのに役立ちます。
順位(StyleCtrl):会話スタイル制御後の順位。モデルの応答スタイル(例:冗長さ、簡潔さ)による選好バイアスを軽減し、モデルのコア能力をより純粋に評価します。
モデル名:大規模言語モデル(LLM)の名称。関連リンクが埋め込まれており、クリックでジャンプします。
スコア:ユーザー投票により獲得したEloスコア。スコアが高いほどパフォーマンスが優れていることを示す相対評価システムです。現在の競争環境におけるモデルの相対的な強さを反映します。
信頼区間:Eloスコアの95%信頼区間(例: +6/-6)。区間が小さいほどスコアの安定性と信頼性が高く、大きい場合はデータ不足やパフォーマンスの変動を示唆します。スコア精度の定量的評価を提供します。
投票数:モデルがアリーナで受けた総投票数。投票数が多いほど統計的信頼性が高くなります。
プロバイダー:モデルを提供する組織または企業。
ライセンス:モデルのライセンスタイプ(例: Proprietary、Apache 2.0、MIT)。
知識カットオフ日:モデル学習データの最終更新日。データなしは情報未提供または不明を示します。
本ランキングデータは fboulnois/llm-leaderboard-csv プロジェクトにより自動生成され、lmarena.ai から取得・処理されます。GitHub Actions により毎日自動更新されます。
本レポートは参考情報です。ランキングデータは動的に変化し、特定の期間におけるChatbot Arena上のユーザー選好投票に基づいています。データの完全性と正確性は、上流データソースおよび fboulnois/llm-leaderboard-csv プロジェクトの更新・処理に依存します。モデルごとに異なるライセンスが適用される場合があります。ご利用の際は必ずモデルプロバイダーの公式説明を参照してください。