Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Lorsqu'aucun modèle d'assistant par défaut n'est défini pour un assistant, le modèle configuré ici sera sélectionné par défaut dans ses nouvelles conversations.
L'optimisation des mots d'incitation (prompts) et l'assistant de sélection de texte utilisent également le modèle défini ici.
Après chaque conversation, un modèle est appelé pour générer un nom de sujet à la conversation. Le modèle configuré ici est celui utilisé pour cette dénomination.
Les fonctions de traduction dans les champs de saisie de conversation, de peinture IA, ainsi que le modèle de traduction dans l'interface de traduction utilisent tous le modèle configuré ici.
Modèle utilisé pour les fonctions d'assistant rapide. Voir détails dans Assistant rapide
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cette interface permet d'effectuer des sauvegardes et restaurations locales ou cloud, de consulter le répertoire des données locales et de vider le cache, d'exporter les paramètres et de configurer des connexions tierces.
Actuellement, la sauvegarde prend en charge trois méthodes : sauvegarde locale, sauvegarde WebDAV et sauvegarde dans un stockage compatible S3 (stockage d'objets). Pour des explications détaillées et des tutoriels, veuillez consulter les documents suivants :
Les paramètres d'exportation permettent de configurer les options d'exportation affichées dans le menu. Vous pouvez également définir le chemin par défaut pour l'export Markdown, le style d'affichage, etc.
Cette section configure la connexion entre Cherry Studio et des applications tierces pour exporter rapidement le contenu des conversations vers vos outils de gestion des connaissances. Actuellement pris en charge : Notion, Obsidian, SiYuan Note, YuQue et Joplin. Tutoriels de configuration :
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Pour l'utilisation de la base de connaissances, consultez le tutoriel avancé : Tutoriel sur la base de connaissances.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
La page Agents est une place d'assistants où vous pouvez sélectionner ou rechercher le modèle prédéfini souhaité. En cliquant sur une carte, vous ajouterez l'assistant à la liste des assistants dans la page de conversation.
Vous pouvez également modifier et créer vos propres assistants sur cette page.
Cliquez sur Mon espace, puis sur Créer un agent pour commencer à créer votre propre assistant.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Sur cette interface, vous pouvez activer (désactiver) et configurer les raccourcis clavier de certaines fonctionnalités. Suivez les instructions spécifiques affichées sur l'interface pour effectuer les réglages.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Dans la page des mini-programmes, vous pouvez utiliser les versions web des applications liées à l'IA des principaux fournisseurs directement dans le client. Actuellement, l'ajout et la suppression personnalisés ne sont pas pris en charge.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Sur cette page, vous pouvez configurer le thème de couleur du logiciel, la mise en page ou personnaliser le CSS pour effectuer des réglages personnalisés.
Vous pouvez définir ici le mode de couleur par défaut de l'interface (mode clair, mode sombre ou suivi du système)
Ces paramètres concernent la mise en page de l'interface de discussion.
Lorsque ce paramètre est activé, cliquer sur le nom de l'assistant basculera automatiquement vers la page de conversation correspondante.
Lorsqu'activé, affiche l'heure de création sous chaque conversation.
Ce paramètre permet d'apporter des modifications personnalisées flexibles à l'interface. Voir les méthodes spécifiques dans le tutoriel avancé : Personnalisation CSS.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
La fonction de peinture prend actuellement en charge les modèles de DMXAPI, TokenFlux, AiHubMix et SiliconFlow. Vous pouvez créer un compte sur SiliconFlow et l'ajouter comme fournisseur de services pour l'utiliser.
Pour toute question sur les paramètres, passez votre souris sur le ? dans la zone correspondante pour voir les explications.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cette page présente uniquement les fonctionnalités de l'interface. Pour le tutoriel de configuration, veuillez consulter dans les tutoriels de base.
Dans Cherry Studio, un seul fournisseur supporte l'utilisation rotative de plusieurs clés via un cycle séquentiel dans la liste.
Ajoutez plusieurs clés en les séparant par des virgules anglaises. Par exemple :
Vous devez utiliser des virgules anglaises.
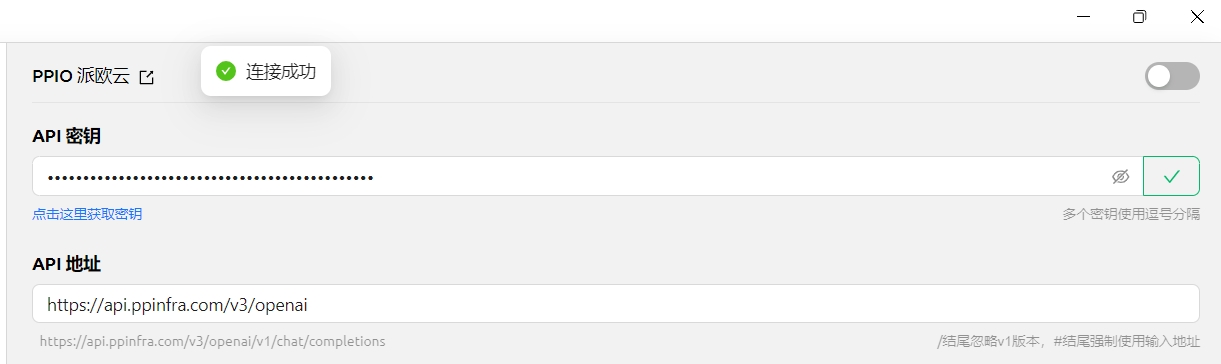
Aucun renseignement n'est généralement nécessaire pour les fournisseurs intégrés. Si modification requise, suivez scrupuleusement l'adresse fournie dans la documentation officielle correspondante.
Si le fournisseur indique une adresse au format https://xxx.xxx.com/v1/chat/completions, saisissez uniquement la partie racine (https://xxx.xxx.com).
Cherry Studio ajoutera automatiquement le chemin restant (/v1/chat/completions). Un format incorrect peut entraîner des dysfonctionnements.
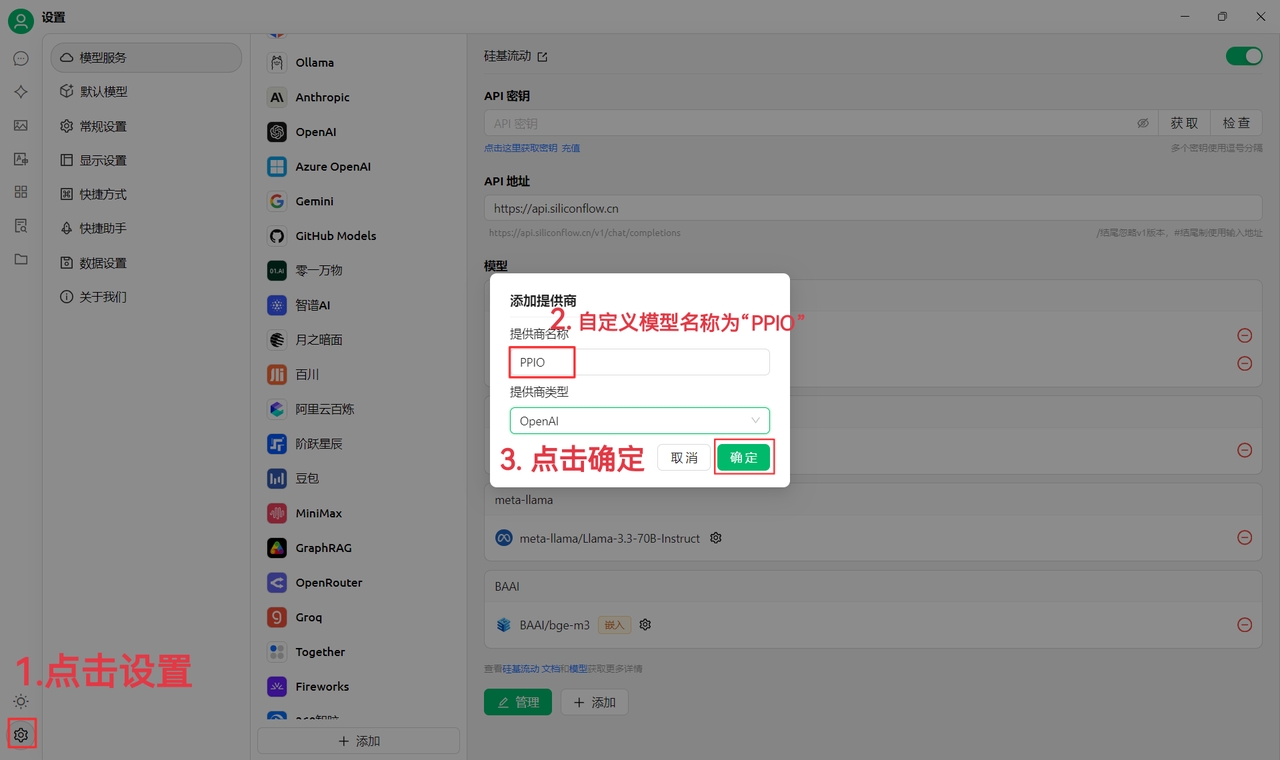
Cliquez généralement sur le bouton Gérer en bas à gauche de la page de configuration du fournisseur pour récupérer automatiquement tous ses modèles disponibles, puis ajoutez-les à la liste via le +.
Cliquez sur le bouton de vérification situé après le champ de clé API pour tester la configuration.
Après une configuration réussie, activez impérativement l'interrupteur en haut à droite, sans quoi le fournisseur restera inactif et ses modèles invisibles.
Windows 版本安装教程
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Remarque : Windows 7 ne prend pas en charge l'installation de Cherry Studio.
Cliquez pour télécharger et sélectionner la version appropriée
Si le navigateur indique que le fichier n'est pas approuvé, etc., choisissez simplement "Conserver"
Choisir Conserver→Faire confiance à Cherry-Studio
macOS 版本安装教程
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Tout d'abord, allez sur la page de téléchargement du site officiel et cliquez pour télécharger la version Mac, ou cliquez directement ci-dessous :
Veuillez télécharger la version correspondant à la puce de votre Mac
Une fois le téléchargement terminé, cliquez ici
Faites glisser l'icône pour installer
Dans le Launchpad, cherchez l'icône de Cherry Studio et cliquez dessus. Si l'interface principale de Cherry Studio s'ouvre, l'installation a réussi.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
1.2 Cliquez sur Paramètres en bas à gauche, sélectionnez【SiliconFlow】dans Services de modèles
1.2 Obtenir la clé API SiliconCloud
Connectez-vous à (l'inscription est automatique lors de la première connexion)
Accédez aux pour créer ou copier une clé existante
1.3 Cliquez sur Gérer pour ajouter des modèles
Cliquez sur le bouton "Conversation" dans le menu de gauche
Saisissez du texte dans la zone de saisie pour commencer à discuter
Changez de modèle via le menu déroulant en haut
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Utilisez cette méthode lorsque des paramètres CSS incorrects sont appliqués ou si vous ne pouvez pas accéder à l'interface après avoir défini des CSS.
Ouvrez la console, cliquez sur la fenêtre CherryStudio, puis appuyez sur le raccourci Ctrl+Shift+I (macOS : command+option+I).
Dans la console qui s'ouvre, cliquez sur Console
Saisissez manuellement document.getElementById('user-defined-custom-css').remove() – le copier-coller ne fonctionnera probablement pas.
Appuyez sur Entrée pour confirmer et effacer les paramètres CSS, puis retournez dans les paramètres d'affichage de CherryStudio pour supprimer le code CSS problématique.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
MCP (Model Context Protocol) est un protocole open-source conçu pour fournir des informations contextuelles aux grands modèles de langage (LLM) de manière standardisée. Pour plus d'informations sur MCP, consultez
Voici un exemple avec la fonction fetch démontrant comment utiliser MCP dans Cherry Studio. Les détails complets sont disponibles dans la .
Cherry Studio utilise actuellement uniquement les versions intégrées de et , sans réutiliser les installations existantes de uv et bun sur votre système.
Dans Paramètres → Serveurs MCP, cliquez sur le bouton Installer pour télécharger et installer automatiquement. Le téléchargement direct depuis GitHub peut être lent et échouer fréquemment. L'installation est réussie si les fichiers apparaissent dans les dossiers mentionnés ci-dessous.
Répertoires d'installation des exécutables :
Windows : C:\Users\Nom_utilisateur\.cherrystudio\bin
macOS/Linux : ~/.cherrystudio/bin
En cas d'échec d'installation :
Créez manuellement le répertoire s'il n'existe pas.
Vous pouvez soit :
Créer des liens symboliques vers les commandes système existantes
Télécharger manuellement les exécutables aux liens ci-dessous et les placer dans le répertoire :
Bun :
UV :
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Installation automatique du service MCP (version bêta)
Implémentation de base de mémoire persistante basée sur un graphe de connaissances local. Cela permet au modèle de mémoriser les informations pertinentes de l'utilisateur entre différentes conversations.
Implémentation d'un serveur MCP fournissant des outils pour la résolution dynamique et réflexive de problèmes grâce à un processus de pensée structuré.
Implémentation d'un serveur MCP intégrant l'API de recherche Brave, offrant une double fonctionnalité de recherche web et locale.
Serveur MCP pour récupérer le contenu de pages web via URL.
Serveur Node.js implémentant le protocole de contexte de modèle (MCP) pour les opérations sur le système de fichiers.
MEMORY_FILE_PATH=/path/to/your/file.jsonBRAVE_API_KEY=YOUR_API_KEYMiSans Global
Multilingue Usage commercial autorisé
MiSans Global est un projet de police personnalisée pour langues mondiales, dirigé par Xiaomi et développé conjointement avec Monotype et HanYi Foundries.
Il s'agit d'une vaste famille de polices couvrant plus de 20 systèmes d'écriture et prenant en charge plus de 600 langues.
mcp-server-time
--local-timezone
<votre fuseau horaire standard, par exemple : Asia/Shanghai>sk-xxxx1,sk-xxxx2,sk-xxxx3,sk-xxxx4







Ce document a été traducido del chino por IA y aún no ha sido revisado.










Ce document a été traducido del chino por IA y aún no ha sido revisado.
La fonction de traduction de Cherry Studio vous offre un service de traduction de texte rapide et précis, prenant en charge les traductions entre plusieurs langues.
L'interface de traduction comprend principalement les éléments suivants :
Zone de sélection de la langue source :
N'importe quelle langue : Cherry Studio détectera automatiquement la langue source et effectuera la traduction.
Zone de sélection de la langue cible :
Menu déroulant : Choisissez la langue dans laquelle vous souhaitez traduire le texte.
Bouton Paramètres :
Cliquez pour accéder aux paramètres des modèles par défaut.
Défilement synchronisé :
Cliquez pour activer/désactiver la synchronisation du défilement (le défilement d'un côté entraîne le défilement de l'autre côté).
Zone de saisie de texte (gauche) :
Saisissez ou collez le texte à traduire.
Zone des résultats de traduction (droite) :
Affiche le texte traduit.
Bouton Copier : Cliquez pour copier le résultat dans le presse-papiers.
Bouton Traduire :
Cliquez pour lancer la traduction.
Historique des traductions (coin supérieur gauche) :
Cliquez pour consulter l'historique des traductions.
Sélectionnez la langue cible :
Dans la zone de sélection de la langue cible, choisissez la langue souhaitée.
Saisissez ou collez le texte :
Entrez ou collez le texte à traduire dans la zone de gauche.
Lancez la traduction :
Cliquez sur le bouton Traduire.
Consultez et copiez les résultats :
Le résultat s'affiche dans la zone de droite.
Cliquez sur le bouton Copier pour transférer le texte dans le presse-papiers.
Q : Que faire si la traduction est inexacte ?
R : Bien que la traduction IA soit puissante, elle n'est pas parfaite. Pour les textes techniques ou contextes complexes, une relecture humaine est recommandée. Vous pouvez aussi essayer différents modèles.
Q : Quelles langues sont prises en charge ?
R : La fonction prend en charge de nombreuses langues principales. Consultez le site officiel ou les instructions dans l'application pour la liste complète.
Q : Peut-on traduire un fichier entier ?
R : L'interface actuelle est conçue pour des textes. Pour les fichiers, accédez à la page de conversation de Cherry Studio pour ajouter des fichiers à traduire.
Q : Que faire en cas de lenteur de traduction ?
R : La vitesse peut être affectée par le réseau, la longueur du texte ou la charge du serveur. Assurez-vous d'avoir une connexion stable et patientez.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Connectez-vous à Alibaba Cloud Bailian. Si vous n'avez pas de compte Alibaba Cloud, vous devrez en créer un.
Cliquez sur le bouton Créer mon API-KEY en haut à droite.
Dans la fenêtre contextuelle, sélectionnez l'espace d'affaires par défaut (ou personnalisez-le si vous le souhaitez). Vous pouvez éventuellement ajouter une description.
Cliquez sur le bouton Confirmer en bas à droite.
Vous devriez alors voir une nouvelle ligne apparaître dans la liste. Cliquez sur le bouton Afficher à droite.
Cliquez sur le bouton Copier.
Rendez-vous dans Cherry Studio. Accédez à Paramètres → Services de modèle → Alibaba Cloud Bailian, trouvez le champ Clé API et collez-y la clé copiée.
Vous pouvez ajuster les paramètres selon les instructions dans Services de modèle, puis commencer à l'utiliser.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cherry Studio permet d'importer des sujets dans la base de données Notion.
Accédez au site Notion Integrations pour créer une application
Créez une application
Nom : Cherry Studio
Type : Sélectionnez le premier
Icône : Vous pouvez sauvegarder cette image
Copiez la clé secrète et collez-la dans les paramètres de Cherry Studio
Ouvrez le site Notion, créez une nouvelle page, sélectionnez le type base de données en bas, nommez-la Cherry Studio, et connectez comme indiqué
Si l'URL de votre base de données Notion ressemble à ceci :
https://www.notion.so/<long_hash_1>?v=<long_hash_2>
Alors l'ID de la base de données Notion est la partie <long_hash_1>
Remplissez le Nom du champ de titre de la page :
Si votre interface est en anglais : saisissez Name
Si votre interface est en chinois : saisissez 名称
Félicitations, la configuration Notion est terminée ✅ Vous pouvez désormais exporter du contenu Cherry Studio vers votre base de données Notion
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cherry Studio permet de configurer les listes noires manuellement ou via des sources d'abonnement. Les règles de configuration suivent les références ublacklist.
Vous pouvez ajouter des règles aux résultats de recherche ou cliquer sur l'icône de la barre d'outils pour bloquer des sites spécifiques. Les règles peuvent être définies via :
Modèles de correspondance (ex: *://*.example.com/*)
Expressions régulières (ex: /example\.(net|org)/)
Vous pouvez également souscrire à des ensembles de règles publics. Ce site liste certains abonnements : https://iorate.github.io/ublacklist/subscriptions
Voici quelques sources d'abonnement recommandées :
https://git.io/ublacklist
Chinois
https://raw.githubusercontent.com/laylavish/uBlockOrigin-HUGE-AI-Blocklist/main/list_uBlacklist.txt
Généré par IA
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Pour utiliser GitHub Copilot, vous devez d'abord disposer d'un compte GitHub et souscrire au service GitHub Copilot. L'abonnement gratuit est possible, mais la version gratuite ne prend pas en charge le dernier modèle Claude 3.7. Pour plus de détails, consultez le site officiel de GitHub Copilot.
Cliquez sur « Se connecter à GitHub » pour obtenir le Device Code et copiez-le.
Après avoir obtenu le Device Code, cliquez sur le lien pour ouvrir le navigateur. Connectez-vous à votre compte GitHub, saisissez le Device Code et autorisez l'accès.
Après autorisation réussie, revenez à Cherry Studio et cliquez sur « Connecter GitHub ». Une fois connecté, votre nom d'utilisateur et votre avatar GitHub s'afficheront.
Cliquez sur le bouton « Gérer » ci-dessous pour récupérer automatiquement la liste des modèles actuellement pris en charge.
Les requêtes actuelles utilisent Axios, qui ne prend pas en charge les proxy SOCKS. Utilisez un proxy système ou HTTP, ou ne configurez pas de proxy dans CherryStudio pour utiliser un proxy global. Assurez-vous d'abord que votre connexion réseau est normale pour éviter cet échec.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Avant d'obtenir la clé API Gemini, vous devez disposer d'un projet Google Cloud (si vous en avez déjà un, cette étape peut être ignorée)
Accédez à Google Cloud pour créer un projet, saisissez le nom du projet et cliquez sur "Créer un projet"
Sur la page officielle des Clés API, cliquez sur Clé > Créer une clé API
Copiez la clé générée et ouvrez les Paramètres du fournisseur de CherryStudio
Localisez le fournisseur Gemini, entrez la clé que vous venez d'obtenir
Cliquez sur "Gérer" ou "Ajouter" en bas, ajoutez les modèles pris en charge et activez le commutateur du fournisseur en haut à droite pour commencer à l'utiliser.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Toutes les données ajoutées à la base de connaissances de Cherry Studio sont stockées localement. Lors de l'ajout, une copie du document est placée dans le répertoire de stockage des données de Cherry Studio.
Base de données vectorielle : https://turso.tech/libsql
Lorsqu'un document est ajouté à la base de connaissances de Cherry Studio, il est découpé en plusieurs segments. Ces segments sont ensuite traités par un modèle d'incorporation.
Lors de l'utilisation d'un grand modèle pour des questions-réponses, les segments de texte pertinents pour la question sont recherchés et transmis ensemble au grand modèle de langage pour traitement.
Si vous avez des exigences concernant la confidentialité des données, il est recommandé d'utiliser une base de données d'incorporation locale et un grand modèle de langage local.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Vous vivez peut-être cette situation : 26 articles utiles épinglés sur WeChat jamais relus, plus de 10 fichiers éparpillés dans votre dossier "Ressources d'apprentissage", cherchant désespérément une théorie lue il y a six mois avec seulement quelques mots-clés en tête. Quand le volume quotidien d'information dépasse la capacité de traitement de votre cerveau, 90% des connaissances précieuses sont oubliées en 72 heures. Désormais, avec l'API de la plateforme de grands modèles Infini-AI + Cherry Studio, vous pouvez créer une base de connaissances personnelle transformant articles WeChat oubliés et contenus fragmentés en savoir structuré, accessible avec précision.
1. Service API Infini-AI : le « cerveau réflexif » de votre base, fiable et performant
En tant que « cerveau réflexif » de la base de connaissances, la plateforme Infini-AI propose des versions de modèles comme DeepSeek R1 version complète, offrant un service API stable. Actuellement, l'utilisation est gratuite après inscription, sans conditions. Elle prend en charge les modèles d'embedding populaires (bge, jina) pour construire votre base, tout en intégrant continuellement les derniers modèles open-source puissants, incluant des capacités multimodales (images, vidéos, audio).
2. Cherry Studio : construisez votre base sans code
Cherry Studio est un outil IA intuitif. Alors que le développement traditionnel d'une base RAG nécessite 1 à 2 mois, cet outil offre l'avantage d'une configuration zéro code. Importez en un clic des contenus aux formats Markdown/PDF/web. L'analyse d'un fichier de 40MB prend 1 minute. Ajoutez également des dossiers locaux, des articles sauvegardés dans WeChat ou des notes de cours.
Étape 1 : Préparatifs
Téléchargez Cherry Studio sur le site officiel (https://cherry-ai.com/)
Créez un compte : connectez-vous à la plateforme Infini-AI (https://cloud.infini-ai.com/genstudio/model?cherrystudio)
Obtenez votre clé API : dans la « Place des modèles », choisissez deepseek-r1, cliquez sur Créer et copiez la clé API + le nom du modèle
Étape 2 : Dans les paramètres de Cherry Studio, sélectionnez "Infini-AI", saisissez votre clé API et activez le service
Après ces étapes, choisissez le modèle dans l'interface pour utiliser le service API Infini-Ai dans Cherry Studio. Pour plus de simplicité, vous pouvez définir un « modèle par défaut ».
Étape 3 : Ajoutez une base de connaissances
Sélectionnez un modèle d'embedding (série bge ou jina) de la plateforme Infini-AI.
Après import de ressources d'apprentissage : "Synthétisez les dérivations clés du chapitre 3 du livre 'Machine Learning'"
Résultat généré :
Ce document a été traducido del chino por IA y aún no ha sido revisado.
La sauvegarde des données de Cherry Studio prend en charge le stockage compatible S3 (stockage objet). Les services de stockage compatibles S3 courants incluent : AWS S3, Cloudflare R2, Alibaba Cloud OSS, Tencent Cloud COS et MinIO.
Grâce au stockage compatible S3, vous pouvez synchroniser les données entre plusieurs appareils via la méthode : Ordinateur A Stockage S3 Ordinateur B.
Créez un compartiment de stockage d'objets (Bucket) et notez son nom. Il est fortement recommandé de définir le compartiment en lecture/écriture privée pour éviter les fuites de données de sauvegarde !!
Consultez la documentation et accédez à la console du service cloud pour obtenir les informations du stockage compatible S3 telles que Access Key ID, Secret Access Key, Endpoint, Bucket, Region, etc.
Endpoint : Adresse d'accès du stockage compatible S3, généralement sous la forme https://<bucket-name>.<region>.amazonaws.com ou https://<ACCOUNT_ID>.r2.cloudflarestorage.com.
Region : Région où se trouve le compartiment, par exemple us-west-1, ap-southeast-1, etc. Pour Cloudflare R2, indiquez auto.
Bucket : Nom du compartiment.
Access Key ID et Secret Access Key : Informations d'identification pour l'authentification.
Root Path : Optionnel, spécifie le chemin racine lors de la sauvegarde dans le compartiment, vide par défaut.
Documentation associée
Cloudflare R2 : Obtenir Access Key ID et Secret Access Key
Alibaba Cloud OSS : Obtenir Access Key ID et Access Key Secret
Tencent Cloud COS : Obtenir SecretId et SecretKey
Dans les paramètres de sauvegarde S3, remplissez les informations ci-dessus, cliquez sur le bouton Sauvegarder pour effectuer la sauvegarde, et cliquez sur le bouton Gérer pour afficher et gérer la liste des fichiers de sauvegarde.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
L'Assistant Rapide est un outil pratique proposé par Cherry Studio qui vous permet d'accéder rapidement aux fonctionnalités d'IA dans n'importe quelle application, permettant ainsi des opérations instantanées comme poser des questions, traduire, résumer et expliquer.
Ouvrir les paramètres : Accédez à Paramètres -> Raccourcis -> Assistant Rapide.
Activer l'interrupteur : Localisez et activez le bouton correspondant à Assistant Rapide.
Configurer un raccourci clavier (optionnel) :
Raccourci par défaut Windows : Ctrl + E
Raccourci par défaut macOS : ⌘ + E
Vous pouvez personnaliser le raccourci ici pour éviter les conflits ou l'adapter à vos habitudes.
Invoquer : Dans n'importe quelle application, appuyez sur votre raccourci configuré (ou le raccourci par défaut) pour ouvrir l'Assistant Rapide.
Interagir : Dans la fenêtre de l'Assistant Rapide, vous pouvez directement effectuer les opérations suivantes :
Poser des questions rapides : Interrogez l'IA sur n'importe quel sujet.
Traduire du texte : Saisissez le texte à traduire.
Résumer du contenu : Entrez un texte long pour en obtenir un résumé.
Expliquer des concepts : Saisissez des termes ou concepts nécessitant une explication.
Fermer : Appuyez sur ESC ou cliquez n'importe où en dehors de la fenêtre pour fermer.
Conflits de raccourcis : Si le raccourci par défaut entre en conflit avec une autre application, modifiez-le.
Découvrir plus de fonctionnalités : Au-delà des fonctions documentées, l'Assistant Rapide peut supporter d'autres opérations comme la génération de code ou la conversion de style. Explorez pendant l'utilisation.
Retours et améliorations : Si vous rencontrez des problèmes ou avez des suggestions, contactez l'équipe Cherry Studio via les retours.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Permet d'exporter des sujets et messages vers SiYuan Note.
Ouvrez SiYuan Note et créez un carnet
Ouvrez les paramètres du carnet et copiez l'ID du carnet
Collez l'ID du carnet dans les paramètres de Cherry Studio
Entrez l'adresse de SiYuan Note
Local
Généralement http://127.0.0.1:6806
Auto-hébergé
Votre domaine http://note.domain.com
Copiez le Jeton d'API de SiYuan Note
Collez-le dans les paramètres de Cherry Studio et vérifiez
Félicitations, la configuration de SiYuan Note est terminée ✅ Vous pouvez maintenant exporter le contenu de Cherry Studio vers votre SiYuan Note
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Connectez-vous et accédez à la page des jetons
Créez un nouveau jeton (vous pouvez aussi utiliser le jeton par défaut ↑)
Copiez le jeton
Ouvrez les paramètres des fournisseurs de CherryStudio, cliquez sur Ajouter en bas de la liste des fournisseurs
Entrez un nom de note, sélectionnez OpenAI comme fournisseur, puis cliquez sur OK
Entrez la clé que vous venez de copier
Retournez à la page où vous avez obtenu la clé API, copiez l'adresse racine dans la barre d'adresse du navigateur, par exemple :
Ajoutez les modèles (cliquez sur Gérer pour obtenir automatiquement ou saisissez manuellement) et activez l'interrupteur en haut à droite pour commencer à utiliser.
L'interface peut varier selon le thème OneAPI, mais la méthode d'ajout reste identique aux étapes ci-dessus.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Le serveur ModelScope MCP nécessite de mettre à jour Cherry Studio à la version v1.2.9 ou supérieure.
Dans la version v1.2.9, Cherry Studio a établi un partenariat officiel avec ModelScope Mofada, simplifiant considérablement les étapes d'ajout des serveurs MCP et évitant les erreurs de configuration. Vous pouvez également découvrir d'innombrables serveurs MCP dans la communauté ModelScope. Suivez maintenant les étapes pour découvrir comment synchroniser les serveurs MCP ModelScope dans Cherry Studio.
Cliquez sur les paramètres des serveurs MCP dans les réglages, sélectionnez Synchroniser les serveurs
Sélectionnez ModelScope et parcourez les services MCP disponibles
Connectez-vous à ModelScope et consultez les détails du service MCP ;
Dans les détails du service MCP, sélectionnez "Connecter le service" ;
Cliquez sur "Obtenir le jeton API" dans Cherry Studio, accédez au site officiel de ModelScope, copiez le jeton API et collez-le dans Cherry Studio.
Dans la liste des serveurs MCP de Cherry Studio, vous verrez les services MCP connectés à ModelScope et pourrez les utiliser dans les conversations.
Pour les nouveaux serveurs MCP connectés ultérieurement via la page web ModelScope, cliquez simplement sur Synchroniser les serveurs pour les ajouter de manière incrémentielle.
Grâce à ces étapes, vous maîtrisez désormais la synchronisation pratique des serveurs MCP ModelScope dans Cherry Studio. Ce processus de configuration est non seulement grandement simplifié mais évite aussi les erreurs potentielles des configurations manuelles. Vous pourrez ainsi exploiter facilement les innombrables ressources de serveurs MCP fournies par la communauté ModelScope.
Commencez à explorer et utiliser ces puissants services MCP pour enrichir votre expérience avec Cherry Studio !
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Connectez-vous et ouvrez la page des jetons
Cliquez sur "Ajouter un jeton"
Entrez le nom du jeton et cliquez sur "Soumettre" (configurez d'autres paramètres si nécessaire)
Accédez aux paramètres des fournisseurs de CherryStudio, cliquez sur Ajouter en bas de la liste des fournisseurs
Saisissez un nom de référence, sélectionnez "OpenAI" comme fournisseur, puis cliquez sur "Confirmer"
Collez la clé copiée précédemment
Revenez à la page de l'API Key, copiez l'adresse racine dans la barre d'adresse du navigateur. Exemple :
Ajoutez les modèles (cliquez sur "Gérer" pour une détection automatique ou saisissez manuellement), puis activez le commutateur en haut à droite pour les utiliser.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Ouvrez les paramètres de Cherry Studio.
Trouvez l'option Serveur MCP.
Cliquez sur Ajouter un serveur.
Remplissez les paramètres du serveur MCP (lien de référence). Les informations à fournir peuvent inclure :
Nom : un nom personnalisé, par exemple fetch-server
Type : sélectionnez STDIO
Commande : entrez uvx
Arguments : entrez mcp-server-fetch
(d'autres paramètres peuvent exister selon le serveur spécifique)
Cliquez sur Enregistrer.
Après cette configuration, Cherry Studio téléchargera automatiquement le serveur MCP requis - fetch server. Une fois le téléchargement terminé, vous pouvez commencer à l'utiliser ! Remarque : si la configuration de mcp-server-fetch échoue, essayez de redémarrer votre ordinateur.
Le serveur MCP a été ajouté avec succès dans les paramètres
Comme le montre l'image ci-dessus, grâce à la fonction fetch intégrée au MCP, Cherry Studio peut mieux comprendre l'intention des requêtes utilisateur, récupérer des informations pertinentes sur Internet et fournir des réponses plus précises et complètes.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Connectez-vous à
Cliquez directement
Cliquez sur dans la barre latérale
Créez une clé API
Après création réussie, cliquez sur l'icône en forme d'œil à côté de votre clé API pour l'afficher et la copier
Collez la clé API copiée dans CherryStudio, puis activez le commutateur du fournisseur de service.
Activez les modèles nécessaires dans de la console Ark. Vous pouvez activer la série Doubao, DeepSeek ou d'autres modèles selon vos besoins.
Dans le , localisez l'ID de modèle correspondant au modèle requis.
Accédez aux de Cherry Studio et sélectionnez Volc Engine
Cliquez sur "Ajouter" et collez l'ID de modèle obtenu dans la zone de texte ID de modèle
Ajoutez les modèles un par un en suivant ce processus
L'adresse API peut s'écrire de deux manières
La première est celle par défaut du client : https://ark.cn-beijing.volces.com/api/v3/
La deuxième écriture est : https://ark.cn-beijing.volces.com/api/v3/chat/completions#
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Suivez nos comptes sociaux : , , , ,
Rejoignez nos communautés : , , ,
Cherry Studio est une plateforme d'assistant IA polyvalente intégrant des fonctionnalités multiformes telles que dialogues multimodèles, gestion de bases de connaissances, peinture IA et traduction. La conception hautement personnalisable, les capacités d'extension puissantes et l'expérience utilisateur conviviale de Cherry Studio en font un choix idéal pour les professionnels et les passionnés d'IA. Que vous soyez débutant ou développeur, chacun trouvera dans Cherry Studio les fonctionnalités IA adaptées pour améliorer sa productivité et créativité.
Réponses multiples : Permet d'obtenir simultanément plusieurs réponses à une même question via différents modèles, facilitant la comparaison des performances. Voir .
Regroupement automatique : L'historique des conversations est automatiquement organisé par assistant pour un accès rapide.
Export des dialogues : Export complet ou partiel au format Markdown, Word etc.
Paramètres hautement personnalisables : Paramètres avancés et possibilité d'entrer des paramètres personnalisés.
Marché d'assistants : Des milliers d'assistants spécialisés par secteur (traduction, programmation, rédaction) + assistants personnalisables.
Multiformats de rendu : Prise en charge du Markdown, des formules mathématiques et du prévisualisation HTML.
Peinture IA : Panneau dédié pour générer des images via description textuelle.
Mini-applications IA : Intégration d'outils IA web sans navigation externe.
Traduction : Scénarios multiples (panneau dédié, traduction conversationnelle).
Gestion des fichiers : Classification unifiée des fichiers des conversations, peinture et connaissances.
Recherche globale : Localisation rapide dans l'historique et les bases de connaissances.
Aggrégation de modèles : Intégration OpenAI, Gemini, Anthropic, Azure etc.
Récupération automatique : Liste complète des modèles sans configuration manuelle.
Rotation de clés : Utilisation cyclique de multiples clés API contre les limitations.
Avatars personnalisés : Attribution automatique d'icônes identitaires par modèle.
Fournisseurs personnalisés : Compatibilité avec services tiers respectant les normes OpenAI/Gemini/Anthropic.
CSS personnalisé : Personnalisation globale du style visuel.
Dispositions de chat : Différents modes d'affichage inclus.
Personnalisation d'avatar : Icônes personnalisées pour logiciel et assistants.
Menu latéral ajustable : Masquage/réorganisation des éléments selon besoins.
Multiformats : Import PDF, DOCX, PPTX, XLSX, TXT, MD etc.
Sources variées : Fichiers locaux, URL, sitemaps ou saisie manuelle.
Export des connaissances : Partage des bases traitées.
Vérification intégrée : Tests de segmentation et résultats immédiats après import.
Questions rapides : Assistance instantanée depuis toute application (Wechat, navigateur).
Traduction rapide : Traduction contextuelle de textes sélectionnés.
Résumé : Synthèse rapide de contenus longs.
Explications contextuelles : Clarification sans prompts complexes.
Sauvegardes multiples : Locale, WebDAV et programmée.
Confiance locale totale : Usage complet en environnement offline avec modèles locaux.
Convivial pour débutants : Accessible sans connaissances techniques préalables.
Documentation complète : Guides détaillés et FAQ complète.
Améliorations continues : Évolutions régulières basées sur les retours utilisateurs.
Ouverture et extensibilité : Code source ouvert pour customisations avancées.
Gestion & consultation de connaissances : Recherche académique, éducation...
Dialogues créatifs : Génération de contenu multimodal.
Traduction & automatisation : Communication multilingue et traitement documentaire.
Peinture IA & design : Visualisation créative par description textuelle.
暂时不支持Claude模型
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Avant d'obtenir une clé API Gemini, vous devez avoir un projet Google Cloud (si vous en avez déjà un, cette étape peut être ignorée)
Accédez à pour créer un projet, remplissez le nom du projet et cliquez sur "Créer un projet"
Accédez à la
Activez dans le projet créé
Ouvrez l'interface des permissions et créez un compte de service
Sur la page de gestion des comptes de service, trouvez le compte nouvellement créé, cliquez sur Clés et créez une nouvelle clé au format JSON
Après création réussie, le fichier de clé sera automatiquement enregistré sur votre ordinateur au format JSON - veuillez le conserver en lieu sûr
Sélectionnez le fournisseur de services Vertex AI
Remplissez les champs correspondants avec les données du fichier JSON
Cliquez sur "Ajouter " pour commencer à utiliser joyeusement !
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Sur la page officielle des , cliquez sur + Create new secret key
Copiez la clé générée, puis accédez aux de CherryStudio
Recherchez le fournisseur OpenAI et saisissez la clé obtenue
Cliquez sur "Gérer" ou "Ajouter" en bas de page, ajoutez les modèles pris en charge, puis activez le bouton du fournisseur en haut à droite pour commencer à l'utiliser.
如何在 Cherry Studio 使用联网模式
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Dans la fenêtre de question de Cherry Studio, cliquez sur l'icône 【Globe terrestre】 pour activer le mode en ligne.
Mode 1 : Les modèles des opérateurs possèdent une fonction de recherche en ligne intégrée
Dans ce cas, après avoir activé le mode en ligne, vous pouvez directement utiliser le service, c'est très simple.
Vous pouvez rapidement vérifier si un modèle prend en charge la connexion Internet en cherchant une petite icône de carte après son nom dans la partie supérieure de l'interface de question-réponse.
Sur la page de gestion des modèles, cette méthode vous permet également de distinguer rapidement les modèles prenant en charge le mode en ligne.
Opérateurs de modèles avec fonction de recherche en ligne actuellement pris en charge par Cherry Studio
Google Gemini
OpenRouter (tous les modèles prennent en charge la connexion Internet)
Tencent Hunyuan
Zhipu AI
Alibaba Cloud Bailian, etc.
Remarque importante : Il existe un cas particulier où même sans l'icône de globe terrestre, un modèle peut accéder à Internet, comme expliqué dans le tutoriel ci-dessous.
Mode 2 : Les modèles sans fonction de recherche utilisent le service Tavily pour accéder à Internet
Lorsqu'un modèle ne possède pas de fonction de recherche intégrée (pas d'icône de globe après son nom), mais que vous avez besoin d'informations en temps réel, utilisez le service de recherche Internet Tavily.
Lors de la première utilisation du service Tavily, une fenêtre contextuelle vous guidera dans la configuration. Suivez simplement les instructions !
Après avoir cliqué "Obtenir la clé", vous serez redirigé vers le site officiel de Tavily. Inscrivez-vous, connectez-vous, créez une clé API, puis copiez-la dans Cherry Studio.
Besoin d'aide pour l'inscription ? Consultez le tutoriel dans ce même répertoire.
Document de référence pour Tavily :
L'interface suivante indique une inscription réussie.
Testez à nouveau : les résultats montrent une recherche Internet fonctionnelle, avec un nombre de résultats par défaut de 5.
Remarque : Tavily impose des limites d'utilisation gratuite mensuelle. Le dépassement entraîne des frais.
PS : Si vous détectez des erreurs, n'hésitez pas à nous contacter.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
L'installation automatique du MCP nécessite la mise à niveau de Cherry Studio en version v1.1.18 ou ultérieure.
En complément de l'installation manuelle, Cherry Studio intègre l'outil @mcpmarket/mcp-auto-install, offrant une méthode plus pratique pour installer un serveur MCP. Il suffit d'entrer la commande appropriée dans une conversation avec un modèle prenant en charge les services MCP.
Rappel de la phase de test :
@mcpmarket/mcp-auto-install est actuellement en phase de test
L'efficacité dépend de "l'intelligence" du modèle : certaines configurations s'appliquent automatiquement, d'autres exigent des ajustements manuels dans les paramètres MCP
La source de recherche actuelle est @modelcontextprotocol, modifiable via configuration (voir ci-dessous)
Par exemple, saisissez :
Le système identifie automatiquement votre requête et complète l'installation via @mcpmarket/mcp-auto-install. Cet outil prend en charge divers types de serveurs MCP, notamment :
filesystem (système de fichiers)
fetch (requête réseau)
sqlite (base de données)
etc.
La variable MCP_PACKAGE_SCOPES permet de personnaliser les sources de recherche des services MCP (valeur par défaut :
@modelcontextprotocol).
@mcpmarket/mcp-auto-installCe document a été traducido del chino por IA y aún no ha sido revisado.
La base de connaissances Dify MCP nécessite de mettre à jour Cherry Studio vers la version v1.2.9 ou supérieure.
Ouvrez 搜索MCP.
Ajoutez le serveur dify-knowledge.
Il est nécessaire de configurer les paramètres et les variables d'environnement
La clé de la base de connaissances Dify peut être obtenue de la manière suivante
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Le prétraitement des documents de la base de connaissances nécessite la mise à niveau de Cherry Studio vers la version v1.4.8 ou ultérieure.
Après avoir cliqué sur "Obtenir la clé API", l'adresse de demande s'ouvrira dans votre navigateur. Cliquez sur "Demander maintenant", remplissez le formulaire pour obtenir votre clé API, puis saisissez-la dans le champ correspondant.
Dans la base de connaissances créée, effectuez la configuration ci-dessus pour finaliser la configuration du prétraitement des documents.
Vous pouvez utiliser la recherche en haut à droite pour vérifier les résultats de la base de connaissances
Astuce pour la base de connaissances : Lors de l'utilisation de modèles plus performants, modifiez le mode de recherche de la base de connaissances en "reconnaissance d'intention". Cette méthode permet une description plus précise et complète de votre question.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Nous sommes heureux d'accueillir les contributions à Cherry Studio ! Vous pouvez contribuer de plusieurs manières :
Contribuer au code : Développer de nouvelles fonctionnalités ou optimiser le code existant.
Corriger des bugs : Soumettre des corrections pour les bogues que vous découvrez.
Gérer les problèmes : Aider à administrer les issues GitHub.
Conception du produit : Participer aux discussions de design.
Rédiger la documentation : Améliorer les manuels utilisateurs et guides.
Participation communautaire : Rejoindre les discussions et aider les utilisateurs.
Promouvoir l'utilisation : Faire connaître Cherry Studio.
Envoyez un email à
Objet : Demande pour devenir contributeur Corps : Raison de votre candidature
# Huawei Cloud
I. Créez un compte et connectez-vous sur [Huawei Cloud](https://auth.huaweicloud.com/authui/login)
II. Cliquez sur [ce lien](https://console.huaweicloud.com/modelarts/?region=cn-southwest-2#/model-studio/homepage) pour accéder à la console ModelArts
III. Autorisation
<details>
<summary>Procédure d'autorisation (ignorer si déjà autorisé)</summary>
1. Après avoir accédé au lien (II), suivez les instructions pour accéder à la page d'autorisation (cliquez sur Utilisateur IAM → Nouvelle délégation → Utilisateur standard)
.png>)
2. Après avoir cliqué sur Créer, revenez à la page du lien (II)
3. Un message indique des autorisations d'accès insuffisantes, cliquez sur "Cliquez ici" dans le message
4. Ajoutez l'autorisation existante et confirmez
.png>)
Note : Cette méthode convient aux débutants, pas besoin de lire beaucoup de contenu, suivez simplement les instructions. Si vous parvenez à obtenir l'autorisation du premier coup, utilisez votre propre méthode.
</details>
IV. Cliquez sur Gestion de l'authentification dans la barre latérale, créez une clé API (secret) et copiez-la
<figure><img src="../../.gitbook/assets/微信截图_20250214034650.png" alt=""><figcaption></figcaption></figure>
Puis créez un nouveau fournisseur dans CherryStudio
<figure><img src="../../.gitbook/assets/image (1) (2).png" alt="" width="300"><figcaption></figcaption></figure>
Après création, saisissez la clé secrète
V. Cliquez sur Déploiement de modèles dans la barre latérale et récupérez tous
<figure><img src="../../.gitbook/assets/微信截图_20250214034751.png" alt=""><figcaption></figcaption></figure>
VI. Cliquez sur Appel
<figure><img src="../../.gitbook/assets/image (1) (2) (1).png" alt=""><figcaption></figcaption></figure>
Copiez l'adresse à ①, collez-la dans l'adresse du fournisseur CherryStudio et ajoutez un "#" à la fin
et ajoutez un "#" à la fin
et ajoutez un "#" à la fin
et ajoutez un "#" à la fin
et ajoutez un "#" à la fin
Pourquoi ajouter un "#" ? [Voir ici](https://docs.cherry-ai.com/cherrystudio/preview/settings/providers#api-di-zhi)
> Bien sûr, vous pouvez aussi ignorer cela et suivre simplement le tutoriel;
> Vous pouvez également utiliser la méthode de suppression de v1/chat/completions pour remplir. Utilisez votre méthode si vous savez comment faire, sinon suivez strictement le tutoriel.
<figure><img src="../../.gitbook/assets/image (2) (3).png" alt=""><figcaption></figcaption></figure>
Copiez ensuite le nom du modèle à ②, dans CherryStudio cliquez sur le bouton "+Ajouter" pour créer un nouveau modèle
<figure><img src="../../.gitbook/assets/image (4) (3).png" alt=""><figcaption></figcaption></figure>
Saisissez le nom du modèle tel quel, sans modifications ou guillemets. Copiez exactement comme dans l'exemple.
<figure><img src="../../.gitbook/assets/image (3) (3).png" alt=""><figcaption></figcaption></figure>
Cliquez sur Ajouter un modèle pour terminer.
{% hint style="info" %}
Dans Huawei Cloud, chaque modèle ayant une adresse différente, chaque modèle nécessite un nouveau fournisseur. Répétez simplement les étapes ci-dessus.
{% endhint %}














帮我安装一个 filesystem mcp server// `axun-uUpaWEdMEMU8C61K` correspond à l'ID de service, personnalisable
"axun-uUpaWEdMEMU8C61K": {
"name": "mcp-auto-install",
"description": "Automatically install MCP services (Beta version)",
"isActive": false,
"registryUrl": "https://registry.npmmirror.com",
"command": "npx",
"args": [
"-y",
"@mcpmarket/mcp-auto-install",
"connect",
"--json"
],
"env": {
"MCP_REGISTRY_PATH": "Détails sur https://www.npmjs.com/package/@mcpmarket/mcp-auto-install"
},
"disabledTools": []
}















































































Ce document a été traducido del chino por IA y aún no ha sido revisado.
Contactez par e-mail [email protected] pour obtenir l'accès éditeur
Sujet : Demande d'accès éditeur à Cherry Studio Docs Corps : Indiquez vos motivations










Ce document a été traducido del chino por IA y aún no ha sido revisado.
Bienvenue sur Cherry Studio (ci-après dénommé "ce logiciel" ou "nous"). Nous accordons une grande importance à la protection de votre vie privée. Cette politique de confidentialité explique comment nous traitons et protégeons vos informations personnelles et vos données. Veuillez lire attentivement et comprendre cette politique avant d'utiliser ce logiciel :
Pour optimiser l'expérience utilisateur et améliorer la qualité du logiciel, nous ne collectons que les informations non personnelles suivantes de manière anonyme :
• Informations sur la version du logiciel ; • Activité et fréquence d'utilisation des fonctionnalités du logiciel ; • Journaux de plantages et d'erreurs anonymes ;
Ces informations sont totalement anonymes, ne concernent aucune donnée d'identification personnelle et ne peuvent être associées à vos informations personnelles.
Pour protéger au maximum votre vie privée, nous nous engageons explicitement à :
• Ne pas collecter, conserver, transmettre ou traiter les informations de clé API des services de modèles que vous saisissez dans ce logiciel ; • Ne pas collecter, conserver, transmettre ou traiter les données de conversation générées lors de votre utilisation de ce logiciel, y compris mais sans s'y limiter : contenu des discussions, informations d'instruction, données de base de connaissances, données vectorielles et autres contenus personnalisés ; • Ne pas collecter, conserver, transmettre ou traiter des informations sensibles permettant d'identifier personnellement un individu.
Ce logiciel utilise la clé API des fournisseurs de services de modèles tiers que vous avez demandée et configurée vous-même, afin d'effectuer les appels aux modèles correspondants et d'assurer les fonctionnalités de conversation. Les services de modèles que vous utilisez (par exemple, grands modèles, interfaces API, etc.) sont fournis par le fournisseur tiers que vous avez choisi et relèvent entièrement de sa responsabilité. Cherry Studio agit uniquement comme un outil local fournissant des fonctions d'appel d'interface avec les services de modèles tiers.
Par conséquent :
• Toutes les données de conversation générées entre vous et les services de grands modèles sont indépendantes de Cherry Studio. Nous ne participons ni au stockage des données, ni à toute forme de transmission ou de transit de données ; • Vous devez consulter et accepter vous-même la politique de confidentialité et les politiques associées du fournisseur de services de modèles tiers correspondant. Ces politiques de confidentialité sont accessibles sur les sites officiels de chaque fournisseur.
Vous assumez vous-même les risques potentiels pour la vie privée liés à l'utilisation des services de fournisseurs de modèles tiers. Pour les politiques de confidentialité spécifiques, les mesures de sécurité des données et les responsabilités associées, veuillez consulter le contenu pertinent sur le site officiel du fournisseur de services de modèles choisi. Nous déclinons toute responsabilité à cet égard.
Cette politique peut être ajustée lors des mises à jour des versions du logiciel. Veuillez la consulter régulièrement. En cas de modification substantielle de la politique, nous vous en informerons par des moyens appropriés.
Si vous avez des questions concernant le contenu de cette politique ou les mesures de protection de la vie privée de Cherry Studio, n'hésitez pas à nous contacter à tout moment.
Nous vous remercions d'avoir choisi et fait confiance à Cherry Studio. Nous continuerons à vous offrir une expérience produit sûre et fiable.












Ce document a été traducido del chino por IA y aún no ha sido revisado.
Pour permettre à chaque développeur et utilisateur d'expérimenter facilement les capacités des grands modèles de pointe, Zhipu ouvre gratuitement le modèle GLM-4.5-Air aux utilisateurs de Cherry Studio. Conçu spécialement pour les applications d'agents intelligents (Agent), ce modèle fondamental efficace offre un équilibre exceptionnel entre performance et coût, représentant le choix idéal pour construire des applications intelligentes.
🚀 Qu'est-ce que GLM-4.5-Air ?
GLM-4.5-Air est le dernier modèle linguistique haute performance de Zhipu, utilisant une architecture avancée d'experts mixtes (Mixture-of-Experts, MoE) qui maintient une capacité de raisonnement exceptionnelle tout en réduisant significativement la consommation de ressources informatiques.
Paramètres totaux : 106 milliards
Paramètres activés : 12 milliards
Grâce à sa conception épurée, GLM-4.5-Air offre une meilleure efficacité d'inférence, idéale pour des déploiements en environnement contraint tout en conservant une aptitude à traiter des tâches complexes.
📚 Flux de formation unifié, base solide d'intelligence
GLM-4.5-Air partage le même flux de formation que la série phare, garantissant une base solide de capacités universelles :
Préformation à grande échelle : Entraînement sur un corpus général de 15 000 milliards de tokens accumulant une large compréhension ;
Optimisation spécifique : Renforcement sur tâches clés comme la génération de code, le raisonnement logique et les interactions agents ;
Contexte étendu : Longueur de contexte augmentée à 128K tokens, traitant documents longs, dialogues complexes ou projets de code volumineux ;
Amélioration par apprentissage par renforcement : Optimisation des capacités décisionnelles en planification et appel d'outils via RL.
Ce système confère à GLM-4.5-Air une excellente capacité de généralisation et d'adaptation aux tâches.
⚙️ Capacités optimisées pour les agents intelligents
GLM-4.5-Air est spécialement adapté aux scénarios d'agents avec ces capacités pratiques :
✅ Appel d'outils : Interfaçage normé pour automatiser des tâches via des outils externes ✅ Navigation et extraction web : Compréhension et interaction avec du contenu dynamique via extensions ✅ Assistance génie logiciel : Analyse des besoins, génération de code, détection/réparation de bugs ✅ Support front-end : Bonne compréhension/génération des technologies HTML/CSS/JavaScript
Intégrable aux frameworks d'agents de code comme Claude Code ou Roo Code, il sert aussi de moteur central pour tout agent personnalisé.
💡 Mode "réflexion intelligente", adaptation souple aux requêtes
GLM-4.5-Air propose un mode de raisonnement hybride contrôlé par le paramètre thinking.type :
enabled : Réflexion approfondie pour tâches complexes nécessitant une planification
disabled : Désactivée pour requêtes simples ou réponses instantanées
Valeur par défaut : mode réflexion dynamique (auto-évaluation de la nécessité d'analyse)
Tâche simple (réflexion déconseillée)
• Question : "Quand Zhipu AI a été créée ?" • Traduction : "Traduis 'I love you' en chinois"
Tâche moyenne (réflexion conseillée)
• Comparaison avion/TGV Pékin-Shanghai • Explication du nombre élevé de lunes de Jupiter
Tâche complexe (réflexion fortement conseillée)
• Explication de la collaboration experte dans MoE • Analyse d'opportunité d'achat d'ETF
🌟 Efficace et rentable, déploiement simplifié
GLM-4.5-Air atteint un équilibre optimal performance/coût pour déploiements professionnels :
⚡ Vitesse > 100 tokens/sec pour interactions réactives à faible latence
💰 Coût API très bas : Entrée 0.8 ¥ / million tokens, sortie 2 ¥ / million tokens
🖥️ Faible consommation de ressources informatiques, déploiement aisé local/cloud haute concurrency
Une véritable expérience IA "haute performance, faible barrière d'entrée".
🧠 Capacité clé : génération intelligente de code
GLM-4.5-Air excelle en génération de code avec :
Support des langages Python, JavaScript, Java
Génération de code lisible, maintenable via instructions naturelles
Réduction du code "boilerplate", alignement aux besoins réels
Idéal pour prototypage rapide, complétion auto et correction de bugs.
Expérimentez gratuitement GLM-4.5-Air dès maintenant et lancez votre projet d'agent intelligent ! Que vous construisiez un assistant auto, un compagnon de programmation ou une application IA nouvelle génération, GLM-4.5-Air sera votre moteur IA fiable et performant.
📘 Connectez-vous immédiatement pour libérer votre créativité !
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cherry Studio prend en charge la sauvegarde des données via le protocole WebDAV. Vous pouvez choisir un service WebDAV adapté pour effectuer des sauvegardes dans le cloud.
Basé sur WebDAV, il est possible de synchroniser les données entre plusieurs appareils via le schéma : Ordinateur A WebDAV Ordinateur B.
Connectez-vous à Nutstore, cliquez sur votre nom d'utilisateur en haut à droite et sélectionnez "Informations du compte" :
Choisissez "Options de sécurité" puis cliquez sur "Ajouter une application" :
Entrez le nom de l'application et générez un mot de passe aléatoire :
Copiez et enregistrez le mot de passe :
Récupérez l'adresse du serveur, le compte et le mot de passe :
Dans les paramètres de Cherry Studio → Paramètres des données, renseignez les informations WebDAV :
Sélectionnez la sauvegarde ou la restauration des données, et configurez si besoin la périodicité des sauvegardes automatiques :
Les services WebDAV les plus accessibles sont généralement les solutions de stockage cloud :
123 Pan (abonnement requis)
Aliyun Drive (achat requis)
Box (espace gratuit de 10 Go, limitation à 250 Mo par fichier)
Dropbox (2 Go gratuits, extensibles à 16 Go par parrainage)
TeraCloud (10 Go gratuits + 5 Go supplémentaires par invitation)
Yandex Disk (10 Go pour les utilisateurs gratuits)
Solutions nécessitant un déploiement autonome :
如何注册tavily?
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Accédez au site officiel ci-dessus ou, depuis Cherry Studio > Paramètres > Recherche Web > Cliquez sur "Obtenir une clé", ce qui vous redirigera directement vers la page de connexion/d'inscription de Tavily.
Si c'est votre première utilisation, vous devez d'abord créer un compte (Sign up) avant de pouvoir vous connecter (Log in). Par défaut, vous serez redirigé vers la page de connexion.
Cliquez sur "S'inscrire", entrez votre e-mail habituel ou utilisez votre compte Google/GitHub, puis définissez un mot de passe (procédure standard).
🚨🚨🚨ÉTAPE CRUCIALE Après l'inscription, une vérification en deux étapes est nécessaire : scannez le QR code pour générer un code à usage unique.
Deux solutions :
Téléchargez l'application Microsoft Authenticator (légèrement complexe)
Utilisez le mini-programme WeChat : Authentificateur Tencent (simple, recommandé)
Sur WeChat, recherchez le mini-programme : Authentificateur Tencent
Après ces étapes, l'interface ci-dessous s'affiche : copiez votre clé dans Cherry Studio pour commencer à l'utiliser.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Ollama est un excellent outil open source qui vous permet d'exécuter et de gérer facilement divers grands modèles de langage (LLM) localement. Cherry Studio prend désormais en charge l'intégration d'Ollama, vous permettant d'interagir directement avec des LLM déployés localement dans une interface familière, sans dépendre des services cloud !
Ollama est un outil qui simplifie le déploiement et l'utilisation des grands modèles de langage (LLM). Il présente les caractéristiques suivantes :
Exécution locale : Les modèles s'exécutent entièrement sur votre ordinateur local, sans nécessiter de connexion Internet, protégeant ainsi votre vie privée et la sécurité de vos données.
Simplicité d'utilisation : Avec de simples commandes en ligne de commande, vous pouvez télécharger, exécuter et gérer divers LLM.
Modèles variés : Prend en charge de nombreux modèles open source populaires tels que Llama 2, Deepseek, Mistral, Gemma, etc.
Multiplateforme : Compatible avec les systèmes macOS, Windows et Linux.
API ouverte : Prend en charge une interface compatible avec OpenAI, permettant une intégration avec d'autres outils.
Pas de service cloud nécessaire : Plus de limitations de quotas ou de frais liés aux API cloud, profitez pleinement de la puissance des LLM locaux.
Confidentialité des données : Toutes vos données de conversation restent sur votre appareil local, vous n'avez pas à craindre la fuite de vos données privées.
Disponible hors ligne : Vous pouvez continuer à interagir avec le LLM même sans connexion Internet.
Personnalisation : Vous pouvez sélectionner et configurer le LLM qui vous convient le mieux selon vos besoins.
Tout d'abord, vous devez installer et exécuter Ollama sur votre ordinateur. Suivez ces étapes :
Télécharger Ollama : Visitez le site officiel d'Ollama (https://ollama.com/), téléchargez le package d'installation correspondant à votre système d'exploitation. Pour Linux, vous pouvez directement exécuter la commande suivante pour installer Ollama :
curl -fsSL https://ollama.com/install.sh | shInstaller Ollama : Suivez les instructions de l'installateur pour terminer l'installation.
Télécharger un modèle : Ouvrez un terminal (ou invite de commandes), utilisez la commande ollama run pour télécharger le modèle que vous souhaitez utiliser. Par exemple, pour télécharger le modèle Llama 2, vous pouvez exécuter :
ollama run llama3.2Ollama téléchargera et exécutera automatiquement ce modèle.
Gardez Ollama en cours d'exécution : Pendant que vous interagissez avec les modèles Ollama via Cherry Studio, assurez-vous qu'Ollama reste en cours d'exécution.
Ensuite, ajoutez Ollama en tant que fournisseur de services d'IA personnalisé dans Cherry Studio :
Ouvrir les paramètres : Dans la barre de navigation gauche de l'interface Cherry Studio, cliquez sur "Paramètres" (icône d'engrenage).
Accéder aux services de modèle : Sur la page des paramètres, sélectionnez l'onglet "Services de modèle".
Ajouter un fournisseur : Cliquez sur Ollama dans la liste.
Dans la liste des fournisseurs de services, trouvez l'Ollama que vous venez d'ajouter et configurez-le en détail :
État d'activation :
Assurez-vous que l'interrupteur à l'extrême droite du fournisseur Ollama est activé, indiquant qu'il est en service.
Clé API :
Ollama n'a pas besoin par défaut d'une clé API. Vous pouvez laisser ce champ vide ou y mettre n'importe quel contenu.
Adresse API :
Remplissez l'adresse de l'API locale fournie par Ollama. Généralement, l'adresse est :
http://localhost:11434/Si vous avez modifié le port, ajustez-le en conséquence.
Temps de maintien en activité : Cette option définit la durée de maintien de la session en minutes. Si aucune nouvelle conversation n'a lieu dans le temps imparti, Cherry Studio se déconnecte automatiquement d'Ollama pour libérer des ressources.
Gestion des modèles :
Cliquez sur le bouton "+ Ajouter" pour ajouter manuellement le nom du modèle que vous avez déjà téléchargé dans Ollama.
Par exemple, si vous avez téléchargé le modèle llama3.2 via ollama run llama3.2, vous pouvez entrer llama3.2 ici.
Cliquez sur le bouton "Gérer" pour modifier ou supprimer les modèles ajoutés.
Une fois la configuration ci-dessus terminée, vous pouvez dans l'interface de chat de Cherry Studio, sélectionner le fournisseur de services Ollama et le modèle que vous avez téléchargé, et commencer à dialoguer avec votre LLM local !
Première exécution d'un modèle : Lors de la première exécution d'un modèle, Ollama a besoin de télécharger les fichiers du modèle, ce qui peut prendre du temps, soyez patient.
Voir les modèles disponibles : Exécutez la commande ollama list dans un terminal pour voir la liste des modèles Ollama que vous avez téléchargés.
Exigences matérielles : L'exécution de grands modèles de langage nécessite certaines ressources informatiques (CPU, mémoire, GPU), assurez-vous que la configuration de votre ordinateur répond aux exigences du modèle.
Documentation d'Ollama : Vous pouvez cliquer sur le lien Voir la documentation et les modèles d'Ollama dans la page de configuration pour accéder rapidement à la documentation officielle d'Ollama.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
L'Assistant permet de personnaliser les paramètres du modèle sélectionné pour l'utiliser, comme les préréglages de prompts et de paramètres. Ces réglages permettent d'aligner le modèle sur vos attentes de travail.
L'Assistant par défaut du système contient des paramètres génériques (sans prompt). Vous pouvez l'utiliser directement ou chercher des préréglages adaptés dans la .
L'Assistant est le parent des Sujets. Un assistant unique peut créer plusieurs sujets (conversations). Tous les sujets partagent les mêmes paramètres et prompts de l'assistant.
Nouveau sujet Crée un nouveau sujet dans l'assistant actuel.
Importer image ou document
Images : nécessitent une prise en charge par le modèle
Documents : analysés automatiquement en texte comme contexte pour le modèle.
Recherche web Configurez d'abord les paramètres dans les réglages. Les résultats alimentent le contexte du modèle. Voir .
Base de connaissances Active la base de connaissances. Voir .
Serveur MCP Active la fonctionnalité de serveur MCP. Voir .
Générer une image Non affiché par défaut. Pour les modèles compatibles (ex : Gemini), activez manuellement pour générer des images.
Choisir un modèle Change le modèle pour les réponses suivantes tout en conservant le contexte.
Phrases rapides Utilisez des phrases prédéfinies dans les réglages. Supporte les variables.
Effacer les messages Supprime tout le contenu du sujet actuel.
Agrandir Agrandit la zone de dialogue pour les longs textes.
Effacer le contexte Réinitialise le contexte du modèle sans supprimer le contenu ("oubli" des conversations précédentes).
Estimation Tokens Affiche :
Contexte actuel
Contexte max (∞ = illimité)
Caractères saisis
Tokens estimés
Traduire Traduit le contenu actuel en anglais.
Synchronisés avec les Paramètres du modèle des paramètres de l'assistant. Voir .
Séparateur de messages :Ajoute une ligne de séparation entre le contenu et les actions.
Utiliser les polices serif :Change le style de police. Personnalisation via .
Afficher les numéros de ligne des blocs de code :Affiche les numéros de ligne pour les extraits de code.
Blocs de code repliables :Replie automatiquement les blocs de code longs.
Retour à la ligne dans les blocs de code :Retourne à la ligne automatiquement pour les longues lignes de code.
Repli automatique des processus de réflexion :Replie automatiquement le raisonnement des modèles après réflexion.
Style des messages :Bulle de discussion ou style liste.
Thème des blocs de code :Change le style d'affichage des extraits de code.
Moteur de formules mathématiques :KaTeX : Rendu rapide (optimisé performance)
MathJax : Rendu lent mais complet (plus de symboles)
Taille de police des messages :Ajuste la taille du texte.
Afficher l'estimation de Tokens :Affiche les Tokens estimés pour le texte saisi (indicatif).
Coller les longs textes en tant que fichier :Transforme les longs textes collés en fichiers pour éviter les interférences.
Rendu Markdown pour les messages entrants :Désactivé : Ne rend que les réponses du modèle. Activé : Rend aussi les messages envoyés.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
La plateforme de service MaaS renommée "Silicom Flow" offre gratuitement un service d'appel du modèle Qwen3-8B à tous. Membre à haut rendement de la série Qwen3 de Tongyi Qianwen, Qwen3-8B allie performances puissantes et format compact, idéal pour les applications intelligentes et le développement efficace.
🚀 Qu'est-ce que Qwen3-8B ?
Qwen3-8B est un modèle dense de 8 milliards de paramètres de la troisième génération de grands modèles Tongyi Qianwen publié par Alibaba en avril 2025. Adoptant la licence open source Apache 2.0, il peut être librement utilisé dans des contextes commerciaux et de recherche.
Paramètres totaux : 8 milliards
Type d'architecture : Dense (structure purement dense)
Longueur contextuelle : 128K tokens
Multilingue : prend en charge 119 langues et dialectes
Malgré sa taille compacte, Qwen3-8B affiche des performances stables en raisonnement, code, mathématiques et capacités d'agent, rivalisant avec les grands modèles précédents et démontrant une praticabilité exceptionnelle.
📚 Base d'entraînement solide, grande intelligence dans un petit format
Qwen3-8B est pré-entraîné sur environ 36 billions de tokens de données multilingues de haute qualité, couvrant textes web, documents techniques, bases de code et données synthétiques spécialisées pour une vaste couverture des connaissances.
Sa post-formation intègre un processus de renforcement en quatre étapes, optimisant spécifiquement :
✅ Compréhension et génération du langage naturel ✅ Raisonnement mathématique et analyse logique ✅ Traduction et expression multilingues ✅ Appel d'outils et planification de tâches
Grâce à cette amélioration systémique, les performances réelles de Qwen3-8B égalent voire surpassent Qwen2.5-14B, marquant un bond significatif en efficacité paramétrique.
💡 Mode de raisonnement hybride : réfléchir ou répondre rapidement ?
Qwen3-8B permet une commutation flexible entre "mode réflexion" et "mode non-réflexion", permettant aux utilisateurs de choisir la réponse selon la complexité de la tâche.
Contrôle via :
Paramètre API : enable_thinking=True/False
Commande dans le prompt : ajouter /think ou /no_think à l'entrée
Ce design offre un équilibre personnalisable entre vitesse de réponse et profondeur de raisonnement, optimisant l'expérience utilisateur.
⚙️ Capacités Agent natives pour des applications intelligentes
Qwen3-8B possède d'excellentes capacités d'agentisation, s'intégrant facilement dans divers systèmes automatisés :
🔹 Appel de fonctions (Function Calling) : prise en charge des appels d'outils structurés 🔹 Compatibilité MCP : support natif du protocole de contexte de modèle pour étendre les capacités externes 🔹 Collaboration multi-outils : intègre des plugins comme la recherche, calculatrice, exécution de code, etc.
Recommandé avec le framework Qwen-Agent pour construire rapidement des assistants intelligents dotés de mémoire, planification et capacités d'exécution.
🌐 Support linguistique étendu pour des applications mondiales
Qwen3-8B prend en charge 119 langues et dialectes dont chinois, anglais, arabe, espagnol, japonais, coréen et indonésien. Idéal pour :
Développement de produits internationaux
Service client multilingue
Génération de contenu polyglotte
Excellente compréhension du chinois (simplifié, traditionnel, cantonais), adapté aux marchés de Hong Kong, Macao, Taiwan et communautés chinoises d'outre-mer.
🧠 Fortes capacités pratiques, large spectre d'applications
Qwen3-8B excelle dans des scénarios fréquents :
✅ Génération de code : Python, JavaScript, Java, etc. ; produit du code exécutable sur demande ✅ Raisonnement mathématique : résultats stables sur des benchmarks comme GSM8K, adapté aux applications éducatives ✅ Création de contenu : rédige e-mails, rapports, textes avec structure claire et langage naturel ✅ Assistant intelligent : construit des IA légères pour FAQ de bases de connaissances, gestion d'agendas, extraction d'informations
Essayez gratuitement Qwen3-8B dès maintenant via Silicom Flow et lancez votre voyage dans l'IA légère !
📘 Utilisez-le maintenant, rendez l'IA accessible !
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cherry Studio intègre non seulement les principaux services de modèles d'IA, mais vous offre également une puissante capacité de personnalisation. Grâce à la fonctionnalité Fournisseurs d'IA personnalisés, vous pouvez facilement intégrer n'importe quel modèle d'IA dont vous avez besoin.
Flexibilité : Libérez-vous des limites des listes prédéfinies de fournisseurs, choisissez librement le modèle d'IA qui correspond le mieux à vos besoins.
Diversité : Essayez divers modèles d'IA de différentes plateformes, découvrez leurs avantages uniques.
Contrôle : Gérez directement vos clés API et adresses d'accès pour garantir la sécurité et la confidentialité.
Personnalisation : Intégrez des modèles déployés en privé pour répondre aux besoins de scénarios métiers spécifiques.
En quelques étapes simples, vous pouvez ajouter votre fournisseur d'IA personnalisé à Cherry Studio :
Ouvrir les paramètres : Dans la barre de navigation de gauche de l'interface Cherry Studio, cliquez sur "Paramètres" (icône d'engrenage).
Accéder aux services de modèles : Dans la page des paramètres, sélectionnez l'onglet "Services de modèles".
Ajouter un fournisseur : Sur la page "Services de modèles", vous verrez la liste des fournisseurs existants. Cliquez sur le bouton "+ Ajouter" sous la liste pour ouvrir la fenêtre contextuelle "Ajouter un fournisseur".
Remplir les informations : Dans la fenêtre contextuelle, vous devez remplir les informations suivantes :
Nom du fournisseur : Attribuez un nom facilement identifiable à votre fournisseur personnalisé (exemple : MyCustomOpenAI).
Type de fournisseur : Sélectionnez le type de votre fournisseur dans la liste déroulante. Actuellement pris en charge :
OpenAI
Gemini
Anthropic
Azure OpenAI
Enregistrer la configuration : Après avoir rempli les informations, cliquez sur le bouton "Ajouter" pour sauvegarder votre configuration.
Après l'ajout, vous devez trouver le fournisseur que vous venez d'ajouter dans la liste et effectuer une configuration détaillée :
État d'activation : À l'extrémité droite de la liste des fournisseurs personnalisés se trouve un interrupteur d'activation. L'activer signifie que ce service personnalisé est activé.
Clé API :
Saisissez la clé API (API Key) fournie par votre fournisseur de services d'IA.
Cliquez sur le bouton "Vérifier" à droite pour vérifier la validité de la clé.
Adresse API :
Renseignez l'adresse d'accès API (Base URL) du service d'IA.
Veuillez consulter la documentation officielle de votre fournisseur d'IA pour obtenir l'adresse API correcte.
Gestion des modèles :
Cliquez sur le bouton "+ Ajouter" pour ajouter manuellement l'ID du modèle que vous souhaitez utiliser sous ce fournisseur. Par exemple gpt-3.5-turbo, gemini-pro, etc.
* Si vous n'êtes pas sûr du nom exact du modèle, référez-vous à la documentation officielle de votre fournisseur d'IA. * Cliquez sur le bouton "Gérer" pour modifier ou supprimer les modèles déjà ajoutés.
Une fois la configuration ci-dessus terminée, vous pouvez sélectionner votre fournisseur d'IA personnalisé et votre modèle dans l'interface de chat de Cherry Studio pour commencer à dialoguer avec l'IA !
vLLM est une bibliothèque d'inférence LLM rapide et facile à utiliser, similaire à Ollama. Voici comment l'intégrer à Cherry Studio :
Installer vLLM : Suivez la documentation officielle de vLLM () pour l'installer.
Lancer le service vLLM : Démarrez le service en utilisant l'interface compatible OpenAI fournie par vLLM. Deux méthodes principales sont disponibles :
Lancer via vllm.entrypoints.openai.api_server
Lancer via uvicorn
Assurez-vous que le service démarre avec succès et qu'il écoute sur le port par défaut 8000. Vous pouvez également spécifier le port du service vLLM avec le paramètre --port.
Ajouter le fournisseur vLLM dans Cherry Studio :
Suivez les étapes décrites précédemment pour ajouter un nouveau fournisseur d'IA personnalisé.
Nom du fournisseur : vLLM
Type de fournisseur : Sélectionnez OpenAI.
Configurer le fournisseur vLLM :
Clé API : vLLM ne nécessitant pas de clé API, vous pouvez laisser ce champ vide ou saisir n'importe quel contenu.
Adresse API : Renseignez l'adresse API du service vLLM. Par défaut, l'adresse est : http://localhost:8000/ (si un port différent est utilisé, modifiez-le en conséquence).
Gestion des modèles : Ajoutez le nom du modèle que vous avez chargé dans vLLM. Dans l'exemple python -m vllm.entrypoints.openai.api_server --model gpt2, vous devez saisir gpt2.
Commencer à dialoguer : Vous pouvez désormais sélectionner le fournisseur vLLM et le modèle gpt2 dans Cherry Studio pour dialoguer avec le LLM alimenté par vLLM !
Lire attentivement la documentation : Avant d'ajouter un fournisseur personnalisé, lisez attentivement la documentation officielle de votre fournisseur d'IA pour connaître les informations clés telles que la clé API, l'adresse d'accès et les noms de modèles.
Vérifier la clé API : Utilisez le bouton "Vérifier" pour confirmer rapidement la validité de votre clé API et éviter les erreurs.
Attention à l'adresse API : L'adresse API peut varier selon les fournisseurs et modèles d'IA, assurez-vous de saisir l'adresse correcte.
Ajouter les modèles selon les besoins : N'ajoutez que les modèles que vous utiliserez réellement, évitez d'en ajouter trop inutilement.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Le stockage des données de Cherry Studio suit les conventions système. Les données sont automatiquement placées dans le répertoire utilisateur, aux emplacements spécifiques suivants :
macOS: /Users/username/Library/Application Support/CherryStudioDev
Windows: C:\Users\username\AppData\Roaming\CherryStudio
Linux: /home/username/.config/CherryStudio
Vous pouvez également visualiser cet emplacement ici :
Méthode 1 :
Utilisez des liens symboliques. Quittez le logiciel, déplacez les données vers votre emplacement souhaité, puis créez un lien à l'emplacement d'origine pointant vers le nouvel emplacement.
Consultez les étapes détaillées ici :
Méthode 2 : Modifiez l'emplacement via les paramètres de lancement, en exploitant les caractéristiques des applications Electron.
--user-data-dir Exemple : Cherry-Studio-*-x64-portable.exe --user-data-dir="%user_data_dir%"
Exemple :
init_cherry_studio.bat (encodage : ANSI)
Structure du répertoire user-data-dir après initialisation :
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Dans la version 0.9.1, CherryStudio introduit la fonction tant attendue de Base de Connaissances.
Voici le guide d'utilisation détaillé de CherryStudio, présenté étape par étape.
Recherchez des modèles dans le service de gestion des modèles. Vous pouvez cliquer sur "Modèles d'embedding" pour filtrer rapidement ;
Trouvez le modèle nécessaire et ajoutez-le à Mes modèles.
Accès : Dans la barre d'outils gauche de CherryStudio, cliquez sur l'icône Base de connaissances pour accéder à la page de gestion ;
Ajouter : Cliquez sur Ajouter pour commencer la création ;
Nommage : Entrez le nom de la base de connaissances et ajoutez un modèle d'embedding (par exemple bge-m3) pour finaliser la création.
Ajout de fichier : Cliquez sur le bouton d'ajout pour ouvrir la sélection de fichiers ;
Sélection : Choisissez des formats supportés (pdf, docx, pptx, xlsx, txt, md, mdx, etc.) ;
Vectorisation : Le système traite automatiquement les fichiers. Lorsqu'un ✓ vert apparaît, la vectorisation est terminée.
CherryStudio prend en charge plusieurs méthodes d'import :
Dossiers : Importer un dossier entier – les formats compatibles seront vectorisés automatiquement ;
Liens web : URLs comme ;
Sitemap : Fichiers XML de sitemap, ex : ;
Texte brut : Saisie manuelle de contenu personnalisé.
Après vectorisation, lancez une recherche :
Cliquez sur "Rechercher dans la base de connaissances" en bas de page ;
Saisissez votre requête ;
Consultez les résultats ;
Le score de correspondance est affiché pour chaque résultat.
Dans une nouvelle conversation, cliquez sur l'icône Base de connaissances dans la barre d'outils et sélectionnez une base ;
Posez votre question : le modèle répondra en utilisant les données référencées ;
Les sources utilisées sont attachées à la réponse pour consultation rapide.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
En personnalisant le CSS, vous pouvez modifier l'apparence du logiciel pour qu'elle corresponde mieux à vos préférences, par exemple comme ceci :
Pour plus de variables de thème, consultez le code source :
Bibliothèque de thèmes Cherry Studio :
Partage de thèmes Cherry Studio de style chinois :
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cherry Studio est un client desktop multi-modèles, compatible actuellement avec Windows, Linux et macOS. Il agrège les principaux modèles LLM et offre une assistance multi-scénarios. Les utilisateurs peuvent améliorer leur productivité grâce à une gestion intelligente des conversations, une personnalisation open source et des interfaces multi-thèmes.
Cherry Studio est désormais entièrement compatible avec les canaux API hautes performances de PPIO – en assurant une puissance de calcul professionnelle pour offrir des réponses rapides DeepSeek-R1/V3 et une disponibilité de service de 99,9%, vous garantissant une expérience fluide.
Le tutoriel ci-dessous contient la procédure complète d'intégration (incluant la configuration des clés), vous permettant d'activer le mode avancé « Cherry Studio + API hautes performances PPIO » en 3 minutes.
Commencez par télécharger Cherry Studio sur le site officiel : (si le lien ne fonctionne pas, vous pouvez utiliser ce lien alternatif Quark : )
(1) Cliquez d'abord sur l'icône des paramètres en bas à gauche, définissez le nom du fournisseur sur : PPIO, puis cliquez sur "Confirmer"
(2) Rendez-vous sur la , cliquez sur 【Avatar】→【Gestion des clés API】 pour accéder au panneau de contrôle
Cliquez sur le bouton 【+ Créer】 pour générer une nouvelle clé API. Attribuez-lui un nom personnalisé. La clé n'est visible qu'au moment de sa création : copiez-la impérativement et sauvegardez-la, sous peine de compromettre son utilisation ultérieure.
(3) Dans CherryStudio, collez la clé Cliquez sur les paramètres, sélectionnez 【PPIO 派欧云】, saisissez la clé API générée sur le site, puis cliquez sur 【Vérifier】
(4) Sélectionnez un modèle : prenons l'exemple de deepseek/deepseek-r1/community. Pour en changer, remplacez simplement le nom.
Les versions DeepSeek R1 et V3 community sont fournies à titre exploratoire. Ce sont des modèles complets et non limités, avec une stabilité et des performances identiques. Pour des appels intensifs, rechargez votre compte et basculez vers une version non-community.
(1) Une fois la 【vérification】 réussie, l'utilisation normale est possible
(2) Enfin, cliquez sur 【@】 et sélectionnez le modèle DeepSeek R1 nouvellement ajouté sous le fournisseur PPIO pour démarrer une conversation !
【Source partielle du matériel : 】
Pour un apprentissage visuel, nous proposons un tutoriel vidéo sur Bilibili. Ce guide pas à pas vous permettra de maîtriser rapidement la configuration « PPIO API + Cherry Studio ». Cliquez sur le lien ci-dessous pour accéder à la vidéo et démarrer une expérience de développement fluide →
【Source vidéo : sola】
Ce document a été traducido del chino por IA y aún no ha sido revisado.
ModelScope est une nouvelle génération de plateforme open source de Modèle en tant que Service (MaaS). Elle s'engage à fournir aux développeurs une solution de service de modèles flexible, facile à utiliser et à faible coût, rendant l'application des modèles plus simple !
Grâce à la capacité de service API-Inference, la plateforme standardise les modèles open source en interfaces API appelables. Les développeurs peuvent intégrer légèrement et rapidement les capacités des modèles dans diverses applications d'IA, supportant des scénarios innovants tels que l'appel d'outils et le prototypage.
✅ Quota gratuit : Offre 2000 appels API gratuits par jour ()
✅ Base de modèles riche : Couvre plus de 1000 modèles open source dans les domaines NLP, CV, audio, multimodal, etc.
✅ Prêt à l'emploi : Aucun déploiement nécessaire, appel rapide via API RESTful
Connexion à la plateforme
Visitez le → Cliquez sur Connexion en haut à droite → Choisissez le mode d'authentification
Créer un jeton d'accès
Accédez à
Cliquez sur Créer un jeton → Remplissez la description → Copiez le jeton généré (voir exemple ci-dessous)
🔑 Important : La fuite du jeton compromet la sécurité du compte !
Ouvrez Cherry Studio → Paramètres → Services de modèles → ModelScope
Collez le jeton copié dans le champ Clé API
Cliquez sur Enregistrer pour terminer l'autorisation
Trouver des modèles compatibles API
Visitez la
Filtres : Cochez API-Inference (ou identifiez l'icône API sur la carte du modèle)
La couverture des modèles par API-Inference est principalement déterminée par leur popularité dans la communauté (données de likes, téléchargements, etc.). Ainsi, la liste des modèles supportés évolue continuellement avec la sortie de nouvelles versions.
Obtenir l'ID du modèle
Accédez à la page de détails du modèle cible → Copiez le Model ID (format : damo/nlp_structbert_sentiment-classification_chinese-base)
Remplir dans Cherry Studio
Entrez l'ID dans le champ ID du modèle → Sélectionnez le type de tâche → Finalisez la configuration
🎫 Quota gratuit : 2000 appels API par jour par utilisateur (*sujet aux dernières règles officielles)
🔁 Réinitialisation du quota : Réinitialisation automatique quotidienne à 00:00 UTC+8, pas de cumul ou mise à niveau inter-jours
💡 Dépassement de quota :
Lorsque la limite quotidienne est atteinte, l'API retourne une erreur 429
Solutions : Basculer vers un compte secondaire / Utiliser une autre plateforme / Optimiser la fréquence d'appel
Connectez-vous à ModelScope → Cliquez sur Nom d'utilisateur en haut à droite → Statut d'utilisation de l'API
⚠️ Note : L'API d'inférence Inference offre 2000 appels gratuits par jour. Pour des besoins supplémentaires, envisagez d'utiliser des services cloud comme Alibaba Cloud Bailian.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
La chaîne d'appel (également appelée "trace") offre aux utilisateurs une capacité d'analyse des conversations, leur permettant d'observer les performances spécifiques des modèles, des bases de connaissances, du MCP, des recherches Internet et d'autres composants pendant le dialogue. Il s'agit d'un outil d'observabilité basé sur qui collecte, stocke et traite les données côté client pour une visualisation, fournissant une base d'évaluation quantitative pour localiser les problèmes et optimiser les performances.
Chaque conversation correspond à une donnée de trace. Une trace est composée de plusieurs spans, chaque span correspondant à une logique de traitement de programme dans Cherry Studio, comme l'appel d'une session de modèle, l'appel du MCP, l'appel d'une base de connaissances ou l'appel d'une recherche Internet. La trace est présentée sous forme d'arborescence où les spans sont les nœuds, affichant les principales données telles que le temps d'exécution et la consommation de tokens. Dans le détail d'un span, vous pouvez également consulter ses entrées et sorties spécifiques.
Par défaut, après l'installation de Cherry Studio, la fonction Trace est cachée. Vous devez l'activer dans "Paramètres" > "Paramètres généraux" > "Mode développeur", comme illustré ci-dessous :
Les conversations antérieures ne généreront pas d'enregistrements Trace. Les enregistrements ne sont créés qu'après de nouveaux échanges question-réponse. Les enregistrements générés sont stockés localement. Pour supprimer complètement les traces, vous pouvez utiliser "Paramètres" > "Paramètres des données" > "Répertoire de données" > "Effacer le cache", ou supprimer manuellement les fichiers dans ~/.cherrystudio/trace, comme montré ci-dessous :
Cliquez sur la chaîne d'appel dans la boîte de dialogue Cherry Studio pour afficher les données complètes de la chaîne. Que des modèles, des recherches Internet, des bases de connaissances ou du MCP soient appelés pendant la conversation, toutes les données d'appel de la chaîne complète sont visibles dans la fenêtre de la chaîne d'appel.
Pour consulter les détails d'un modèle dans la chaîne d'appel, cliquez sur le nœud d'appel du modèle afin d'afficher ses entrées et sorties spécifiques.
Pour consulter les détails d'une recherche Internet dans la chaîne d'appel, cliquez sur le nœud de recherche Internet afin d'afficher ses entrées et sorties spécifiques. Dans les détails, vous pouvez voir la requête envoyée et les résultats retournés.
Pour consulter les détails d'une base de connaissances dans la chaîne d'appel, cliquez sur le nœud de la base de connaissances afin d'afficher ses entrées et sorties spécifiques. Dans les détails, vous pouvez voir la requête envoyée et la réponse retournée.
Pour consulter les détails d'un appel MCP dans la chaîne d'appel, cliquez sur le nœud d'appel MCP afin d'afficher ses entrées et sorties spécifiques. Dans les détails, vous pouvez voir les paramètres d'entrée passés au tool du serveur MCP et la réponse du tool.
Cette fonctionnalité est actuellement fournie par l'équipe d'Alibaba Cloud. Si vous rencontrez des problèmes ou avez des suggestions, veuillez rejoindre le groupe DingTalk (ID de groupe : 21958624) pour discuter en profondeur avec les développeurs.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Contact : M. Wang 📮 : [email protected] 📱 : 18954281942 (numéro non destiné au service client)
Pour les questions d'utilisation, rejoignez notre groupe d'échange utilisateurs via le lien en bas de page d'accueil du site officiel, ou contactez-nous par email à [email protected]
Vous pouvez également soumettre des issues sur GitHub :
Pour un accompagnement personnalisé, rejoignez notre communauté "Knowledge Planet" (星球) :
Détails de la licence commerciale :
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Rejoignez le groupe Telegram pour obtenir de l'aide :
Signaler des problèmes sur GitHub :
Contacter les développeurs par email : [email protected]
Ce document a été traducido del chino por IA y aún no ha sido revisado.
360gpt-pro
8k
-
Non supporté
Dialogue
360AI_360gpt
Modèle phare de la série 360 Brain, optimisé pour tâches complexes multidisciplinaires.
gemini-2.0-pro-exp-02-05
2m
8k
Non supporté
Dialogue, Reconnaissance image
Google_gemini
Modèle expérimental Gemini 2.0 Pro publié en février 2024, supportant un contexte de 2M tokens.
qwen-vl-max-latest
32k
2k
Supporté
Dialogue, Reconnaissance image
千问_qwen
Version multilingue avancée pour tâches complexes nécessitant compréhension visuelle et textuelle.
glm-4v-flash
2k
1k
Non supporté
Dialogue, Reconnaissance image
智谱_glm
Modèle gratuit avec capacités avancées de compréhension d'images.
{% hint style="danger" %}
Attention : La génération d'images Gemini nécessite d'utiliser l'interface de conversation, car Gemini est un générateur d'images multimodal interactif qui ne prend pas non plus en charge le réglage des paramètres.
{% endhint %}Mode réflexion
Raisonnement complexe, problèmes mathématiques, planification
- Résoudre un problème de géométrie - Concevoir une architecture de projet
Mode non-réflexion
Questions-réponses rapides, traduction, résumé
- Vérifier la météo - Traduction chinois-anglais


pip install vllm # si vous utilisez pip
uv pip install vllm # si vous utilisez uvpython -m vllm.entrypoints.openai.api_server --model gpt2vllm --model gpt2 --served-model-name gpt2
































































数据设置→Obsidian配置
Ce document a été traducido del chino por IA y aún no ha sido revisado.
# Tutoriel de configuration d'Obsidian
Cherry Studio prend en charge l'intégration avec Obsidian pour exporter des conversations complètes ou des messages individuels vers une bibliothèque Obsidian.
{% hint style="warning" %}
Ce processus ne nécessite pas l'installation de plugiciels Obsidian supplémentaires. Cependant, puisque le principe d'importation de Cherry Studio vers Obsidian est similaire à Obsidian Web Clipper, il est recommandé de mettre à jour Obsidian vers la dernière version (la version actuelle d'Obsidian doit être supérieure à **1.7.2**). Ceci évite les [échecs d'importation lors de conversations trop longues](https://github.com/obsidianmd/obsidian-clipper/releases/tag/0.7.0).
{% endhint %}
## Tutoriel récent
{% hint style="info" %}
Comparée à l'ancienne version, la nouvelle fonction d'exportation vers Obsidian sélectionne automatiquement le chemin de la bibliothèque, sans nécessiter la saisie manuelle du nom de bibliothèque ou du dossier.
{% endhint %}
### Étape 1 : Configurer Cherry Studio
Ouvrez les _Paramètres_ de Cherry Studio → _Paramètres des données_ → Menu _Configuration d'Obsidian_. Les noms des bibliothèques Obsidian ouvertes localement apparaîtront dans la liste déroulante. Sélectionnez votre bibliothèque cible :
<figure><img src="../.gitbook/assets/image (142).png" alt=""><figcaption></figcaption></figure>
### Étape 2 : Exporter une conversation
#### Exporter une conversation complète
Retournez à l'interface de conversation de Cherry Studio, cliquez droit sur une conversation, sélectionnez _Exporter_, puis cliquez sur _Exporter vers Obsidian_ :
<figure><img src="../.gitbook/assets/image (143).png" alt=""><figcaption></figcaption></figure>
Une fenêtre s'affiche pour configurer les **Propriétés** de la note, l'**emplacement du dossier** dans Obsidian et le **mode de traitement** :
* **Bibliothèque** : Sélectionnez d'autres bibliothèques via le menu déroulant
* **Chemin** : Choisissez le dossier de destination via le menu déroulant
* Propriétés de la note Obsidian :
* Étiquettes (tags)
* Date de création (created)
* Source (source)
* **Modes de traitement** disponibles :
* **Nouveau (remplace si existant)** : Crée une nouvelle note dans le dossier spécifié, remplace les notes existantes homonymes
* **Préfixer** : Ajoute le contenu au début d'une note existante homonyme
* **Suffixer** : Ajoute le contenu à la fin d'une note existante homonyme
{% hint style="info" %}
Seul le premier mode inclut les propriétés. Les deux autres modes ne les conservent pas.
{% endhint %}
<figure><img src="../.gitbook/assets/image (144).png" alt=""><figcaption><p>Configurer les propriétés de la note</p></figcaption></figure>
<figure><img src="../.gitbook/assets/image (145).png" alt=""><figcaption><p>Sélectionner le chemin</p></figcaption></figure>
<figure><img src="../.gitbook/assets/image (146).png" alt=""><figcaption><p>Choisir le mode de traitement</p></figcaption></figure>
Après sélection, cliquez sur **Confirmer** pour exporter la conversation vers le dossier cible d'Obsidian.
#### Exporter un message individuel
Cliquez sur le _menu à trois barres_ sous un message → _Exporter_ → _Exporter vers Obsidian_ :
<figure><img src="../.gitbook/assets/image (147).png" alt=""><figcaption><p>Exporter un message individuel</p></figcaption></figure>
La même fenêtre de configuration que pour une conversation complète s'affiche. Suivez les [instructions ci-dessus](obsidian.md#dao-chu-wan-zheng-dui-hua) pour finaliser.
### Exportation réussie
🎉 Félicitations ! Vous avez terminé la configuration d'intégration Obsidian et mené à bien le processus d'exportation.
<figure><img src="../.gitbook/assets/image (140).png" alt=""><figcaption><p>Exportation vers Obsidian</p></figcaption></figure>
<figure><img src="../.gitbook/assets/image (139).png" alt=""><figcaption><p>Vérifier le résultat</p></figcaption></figure>
***
## Ancien tutoriel (pour Cherry Studio < v1.1.13)
### Étape 1 : Préparer Obsidian
Ouvrez une bibliothèque Obsidian et créez un `dossier` pour les conversations exportées (exemple : dossier Cherry Studio) :
<figure><img src="../.gitbook/assets/image (127).png" alt=""><figcaption></figcaption></figure>
Notez le nom de `bibliothèque` encadré en bas à gauche.
### Étape 2 : Configurer Cherry Studio
Dans _Paramètres_ → _Paramètres des données_ → _Configuration d'Obsidian_, saisissez le nom de `bibliothèque` et de `dossier` obtenus à l'[étape 1](obsidian.md#di-yi-bu) :
<figure><img src="../.gitbook/assets/image (129).png" alt=""><figcaption></figcaption></figure>
Le champ `Étiquettes globales` est optionnel pour définir les étiquettes des notes exportées.
### Étape 3 : Exporter une conversation
#### Conversation complète
Cliquez droit sur une conversation → _Exporter_ → _Exporter vers Obsidian_ :
<figure><img src="../.gitbook/assets/image (138).png" alt=""><figcaption><p>Exporter une conversation complète</p></figcaption></figure>
Configurer les **Propriétés** et le **mode de traitement** (identique à la version récente).
#### Message individuel
Cliquez sur le _menu à trois barres_ → _Exporter_ → _Exporter vers Obsidian_ :
<figure><img src="../.gitbook/assets/image (141).png" alt=""><figcaption><p>Exporter un message individuel</p></figcaption></figure>
### Exportation réussie
🎉 Félicitations ! Profitez de l'intégration Obsidian 🎉
<figure><img src="../.gitbook/assets/image (140).png" alt=""><figcaption><p>Exportation vers Obsidian</p></figcaption></figure>
<figure><img src="../.gitbook/assets/image (139).png" alt=""><figcaption><p>Vérifier le résultat</p></figcaption></figure>Ce document a été traducido del chino por IA y aún no ha sido revisado.
Cherry Studio est un projet gratuit et open source. À mesure que le projet se développe, la charge de travail de l'équipe augmente également. Afin de réduire les coûts de communication et de résoudre vos problèmes rapidement et efficacement, nous vous demandons de suivre les étapes et méthodes ci-dessous avant de poser des questions. Cela permettra à l'équipe de consacrer plus de temps à la maintenance et au développement du projet. Merci pour votre coopération !
La plupart des problèmes fondamentaux peuvent être résolus en consultant attentivement la documentation :
Pour les questions sur les fonctionnalités et l'utilisation du logiciel, consultez la documentation Fonctionnalités ;
Les questions fréquentes sont répertoriées dans la page Questions fréquentes - vérifiez d'abord s'il existe une solution ;
Des problèmes plus complexes peuvent être résolus directement via la recherche ou en posant des questions dans la barre de recherche ;
Lisez attentivement le contenu des encadrés d'information dans chaque document - cela vous évitera de nombreux problèmes ;
Consultez ou recherchez des problèmes et solutions similaires sur la page Issue de GitHub.
Pour les problèmes liés à l'utilisation des modèles mais non liés aux fonctionnalités du client (tels que les erreurs des modèles, des réponses inattendues, ou les paramètres), il est recommandé de :
Rechercher d'abord des solutions sur Internet,
Ou décrire le contenu de l'erreur et le problème à une IA pour trouver des solutions.
Si les deux premières étapes ne donnent pas de réponse ou ne résolvent pas votre problème :
Accédez à la chaîne officielle Telegram,
Ou (Rejoindre directement),
Et décrivez le problème en détail.
Pour les erreurs de modèle : Fournissez une capture d'écran complète et les informations d'erreur de la console. Les informations sensibles peuvent être masquées, mais le nom du modèle, les paramètres et le contenu de l'erreur doivent figurer dans la capture. Méthode pour consulter les erreurs de la console : Cliquez ici.
Pour les bugs logiciels : Fournissez une description précise de l'erreur et des étapes détaillées de pour faciliter le débogage. Si le problème est intermittent, décrivez le contexte, l'environnement et les paramètres de configuration. Mentionnez également les informations sur la plateforme (Windows, Mac ou Linux) et la version du logiciel.
Demande de documentation ou suggestions
Contactez la chaîne Telegram @Wangmouuu, QQ (1355873789) ou envoyez un e-mail à : [email protected].




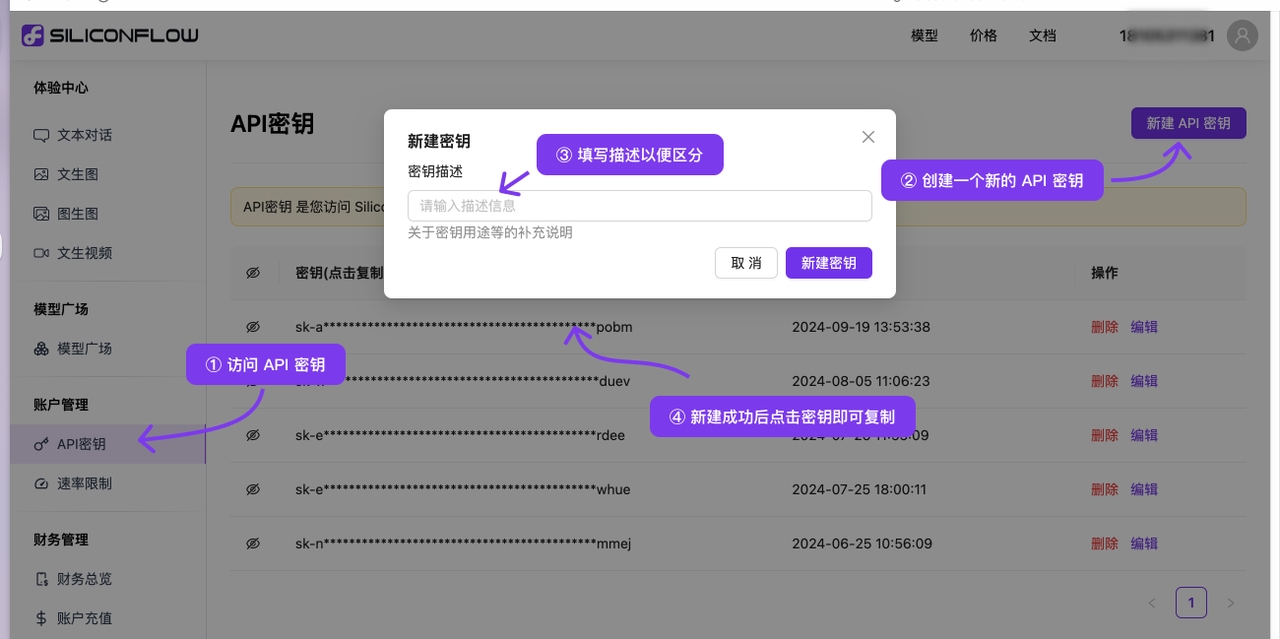
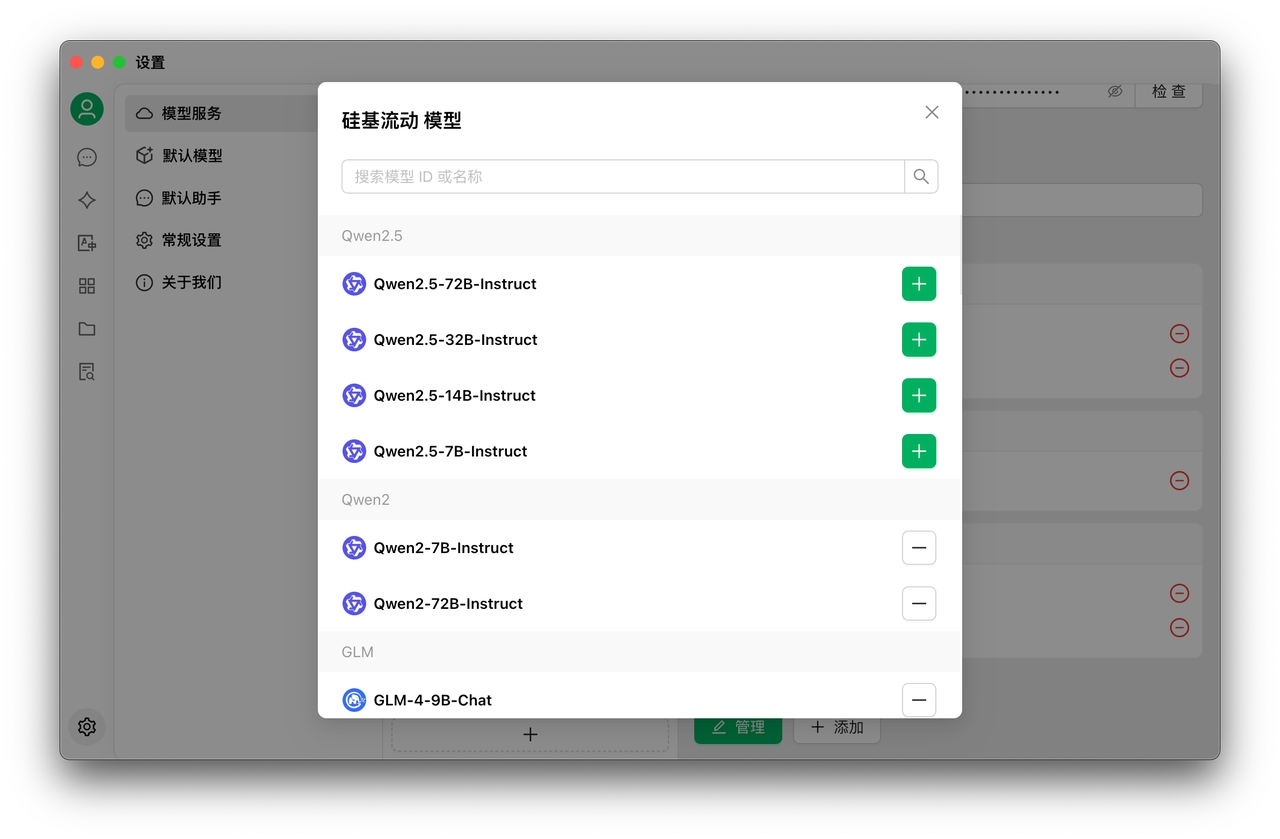
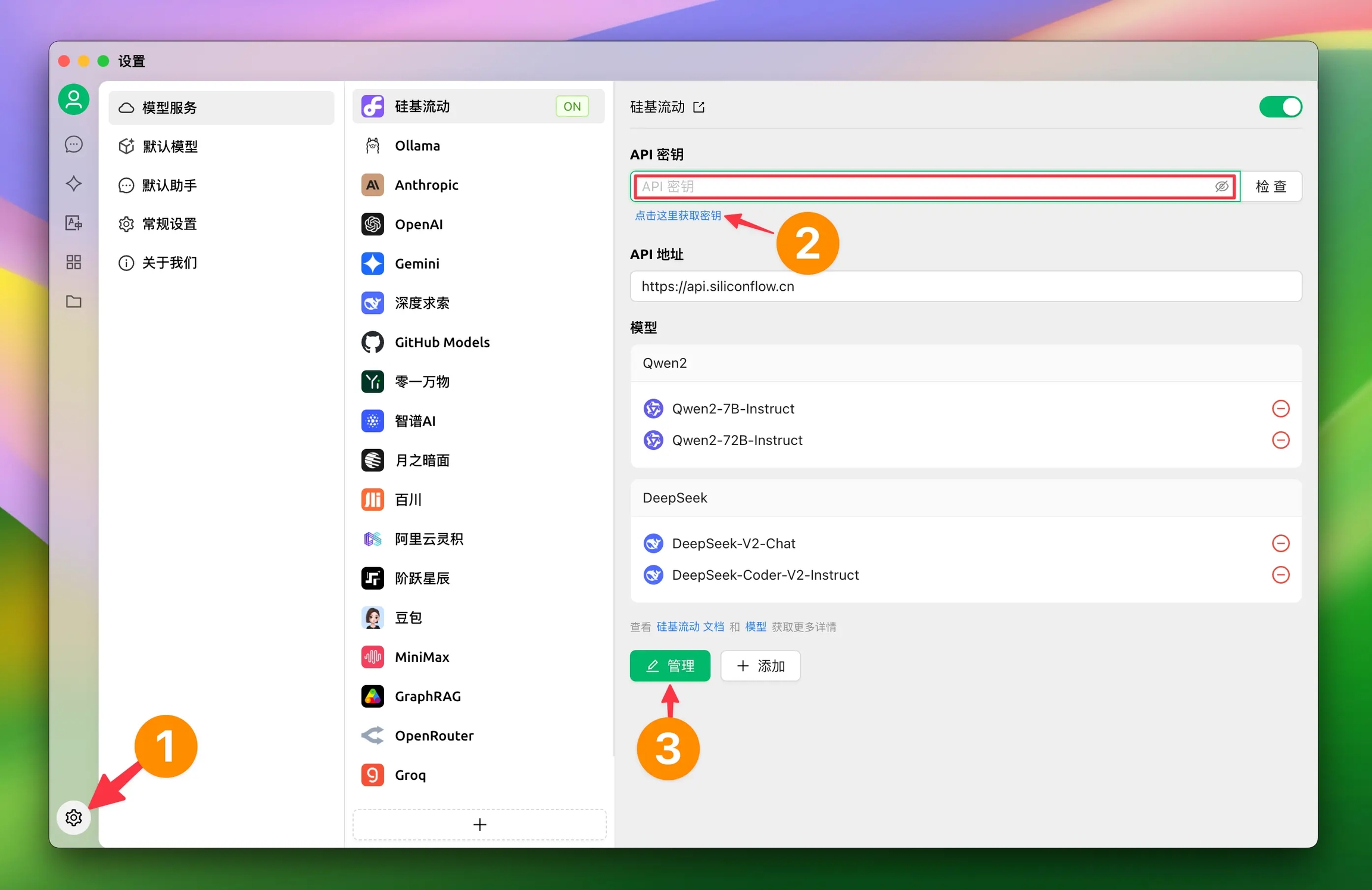

Ce document a été traducido del chino por IA y aún no ha sido revisado.
L'utilisation ou la distribution de toute partie ou élément des Matériaux Cherry Studio implique que vous avez pris connaissance et accepté le contenu du présent Accord, qui prend effet immédiatement.
Le présent Accord de Licence Cherry Studio (ci-après "l’Accord") désigne les termes et conditions régissant l'utilisation, la copie, la distribution et la modification des Matériaux.
"Nous" (ou "Notre") désigne Shanghai Qianhui Technology Co., Ltd.
"Vous" (ou "Votre") désigne toute personne physique ou entité légale exerçant les droits accordés par le présent Accord et/ou utilisant les Matériaux à quelque fin que ce soit et dans tout domaine d'utilisation.
"Tiers" désigne toute personne ou entité légale ne partageant aucun lien de contrôle avec Nous ou Vous.
"Cherry Studio" désigne le logiciel concerné, comprenant sans limitation [exemples : bibliothèques principales, éditeur, extensions, projets d'exemple], ainsi que le code source, la documentation, les exemples de code et tout autre élément distribué avec ce dernier. (Veuillez décrire précisément selon la composition réelle de Cherry Studio)
"Matériaux" désigne collectivement Cherry Studio et la documentation (et toute partie de ceux-ci), propriété exclusive de Shanghai Qianhui Technology Co., Ltd., fournis sous le présent Accord.
"Forme Source" désigne la forme privilégiée pour apporter des modifications, comprenant notamment le code source, les fichiers sources de documentation et les fichiers de configuration.
"Forme Objet" désigne toute forme résultant d'une transformation mécanique ou d'une traduction de la Forme Source, comprenant notamment le code objet compilé, la documentation générée et les formats convertis vers d'autres types de médias.
"Utilisation Commerciale" désigne toute fin présentant un avantage ou bénéfice commercial direct ou indirect, incluant notamment la vente, la licence, l'abonnement, la publicité, le marketing, la formation, les services de conseil, etc.
"Modification" désigne tout changement, adaptation, création dérivée ou développement secondaire apporté à la Forme Source des Matériaux, incluant notamment la modification du nom de l'application, du logo, du code, des fonctionnalités, de l'interface, etc.
Utilisation commerciale gratuite (Code non modifié uniquement) : Nous Vous accordons, sous réserve des termes et conditions du présent Accord, une licence non exclusive, mondiale, non cessible, exempte de redevances, pour utiliser, copier, distribuer les Matériaux non modifiés, y compris à des fins d'Utilisation Commerciale, conformément à Nos droits de propriété intellectuelle ou autres droits existants dans les Matériaux.
Licence commerciale (si nécessaire) : Sous réserve de remplir les conditions énoncées à l'article III "Licence Commerciale", Vous devez obtenir une licence commerciale écrite explicite de Notre part pour exercer les droits en vertu du présent Accord.
Vous devez Nous contacter et obtenir une licence commerciale écrite explicite avant de continuer à utiliser les Matériaux Cherry Studio dans les cas suivants :
Modifications et créations dérivées : Vous modifiez les Matériaux ou effectuez un développement dérivé basé sur ceux-ci (incluant notamment la modification du nom de l'application, du logo, du code, des fonctionnalités, de l'interface, etc.).
Services d'entreprise : Vous fournissez des services basés sur Cherry Studio au sein de Votre entreprise ou pour des clients entreprises, prenant en charge 10 utilisateurs cumulés ou plus.
Vente groupée avec matériel : Vous préinstallez ou intégrez Cherry Studio dans un équipement ou produit matériel pour une vente groupée.
Approvisionnement à grande échelle par des institutions publiques ou éducatives : Votre cas d'usage relève d'un projet d'approvisionnement à grande échelle par des institutions gouvernementales ou éducatives, notamment impliquant des exigences sensibles (sécurité, confidentialité des données).
Service cloud public : Vous proposez un service cloud public basé sur Cherry Studio.
Vous pouvez distribuer des copies des Matériaux non modifiés ou les fournir dans le cadre d'un produit ou service contenant des Matériaux non modifiés, sous Forme Source ou Forme Objet, à condition de :
Fournir une copie du présent Accord à tout autre destinataire des Matériaux ;
Conserver dans toutes les copies des Matériaux que Vous distribuez l'avis d'attribution suivant, placé dans un fichier "NOTICE" ou texte similaire distribué avec ces copies : `"Cherry Studio est licencié sous les termes du Cherry Studio LICENSE AGREEMENT, Copyright (c) 上海千彗科技有限公司. Tous droits réservés."`
Les Matériaux peuvent être soumis à des contrôles ou restrictions à l'exportation. Vous devez respecter les lois et règlements applicables lors de leur utilisation.
Si Vous utilisez les Matériaux ou leurs résultats pour créer, entraîner, affiner ou améliorer un logiciel ou modèle destiné à être distribué, Nous Vous encourageons à indiquer clairement "Built with Cherry Studio" ou "Powered by Cherry Studio" dans la documentation associée.
Nous conservons la propriété de tous les droits de propriété intellectuelle sur les Matériaux et les œuvres dérivées créées par ou pour Nous. Sous réserve du respect du présent Accord, la propriété des Modifications et œuvres dérivées créées par Vous sera définie dans la licence commerciale applicable. Sans licence commerciale, Vous ne détenez aucun droit de propriété sur Vos Modifications/œuvres dérivées ; celles-ci restent Notre propriété.
Aucune licence d'utilisation de Nos marques commerciales, marques déposées, marques de service ou noms de produits n'est accordée, sauf pour s'acquitter des obligations de notification ou pour une utilisation raisonnable et usuelle dans la description/redistribution des Matériaux.
Si Vous engagez une action en justice (y compris une demande reconventionnelle) contre Nous ou toute entité, alléguant que les Matériaux ou leurs résultats enfreignent Vos droits de propriété intellectuelle, toutes les licences accordées par le présent Accord prendront fin à la date d'introduction de la procédure.
Nous n'avons aucune obligation de support, de mise à jour, de formation ou de développement de nouvelles versions des Matériaux, ni d'accorder de licences connexes.
Les Matériaux sont fournis "TELS QUELS", sans garantie expresse ou implicite (y compris de qualité marchande, de non-contrefaçon ou d'adéquation à un usage particulier). Nous n'offrons aucune garantie concernant leur sécurité/stabilité.
En aucun cas Nous ne serons responsables envers Vous des dommages résultant de l'utilisation ou de l'impossibilité d'utiliser les Matériaux ou leurs résultats, notamment tout dommage direct, indirect, spécial ou consécutif.
Vous Nous défendrez, indemniserez et Nous tiendrez indemnes de toute réclamation faite par un Tiers liée à Votre utilisation ou distribution des Matériaux.
Le présent Accord prend effet lors de Votre acceptation ou accès aux Matériaux et reste valide jusqu'à résiliation selon ses termes.
Nous pouvons résilier l'Accord en cas de violation de Vos obligations. Après résiliation, Vous cesserez d'utiliser les Matériaux. Les articles VII, IX et "II. Accord du contributeur" (si applicable) survivront à la résiliation.
Le présent Accord et tout litige y afférent sont régis par le droit chinois.
Tout litige né du présent Accord relève de la compétence exclusive des tribunaux populaires de Shanghai.
PS D:\CherryStudio> dir
目录: D:\CherryStudio
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:05 user-data-dir
-a---- 2025/4/14 23:05 94987175 Cherry-Studio-1.2.4-x64-portable.exe
-a---- 2025/4/18 14:05 701 init_cherry_studio.bat@title Initialisation CherryStudio
@echo off
set current_path_dir=%~dp0
@echo Chemin actuel : %current_path_dir%
set user_data_dir=%current_path_dir%user-data-dir
@echo Chemin des données CherryStudio : %user_data_dir%
@echo Recherche de Cherry-Studio-*-portable.exe dans le chemin actuel
setlocal enabledelayedexpansion
for /f "delims=" %%F in ('dir /b /a-d "Cherry-Studio-*-portable*.exe" 2^>nul') do ( # Ce code s'adapte aux versions GitHub et officielles, modifiez si nécessaire
set "target_file=!cd!\%%F"
goto :break
)
:break
if defined target_file (
echo Fichier trouvé : %target_file%
) else (
echo Aucun fichier correspondant, arrêt du script
pause
exit
)
@echo Confirmez pour continuer
pause
@echo Lancement de CherryStudio
start %target_file% --user-data-dir="%user_data_dir%"
@echo Opération terminée
@echo on
exitPS D:\CherryStudio> dir .\user-data-dir\
目录: D:\CherryStudio\user-data-dir
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:29 blob_storage
d----- 2025/4/18 14:07 Cache
d----- 2025/4/18 14:07 Code Cache
d----- 2025/4/18 14:07 Data
d----- 2025/4/18 14:07 DawnGraphiteCache
d----- 2025/4/18 14:07 DawnWebGPUCache
d----- 2025/4/18 14:07 Dictionaries
d----- 2025/4/18 14:07 GPUCache
d----- 2025/4/18 14:07 IndexedDB
d----- 2025/4/18 14:07 Local Storage
d----- 2025/4/18 14:07 logs
d----- 2025/4/18 14:30 Network
d----- 2025/4/18 14:07 Partitions
d----- 2025/4/18 14:29 Session Storage
d----- 2025/4/18 14:07 Shared Dictionary
d----- 2025/4/18 14:07 WebStorage
-a---- 2025/4/18 14:07 36 .updaterId
-a---- 2025/4/18 14:29 20 config.json
-a---- 2025/4/18 14:07 434 Local State
-a---- 2025/4/18 14:29 57 Preferences
-a---- 2025/4/18 14:09 4096 SharedStorage
-a---- 2025/4/18 14:30 140 window-state.json:root {
--color-background: #1a462788;
--color-background-soft: #1a4627aa;
--color-background-mute: #1a462766;
--navbar-background: #1a4627;
--chat-background: #1a4627;
--chat-background-user: #28b561;
--chat-background-assistant: #1a462722;
}
#content-container {
background-color: #2e5d3a !important;
}:root {
font-family: "汉仪唐美人" !important; /* police de caractères */
}
/* Couleur du texte en mode réflexion approfondie */
.ant-collapse-content-box .markdown {
color: red;
}
/* Variables de thème */
:root {
--color-black-soft: #2a2b2a; /* couleur de fond sombre */
--color-white-soft: #f8f7f2; /* couleur de fond claire */
}
/* Thème sombre */
body[theme-mode="dark"] {
/* Couleurs */
--color-background: #2b2b2b; /* couleur de fond sombre */
--color-background-soft: #303030; /* couleur de fond claire */
--color-background-mute: #282c34; /* couleur de fond neutre */
--navbar-background: var(-–color-black-soft); /* couleur de fond de la barre de navigation */
--chat-background: var(–-color-black-soft); /* couleur de fond du chat */
--chat-background-user: #323332; /* couleur de fond des messages utilisateur */
--chat-background-assistant: #2d2e2d; /* couleur de fond des messages de l'assistant */
}
/* Styles spécifiques au thème sombre */
body[theme-mode="dark"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* couleur de fond du conteneur */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* couleur de fond des messages */
}
.inputbar-container {
background-color: #3d3d3a; /* couleur de fond de la zone de saisie */
border: 1px solid #5e5d5940; /* couleur de bordure de la zone de saisie */
border-radius: 8px; /* rayon de bordure de la zone de saisie */
}
/* Styles de code */
code {
background-color: #e5e5e20d; /* couleur de fond du code */
color: #ea928a; /* couleur du texte du code */
}
pre code {
color: #abb2bf; /* couleur du texte du code préformaté */
}
}
/* Thème clair */
body[theme-mode="light"] {
/* Couleurs */
--color-white: #ffffff; /* blanc */
--color-background: #ebe8e2; /* couleur de fond claire */
--color-background-soft: #cbc7be; /* couleur de fond claire */
--color-background-mute: #e4e1d7; /* couleur de fond neutre */
--navbar-background: var(-–color-white-soft); /* couleur de fond de la barre de navigation */
--chat-background: var(-–color-white-soft); /* couleur de fond du chat */
--chat-background-user: #f8f7f2; /* couleur de fond des messages utilisateur */
--chat-background-assistant: #f6f4ec; /* couleur de fond des messages de l'assistant */
}
/* Styles spécifiques au thème clair */
body[theme-mode="light"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* couleur de fond du conteneur */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* couleur de fond des messages */
}
.inputbar-container {
background-color: #ffffff; /* couleur de fond de la zone de saisie */
border: 1px solid #87867f40; /* couleur de bordure de la zone de saisie */
border-radius: 8px; /* rayon de bordure de la zone de saisie (ajustez à votre convenance) */
}
/* Styles de code */
code {
background-color: #3d39290d; /* couleur de fond du code */
color: #7c1b13; /* couleur du texte du code */
}
pre code {
color: #000000; /* couleur du texte du code préformaté */
}
}Tools
Ce document a été traducido del chino por IA y aún no ha sido revisado.
La version Cherry Studio v1.5.7 introduit une fonctionnalité puissante et simple d'utilisation : Code Agent, permettant de démarrer et gérer directement divers agents de programmation IA. Ce tutoriel vous guidera à travers le processus complet de configuration et de démarrage.
Assurez-vous d'abord que votre Cherry Studio est mis à jour vers la version v1.5.7 ou supérieure. Vous pouvez télécharger la dernière version sur GitHub Releases ou le site officiel.
Pour faciliter l'utilisation des onglets supérieurs, nous recommandons de positionner la barre de navigation en haut.
Chemin d'accès : Paramètres -> Paramètres d'affichage -> Configuration de la barre de navigation
Définissez l'option "Position de la barre de navigation" sur Haut.
Cliquez sur l'icône "+" en haut de l'interface pour créer un nouvel onglet vierge.
Dans le nouvel onglet, cliquez sur l'icône Code (ou </>) pour accéder à l'interface de configuration de Code Agent.
Choisissez un outil Code Agent selon vos besoins et votre clé API disponible. Actuellement pris en charge :
Claude Code
Gemini CLI
Qwen Code
OpenAI Codex
Dans la liste déroulante des modèles, choisissez un modèle compatible avec l'outil CLI sélectionné. (Consultez les "Remarques importantes" ci-dessous pour la compatibilité détaillée)
Cliquez sur "Sélectionner un répertoire" pour définir un espace de travail pour l'Agent. Celui-ci aura accès à tous les fichiers et sous-répertoires pour comprendre le contexte du projet.
Configuration automatique : Vos choix aux étapes 6 (modèle) et 7 (répertoire) génèrent automatiquement les variables correspondantes.
Ajout personnalisé : Ajoutez des variables spécifiques si nécessaire (ex: PROXY_URL).
Exécutables intégrés : Cherry Studio inclut tous les exécutables Code Agent, utilisables hors connexion.
Mise à jour automatique : Cochez Vérifier les mises à jour et installer la dernière version pour maintenir l'Agent à jour.
Après configuration, cliquez sur Démarrer. Cherry Studio ouvrira le Terminal système avec les variables chargées, exécutant le Code Agent sélectionné. Interagissez avec l'Agent IA dans la fenêtre de terminal.
Compatibilité des modèles :
Claude Code : Requiert des modèles supportant le format API Anthropic :
Modèles Claude
DeepSeek V3.1 (plateforme officielle)
Kimi K2 (plateforme officielle)
GLM 4.5 de Zhipu (plateforme officielle)
Attention : Les fournisseurs tiers (One API, New API...) utilisent souvent le format OpenAI pour DeepSeek/Kimi/GLM, incompatible avec Claude Code.
Gemini CLI : Requiert les modèles Gemini de Google.
Qwen Code : Supporte le format OpenAI Chat Completions. Recommandé : Qwen3 Coder.
OpenAI Codex : Supporte les modèles GPT (ex: gpt-4o, gpt-5).
Conflits de dépendances :
Cherry Studio intègre un environnement Node.js isolé pour éviter les conflits.
En cas d'erreurs, désinstallez les dépendances globales (Node.js, outils système).
Consommation de tokens API :
Les Code Agents consomment énormément de tokens. Les tâches complexes génèrent de nombreuses requêtes.
Surveillez votre quota API et budget pour éviter les dépassements.
Ce tutoriel vous aidera à maîtriser rapidement les puissantes fonctionnalités Code Agent de Cherry Studio !










Ce document a été traducido del chino por IA y aún no ha sido revisado.
Les tokens sont l'unité fondamentale de traitement du texte par les modèles d'IA, on peut les comprendre comme les plus petites unités de "pensée" du modèle. Ils ne correspondent pas exactement aux caractères ou mots tels que nous les concevons, mais représentent plutôt une méthode particulière de segmentation du texte spécifique au modèle.
1. Segmentation du chinois
Un caractère chinois est généralement encodé en 1-2 tokens
Par exemple : "你好" ≈ 2-4 tokens
2. Segmentation de l'anglais
Les mots courants représentent généralement 1 token
Les mots longs ou peu courants sont décomposés en plusieurs tokens
Par exemple :
"hello" = 1 token
"indescribable" = 4 tokens
3. Caractères spéciaux
Les espaces, signes de ponctuation occupent également des tokens
Un saut de ligne représente généralement 1 token
Le Tokenizer (outil de segmentation) est l'outil qui permet aux modèles d'IA de convertir du texte en tokens. Il détermine comment découper le texte d'entrée en unités minimales compréhensibles par le modèle.
1. Données d'entraînement différentes
Corpus différents entraînant des optimisations distinctes
Prise en charge variable des langues multiples
Optimisations spécifiques à certains domaines (médical, juridique, etc.)
2. Algorithmes de segmentation différents
BPE (Byte Pair Encoding) - Série GPT d'OpenAI
WordPiece - Google BERT
SentencePiece - Adapté aux scénarios multilingues
3. Objectifs d'optimisation différents
Certains privilégient la compression
D'autres la préservation sémantique
D'autres encore la vitesse de traitement
Un même texte peut produire différents nombres de tokens selon les modèles :
Entrée : "Hello, world!"
GPT-3 : 4 tokens
BERT : 3 tokens
Claude : 3 tokensConcept de base : Un modèle d'embedding est une technique convertissant des données discrètes dimensionnelles élevées (texte, images...) en vecteurs continus de basse dimension. Cette conversion permet aux machines de mieux comprendre et traiter des données complexes. Imaginez transformer un puzzle complexe en un simple point de coordonnées qui conserve les caractéristiques clés du puzzle. Dans l'écosystème des grands modèles, il agit comme un "traducteur", transformant des informations humainement compréhensibles en formes numériques calculables par l'IA.
Mode de fonctionnement : En traitement du langage naturel, le modèle d'embedding projette les mots dans un espace vectoriel où les termes sémantiquement proches se regroupent naturellement. Par exemple :
Les vecteurs de "roi" et "reine" seront proches
Les termes comme "chat" et "chien" formeront un autre groupe
Des mots sans lien sémantique comme "voiture" et "pain" seront éloignés
Principaux scénarios d'application :
Analyse de texte : classification documentaire, analyse des sentiments
Systèmes de recommandation : suggestions de contenu personnalisées
Traitement d'images : recherche d'images similaires
Moteurs de recherche : optimisation de la recherche sémantique
Avantages clés :
Réduction dimensionnelle : simplification des données complexes
Cohérence sémantique : préservation des informations sémantiques essentielles
Efficacité computationnelle : accélération significative de l'entraînement et de l'inférence
Valeur technique : Les modèles d'embedding sont des composants fondamentaux des systèmes d'IA modernes. Ils fournissent des représentations de données de haute qualité pour les tâches d'apprentissage automatique, constituant une technologie clé dans le développement du traitement du langage naturel et de la vision par ordinateur.
Flux de travail de base :
Phase de prétraitement de la base de connaissances
Segmentation des documents en chunks (blocs de texte) appropriés
Conversion de chaque chunk en vecteur via le modèle d'embedding
Stockage des vecteurs et du texte original dans une base de données vectorielle
Phase de traitement des requêtes
Conversion de la question utilisateur en vecteur
Recherche de contenu similaire dans la base vectorielle
Fourniture des résultats pertinents comme contexte au LLM
MCP est un protocole open source visant à fournir des informations contextuelles aux grands modèles de langage (LLM) de manière standardisée.
Analogie : Imaginez MCP comme une "clé USB" pour l'IA. De même qu'une clé USB stocke divers fichiers accessibles sur ordinateur, le serveur MCP peut "brancher" différents "plugins" contextuels. Les LLM peuvent ainsi accéder à ces composants selon leurs besoins, enrichissant leurs capacités par un contexte élargi.
Comparaison avec les outils fonctionnels : Les outils fonctionnels traditionnels étendent les capacités des LLM, mais MCP propose une abstraction de niveau supérieur. Alors que les outils fonctionnels sont spécifiques à certaines tâches, MCP offre un mécanisme contextuel modulaire et universel.
Standardisation : Interface et format de données unifiés pour une collaboration transparente
Modularité : Décomposition de l'information contextuelle en modules indépendants (plugins)
Flexibilité : Sélection dynamique des plugins contextuels par les LLM
Évolutivité : Architecture ouverte à de nouveaux types de plugins contextuels
Ce document a été traducido del chino por IA y aún no ha sido revisado.
4xx (codes d'état d'erreur client) : Généralement des erreurs de syntaxe de requête, d'échec d'authentification ou d'autorisation empêchant l'exécution de la demande.
5xx (codes d'état d'erreur serveur) : Généralement des erreurs côté serveur, comme un serveur en panne ou un dépassement du délai de traitement.
400
Format du corps de la requête incorrect, etc.
Consultez le contenu d'erreur renvoyé ou pour l'erreur et agissez selon les instructions.
401
Échec d'authentification : modèle non pris en charge ou compte suspendu
Vérifier l'état du compte auprès du fournisseur
403
Autorisation refusée pour l'opération demandée
Suivre les instructions dans l'erreur ou consulter les erreurs dans la
404
Ressource introuvable
Vérifier le chemin de la requête
422
Format de requête correct mais erreur sémantique
Erreur interprétable par le serveur mais non traitable (ex : valeur nulle, type incorrect comme un nombre au lieu d'une chaîne).
429
Limite de débit de requêtes atteinte
Réessayer après une durée de refroidissement
500
Erreur interne du serveur
Contacter le fournisseur si persistant
501
Fonction non implémentée par le serveur
502
Réponse invalide d'un serveur proxy ou passerelle
503
Serveur temporairement surchargé (retry après délai dans l'en-tête Retry-After)
504
Serveur proxy/passerelle n'a pas reçu la réponse du serveur distant à temps
Appuyer sur Ctrl + Shift + I (Mac: Command + Option + I) devant la fenêtre client de Cherry Studio
Dans la console, cliquer sur Network → Sélectionner le dernier élément marqué d'un × rouge : completions (erreurs de dialogue/traduction) ou generations (erreurs de génération d'images) → Cliquer sur Response pour voir le contenu complet (zone ④).
Si vous ne trouvez pas la cause de l'erreur, partagez une capture de cet écran dans le groupe officiel.
Cette méthode fonctionne pour les dialogues, tests de modèles, ajout de bases de connaissances, générations d'images, etc. Ouvrir toujours la console avant l'opération.
Si la formule s'affiche en code source, vérifier les délimiteurs :
Utilisation des délimiteurs
Formule en ligne
Utiliser
$formule$ou
\(formule\)Bloc de formule
Utiliser
$$formule$$ou
\[formule\]Exemple :
$$\sum_{i=1}^n x_i$$
Si le rendu est incorrect (souvent avec des caractères chinois), basculer le moteur de formules vers KateX.
Modèle indisponible
Vérifier si le modèle est pris en charge par le fournisseur et si son statut est normal.
Utilisation d'un modèle non adapté à l'embedding
Vérifier d'abord si le modèle supporte la reconnaissance d'images. Dans Cherry Studio, les modèles compatibles sont indiqués par une icône d'œil 👁️ après leur nom.
Les modèles compatibles permettent le téléchargement d'images. Si la fonctionnalité n'est pas activée, accéder aux paramètres du modèle chez le fournisseur et cocher l'option "image".
Consulter les informations détaillées du modèle chez le fournisseur. Les modèles non visuels n'utiliseront pas cette fonction même si activée.


Ce document a été traducido del chino por IA y aún no ha sido revisado.
Ce document a été traducido del chino por IA y aún no ha sido revisado.
Ce classement est généré automatiquement à partir des données de Chatbot Arena (lmarena.ai).
Date de mise à jour des données : 2025-09-11 11:40:35 UTC / 2025-09-11 19:40:35 CST (Heure de Pékin)
Rang (UB) : Classement calculé à partir du modèle Bradley-Terry. Ce rang reflète la performance globale du modèle dans l'arène et fournit une estimation de la borne supérieure de son score Elo, aidant à comprendre sa compétitivité potentielle.
Rang (StyleCtrl) : Classement après contrôle du style conversationnel. Ce rang vise à réduire les biais de préférence liés au style des réponses (par exemple verbose ou concis), évaluant plus purement les capacités fondamentales du modèle.
Modèle : Nom du grand modèle de langage (LLM). Cette colonne intègre des liens vers les modèles ; cliquez pour accéder au détail.
Score : Score Elo obtenu par le modèle via les votes des utilisateurs dans l'arène. Le score Elo est un système de classement relatif : plus le score est élevé, meilleure est la performance du modèle. Ce score est dynamique et reflète la position concurrentielle actuelle du modèle.
Intervalle de confiance : Intervalle de confiance à 95% du score Elo (par exemple : +6/-6). Plus cet intervalle est petit, plus le score est stable et fiable ; inversement, un intervalle large peut indiquer des données insuffisantes ou une performance variable. Il fournit une évaluation quantitative de la précision du score.
Votes : Nombre total de votes reçus par le modèle dans l'arène. Plus le nombre de votes est élevé, plus la fiabilité statistique du score est généralement importante.
Fournisseur : Organisation ou entreprise fournissant le modèle.
Licence : Type de licence du modèle (ex : propriétaire, Apache 2.0, MIT, etc.).
Date de fin de connaissance : Date limite des données d'entraînement. Aucune donnée signifie que l'information n'est pas fournie ou inconnue.
Les données de ce classement sont générées automatiquement par le projet , qui collecte et traite les données de . Ce classement est mis à jour quotidiennement par GitHub Actions.
Ce rapport est fourni à titre informatif uniquement. Les données du classement sont dynamiques et basées sur les votes de préférence des utilisateurs de Chatbot Arena pendant une période spécifique. L'exhaustivité et l'exactitude des données dépendent de la source amont et des mises à jour du projet fboulnois/llm-leaderboard-csv. Différents modèles peuvent utiliser différentes licences ; veuillez vous référer aux instructions officielles des fournisseurs de modèles avant toute utilisation.
Doubao-embedding
4095
Doubao-embedding-vision
8191
Doubao-embedding-large
4095
text-embedding-v3
8192
text-embedding-v2
2048
text-embedding-v1
2048
text-embedding-async-v2
2048
text-embedding-async-v1
2048
text-embedding-3-small
8191
text-embedding-3-large
8191
text-embedding-ada-002
8191
Embedding-V1
384
tao-8k
8192
embedding-2
1024
embedding-3
2048
hunyuan-embedding
1024
Baichuan-Text-Embedding
512
M2-BERT-80M-2K-Retrieval
2048
M2-BERT-80M-8K-Retrieval
8192
M2-BERT-80M-32K-Retrieval
32768
UAE-Large-v1
512
BGE-Large-EN-v1.5
512
BGE-Base-EN-v1.5
512
jina-embedding-b-en-v1
512
jina-embeddings-v2-base-en
8191
jina-embeddings-v2-base-zh
8191
jina-embeddings-v2-base-de
8191
jina-embeddings-v2-base-code
8191
jina-embeddings-v2-base-es
8191
jina-colbert-v1-en
8191
jina-reranker-v1-base-en
8191
jina-reranker-v1-turbo-en
8191
jina-reranker-v1-tiny-en
8191
jina-clip-v1
8191
jina-reranker-v2-base-multilingual
8191
reader-lm-1.5b
256000
reader-lm-0.5b
256000
jina-colbert-v2
8191
jina-embeddings-v3
8191
BAAI/bge-m3
8191
netease-youdao/bce-embedding-base_v1
512
BAAI/bge-large-zh-v1.5
512
BAAI/bge-large-en-v1.5
512
Pro/BAAI/bge-m3
8191
text-embedding-004
2048
nomic-embed-text-v1
8192
nomic-embed-text-v1.5
8192
gte-multilingual-base
8192
embedding-query
4000
embedding-passage
4000
embed-english-v3.0
512
embed-english-light-v3.0
512
embed-multilingual-v3.0
512
embed-multilingual-light-v3.0
512
embed-english-v2.0
512
embed-english-light-v2.0
512
embed-multilingual-v2.0
256
1
1
1470
+5/-5
26,019
Propriétaire
nan
2
2
1446
+6/-6
13,715
Propriétaire
nan
3
2
1434
+9/-9
4,112
Z.ai
MIT
nan
4
2
1434
+6/-6
13,058
xAI
Propriétaire
nan
...
...
...
...
...
...
...
...
...
266
264
840
+16/-16
2,446
Meta
Non commercial
2023/2











Ce document a été traducido del chino por IA y aún no ha sido revisado.
CherryStudio prend en charge les recherches sur le web via SearXNG, un projet open source pouvant être déployé localement ou sur un serveur. Son mode de configuration diffère légèrement des autres solutions nécessitant des fournisseurs d'API.
Lien du projet SearXNG : SearXNG
Open source et gratuit, sans API nécessaire
Respect élevé de la vie privée
Hautement personnalisable
Comme SearXNG ne nécessite pas de configuration environnementale complexe, vous pouvez le déployer simplement en fournissant un port libre sans utiliser docker compose. La méthode la plus rapide consiste à utiliser Docker pour extraire directement l'image et la déployer.
1. Télécharger et configurer Docker
Après l'installation, choisissez un chemin de stockage pour l'image :
2. Rechercher et extraire l'image SearXNG
Entrez searxng dans la barre de recherche :
Extraire l'image :
3. Exécuter l'image
Après l'extraction réussie, accédez à la page Images :
Sélectionnez l'image extraite et cliquez sur Exécuter :
Ouvrez les paramètres pour configurer :
Exemple avec le port 8085 :
Après le succès de l'exécution, cliquez sur le lien pour ouvrir l'interface frontale de SearXNG :
Cette page indique que le déploiement a réussi :
Comme l'installation de Docker sous Windows peut être complexe, les utilisateurs peuvent déployer SearXNG sur un serveur et le partager avec d'autres. Malheureusement, SearXNG ne prend pas encore en charge l'authentification nativement, permettant ainsi à d'autres personnes de scanner et d'utiliser abusivement votre instance déployée.
Cherry Studio prend désormais en charge la configuration de l'authentification HTTP de base (RFC7617). Si vous exposez votre SearXNG déployé sur Internet, il est impératif de configurer cette authentification via un logiciel de proxy inverse comme Nginx. Voici un bref tutoriel qui nécessite des connaissances de base en administration Linux.
De manière similaire, utilisez Docker pour le déploiement. Supposons que vous ayez déjà installé Docker CE sur le serveur selon le tutoriel officiel. Voici des commandes complètes pour une installation neuve sous Debian :
sudo apt update
sudo apt install git -y
# Extraire le dépôt officiel
cd /opt
git clone https://github.com/searxng/searxng-docker.git
cd /opt/searxng-docker
# Si la bande passante de votre serveur est limitée, définissez sur false
export IMAGE_PROXY=true
# Modifier le fichier de configuration
cat <<EOF > /opt/searxng-docker/searxng/settings.yml
# voir https://docs.searxng.org/admin/settings/settings.html#settings-use-default-settings
use_default_settings: true
server:
# base_url est défini dans la variable d'environnement SEARXNG_BASE_URL, voir .env et docker-compose.yml
secret_key: $(openssl rand -hex 32)
limiter: false # peut être désactivé pour une instance privée
image_proxy: $IMAGE_PROXY
ui:
static_use_hash: true
redis:
url: redis://redis:6379/0
search:
formats:
- html
- json
EOFSi vous devez modifier le port d'écoute local ou réutiliser un Nginx existant, éditez le fichier docker-compose.yaml comme suit :
version: "3.7"
services:
# Si Caddy n'est pas nécessaire et que vous réutilisez un Nginx local existant, supprimez cette section.
caddy:
container_name: caddy
image: docker.io/library/caddy:2-alpine
network_mode: host
restart: unless-stopped
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile:ro
- caddy-data:/data:rw
- caddy-config:/config:rw
environment:
- SEARXNG_HOSTNAME=${SEARXNG_HOSTNAME:-http://localhost}
- SEARXNG_TLS=${LETSENCRYPT_EMAIL:-internal}
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
# Si Caddy n'est pas nécessaire et que vous réutilisez un Nginx local existant, supprimez cette section.
redis:
container_name: redis
image: docker.io/valkey/valkey:8-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: unless-stopped
networks:
- searxng
volumes:
- valkey-data2:/data
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
searxng:
container_name: searxng
image: docker.io/searxng/searxng:latest
restart: unless-stopped
networks:
- searxng
# Par défaut mappé sur le port 8080 de l'hôte, si vous voulez écouter sur 8000, remplacez par "127.0.0.1:8000:8080"
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
- UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4}
- UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4}
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
searxng:
volumes:
# Si Caddy n'est pas nécessaire et que vous réutilisez un Nginx local existant, supprimez cette section
caddy-data:
caddy-config:
# Si Caddy n'est pas nécessaire et que vous réutilisez un Nginx local existant, supprimez cette section
valkey-data2:Exécutez docker compose up -d pour démarrer. Visualisez les journaux avec docker compose logs -f searxng.
Si vous utilisez des panneaux de serveur comme Baota ou 1Panel, consultez leur documentation pour ajouter un site et configurer le proxy inverse Nginx. Modifiez ensuite le fichier de configuration Nginx comme dans l'exemple ci-dessous :
server
{
listen 443 ssl;
# Votre nom d'hôte
server_name search.example.com;
# index index.html;
# root /data/www/default;
# Si SSL est configuré, ajoutez ces deux lignes
ssl_certificate /path/to/your/cert/fullchain.pem;
ssl_certificate_key /path/to/your/cert/privkey.pem;
# HSTS
# add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload";
# Configuration proxy inverse standard
location / {
# Ajoutez ces deux lignes dans le bloc location, conservez le reste
auth_basic "Veuillez saisir votre nom d'utilisateur et mot de passe";
auth_basic_user_file /etc/nginx/conf.d/search.htpasswd;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_protocol_addr;
proxy_pass http://127.0.0.1:8000;
client_max_body_size 0;
}
# access_log ...;
# error_log ...;
}Supposons que le fichier de configuration Nginx soit dans /etc/nginx/conf.d, placez-y également le fichier de mots de passe.
Exécutez la commande (remplacez example_name et example_password par vos identifiants) :
echo "example_name:$(openssl passwd -5 'example_password')" > /etc/nginx/conf.d/search.htpasswdRedémarrez Nginx (ou rechargez la configuration).
Ouvrez ensuite la page web. Vous devriez être invité à saisir vos identifiants. Entrez ceux définis précédemment pour vérifier la configuration.
Une fois SearXNG déployé localement ou sur serveur, procédez à la configuration dans CherryStudio.
Accédez à la page des paramètres de recherche web et sélectionnez Searxng :
La validation échoue si vous entrez directement l'URL du déploiement local :
Cela est dû au format JSON non activé par défaut. Modifiez le fichier de configuration.
Revenez à Docker, dans l'onglet Fichiers, trouvez le dossier avec les étiquettes :
Déroulez et trouvez un autre dossier étiqueté :
Localisez le fichier de configuration settings.yml :
Ouvrez l'éditeur de fichiers :
À la ligne 78, seul le format html est présent :
Ajoutez le format json, enregistrez et réexécutez l'image :
Revenez dans Cherry Studio pour valider :
L'adresse peut être locale : http://localhost:port Ou l'adresse Docker : http://host.docker.internal:port
Pour les déploiements serveur avec proxy inverse et format json activé, la validation retournera l'erreur 401 si l'authentification HTTP est configurée :
Configurez l'authentification HTTP de base dans le client avec vos identifiants :
La validation devrait alors réussir.
SearXNG possède désormais une capacité de recherche par défaut. Pour personnaliser les moteurs de recherche, configurez manuellement.
Notez que ces préférences n'affectent pas la configuration appelée par le grand modèle :
Pour configurer les moteurs utilisés par le grand modèle, modifiez le fichier de configuration :
Référence de configuration linguistique :
Si le contenu est trop long, copiez-le dans un IDE local, modifiez-le et collez-le dans le fichier de configuration.
Ajoutez json aux formats de retour dans le fichier de configuration :
Cherry Studio sélectionne par défaut les moteurs avec des catégories web et general. Google étant souvent inaccessible en Chine, forcez l'utilisation de Baidu :
use_default_settings:
engines:
keep_only:
- baidu
engines:
- name: baidu
engine: baidu
categories:
- web
- general
disabled: falseDésactivez le limiteur de SearXNG dans les paramètres :