Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
This document was translated from Chinese by AI and has not yet been reviewed.
The Agents page is an assistant marketplace where you can select or search for desired model presets. Click on a card to add the assistant to your conversation page's assistant list.
You can also edit and create your own assistants on this page.
Click My, then Create Agent to start building your own assistant.
This document was translated from Chinese by AI and has not yet been reviewed.
For knowledge base usage, please refer to the Knowledge Base Tutorial in the advanced tutorials.
This document was translated from Chinese by AI and has not yet been reviewed.
When the assistant does not have a default assistant model configured, the model selected by default for new conversations is the one set here. The model used for prompt optimization and word-selection assistant is also configured in this section.
After each conversation, a model is called to generate a topic name for the dialog. The model set here is the one used for naming.
The translation feature in input boxes for conversations, painting, etc., and the translation model in the translation interface all use the model set here.
The model used for the quick assistant feature. For details, see Quick Assistant.
This document was translated from Chinese by AI and has not yet been reviewed.
Key translation notes:
Preserved all Markdown formatting (headings, checkboxes)
Technical terms remain unchanged: "JavaScript", "SSO", "iOS", "Android"
Action descriptions standardized: "Quick Pop-up" for 快捷弹窗, "multi-model" for 多模型
Functional translations: "划词翻译" → "text selection translation"
Feature localization: "AI 通话" → "AI calls"
Maintained present tense for consistency
Preserved special characters and list formatting
Translated bracket content while keeping technical references (JavaScript)
Proper noun capitalization: "AI Notes"
This document was translated from Chinese by AI and has not yet been reviewed.
This document was translated from Chinese by AI and has not yet been reviewed.
Welcome to Cherry Studio (hereinafter referred to as "this software" or "we"). We highly value your privacy protection, and this Privacy Policy explains how we handle and protect your personal information and data. Please read and understand this agreement carefully before using this software:
To optimize user experience and improve software quality, we may only collect the following anonymous non-personal information: • Software version information; • Function activity and usage frequency; • Anonymous crash and error log information;
The above information is completely anonymous, does not involve any personally identifiable data, and cannot be associated with your personal information.
To maximize the protection of your privacy, we explicitly commit: • Will not collect, store, transmit, or process the model service API Key information you input into this software; • Will not collect, store, transmit, or process any conversation data generated during your use of this software, including but not limited to chat content, instruction information, knowledge base information, vector data, and other custom content; • Will not collect, store, transmit, or process any personally identifiable sensitive information.
This software uses the API Key of third-party model service providers that you apply for and configure yourself to complete model invocation and conversation functions. The model services you use (such as large language models, API interfaces, etc.) are provided and fully managed by the third-party provider you choose, and Cherry Studio only serves as a local tool providing interface invocation functionality with third-party model services.
Therefore: • All conversation data generated between you and the model service is unrelated to Cherry Studio. We neither participate in data storage nor perform any form of data transmission or relay; • You need to independently review and accept the privacy policies and relevant regulations of the corresponding third-party model service providers. These services' privacy policies can be viewed on each provider's official website.
You shall bear any privacy risks that may arise from using third-party model service providers. For specific privacy policies, data security measures, and related responsibilities, please refer to the relevant content on the official websites of your chosen model service providers. We assume no responsibility for these matters.
This agreement may be appropriately adjusted with software version updates. Please check it periodically. When substantive changes occur to the agreement, we will notify you through appropriate means.
If you have any questions regarding this agreement or Cherry Studio's privacy protection measures, please feel free to contact us at any time.
Thank you for choosing and trusting Cherry Studio. We will continue to provide you with a secure and reliable product experience.
This document was translated from Chinese by AI and has not yet been reviewed.
Quick Assistant is a convenient tool provided by Cherry Studio that allows you to quickly access AI functions in any application, enabling instant operations like asking questions, translation, summarization, and explanations.
Open Settings: Navigate to Settings -> Shortcuts -> Quick Assistant.
Enable Switch: Find and toggle on the Quick Assistant button.
Set Shortcut Key (Optional):
Default shortcut for Windows: Ctrl + E
Default shortcut for macOS: ⌘ + E
Customize your shortcut here to avoid conflicts or match your usage habits.
Activate: Press your configured shortcut key (or default shortcut) in any application to open Quick Assistant.
Interact: Within the Quick Assistant window, you can directly perform:
Quick Questions: Ask any question to the AI.
Text Translation: Input text to be translated.
Content Summarization: Input long text for summarization.
Explanation: Input concepts or terms requiring explanation.
Close: Press ESC or click anywhere outside the Quick Assistant window.
Shortcut Conflicts: Modify shortcuts if defaults conflict with other applications.
Explore More Functions: Beyond documented features, Quick Assistant may support operations like code generation and style transfer. Continuously explore during usage.
Feedback & Improvements: Report issues or suggestions to the Cherry Studio team via feedback.
This document was translated from Chinese by AI and has not yet been reviewed.
On this page, you can set the software's color theme, page layout, or customize CSS for personalized settings.
Here you can set the default interface color mode (light mode, dark mode, or follow system).
These settings are for the layout of the chat interface.
When this setting is enabled, clicking on the assistant's name will automatically switch to the corresponding topic page.
When enabled, the creation time of the topic will be displayed below it.
This setting allows flexible customization of the interface. For specific methods, please refer to Custom CSS in the advanced tutorial.
Windows 版本安装教程
This document was translated from Chinese by AI and has not yet been reviewed.
Note: Windows 7 system does not support Cherry Studio installation.
Click download to select the appropriate version
If the browser prompts that the file is not trusted, simply choose to keep it.
Choose to Keep→Trust Cherry-Studio
This document was translated from Chinese by AI and has not yet been reviewed.
The drawing feature currently supports painting models from DMXAPI, TokenFlux, AiHubMix, and . You can register an account at and to use this feature.
For questions about parameters, hover your mouse over the ? icon in corresponding areas to view descriptions.
This document was translated from Chinese by AI and has not yet been reviewed.
This page only introduces the interface functions. For configuration tutorials, please refer to the tutorial in the basic tutorials.
In Cherry Studio, a single service provider supports multi-key round-robin usage, where the keys are rotated from first to last in a list.
Add multiple keys separated by English commas, as shown in the example below:
You must use an English comma.
When using built-in service providers, you generally do not need to fill in the API address. If you need to modify it, please strictly follow the address provided in the official documentation.
If the address provided by the service provider is in the format https://xxx.xxx.com/v1/chat/completions, you only need to fill in the root address part (https://xxx.xxx.com).
Cherry Studio will automatically concatenate the remaining path (/v1/chat/completions). Not filling it as required may lead to improper functionality.
Typically, clicking the Manage button in the bottom left corner of the service provider configuration page will automatically fetch all models supported by that service provider. You can then click the + sign from the fetched list to add them to the model list.
Click the check button next to the API Key input box to test if the configuration is successful.
After successful configuration, make sure to turn on the switch in the upper right corner, otherwise, the service provider will remain disabled, and the corresponding models will not be found in the model list.
macOS 版本安装教程
This document was translated from Chinese by AI and has not yet been reviewed.
First, visit the official download page to download the Mac version, or click the direct link below
Please download the chip-specific version matching your Mac
After downloading, click here
Drag the icon to install
Find the Cherry Studio icon in Launchpad and click it. If the Cherry Studio main interface opens, the installation is successful.
This document was translated from Chinese by AI and has not yet been reviewed.
Log in to . If you don't have an Alibaba Cloud account, you'll need to register.
Click the Create My API-KEY button in the upper-right corner.
In the popup window, select the default workspace (or customize it if desired). You can optionally add a description.
Click the Confirm button in the lower-right corner.
You should now see a new entry in the list. Click the View button on the right.
Click the Copy button.
Go to Cherry Studio, navigate to Settings → Model Services → Alibaba Cloud Bailian, and paste the copied API key into the API Key field.
You can adjust related settings as described in , then start using the service.
This document was translated from Chinese by AI and has not yet been reviewed.
Log in and navigate to the tokens page
Create a new token (you can also directly use the default token ↑)
Copy the token
Open CherryStudio's service provider settings and click Add at the bottom of the provider list
Enter a note name, select OpenAI as the provider, and click OK
Paste the key you just copied
Return to the API Key page, copy the root address from the browser's address bar, for example:
Add models (click Manage to auto-fetch or enter manually) and toggle the switch in the top right corner to start using.
The interface may differ in other OneAPI themes, but the addition method follows the same workflow as above.
This document was translated from Chinese by AI and has not yet been reviewed.
1.2 Click the settings at the bottom left, and select 【SiliconFlow】 in the model service
1.2 Click the link to get SiliconCloud API Key
Log in to (if not registered, the first login will automatically register an account)
Visit to create a new key or copy an existing one
1.3 Click Manage to add models
Click the "Chat" button in the left menu bar
Enter text in the input box to start chatting
You can switch models by selecting the model name in the top menu
This document was translated from Chinese by AI and has not yet been reviewed.
To use GitHub Copilot, you must first have a GitHub account and subscribe to the GitHub Copilot service. The free subscription tier is acceptable, but note that it does not support the latest Claude 3.7 model. For details, refer to the .
Click "Log in with GitHub" to generate and copy your Device Code.
After obtaining your Device Code, click the link to open your browser. Log in to your GitHub account, enter the Device Code, and grant authorization.
After successful authorization, return to Cherry Studio and click "Connect GitHub". Your GitHub username and avatar will appear upon successful connection.
Click the "Manage" button below, which will automatically fetch the currently supported models list online.
The current implementation uses Axios for network requests. Note that Axios does not support SOCKS proxies. Please use a system proxy or HTTP proxy, or avoid setting proxies within CherryStudio and use a global proxy instead. First, ensure your network connection is stable to prevent Device Code retrieval failures.
This document was translated from Chinese by AI and has not yet been reviewed.
Use this method to clear CSS settings when incorrect CSS has been applied, or when you cannot access the settings interface after applying CSS.
Open the console by clicking on the CherryStudio window and pressing Ctrl+Shift+I (MacOS: command+option+I).
In the opened console window, click Console
Then manually enter document.getElementById('user-defined-custom-css').remove(). Copying and pasting will most likely not work.
After entering, press Enter to confirm and clear the CSS settings. Then, go back to CherryStudio's display settings and remove the problematic CSS code.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio data backup supports backup via S3 compatible storage (object storage). Common S3 compatible storage services include: AWS S3, Cloudflare R2, Alibaba Cloud OSS, Tencent Cloud COS, and MinIO.
Based on S3 compatible storage, multi-terminal data synchronization can be achieved by the method of Computer A S3 Storage Computer B.
Create an object storage bucket, and record the bucket name. It is highly recommended to set the bucket to private read/write to prevent backup data leakage!!
Refer to the documentation, go to the cloud service console to obtain information such as Access Key ID, Secret Access Key, Endpoint, Bucket, Region for S3 compatible storage.
Endpoint: The access address for S3 compatible storage, usually in the form of https://<bucket-name>.<region>.amazonaws.com or https://<ACCOUNT_ID>.r2.cloudflarestorage.com.
Region: The region where the bucket is located, such as us-west-1, ap-southeast-1, etc. For Cloudflare R2, please fill in auto.
Bucket: The bucket name.
Access Key ID and Secret Access Key: Credentials used for authentication.
Root Path: Optional, specifies the root path when backing up to the bucket, default is empty.
Related Documentation
AWS S3:
Cloudflare R2:
Alibaba Cloud OSS:
Tencent Cloud COS:
Fill in the above information in the S3 backup settings, click the backup button to perform backup, and click the manage button to view and manage the list of backup files.
This document was translated from Chinese by AI and has not yet been reviewed.
MCP (Model Context Protocol) is an open-source protocol designed to provide context information to Large Language Models (LLMs) in a standardized way. For more about MCP, see .
Below, we'll use the fetch function as an example to demonstrate how to use MCP in Cherry Studio. Details can be found in the .
Cherry Studio currently only uses its built-in and and will not reuse uv and bun already installed on your system.
In Settings - MCP Server, click the Install button to automatically download and install. Since it's downloaded directly from GitHub, the speed might be slow, and there's a high chance of failure. The success of the installation is determined by whether there are files in the folder mentioned below.
Executable installation directory:
Windows: C:\Users\username\.cherrystudio\bin
macOS, Linux: ~/.cherrystudio/bin
If installation fails:
You can symlink the corresponding commands from your system here. If the directory does not exist, you need to create it manually. Alternatively, you can manually download the executable files and place them in this directory:
Bun: UV:
This document was translated from Chinese by AI and has not yet been reviewed.
Automatically install MCP service (Beta)
Persistence memory base implementation based on local knowledge graph. This enables models to remember user-related information across different conversations.
An MCP server implementation providing tools for dynamic and reflective problem-solving through structured thought processes.
An MCP server implementation integrated with Brave Search API, offering dual functionality for both web and local searches.
MCP server for retrieving web content from URLs.
Node.js server implementing the Model Context Protocol (MCP) for file system operations.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio supports two ways to configure blacklists: manually and by adding subscription sources. For configuration rules, refer to
You can add rules for search results or click the toolbar icon to block specific websites. Rules can be specified using (e.g., *://*.example.com/*) or (e.g., /example\.(net|org)/).
You can also subscribe to public rule sets. This website lists some subscriptions: https://iorate.github.io/ublacklist/subscriptions
Here are some recommended subscription source links:
MEMORY_FILE_PATH=/path/to/your/file.jsonBRAVE_API_KEY=YOUR_API_KEY













https://git.io/ublacklist
Chinese
https://raw.githubusercontent.com/laylavish/uBlockOrigin-HUGE-AI-Blocklist/main/list_uBlacklist.txt
AI Generated

sk-xxxx1,sk-xxxx2,sk-xxxx3,sk-xxxx4









This document was translated from Chinese by AI and has not yet been reviewed.
This interface allows for local and cloud data backup and recovery, local data directory inquiry and cache clearing, export settings, and third-party connections.
Currently, data backup supports three methods: local backup, WebDAV backup, and S3-compatible storage (object storage) backup. For specific introductions and tutorials, please refer to the following documents:
Export settings allow you to configure the export options displayed in the export menu, as well as set the default path for Markdown exports, display styles, and more.
Third-party connections allow you to configure Cherry Studio's connection with third-party applications for quickly exporting conversation content to your familiar knowledge management applications. Currently supported applications include: Notion, Obsidian, SiYuan Note, Yuque, Joplin. For specific configuration tutorials, please refer to the following documents:
This document was translated from Chinese by AI and has not yet been reviewed.
We welcome contributions to Cherry Studio! You can contribute in the following ways:
Contribute code: Develop new features or optimize existing code.
Fix bugs: Submit bug fixes you discover.
Maintain issues: Help manage GitHub issues.
Product design: Participate in design discussions.
Write documentation: Improve user manuals and guides.
Community engagement: Join discussions and assist users.
Promote usage: Spread the word about Cherry Studio.
Email [email protected]
Email subject: Application to Become a Developer Email content: Reason for Application
This document was translated from Chinese by AI and has not yet been reviewed.
Email [email protected] to obtain editing privileges
Subject: Request for Cherry Studio Docs Editing Privileges
Body: State your reason for applying










This document was translated from Chinese by AI and has not yet been reviewed.
Follow our social accounts: Twitter (X), Xiaohongshu, Weibo, Bilibili, Douyin
Join our communities: QQ Group (575014769), Telegram, Discord, WeChat Group (Click to view)
Cherry Studio is an all-in-one AI assistant platform integrating multi-model conversations, knowledge base management, AI painting, translation, and more. Cherry Studio's highly customizable design, powerful extensibility, and user-friendly experience make it an ideal choice for both professional users and AI enthusiasts. Whether you are a beginner or a developer, you can find suitable AI features in Cherry Studio to enhance your work efficiency and creativity.
Multi-Model Responses: Supports generating replies to the same question simultaneously through multiple models, allowing users to compare the performance of different models. See Chat Interface for details.
Automatic Grouping: Chat records for each assistant are automatically grouped and managed, making it easy for users to quickly find historical conversations.
Chat Export: Supports exporting full or partial conversations into various formats (e.g., Markdown, Word), facilitating storage and sharing.
Highly Customizable Parameters: In addition to basic parameter adjustments, it also supports users filling in custom parameters to meet personalized needs.
Assistant Marketplace: Built-in with over a thousand industry-specific assistants covering translation, programming, writing, and other fields, while also supporting user-defined assistants.
Multi-Format Rendering: Supports Markdown rendering, formula rendering, real-time HTML preview, and other features to enhance content display.
AI Painting: Provides a dedicated drawing panel, allowing users to generate high-quality images through natural language descriptions.
AI Mini-Apps: Integrates various free web-based AI tools, allowing direct use without switching browsers.
Translation Feature: Supports dedicated translation panel, chat translation, prompt translation, and various other translation scenarios.
File Management: Files within chats, paintings, and knowledge bases are uniformly categorized and managed to avoid tedious searching.
Global Search: Supports quick location of historical records and knowledge base content, improving work efficiency.
Service Provider Model Aggregation: Supports unified invocation of models from mainstream service providers such as OpenAI, Gemini, Anthropic, and Azure.
Automatic Model Retrieval: One-click retrieval of the complete model list, no manual configuration required.
Multiple API Key Rotation: Supports rotating multiple API keys to avoid rate limit issues.
Accurate Avatar Matching: Automatically matches exclusive avatars for each model to enhance recognition.
Custom Service Providers: Supports the integration of third-party service providers compliant with OpenAI, Gemini, Anthropic, etc., offering strong compatibility.
Custom CSS: Supports global style customization to create a unique interface style.
Custom Chat Layout: Supports list or bubble style layouts, and allows customizing message styles (e.g., code snippet styles).
Custom Avatars: Supports setting personalized avatars for the software and assistants.
Custom Sidebar Menu: Users can hide or reorder sidebar functions according to their needs to optimize the user experience.
Multi-Format Support: Supports importing various file formats such as PDF, DOCX, PPTX, XLSX, TXT, and MD.
Multiple Data Source Support: Supports local files, URLs, sitemaps, and even manual input content as knowledge base sources.
Knowledge Base Export: Supports exporting processed knowledge bases for sharing with others.
Search Verification Support: After importing the knowledge base, users can perform real-time retrieval tests to view processing results and segmentation effects.
Quick Q&A: Summon the quick assistant in any scenario (e.g., WeChat, browser) to quickly get answers.
Quick Translate: Supports quick translation of words or text in other scenarios.
Content Summary: Quickly summarizes long text content, improving information extraction efficiency.
Explanation: Explains confusing questions with one click, no complex prompts required.
Multiple Backup Solutions: Supports local backup, WebDAV backup, and scheduled backup to ensure data security.
Data Security: Supports full local usage scenarios, combined with local large models, to avoid data leakage risks.
Beginner-Friendly: Cherry Studio is committed to lowering technical barriers, allowing users with no prior experience to get started quickly and focus on work, study, or creation.
Comprehensive Documentation: Provides detailed user documentation and a FAQ handbook to help users quickly resolve issues.
Continuous Iteration: The project team actively responds to user feedback and continuously optimizes features to ensure the healthy development of the project.
Open Source and Extensibility: Supports users in customizing and extending through open-source code to meet personalized needs.
Knowledge Management and Query: Quickly build and query exclusive knowledge bases through the local knowledge base feature, suitable for research, education, and other fields.
Multi-Model Chat and Creation: Supports simultaneous multi-model conversations, helping users quickly obtain information or generate content.
Translation and Office Automation: Built-in translation assistant and file processing features, suitable for users needing cross-language communication or document processing.
AI Painting and Design: Generate images through natural language descriptions to meet creative design needs.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio's translation feature provides you with fast and accurate text translation services, supporting mutual translation between multiple languages.
The translation interface mainly consists of the following components:
Source Language Selection Area:
Any Language: Cherry Studio will automatically identify the source language and perform translation.
Target Language Selection Area:
Dropdown Menu: Select the language you wish to translate the text into.
Settings Button:
Clicking will jump to Default Model Settings.
Scroll Synchronization:
Toggle to enable scroll sync (scrolling in either side will synchronize the other).
Text Input Box (Left):
Input or paste the text you need to translate.
Translation Result Box (Right):
Displays the translated text.
Copy Button: Click to copy the translation result to clipboard.
Translate Button:
Click this button to start translation.
Translation History (Top Left):
Click to view translation history records.
Select Target Language:
Choose your desired translation language in the Target Language Selection Area.
Input or Paste Text:
Enter or paste the text to be translated in the left text input box.
Start Translation:
Click the Translate button.
View and Copy Results:
Translation results will appear in the right result box.
Click the copy button to save the result to clipboard.
Q: What to do about inaccurate translations?
A: While AI translation is powerful, it's not perfect. For professional fields or complex contexts, manual proofreading is recommended. You may also try switching different models.
Q: Which languages are supported?
A: Cherry Studio translation supports multiple major languages. Refer to Cherry Studio's official website or in-app instructions for the specific supported languages list.
Q: Can entire files be translated?
A: The current interface primarily handles text translation. For document translation, please use Cherry Studio's conversation page to add files for translation.
Q: How to handle slow translation speeds?
A: Translation speed may be affected by network connection, text length, or server load. Ensure stable network connectivity and be patient.
暂时不支持Claude模型
This document was translated from Chinese by AI and has not yet been reviewed.
Before obtaining a Gemini API Key, you need to have a Google Cloud project (if you already have one, you can skip this step)
Go to Google Cloud to create a project, fill in the project name, and click "Create Project"
Go to the Vertex AI console
Enable the Vertex AI API in the created project
Open the Service Accounts permissions interface and create a service account
On the service account management page, find the service account you just created, click on Keys and create a new JSON format key
After successful creation, the key file will be automatically saved to your computer in JSON format. Please keep it safe
Select Vertex AI as the service provider
Fill in the corresponding fields from the JSON file
Click "Add Model" to start using it happily!
This document was translated from Chinese by AI and has not yet been reviewed.
Create an account and log in at Huawei Cloud
Click this link to enter the MaaS control panel
Authorization
Click Authentication Management in the sidebar, create an API Key (secret key) and copy it
Then create a new service provider in CherryStudio
After creation, enter the secret key
Click Model Deployment in the sidebar, claim all offerings
Click Call
Copy the address from ①, paste it into CherryStudio's service provider address field and add a "#" at the end and add a "#" at the end and add a "#" at the end and add a "#" at the end and add a "#" at the end Why add "#"? [see here](https://docs.cherry-ai.com/cherrystudio/preview/settings/providers#api-di-zhi) > You can choose not to read that and just follow this tutorial; > Alternatively, you can fill it by removing v1/chat/completions - feel free to use your own method if you know how, but if not, strictly follow this tutorial.
Then copy the model name from ②, and click the "+ Add" button in CherryStudio to create a new model
Enter the model name exactly as shown - do not add or remove anything, and don't include quotes. Copy exactly as in the example.
Click the Add Model button to complete.
This document was translated from Chinese by AI and has not yet been reviewed.
On the official API Key page, click + Create new secret key
Copy the generated key and open CherryStudio's Service Provider Settings
Find the service provider OpenAI and enter the key you just obtained.
Click "Manage" or "Add" at the bottom to add supported models, and then turn on the service provider switch in the top right corner to start using it.
This document was translated from Chinese by AI and has not yet been reviewed.
Have you ever experienced: saving 26 insightful articles in WeChat that you never open again, storing over 10 scattered files in a "Study Materials" folder on your computer, or trying to recall a theory you read half a year ago only to remember fragmented keywords? And when daily information exceeds your brain's processing limit, 90% of valuable knowledge gets forgotten within 72 hours. Now, by leveraging the Infini-AI large model service platform API + Cherry Studio to build a personal knowledge base, you can transform dust-collecting WeChat articles and fragmented course content into structured knowledge for precise retrieval.
1. Infini-AI API Service: The Stable "Thinking Hub" of Knowledge Bases
Serving as the "thinking hub" of knowledge bases, the Infini-AI large model service platform offers robust API services including full-capacity DeepSeek R1 and other model versions. Currently free to use without barriers after registration. Supports mainstream embedding models (bge, jina) for knowledge base construction. The platform continuously updates with the latest, most powerful open-source models, covering multiple modalities like images, videos, and audio.
2. Cherry Studio: Zero-Code Knowledge Base Setup
Compared to RAG knowledge base development requiring 1-2 months deployment time, Cherry Studio offers a significant advantage: zero-code operation. Instantly import multiple formats like Markdown/PDF/web pages – parsing 40MB files in 1 minute. Easily add local folders, saved WeChat articles, and course notes.
Step 1: Basic Preparation
Download the suitable version from Cherry Studio official site (https://cherry-ai.com/)
Register account: Log in to Infini-AI platform (https://cloud.infini-ai.com/genstudio/model?cherrystudio)
Get API key: Select "deepseek-r1" in Model Square, create and copy the API key + model name
Step 2: CherryStudio Settings
Go to model services → Select Infini-AI → Enter API key → Activate Infini-AI service
After setup, select the large model during interaction to use Infini-AI API in CherryStudio. Optional: Set as default model for convenience
Step 3: Add Knowledge Base
Choose any version of bge-series or jina-series embedding models from Infini-AI platform
After importing study materials, query: "Outline core formula derivations in Chapter 3 of 'Machine Learning'"
Result Demonstration
This document was translated from Chinese by AI and has not yet been reviewed.
Log in and open the token page
Click "Add Token"
Enter a token name and click Submit (configure other settings if needed)
Open CherryStudio's provider settings and click Add at the bottom of the provider list
Enter a remark name, select OpenAI as the provider, and click OK
Paste the key you just copied
Return to the API Key acquisition page and copy the root address from the browser's address bar, for example:
Add models (click Manage to automatically fetch or manually enter) and toggle the switch at the top right to use.
如何注册tavily?
This document was translated from Chinese by AI and has not yet been reviewed.
Visit the official website above, or go to Cherry Studio > Settings > Web Search > click "Get API Key" to directly access Tavily's login/registration page.
First-time users must register (Sign up) before logging in (Log in). The default page is the login interface.
Click "Sign up" and enter your email (or use Google/GitHub account) followed by your password.
🚨🚨🚨[Critical Step] After registration, a dynamic verification code is required. Scan the QR code to generate a one-time code.
Two solutions:
Download Microsoft Authenticator app (slightly complex)
Use WeChat Mini Program: Tencent Authenticator (recommended, as simple as it gets).
Search "Tencent Authenticator" in WeChat Mini Programs:
After completing these steps, you'll see the dashboard. Copy the API key to Cherry Studio to start using Tavily!
This document was translated from Chinese by AI and has not yet been reviewed.
Supports exporting topics and messages to SiYuan Note.
Open SiYuan Note and create a notebook
Open notebook settings and copy the Notebook ID
Paste the copied notebook ID into Cherry Studio settings
Fill in the SiYuan Note address
Local
Typically http://127.0.0.1:6806
Self-hosted
Use your domain http://note.domain.com
Copy the SiYuan Note API Token
Paste it into Cherry Studio settings and check
Congratulations, the configuration for SiYuan Note is complete ✅ Now you can export content from Cherry Studio to your SiYuan Note
This document was translated from Chinese by AI and has not yet been reviewed.
Automatic installation of MCP requires upgrading Cherry Studio to v1.1.18 or higher.
In addition to manual installation, Cherry Studio has a built-in @mcpmarket/mcp-auto-install tool that provides a more convenient way to install MCP servers. You simply need to enter specific commands in conversations with large models that support MCP services.
Beta Phase Reminder:
@mcpmarket/mcp-auto-install is currently in beta phase
Effectiveness depends on the "intelligence" of the large model - some configurations are automatically added, while others still require manual parameter adjustments in MCP settings
Current search sources are from @modelcontextprotocol, but this can be customized (explained below)
For example, you can input:
Help me install a filesystem mcp serverThe system will automatically recognize your requirements and complete the installation via @mcpmarket/mcp-auto-install. This tool supports various types of MCP servers, including but not limited to:
filesystem (file system)
fetch (network requests)
sqlite (database)
etc.
The MCP_PACKAGE_SCOPES variable allows customization of MCP service search sources. Default value:
@modelcontextprotocol.
@mcpmarket/mcp-auto-install LibraryThis document was translated from Chinese by AI and has not yet been reviewed.
Data added to the Cherry Studio knowledge base is entirely stored locally. During the addition process, a copy of the document will be placed in the Cherry Studio data storage directory.
Vector Database: https://turso.tech/libsql
After documents are added to the Cherry Studio knowledge base, they are segmented into multiple fragments. These fragments are then processed by the embedding model.
When using large models for Q&A, relevant text fragments matching the query will be retrieved and processed together by the large language model.
If you have data privacy requirements, it is recommended to use local embedding databases and local large language models.
This document was translated from Chinese by AI and has not yet been reviewed.
Dify Knowledge Base MCP requires upgrading Cherry Studio to v1.2.9 or higher.
Open Search MCP.
Add the dify-knowledge server.
Requires configuring parameters and environment variables
Dify Knowledge Base key can be obtained in the following way:
This document was translated from Chinese by AI and has not yet been reviewed.
Knowledge base document preprocessing requires upgrading Cherry Studio to v1.4.8 or higher.
After clicking 'Get API KEY', the application address will open in your browser. Click 'Apply Now' to fill out the form and obtain the API KEY, then fill it into the API KEY field.
Configure as shown above in the created knowledge base to complete the knowledge base document preprocessing configuration.
You can check knowledge base results by searching in the top right corner.
Knowledge Base Usage Tips: When using more capable models, you can change the knowledge base search mode to intent recognition. Intent recognition can describe your questions more accurately and broadly.
This document was translated from Chinese by AI and has not yet been reviewed.
Contact Person: Mr. Wang 📮: [email protected] 📱: 18954281942 (Not a customer service hotline)
For usage inquiries: • Join our user community at the bottom of the official website homepage • Email [email protected] • Or submit issues: https://github.com/CherryHQ/cherry-studio/issues
For additional guidance, join our Knowledge Planet
Commercial license details: https://docs.cherry-ai.com/contact-us/questions/cherrystudio-xu-ke-xie-yi
This document was translated from Chinese by AI and has not yet been reviewed.
Before obtaining the Gemini API key, you need a Google Cloud project (skip this step if you already have one).
Go to to create a project, fill in the project name, and click "Create Project".
On the official , click Create API Key.
Copy the generated key, then open CherryStudio's .
Find the Gemini service provider and enter the key you just obtained.
Click "Manage" or "Add" at the bottom, add the supported models, then toggle the service provider switch at the top right to start using.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio supports importing topics into Notion databases.
Visit to create an application
Create an application
Name: Cherry Studio Type: Select the first option Icon: You can save this image
Copy the secret key and enter it in Cherry Studio settings
Open website and create a new page. Select database type below, name it Cherry Studio, and connect as shown
If your Notion database URL looks like this:
https://www.notion.so/<long_hash_1>?v=<long_hash_2>
Then the Notion database ID is the part <long_hash_1>
Fill in Page Title Field Name:
If your interface is in English, enter Name
If your interface is in Chinese, enter 名称
Congratulations! Notion configuration is complete ✅ You can now export Cherry Studio content to your Notion database
This document was translated from Chinese by AI and has not yet been reviewed.
Log in to
Or click
Click in the sidebar
Create an API Key
After creation, click the eye icon next to the created API Key to reveal and copy it
Paste the copied API Key into Cherry Studio and then toggle the provider switch to ON
Enable the models you need at the bottom of the sidebar in the Ark console under . You can enable the Doubao series, DeepSeek, and other models as required
In the , find the model ID corresponding to the desired model
Open Cherry Studio's settings and locate Volcano Engine
Click Add, then paste the previously obtained model ID into the model ID text field
Follow this process to add models one by one
There are two ways to write the API address:
First, the default in the client: https://ark.cn-beijing.volces.com/api/v3/
Second: https://ark.cn-beijing.volces.com/api/v3/chat/completions#
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio data backup supports WebDAV for backup. You can choose a suitable WebDAV service for cloud backup.
Based on WebDAV, you can achieve multi-device data synchronization through Computer A WebDAV Computer B.
Log in to Jianguoyun, click your username in the top right corner, and select "Account Info":
Select "Security Options" and click "Add Application":
Enter the application name and generate a random password;
Copy and record the password;
Get the server address, account, and password;
In Cherry Studio Settings -> Data Settings, fill in the WebDAV information;
Choose to back up or restore data, and you can set the automatic backup time period.
WebDAV services with a lower barrier to entry are generally cloud drives:
(requires membership)
(requires purchase)
(Free storage capacity is 10GB, single file size limit is 250MB.)
(Dropbox offers 2GB free, can expand by 16GB by inviting friends.)
(Free space is 10GB, an additional 5GB can be obtained through invitation.)
(Free users get 10GB capacity.)
Secondly, there are some services that require self-deployment:
This document was translated from Chinese by AI and has not yet been reviewed.
Open Cherry Studio settings.
Find the MCP Server option.
Click Add Server.
Fill in the relevant parameters for the MCP Server (). Content that may need to be filled in includes:
Name: Customize a name, for example fetch-server
Type: Select STDIO
Command: Enter uvx
Arguments: Enter mcp-server-fetch
(There may be other parameters, depending on the specific Server)
Click Save.
After completing the above configuration, Cherry Studio will automatically download the required MCP Server - fetch server. Once the download is complete, we can start using it! Note: If mcp-server-fetch fails to configure, try restarting your computer.
Successfully added the MCP Server in the MCP Server settings.
As seen from the image above, by integrating MCP's fetch capability, Cherry Studio can better understand user query intent, retrieve relevant information from the web, and provide more accurate and comprehensive answers.
This document was translated from Chinese by AI and has not yet been reviewed.
ModelScope MCP Server requires Cherry Studio to be upgraded to v1.2.9 or higher.
In version v1.2.9, Cherry Studio and ModelScope reached an official collaboration, greatly simplifying the steps for adding MCP servers, avoiding configuration errors, and allowing you to discover a vast number of MCP servers in the ModelScope community. Follow the steps below to see how to sync ModelScope's MCP servers in Cherry Studio.
Click on MCP Server Settings in Settings, then select Sync Servers.
Select ModelScope and browse to discover MCP services.
Register and log in to ModelScope, then view MCP service details;
In the MCP service details, select connect to service;
Click "Get API Token" in Cherry Studio to jump to the ModelScope official website, copy the API token, and then paste it back into Cherry Studio.
In Cherry Studio's MCP server list, you can see the ModelScope connected MCP services and invoke them in conversations.
For newly connected MCP servers on the ModelScope website in the future, simply click Sync Servers to add them incrementally.
Through the steps above, you have successfully mastered how to conveniently sync MCP servers from ModelScope in Cherry Studio. The entire configuration process is not only greatly simplified, effectively avoiding the tediousness and potential errors of manual configuration, but also allows you to easily access the vast MCP server resources provided by the ModelScope community.
Start exploring and using these powerful MCP services to bring more convenience and possibilities to your Cherry Studio experience!
This document was translated from Chinese by AI and has not yet been reviewed.
Join the Telegram discussion group for assistance:
GitHub Issues:
Email the developers: [email protected]
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio is a free and open-source project. As the project grows, the workload of the team increases significantly. To reduce communication costs and efficiently resolve your issues, we encourage everyone to follow the steps below when reporting problems. This will allow our team to dedicate more time to project maintenance and development. Thank you for your cooperation!
Most basic problems can be resolved by carefully reviewing the documentation:
Functionality and usage questions can be answered in the documentation;
High-frequency issues are compiled on the page—check there first for solutions;
Complex questions can often be resolved through search or using the search bar;
Carefully read all hint boxes in documents to avoid many common issues;
Check existing solutions in the GitHub .
For model-related issues unrelated to client functionality (e.g., model errors, unexpected responses, parameter settings):
Search online for solutions first;
Provide error messages to AI assistants for resolution suggestions.
If steps 1-2 don't solve your problem:
Seek help in our official , , or () When reporting:
For model errors:
Provide full screenshots with error messages visible
Include console errors ()
Sensitive information can be redacted, but keep model names, parameters, and error details
For software bugs:
Give detailed error descriptions
Provide precise reproduction
Include OS (Windows/Mac/Linux) and software version number
For intermittent issues, describe scenarios and configurations comprehensively
Request Documentation or Suggest Improvements
Contact via Telegram @Wangmouuu, QQ (1355873789), or email [email protected].
Monaspace
English Font Commercial Use
GitHub has launched an open-source font family called Monaspace, featuring five styles: Neon (modern style), Argon (humanist style), Xenon (serif style), Radon (handwritten style), and Krypton (mechanical style).
MiSans Global
Multilingual Commercial Use
MiSans Global is a global language font customization project led by Xiaomi, created in collaboration with Monotype and Hanyi.
This comprehensive font family covers over 20 writing systems and supports more than 600 languages.















































































































如何在 Cherry Studio 使用联网模式
This document was translated from Chinese by AI and has not yet been reviewed.
In the Cherry Studio question window, click the 【Globe】 icon to enable internet access.
Mode 1: Models with built-in internet function from providers
When using such models, enabling internet access requires no extra steps - it's straightforward.
Quickly identify internet-enabled models by checking for a small globe icon next to the model name above the chat interface.
This method also helps quickly distinguish internet-enabled models in the Model Management page.
Cherry Studio currently supports internet-enabled models from
Google Gemini
OpenRouter (all models support internet)
Tencent Hunyuan
Zhipu AI
Alibaba Bailian, etc.
Important note:
Special cases exist where models may access internet without the globe icon, as explained in the tutorial below.
Mode 2: Models without internet function use Tavily service
When using models without built-in internet (no globe icon), use Tavily search service to process real-time information.
First-time Tavily setup triggers a setup prompt - simply follow the instructions!
After clicking, you'll be redirected to Tavily's website to register/login. Create and copy your API key back to Cherry Studio.
Registration guide available in Tavily tutorial within this documentation directory.
Tavily registration reference:
The following interface confirms successful registration.
Test again for results: shows normal internet search with default result count (5).
Note: Tavily has monthly free tier limits - exceeding requires payment~~
PS: Please report any issues you encounter.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio not only integrates mainstream AI model services but also empowers you with powerful customization capabilities. Through the Custom AI Providers feature, you can easily integrate any AI model you require.
Flexibility: Break free from predefined provider lists and freely choose the AI models that best suit your needs.
Diversity: Experiment with various AI models from different platforms to discover their unique advantages.
Controllability: Directly manage your API keys and access addresses to ensure security and privacy.
Customization: Integrate privately deployed models to meet the demands of specific business scenarios.
Add your custom AI provider to Cherry Studio in just a few simple steps:
Open Settings: Click the "Settings" (gear icon) in the left navigation bar of the Cherry Studio interface.
Enter Model Services: Select the "Model Services" tab in the settings page.
Add Provider: On the "Model Services" page, you'll see existing providers. Click the "+ Add" button below the list to open the "Add Provider" pop-up.
Fill in Information: In the pop-up, provide the following details:
Provider Name: Give your custom provider a recognizable name (e.g., MyCustomOpenAI).
Provider Type: Select your provider type from the dropdown menu. Currently supports:
OpenAI
Gemini
Anthropic
Azure OpenAI
Save Configuration: After filling in the details, click the "Add" button to save your configuration.
After adding, locate your newly added provider in the list and configure it:
Activation Status: Toggle the activation switch on the far right of the list to enable this custom service.
API Key:
Enter the API key provided by your AI provider.
Click the "Test" button to verify the key's validity.
API Address:
Enter the base URL to access the AI service.
Always refer to your AI provider's official documentation for the correct API address.
Model Management:
Click the "+ Add" button to manually add model IDs you want to use under this provider (e.g., gpt-3.5-turbo, gemini-pro).
If unsure about specific model names, consult your AI provider's official documentation.
Click the "Manage" button to edit or delete added models.
After completing the above configurations, you can select your custom AI provider and model in Cherry Studio's chat interface and start conversing with AI!
vLLM is a fast and easy-to-use LLM inference library similar to Ollama. Here's how to integrate vLLM into Cherry Studio:
Install vLLM: Follow vLLM's official documentation (https://docs.vllm.ai/en/latest/getting_started/quickstart.html) to install vLLM.
pip install vllm # if using pip
uv pip install vllm # if using uvLaunch vLLM Service: Start the service using vLLM's OpenAI-compatible interface via two main methods:
Using vllm.entrypoints.openai.api_server
python -m vllm.entrypoints.openai.api_server --model gpt2Using uvicorn
vllm --model gpt2 --served-model-name gpt2Ensure the service launches successfully, listening on the default port 8000. You can also specify a different port using the --port parameter.
Add vLLM Provider in Cherry Studio:
Follow the steps above to add a new custom AI provider.
Provider Name: vLLM
Provider Type: Select OpenAI.
Configure vLLM Provider:
API Key: Leave this field blank or enter any value since vLLM doesn't require an API key.
API Address: Enter vLLM's API address (default: http://localhost:8000/, adjust if using a different port).
Model Management: Add the model name loaded in vLLM (e.g., gpt2 for the command python -m vllm.entrypoints.openai.api_server --model gpt2).
Start Chatting: Now select the vLLM provider and the gpt2 model in Cherry Studio to chat with the vLLM-powered LLM!
Read Documentation Carefully: Before adding custom providers, thoroughly review your AI provider's official documentation for API keys, addresses, model names, etc.
Test API Keys: Use the "Test" button to quickly verify API key validity.
Verify API Addresses: Different providers and models may have varying API addresses—ensure correctness.
Add Models Judiciously: Only add models you'll actually use to avoid cluttering.
This document was translated from Chinese by AI and has not yet been reviewed.
ModelScope is a new generation open-source Model-as-a-Service (MaaS) sharing platform, dedicated to providing flexible, easy-to-use, and low-cost one-stop model service solutions for general AI developers, making model application simpler!
Through its API-Inference as a Service capability, the platform standardizes open-source models into callable API interfaces, allowing developers to easily and quickly integrate model capabilities into various AI applications, supporting innovative scenarios such as tool invocation and prototype development.
✅ Free Quota: Provides 2000 free API calls daily (Billing Rules)
✅ Rich Model Library: Covers 1000+ open-source models including NLP, CV, Speech, Multimodal, etc.
✅ Ready-to-Use: No deployment needed, quick invocation via RESTful API
Log In to the Platform
Visit ModelScope Official Website → Click Log In at the top right → Select authentication method
Create Access Token
Click New Token → Fill in description → Copy the generated token (Page example shown below)
🔑 Important Tip: Token leakage will affect account security!
Open Cherry Studio → Settings → Model Service → ModelScope
Paste the copied token into the API Key field
Click Save to complete authorization
Find Models Supporting API
Visit ModelScope Model Library
Filter: Check API-Inference (or look for the API icon on the model card)
The scope of models covered by API-Inference is primarily determined by their popularity within the Moda community (referencing data such as likes and downloads). Therefore, the list of supported models will continue to iterate after the release of more powerful and highly-regarded next-generation open-source models.
Get Model ID
Go to the target model's detail page → Copy Model ID (format like damo/nlp_structbert_sentiment-classification_chinese-base)
Fill into Cherry Studio
On the model service configuration page, enter the ID in the Model ID field → Select task type → Complete configuration
🎫 Free Quota: 2000 API calls per user daily (*Subject to the latest rules on the official website)
🔁 Quota Reset: Automatically resets daily at UTC+8 00:00, does not support cross-day accumulation or upgrade
💡 Over-quota Handling:
After reaching the daily limit, the API will return a 429 error
Solution: Switch to a backup account / Use another platform / Optimize call frequency
Log in to ModelScope → Click Username at the top right → API Usage
⚠️ Note: Inference API-Inference has a free daily quota of 2000 calls. For more calling needs, consider using cloud services like Alibaba Cloud Bailian.
This document was translated from Chinese by AI and has not yet been reviewed.
By customizing CSS, you can modify the software's appearance to better suit your preferences, like this:
:root {
--color-background: #1a462788;
--color-background-soft: #1a4627aa;
--color-background-mute: #1a462766;
--navbar-background: #1a4627;
--chat-background: #1a4627;
--chat-background-user: #28b561;
--chat-background-assistant: #1a462722;
}
#content-container {
background-color: #2e5d3a !important;
}:root {
font-family: "汉仪唐美人" !important; /* Font */
}
/* Color of expanded deep thinking text */
.ant-collapse-content-box .markdown {
color: red;
}
/* Theme variables */
:root {
--color-black-soft: #2a2b2a; /* Dark background color */
--color-white-soft: #f8f7f2; /* Light background color */
}
/* Dark theme */
body[theme-mode="dark"] {
/* Colors */
--color-background: #2b2b2b; /* Dark background color */
--color-background-soft: #303030; /* Light background color */
--color-background-mute: #282c34; /* Neutral background color */
--navbar-background: var(-–color-black-soft); /* Navigation bar background */
--chat-background: var(–-color-black-soft); /* Chat background */
--chat-background-user: #323332; /* User chat background */
--chat-background-assistant: #2d2e2d; /* Assistant chat background */
}
/* Dark theme specific styles */
body[theme-mode="dark"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* Content container background */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* Messages background */
}
.inputbar-container {
background-color: #3d3d3a; /* Input bar background */
border: 1px solid #5e5d5940; /* Input bar border color */
border-radius: 8px; /* Input bar border radius */
}
/* Code styles */
code {
background-color: #e5e5e20d; /* Code background */
color: #ea928a; /* Code text color */
}
pre code {
color: #abb2bf; /* Preformatted code text color */
}
}
/* Light theme */
body[theme-mode="light"] {
/* Colors */
--color-white: #ffffff; /* White */
--color-background: #ebe8e2; /* Light background */
--color-background-soft: #cbc7be; /* Light background */
--color-background-mute: #e4e1d7; /* Neutral background */
--navbar-background: var(-–color-white-soft); /* Navigation bar background */
--chat-background: var(-–color-white-soft); /* Chat background */
--chat-background-user: #f8f7f2; /* User chat background */
--chat-background-assistant: #f6f4ec; /* Assistant chat background */
}
/* Light theme specific styles */
body[theme-mode="light"] {
#content-container {
background-color: var(-–chat-background-assistant) !important; /* Content container background */
}
#content-container #messages {
background-color: var(-–chat-background-assistant); /* Messages background */
}
.inputbar-container {
background-color: #ffffff; /* Input bar background */
border: 1px solid #87867f40; /* Input bar border color */
border-radius: 8px; /* Input bar border radius */
}
/* Code styles */
code {
background-color: #3d39290d; /* Code background */
color: #7c1b13; /* Code text color */
}
pre code {
color: #000000; /* Preformatted code text color */
}
}For more theme variables, refer to the source code: https://github.com/CherryHQ/cherry-studio/tree/main/src/renderer/src/assets/styles
Cherry Studio Theme Library: https://github.com/boilcy/cherrycss
Share some Chinese-style Cherry Studio theme skins: https://linux.do/t/topic/325119/129
This document was translated from Chinese by AI and has not yet been reviewed.
Trace provides users with dialogue insights, helping them understand the specific performance of models, knowledge bases, MCP, web search, etc., during the conversation process. It is an observability tool implemented based on OpenTelemetry, which enables visualization through client-side data collection, storage, and processing, providing quantitative evaluation basis for problem localization and performance optimization.
Each conversation corresponds to one trace data, and a trace is composed of multiple spans. Each span corresponds to a program processing logic in Cherry Studio, such as calling a model session, calling MCP, calling a knowledge base, calling web search, etc. Traces are displayed in a tree structure, with spans as tree nodes. The main data includes time consumption and token usage. Of course, the specific input and output can also be viewed in the span details.
By default, after Cherry Studio is installed, Trace is hidden. It needs to be enabled in "Settings" - "General Settings" - "Developer Mode", as shown below:
Also, Trace records will not be generated for previous sessions; they will only be generated after new questions and answers occur. The generated records are stored locally. If you need to clear Trace completely, you can do so by going to "Settings" - "Data Settings" - "Data Directory" - "Clear Cache", or by manually deleting files under ~/.cherrystudio/trace, as shown below:
Click "Trace" in the Cherry Studio chat window to view the full trace data. Regardless of whether a model, web search, knowledge base, or MCP was called during the conversation, you can view the full trace data in the trace window.
If you want to view the details of a model in the trace, click on the model call node to view its input and output details.
If you want to view the details of a web search in the trace, click on the web search call node to view its input and output details. In the details, you can see the question queried by the web search and its returned results.
If you want to view the details of a knowledge base in the trace, click on the knowledge base call node to view its input and output details. In the details, you can see the question queried by the knowledge base and its returned answer.
If you want to view the details of MCP in the trace, click on the MCP call node to view its input and output details. In the details, you can see the input parameters for calling this MCP Server tool and the tool's return.
This feature is provided by the Alibaba Cloud EDAS team. If you have any questions or suggestions, please join the DingTalk group (Group ID: 21958624) for in-depth communication with the developers.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio is a multi-model desktop client currently supporting installation packages for Windows, Linux, and macOS systems. It integrates mainstream LLM models to provide multi-scenario assistance. Users can enhance work efficiency through smart conversation management, open-source customization, and multi-theme interfaces.
Cherry Studio is now deeply integrated with PPIO's High-Performance API Channel – leveraging enterprise-grade computing power to ensure high-speed response for DeepSeek-R1/V3 and 99.9% service availability, delivering a fast and smooth experience.
The tutorial below provides a complete integration solution (including API key configuration), enabling the advanced mode of Cherry Studio Intelligent Scheduling + PPIO High-Performance API within 3 minutes.
First download Cherry Studio from the official website: (If inaccessible, download your required version from Quark Netdisk: )
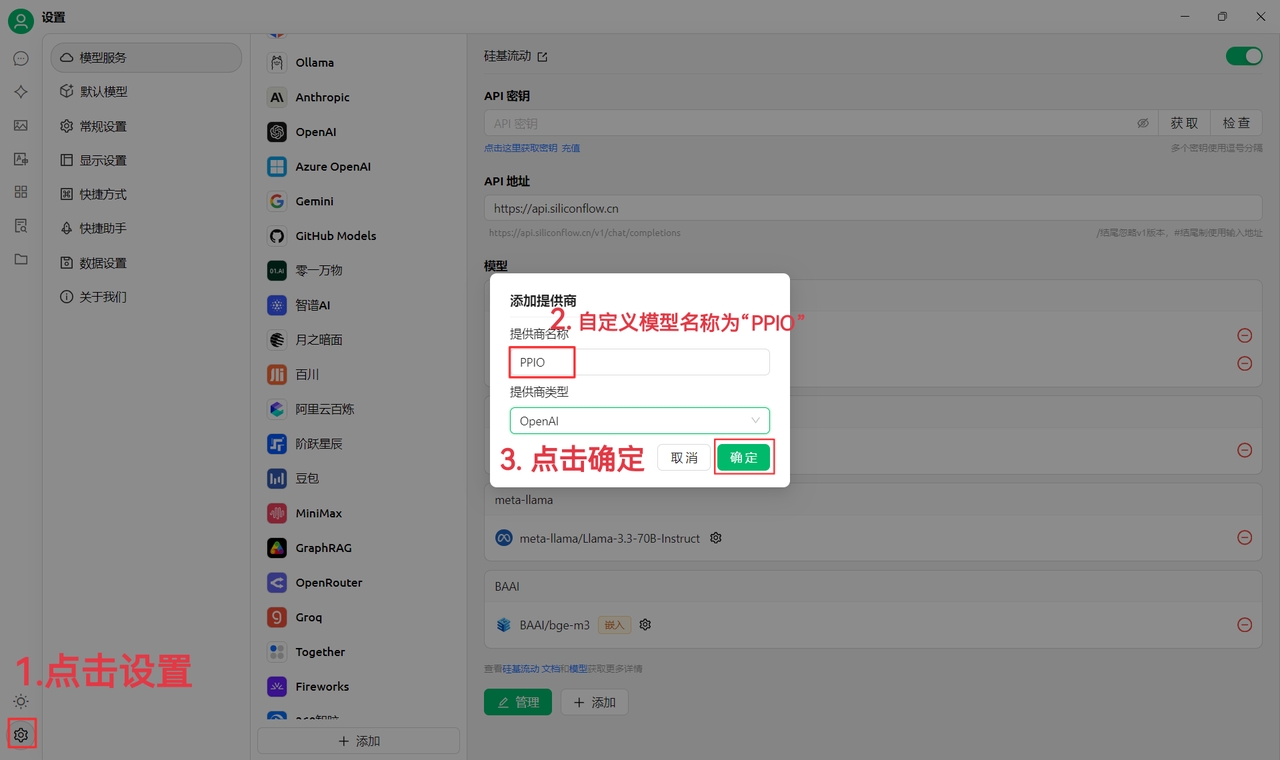
(1) Click the settings icon in the bottom left corner, set the provider name to PPIO, and click "OK"
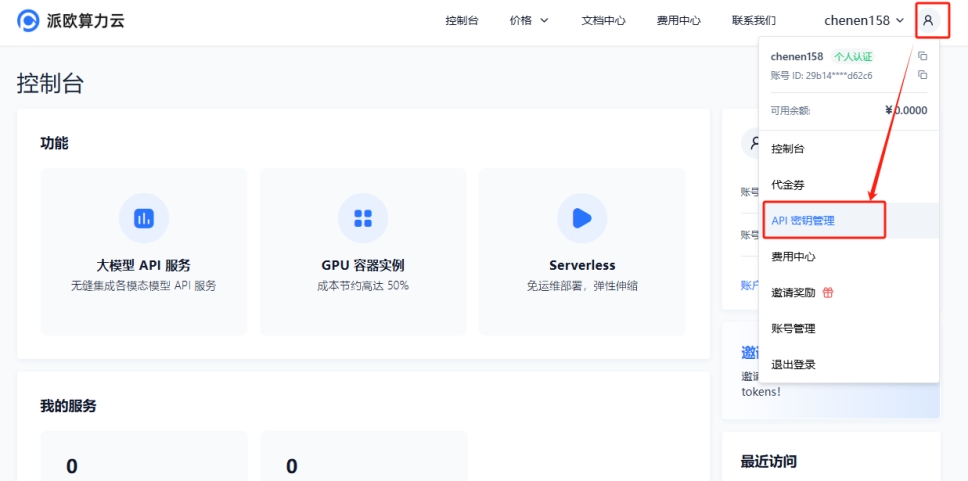
(2) Visit , click 【User Avatar】→【API Key Management】 to enter console
Click 【+ Create】 to generate a new API key. Customize a key name. Generated keys are visible only at creation – immediately copy and save them to avoid affecting future usage
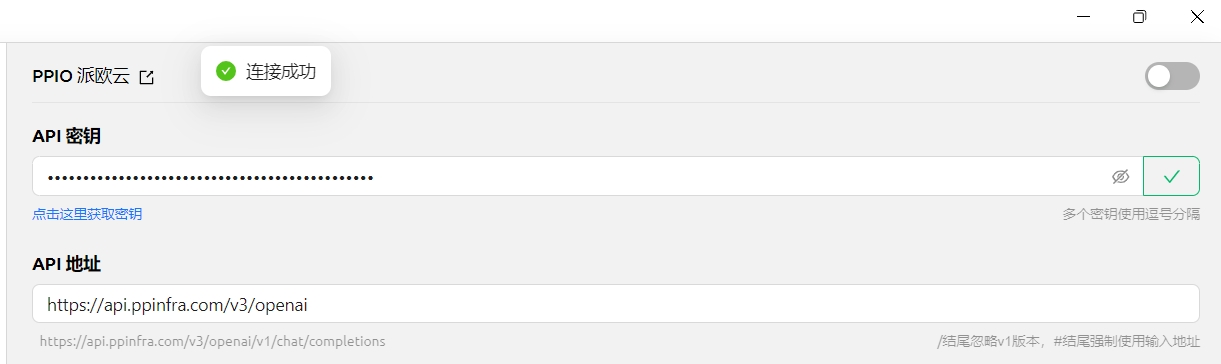
(3) In Cherry Studio settings, select 【PPIO Paiou Cloud】, enter the API key generated on the official website, then click 【Verify】
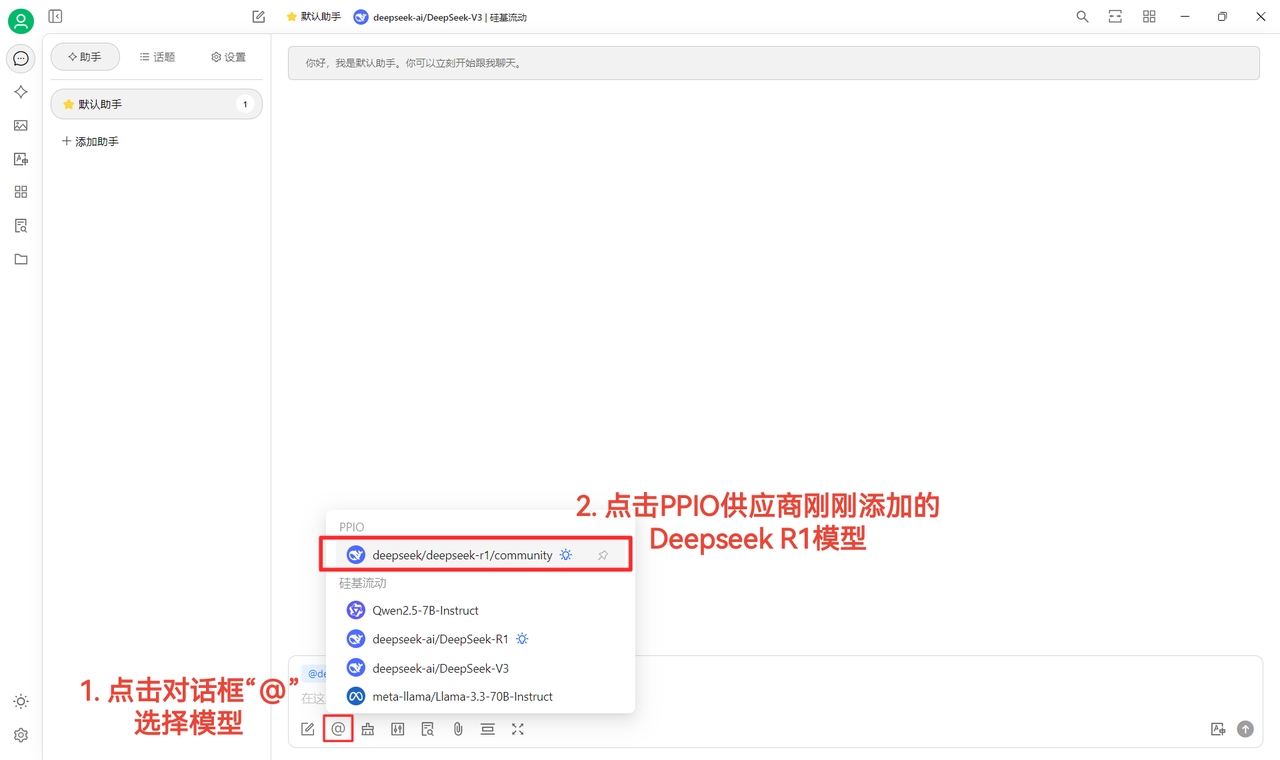
(4) Select model: using deepseek/deepseek-r1/community as example. Switch directly if needing other models.
DeepSeek R1 and V3 community versions are for trial use only. They are full-parameter models with identical stability and performance. For high-volume usage, top up and switch to non-community versions.
(1) After clicking 【Verify】 and seeing successful connection, it's ready for use
(2) Finally, click 【@】 and select the newly added DeepSeek R1 model under PPIO provider to start chatting~
【Partial material source: 】
For visual learners, we've prepared a Bilibili video tutorial. Follow step-by-step instructions to quickly master PPIO API + Cherry Studio configuration. Click the link to jump directly: →
【Video material source: sola】
This document was translated from Chinese by AI and has not yet been reviewed.
To allow every developer and user to easily experience the capabilities of cutting-edge large models, Zhipu has made the GLM-4.5-Air model freely available to Cherry Studio users. As an efficient foundational model specifically designed for agent applications, GLM-4.5-Air strikes an excellent balance between performance and cost, making it an ideal choice for building intelligent applications.
🚀 What is GLM-4.5-Air?
GLM-4.5-Air is Zhipu's latest high-performance language model, featuring an advanced Mixture-of-Experts (MoE) architecture. It significantly reduces computational resource consumption while maintaining excellent inference capabilities.
Total Parameters: 106 Billion
Active Parameters: 12 Billion
Through its streamlined design, GLM-4.5-Air achieves higher inference efficiency, making it suitable for deployment in resource-constrained environments while still capable of handling complex tasks.
📚 Unified Training Process, Solidifying Intelligent Foundations
GLM-4.5-Air shares a consistent training process with its flagship series, ensuring it possesses a solid foundation of general capabilities:
Large-scale Pre-training: Trained on up to 15 trillion tokens of general corpus to build extensive knowledge comprehension abilities;
Specialized Domain Optimization: Enhanced training on key tasks such as code generation, logical reasoning, and agent interaction;
Long Context Support: Context length extended to 128K tokens, capable of processing long documents, complex dialogues, or large code projects;
Reinforcement Learning Enhancement: RL optimization improves the model's decision-making capabilities in inference planning, tool calling, and other aspects.
This training system endows GLM-4.5-Air with excellent generalization and task adaptation capabilities.
⚙️ Core Capabilities Optimized for Agents
GLM-4.5-Air is deeply adapted for agent application scenarios, offering the following practical capabilities:
✅ Tool Calling Support: Can call external tools via standardized interfaces to automate tasks ✅ Web Browsing and Information Extraction: Can work with browser plugins to understand and interact with dynamic content ✅ Software Engineering Assistance: Supports requirements parsing, code generation, defect identification, and repair ✅ Front-end Development Support: Has a good understanding and generation capability for front-end technologies such as HTML, CSS, and JavaScript
This model can be flexibly integrated into code agent frameworks like Claude Code and Roo Code, or used as the core engine for any custom Agent.
💡 Intelligent "Thinking Mode" for Flexible Response to Various Requests
GLM-4.5-Air supports a hybrid inference mode, allowing users to control whether deep thinking is enabled via the thinking.type parameter:
``enabled`: Enables thinking, suitable for complex tasks requiring step-by-step reasoning or planning
``disabled`: Disables thinking, used for simple queries or immediate responses
Default setting is dynamic thinking mode, where the model automatically determines if deep analysis is needed
🌟 High Efficiency, Low Cost, Easier Deployment
GLM-4.5-Air achieves an excellent balance between performance and cost, making it particularly suitable for real-world business deployment:
⚡ Generation speed exceeds 100 tokens/second, offering rapid response and supporting low-latency interaction
💰 Extremely low API cost: Input only 0.8 RMB/million tokens, output 2 RMB/million tokens
🖥️ Fewer active parameters, lower computing power requirements, easy for high-concurrency operation locally or in the cloud
Truly achieving an AI service experience that is "high-performance, low-barrier."
🧠 Focus on Practical Capabilities: Intelligent Code Generation
GLM-4.5-Air performs stably in code generation, supporting:
Covering mainstream languages such as Python, JavaScript, and Java
Generating clear, maintainable code based on natural language instructions
Reducing templated output, aligning closely with real development scenario needs
Applicable to high-frequency development tasks such as rapid prototyping, automated completion, and bug fixing.
Experience GLM-4.5-Air for free now and start your agent development journey! Whether you want to build automated assistants, programming companions, or explore next-generation AI applications, GLM-4.5-Air will be your efficient and reliable AI engine.
📘 Get started now and unleash your creativity!
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio data storage follows system specifications. Data is automatically placed in the user directory at the following locations:
macOS: /Users/username/Library/Application Support/CherryStudioDev
Windows: C:\Users\username\AppData\Roaming\CherryStudio
Linux: /home/username/.config/CherryStudio
You can also view it at:
Method 1:
This can be achieved by creating a symbolic link. Exit the application, move the data to your desired location, then create a link at the original location pointing to the new path.
For detailed steps, refer to:
Method 2: Based on Electron application characteristics, modify the storage location by configuring launch parameters.
--user-data-dir Example: Cherry-Studio-*-x64-portable.exe --user-data-dir="%user_data_dir%"
Example:
init_cherry_studio.bat (encoding: ANSI)
Initial structure of user-data-dir:
This document was translated from Chinese by AI and has not yet been reviewed.
The well-known MaaS service platform "SiluFlow" provides free access to the Qwen3-8B model call service for everyone. As a cost-effective member of the Tongyi Qianwen Qwen3 series, Qwen3-8B achieves powerful capabilities in a compact size, making it an ideal choice for intelligent applications and efficient development.
🚀 What is Qwen3-8B?
Qwen3-8B is an 8-billion parameter dense model in the third-generation large model series of Tongyi Qianwen, released by Alibaba in April 2025. It adopts the Apache 2.0 open-source license and can be freely used for commercial and research scenarios.
Total Parameters: 8 billion
Architecture Type: Dense (pure dense structure)
Context Length: 128K tokens
Multilingual Support: Covers 119 languages and dialects
Despite its compact size, Qwen3-8B demonstrates stable performance in inference, code, mathematics, and Agent capabilities, comparable to larger previous-generation models, showing extremely high practicality in real-world applications.
📚 Powerful Training Foundation, Small Model with Big Wisdom
Qwen3-8B is pre-trained on approximately 36 trillion tokens of high-quality multilingual data, covering web text, technical documents, code repositories, and synthetic data from professional fields, providing extensive knowledge coverage.
The subsequent training phase introduced a four-stage reinforcement process, specifically optimizing the following capabilities:
✅ Natural language understanding and generation ✅ Mathematical reasoning and logical analysis ✅ Multilingual translation and expression ✅ Tool calling and task planning
Thanks to the comprehensive upgrade of the training system, Qwen3-8B's actual performance approaches or even surpasses Qwen2.5-14B, achieving a significant leap in parameter efficiency.
💡 Hybrid Inference Mode: Think or Respond Quickly?
Qwen3-8B supports flexible switching between "Thinking Mode" and "Non-Thinking Mode", allowing users to independently choose the response method based on task complexity.
Control modes via the following methods:
API Parameter Setting: enable_thinking=True/False
Prompt Instruction: Add /think or /no_think to the input
This design allows users to freely balance response speed and inference depth, enhancing the user experience.
⚙️ Native Agent Capability Support, Empowering Intelligent Applications
Qwen3-8B possesses excellent Agent capabilities and can be easily integrated into various automation systems:
🔹 Function Calling: Supports structured tool calling 🔹 MCP Protocol Compatibility: Natively supports the Model Context Protocol, facilitating extension of external capabilities 🔹 Multi-tool Collaboration: Can integrate plugins for search, calculators, code execution, etc.
It is recommended to use it in conjunction with the Qwen-Agent framework to quickly build intelligent assistants with memory, planning, and execution capabilities.
🌐 Extensive Language Support for Global Applications
Qwen3-8B supports 119 languages and dialects, including Chinese, English, Arabic, Spanish, Japanese, Korean, Indonesian, etc., making it suitable for international product development, cross-language customer service, multilingual content generation, and other scenarios.
Its understanding of Chinese is particularly outstanding, supporting simplified, traditional, and Cantonese expressions, making it suitable for the markets in Hong Kong, Macao, Taiwan, and overseas Chinese communities.
🧠 Strong Practical Capabilities, Wide Scenario Coverage
Qwen3-8B performs excellently in various high-frequency application scenarios:
✅ Code Generation: Supports mainstream languages such as Python, JavaScript, and Java, capable of generating runnable code based on requirements ✅ Mathematical Reasoning: Stable performance in benchmarks like GSM8K, suitable for educational applications ✅ Content Creation: Writes emails, reports, and copy with clear structure and natural language ✅ Intelligent Assistant: Can build lightweight AI assistants for personal knowledge base Q&A, schedule management, information extraction, etc.
Experience Qwen3-8B for free now through SiluFlow and start your journey with lightweight AI applications!
📘 Use now to make AI accessible!
This document was translated from Chinese by AI and has not yet been reviewed.
Ollama is an excellent open-source tool that allows you to easily run and manage various large language models (LLMs) locally. Cherry Studio now supports Ollama integration, enabling you to interact directly with locally deployed LLMs through the familiar interface without relying on cloud services!
Ollama is a tool that simplifies the deployment and use of large language models (LLMs). It has the following features:
Local Operation: Models run entirely on your local computer without requiring internet connectivity, protecting your privacy and data security.
Simple and User-Friendly: Download, run, and manage various LLMs through simple command-line instructions.
Rich Model Selection: Supports popular open-source models like Llama 2, Deepseek, Mistral, Gemma, and more.
Cross-Platform: Compatible with macOS, Windows, and Linux systems.
OpenAPI: Features OpenAI-compatible interfaces for integration with other tools.
No Cloud Service Needed: Break free from cloud API quotas and fees, and fully leverage the power of local LLMs.
Data Privacy: All your conversation data remains locally stored with no privacy concerns.
Offline Availability: Continue interacting with LLMs even without an internet connection.
Customization: Choose and configure the most suitable LLMs according to your needs.
First, you need to install and run Ollama on your computer. Follow these steps:
Download Ollama: Visit the and download the installation package for your operating system. For Linux systems, you can directly install Ollama by running:
Install Ollama: Complete the installation by following the installer instructions.
Download Models: Open a terminal (or command prompt) and use the ollama run command to download your desired model. For example, to download the Llama 2 model, run:
Ollama will automatically download and run the model.
Keep Ollama Running: Ensure Ollama remains running while using Cherry Studio to interact with its models.
Next, add Ollama as a custom AI provider in Cherry Studio:
Open Settings: Click on "Settings" (gear icon) in the left navigation bar of Cherry Studio.
Access Model Services: Select the "Model Services" tab in the settings page.
Add Provider: Click "Ollama" in the provider list.
Locate the newly added Ollama provider in the list and configure it in detail:
Enable Status:
Ensure the switch on the far right of the Ollama provider is turned on (indicating enabled status).
API Key:
Ollama typically requires no API key. Leave this field blank or enter any content.
API Address:
Enter Ollama's local API address. Normally, this is:
Adjust if you've modified the default port.
Keep-Alive Time: Sets the session retention time in minutes. Cherry Studio will automatically disconnect from Ollama if no new interactions occur within this period to free up resources.
Model Management:
Click "+ Add" to manually add the names of models you've downloaded in Ollama.
For example, if you downloaded llama3.2 via ollama run llama3.2, enter llama3.2 here.
Click "Manage" to edit or delete added models.
After completing the above configurations, select Ollama as the provider and choose your downloaded model in Cherry Studio's chat interface to start conversations with local LLMs!
First-Time Model Execution: Ollama needs to download model files during initial runs, which may take considerable time. Please be patient.
View Available Models: Run ollama list in the terminal to see your downloaded Ollama models.
Hardware Requirements: Running large language models requires substantial computing resources (CPU, RAM, GPU). Ensure your computer meets the model's requirements.
Ollama Documentation: Click the View Ollama Documentation and Models link in the configuration page to quickly access Ollama's official documentation.
Thinking Mode
Complex reasoning, math problems, planning tasks
- Solve geometric problems - Write complete project architecture
Non-Thinking Mode
Quick Q&A, translation, summarization
- Query weather - Chinese-English translation


curl -fsSL https://ollama.com/install.sh | shollama run llama3.2http://localhost:11434/


































This document was translated from Chinese by AI and has not yet been reviewed.
Tokens are the basic units of text processed by AI models, understood as the smallest units of model "thinking". They are not entirely equivalent to the characters or words as we understand them, but rather a special way the model segments text itself.
1. Chinese Tokenization
A Chinese character is typically encoded as 1-2 tokens
For example: "你好" ≈ 2-4 tokens
2. English Tokenization
Common words are typically 1 token
Longer or uncommon words are decomposed into multiple tokens
For example:
"hello" = 1 token
"indescribable" = 4 tokens
3. Special Characters
Spaces, punctuation, etc. also consume tokens
Line breaks are typically 1 token
A Tokenizer is the tool that converts text into tokens for AI models. It determines how to split input text into the smallest units that models can understand.
1. Different Training Data
Different corpora lead to different optimization directions
Variations in multilingual support levels
Specialized optimization for specific domains (medical, legal, etc.)
2. Different Tokenization Algorithms
BPE (Byte Pair Encoding) - OpenAI GPT series
WordPiece - Google BERT
SentencePiece - Suitable for multilingual scenarios
3. Different Optimization Goals
Some focus on compression efficiency
Others on semantic preservation
Others on processing speed
The same text may have different token counts across models:
Input: "Hello, world!"
GPT-3: 4 tokens
BERT: 3 tokens
Claude: 3 tokensBasic Concept: An embedding model is a technique that converts high-dimensional discrete data (text, images, etc.) into low-dimensional continuous vectors. This transformation allows machines to better understand and process complex data. Imagine it as simplifying a complex puzzle into a simple coordinate point that still retains the puzzle's key features. In the large model ecosystem, it serves as a "translator," converting human-understandable information into AI-computable numerical forms.
Working Principle: Taking natural language processing as an example, an embedding model maps words to specific positions in vector space. In this space:
Vectors for "King" and "Queen" will be very close
Pet-related words like "cat" and "dog" will cluster together
Semantically unrelated words like "car" and "bread" will be distant
Main Application Scenarios:
Text analysis: Document classification, sentiment analysis
Recommendation systems: Personalized content recommendations
Image processing: Similar image retrieval
Search engines: Semantic search optimization
Core Advantages:
Dimensionality reduction: Simplifies complex data into manageable vector forms
Semantic preservation: Retains key semantic information from original data
Computational efficiency: Significantly improves training and inference efficiency
Technical Value: Embedding models are fundamental components of modern AI systems, providing high-quality data representations for machine learning tasks, and are key technologies driving advances in natural language processing, computer vision, and other fields.
Basic Workflow:
Knowledge Base Preprocessing Stage
Split documents into appropriately sized chunks
Use embedding models to convert each chunk into vectors
Store vectors and original text in a vector database
Query Processing Stage
Convert user questions into vectors
Retrieve similar content from the vector database
Provide retrieved context to the LLM
MCP is an open-source protocol designed to provide context information to large language models (LLMs) in a standardized way.
Analogy: Think of MCP as a "USB drive" for AI. Just as USB drives can store various files and be plugged into computers for immediate use, MCP servers can "plug in" various context-providing "plugins". LLMs can request these plugins from MCP servers as needed to obtain richer context information and enhance their capabilities.
Comparison with Function Tools: Traditional function tools provide external capabilities to LLMs, but MCP is a higher-level abstraction. Function tools focus on specific tasks, while MCP provides a more universal, modular context acquisition mechanism.
Standardization: Provides unified interfaces and data formats for seamless collaboration between LLMs and context providers.
Modularity: Allows developers to decompose context information into independent modules (plugins) for easy management and reuse.
Flexibility: Enables LLMs to dynamically select required context plugins for smarter, more personalized interactions.
Extensibility: Supports adding new types of context plugins in the future, providing unlimited possibilities for LLM capability expansion.
This document was translated from Chinese by AI and has not yet been reviewed.
Note: Gemini image generation must be used in the chat interface because Gemini performs multi-modal interactive image generation and does not support parameter adjustment.
Simple Tasks (Thinking recommended to be disabled)
- Query "When was Zhipu AI founded?" - Translate "I love you" into Chinese
Medium Tasks (Thinking recommended to be enabled)
- Compare the pros and cons of taking a plane vs. high-speed rail from Beijing to Shanghai - Explain why Jupiter has many moons
Complex Tasks (Thinking strongly recommended to be enabled)
- Explain how experts collaborate in MoE models - Analyze whether to buy ETFs based on market information
PS D:\CherryStudio> dir
目录: D:\CherryStudio
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:05 user-data-dir
-a---- 2025/4/14 23:05 94987175 Cherry-Studio-1.2.4-x64-portable.exe
-a---- 2025/4/18 14:05 701 init_cherry_studio.bat@title CherryStudio Initialization
@echo off
set current_path_dir=%~dp0
@echo Current path: %current_path_dir%
set user_data_dir=%current_path_dir%user-data-dir
@echo CherryStudio data path: %user_data_dir%
@echo Searching for Cherry-Studio-*-portable.exe in current directory
setlocal enabledelayedexpansion
for /f "delims=" %%F in ('dir /b /a-d "Cherry-Studio-*-portable*.exe" 2^>nul') do ( # Compatible with GitHub and official releases. Modify for other versions
set "target_file=!cd!\%%F"
goto :break
)
:break
if defined target_file (
echo Found file: %target_file%
) else (
echo No matching files found. Exiting script
pause
exit
)
@echo Press any key to continue...
pause
@echo Launching CherryStudio
start %target_file% --user-data-dir="%user_data_dir%"
@echo Operation completed
@echo on
exitPS D:\CherryStudio> dir .\user-data-dir\
目录: D:\CherryStudio\user-data-dir
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/4/18 14:29 blob_storage
d----- 2025/4/18 14:07 Cache
d----- 2025/4/18 14:07 Code Cache
d----- 2025/4/18 14:07 Data
d----- 2025/4/18 14:07 DawnGraphiteCache
d----- 2025/4/18 14:07 DawnWebGPUCache
d----- 2025/4/18 14:07 Dictionaries
d----- 2025/4/18 14:07 GPUCache
d----- 2025/4/18 14:07 IndexedDB
d----- 2025/4/18 14:07 Local Storage
d----- 2025/4/18 14:07 logs
d----- 2025/4/18 14:30 Network
d----- 2025/4/18 14:07 Partitions
d----- 2025/4/18 14:29 Session Storage
d----- 2025/4/18 14:07 Shared Dictionary
d----- 2025/4/18 14:07 WebStorage
-a---- 2025/4/18 14:07 36 .updaterId
-a---- 2025/4/18 14:29 20 config.json
-a---- 2025/4/18 14:07 434 Local State
-a---- 2025/4/18 14:29 57 Preferences
-a---- 2025/4/18 14:09 4096 SharedStorage
-a---- 2025/4/18 14:30 140 window-state.json数据设置→Obsidian配置
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio supports integration with Obsidian, allowing you to export complete conversations or individual messages to your Obsidian vault.
This process does not require installing additional Obsidian plugins. However, since the mechanism used by Cherry Studio to import to Obsidian is similar to the Obsidian Web Clipper, it is recommended to upgrade Obsidian to the latest version (the current version should be at least greater than 1.7.2) to prevent import failure when conversations are too long.
Open Cherry Studio's Settings → Data Settings → Obsidian Configuration menu. The drop-down box will automatically display the names of Obsidian vaults that have been opened on this machine. Select your target Obsidian vault:
Exporting a Complete Conversation
Return to Cherry Studio's conversation interface, right-click on the conversation, select Export, and click Export to Obsidian:
A window will pop up allowing you to configure the Properties of the note exported to Obsidian, its folder location, and the processing method:
Vault: Click the drop-down menu to select another Obsidian vault
Path: Click the drop-down menu to select the folder for storing the exported conversation note
As Obsidian note properties:
Tags
Created time
Source
Three available processing methods:
New (overwrite if exists): Create a new conversation note in the folder specified at Path. If a note with the same name exists, it will overwrite the old note
Prepend: When a note with the same name already exists, export the selected conversation content and add it to the beginning of that note
Append: When a note with the same name already exists, export the selected conversation content and add it to the end of that note
After selecting all options, click OK to export the complete conversation to the specified folder in the corresponding Obsidian vault.
Exporting a Single Message
To export a single message, click the three-dash menu below the message, select Export, and click Export to Obsidian:
The same window as when exporting a complete conversation will appear, requiring you to configure the note properties and processing method. Complete the configuration following the same steps as in Exporting a Complete Conversation.
🎉 Congratulations! You've completed all configurations for Cherry Studio's integration with Obsidian and finished the entire export process. Enjoy yourselves!
Open your Obsidian vault and create a folder to store exported conversations (shown as "Cherry Studio" folder in the example):
Note the text highlighted in the bottom-left corner - this is your vault name.
In Cherry Studio's Settings → Data Settings → Obsidian Configuration menu, enter the vault name and folder name obtained in Step 1:
Global Tags is optional and can be used to set tags for all exported conversations in Obsidian. Fill in as needed.
Exporting a Complete Conversation
Return to Cherry Studio's conversation interface, right-click on the conversation, select Export, and click Export to Obsidian:
A window will pop up allowing you to adjust the Properties of the note exported to Obsidian and select a processing method. Three processing methods are available:
New (overwrite if exists): Create a new conversation note in the folder specified in Step 2. If a note with the same name exists, it will overwrite the old note
Prepend: When a note with the same name already exists, export the selected conversation content and add it to the beginning of that note
Append: When a note with the same name already exists, export the selected conversation content and add it to the end of that note
Exporting a Single Message
To export a single message, click the three-dash menu below the message, select Export, and click Export to Obsidian:
The same window as when exporting a complete conversation will appear. Complete the configuration by following the same steps in Exporting a Complete Conversation.
🎉 Congratulations! You've completed all configurations for Cherry Studio's integration with Obsidian and finished the entire export process. Enjoy yourselves!
This document was translated from Chinese by AI and has not yet been reviewed.
In version 0.9.1, Cherry Studio introduces the long-awaited knowledge base feature. Below is the step-by-step guide to using Cherry Studio's knowledge base.
Find models in the Model Management Service. You can quickly filter by clicking "Embedding Models".
Locate the required model and add it to My Models.
Access: Click the Knowledge Base icon in Cherry Studio's left toolbar to enter the management page.
Add Knowledge Base: Click "Add" to start creating.
Naming: Enter a name for the knowledge base and add an embedding model (e.g., bge-m3) to complete creation.
Add Files: Click the "Add Files" button to open file selection.
Select Files: Choose supported file formats (pdf, docx, pptx, xlsx, txt, md, mdx, etc.) and open.
Vectorization: The system automatically vectorizes files. A green checkmark (✓) indicates completion.
Cherry Studio supports adding data through:
Folder Directories: Entire directories where supported format files are auto-vectorized.
URL Links: e.g., https://docs.siliconflow.cn/introduction
Sitemaps: XML format sitemaps, e.g., https://docs.siliconflow.cn/sitemap.xml
Plain Text Notes: Custom content input.
After vectorization:
Click "Search Knowledge Base" at bottom of page.
Enter query content.
View search results.
Matching scores are displayed per result.
Create new topic > Click "Knowledge Base" in toolbar > Select target knowledge base.
Enter question > Model generates answer using retrieved knowledge.
Data sources appear below answer for quick reference.
Tools
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio v1.5.7 introduces a simple to operate, powerful Code Agent feature, which can directly launch and manage various AI programming agents. This tutorial will guide you through the complete setup and launch process.
First, please ensure your Cherry Studio is upgraded to v1.5.7 or higher. You can go to or the official website to download the latest version.
To facilitate the use of the top tab feature, we recommend adjusting the navigation bar to the top.
Operation path: Settings -> Display Settings -> Navigation Bar Settings
Set the "Navigation Bar Position" option to Top.
Click the "+" icon at the top of the interface to create a new blank tab.
In the newly created tab, click the Code (or </>) icon to enter the Code Agent configuration interface.
Based on your needs and API Key, select a Code Agent tool to use. Currently, the following are supported:
Claude Code
Gemini CLI
Qwen Code
OpenAI Codex
In the model dropdown list, select a model compatible with your chosen CLI tool. (For detailed model compatibility instructions, please refer to the 'Important Notes' below)
Click the "Select Directory" button to specify a working directory for the Agent. The Agent will have access to all files and subdirectories within this directory, allowing it to understand the project context, read files, and execute code.
Automatic Configuration: Your selections in step 6 (model) and step 7 (working directory) will automatically generate corresponding environment variables.
Custom Addition: If your Agent or project requires other specific environment variables (e.g., PROXY_URL, etc.), you can add them custom in this area.
Built-in Executables: Cherry Studio has integrated the executables for all the above Code Agents for you. In most cases, you can use them directly without an internet connection.
Automatic Updates: If you want the Agent to always stay updated, you can check the Check for updates and install the latest version option. When checked, the program will check for updates online and update the Agent tool every time it starts.
After all configurations are complete, click the Launch button. Cherry Studio will automatically invoke your system's built-in Terminal tool, load all environment variables into it, and then run your selected Code Agent. You can now interact with the AI Agent in the popped-up terminal window.
Model Compatibility Instructions:
Claude Code: Requires selecting models that support the Anthropic API Endpoint format. Currently supported official models include:
Claude series models
DeepSeek V3.1 (Official API platform)
Kimi K2 (Official API platform)
Zhipu GLM 4.5 (Official API platform)
Note: Many third-party service providers (such as One API, New API, etc.) currently offer API interfaces for DeepSeek, Kimi, and GLM that mostly only support the OpenAI Chat Completions format. These may not be directly compatible with Claude Code and require waiting for service providers to gradually adapt.
Gemini CLI: Requires selecting Google's Gemini series models.
Qwen Code: Supports models with OpenAI Chat Completions API format, and it is highly recommended to use the Qwen3 Coder series models for the best code generation results.
OpenAI Codex: Supports GPT series models (e.g., gpt-4o, gpt-5, etc.).
Dependencies and Environment Conflicts:
Cherry Studio internally integrates a standalone Node.js runtime environment, Code Agent executables, and environment variable configurations, aiming to provide a ready-to-use, clean environment.
If you encounter dependency conflicts or unusual errors when launching the Agent, consider temporarily uninstalling or disabling related dependencies already installed on your system (such as globally installed Node.js or specific toolchains) to eliminate conflicts.
API Token Consumption Warning:
Code Agent consumes a very large amount of API Tokens. When handling complex tasks, the Agent may generate a large number of requests for thinking, planning, and generating code, leading to rapid Token consumption.
Please be sure to act within your means based on your API quota and budget, and closely monitor Token usage to prevent budget overruns.
We hope this tutorial helps you quickly get started with Cherry Studio's powerful Code Agent feature!
This document was translated from Chinese by AI and has not yet been reviewed.
4xx (Client Error Status Codes): Generally indicate a request syntax error, authentication failure, or authorization failure that prevents the request from being completed.
5xx (Server Error Status Codes): Generally indicate a server-side error, such as a server crash or request processing timeout.
Here's a self-correction/thought process I'll use:
Initial Scan: Read through the entire Chinese document quickly to understand its context and identify major sections (headings, tables, lists, code blocks, hint blocks).
Heading Translation:
# 项目简介 -> # Project Introduction (already done in previous turn, but good to keep in mind)
# 常见问题 -> # Frequently Asked Questions
## 常见错误代码 -> ## Common Error Codes
## 控制台报错查看方法 -> ## How to Check Console Errors
## 公式没被渲染/公式渲染错误 -> ## Formulas Not Rendered / Formula Rendering Errors
## 无法创建知识库/提示获取嵌入维度失败 -> ## Failed to Create Knowledge Base / Prompt to Get Embedding Dimensions Failed
## 模型不能识图/无法上传或选择图片 -> ## Model Cannot Recognize Images / Unable to Upload or Select Images
Hint Blocks ({% hint style="..." %}):
Preserve the {% hint ... %} tags.
Translate the content within the tags.
Example: 此文档由中文AI翻译而来,目前暂未经过审核。我会尽量逐一查看文档,检查翻译是否合理。 -> This document is translated from Chinese by AI and has not yet been reviewed. I will try to check the document one by one to ensure the translation is reasonable.
Example: 当前活动窗口必须为 Cherry Studio 的客户端窗口才能调出控制台; 需要先打开控制台,再点击测试或者发起对话等请求才能收集到请求信息。 -> The active window must be the Cherry Studio client window to bring up the console; You need to open the console first, and then click test or initiate a conversation and other requests to collect request information.
Example: 不同场景下Name(上图②处)栏里的名称会有所区别 -> The name in the Name column (② in the image above) will vary depending on the scenario. (And translate the list items below it.)4. Tables:
Translate 错误码, 可能的情况, 解决方法 headers.
Translate all content within table cells.
Crucial: Pay attention to [控制台](questions.md#kong-zhi-tai-bao-cuo-cha-kan-fang-fa) and <a href="questions.md#kong-zhi-tai-bao-cuo-cha-kan-fang-fa">控制台</a>. These are links and should not have their href or questions.md#... part translated. Only the visible text 控制台 should be translated. The <mark> tags also need to be preserved.
【常见情况1】 -> [Common Case 1] etc.
Lists: Translate bullet points.
Code Blocks/Inline Code:
<code> or \backticks`: Preserve as-is. Do *not* translate Network, ×, completions, generations, Response, embeddings, formula, KateX`.
Ctrl, Shift, I, Command, Option: Preserve these as they are keyboard keys.
Links:
[官方交流群](https://t.me/CherryStudioAI): Translate 官方交流群 to Official Community Group, but preserve the URL https://t.me/CherryStudioAI.
[对话界面](cherrystudio/preview/chat.md): (Not in this document, but a general rule) Translate 对话界面 but preserve cherrystudio/preview/chat.md.
Images: Preserve . The alt text should be empty or translated if it contains user-facing text, but in this case, alt="" is empty. The src path must be preserved. figcaption content should be translated if present, here it's empty.
General Text: Translate all other prose fluently and accurately.
GitHub Terminology: (Not much in this specific document, but relevant) If terms like "pull request," "fork," "commit," "repository" appear, leave them in English.
URLs/File Paths/Version Numbers: Preserve exactly. (e.g., questions.md#kong-zhi-tai-bao-cuo-cha-kan-fang-fa, https://t.me/CherryStudioAI)
Markdown Structure: Ensure headings, bold, italics, lists, tables, etc., are perfectly maintained.
With this systematic approach, I will now proceed with the translation.# Frequently Asked Questions
4xx (Client Error Status Codes): Generally indicate a request syntax error, authentication failure, or authorization failure that prevents the request from being completed.
5xx (Server Error Status Codes): Generally indicate a server-side error, such as a server crash or request processing timeout.
| Error Code | Possible Situation | 400 | Request body format error, etc. |
Check the error content returned in the conversation or check the error content in the and follow the prompts.
| | 401 | Authentication failed: model not supported or service provider account banned, etc. | Contact or check the account status of the corresponding service provider.
360gpt-pro
8k
-
Not Supported
Dialogue
360AI_360gpt
360's flagship trillion-parameter large model, widely applicable to complex tasks across various domains.
glm-4v-flash
2k
1k
Not Supported
Dialogue, Visual Understanding
Zhipu_glm
Free model with robust image comprehension capabilities.
400
Request body format error, etc.
Check the error content returned in the conversation or check the error content in the console and follow the prompts.
401
Authentication failed: model not supported or service provider account banned, etc.
Contact or check the account status of the corresponding service provider. Okay, I will translate the document into English while strictly adhering to the specified rules. My main focus will be on translating user-facing text and preserving all Markdown and structural elements precisely. I will pay special attention to links, image paths, code blocks, hint blocks, and GitHub terminology.





































This document was translated from Chinese by AI and has not yet been reviewed.
By using or distributing any portion or element of Cherry Studio materials, you are deemed to have acknowledged and accepted the terms of this Agreement, which shall take effect immediately.
This Cherry Studio License Agreement (hereinafter referred to as the "Agreement") shall mean the terms and conditions governing the use, reproduction, distribution, and modification of the Materials as defined herein.
"We" (or "Our") shall mean Shanghai WisdomAI Technology Co., Ltd.
"You" (or "Your") shall mean a natural person or legal entity exercising rights granted under this Agreement and/or using the Materials for any purpose and in any field of use.
"Third Party" shall mean an individual or legal entity not under common control with Us or You.
"Cherry Studio" shall mean this software suite, including but not limited to [e.g., core libraries, editor, plugins, sample projects], as well as source code, documentation, sample code, and other elements of the foregoing distributed by Us. (Please elaborate based on Cherry Studio’s actual composition.)
"Materials" shall collectively refer to Cherry Studio and documentation (and any portions thereof), proprietary to Shanghai WisdomAI Technology Co., Ltd., and provided under this Agreement.
"Source" Form shall mean the preferred form for making modifications, including but not limited to source code, documentation source files, and configuration files.
"Object" Form shall mean any form resulting from mechanical transformation or translation of a Source Form, including but not limited to compiled object code, generated documentation, and forms converted into other media types.
"Commercial Use" shall mean use for the purpose of direct or indirect commercial benefit or commercial advantage, including but not limited to sale, licensing, subscription, advertising, marketing, training, consulting services, etc.
"Modification" shall mean any change, adaptation, derivation, or secondary development to the Source Form of the Materials, including but not limited to modifying application names, logos, code, features, interfaces, etc.
Free Commercial Use (Limited to Unmodified Code): Subject to the terms and conditions of this Agreement, We hereby grant You a non-exclusive, worldwide, non-transferable, royalty-free license to use, reproduce, distribute, copy, and disseminate unmodified Materials, including for Commercial Use, under the intellectual property or other rights We own or control embodied in the Materials.
Commercial Authorization (When Necessary): Under the conditions described in Section III ("Commercial Authorization"), You must obtain explicit written commercial authorization from Us to exercise rights under this Agreement.
In any of the following circumstances, You must contact Us and obtain explicit written commercial authorization before continuing to use Cherry Studio Materials:
Modification and Derivation: You modify Cherry Studio Materials or develop derivatives based on them (including but not limited to modifying application names, logos, code, features, interfaces, etc.).
Enterprise Services: You provide services based on Cherry Studio within Your enterprise or for enterprise clients, and such services support 10 or more cumulative users.
Hardware Bundling: You pre-install or integrate Cherry Studio into hardware devices or products for bundled sales.
Government or Educational Institutional Procurement: Your use case involves large-scale procurement projects by government or educational institutions, especially those involving sensitive requirements such as security or data privacy.
Public Cloud Services: Providing public-facing cloud services based on Cherry Studio.
You may distribute copies of unmodified Materials or make them available as part of a product or service containing unmodified Materials, distributed in Source or Object Form, provided You satisfy the following conditions:
You must provide a copy of this Agreement to any other recipient of the Materials;
You must retain the following attribution notice in all copies of the Materials You distribute, placing it within a "NOTICE" or similar text file distributed as part of such copies:
"Cherry Studio is licensed under the Cherry Studio LICENSE AGREEMENT, Copyright (c) Shanghai WisdomAI Technology Co., Ltd. All Rights Reserved."
Materials may be subject to export controls or restrictions. You shall comply with applicable laws and regulations when using the Materials.
If You use Materials or any output thereof to create, train, fine-tune, or improve software or models that will be distributed or provided, We encourage You to prominently mark "Built with Cherry Studio" or "Powered by Cherry Studio" in relevant product documentation.
We retain ownership of all intellectual property rights to the Materials and derivative works made by or for Us. Subject to compliance with the terms and conditions of this Agreement, intellectual property rights in modifications and derivative works of the Materials created by You shall be governed by the specific commercial authorization agreement. Without obtaining commercial authorization, You do not own such modifications or derivatives, and all intellectual property rights therein remain vested in Us.
No trademark license is granted for the use of Our trade names, trademarks, service marks, or product names except as necessary to fulfill notice obligations under this Agreement or for reasonable and customary use in describing and redistributing the Materials.
If You initiate litigation or other legal proceedings (including counterclaims in litigation) against Us or any entity alleging that the Materials, any output thereof, or any portion thereof infringes any intellectual property or other rights owned or licensable by You, all licenses granted to You under this Agreement shall terminate as of the commencement or filing date of such litigation or proceedings.
We have no obligation to support, update, provide training for, or develop any further versions of Cherry Studio Materials, nor to grant any related licenses.
THE MATERIALS ARE PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING WARRANTIES OF MERCHANTABILITY, NON-INFRINGEMENT, OR FITNESS FOR A PARTICULAR PURPOSE. WE MAKE NO WARRANTIES AND ASSUME NO LIABILITY REGARDING THE SECURITY OR STABILITY OF THE MATERIALS OR ANY OUTPUT THEREOF.
IN NO EVENT SHALL WE BE LIABLE TO YOU FOR ANY DAMAGES ARISING FROM YOUR USE OR INABILITY TO USE THE MATERIALS OR ANY OUTPUT THEREOF, INCLUDING BUT NOT LIMITED TO ANY DIRECT, INDIRECT, SPECIAL, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED.
You shall defend, indemnify, and hold Us harmless from any claims by third parties arising from or related to Your use or distribution of the Materials.
The term of this Agreement shall begin upon Your acceptance hereof or access to the Materials and shall continue until terminated in accordance with these terms and conditions.
We may terminate this Agreement if You breach any term or condition herein. Upon termination, You must cease all use of the Materials. Sections VII, IX, and "II. Contributor Agreement" shall survive termination.
This Agreement and any disputes arising out of or in connection herewith shall be governed by the laws of China.
The People's Court of Shanghai shall have exclusive jurisdiction over any disputes arising from this Agreement.
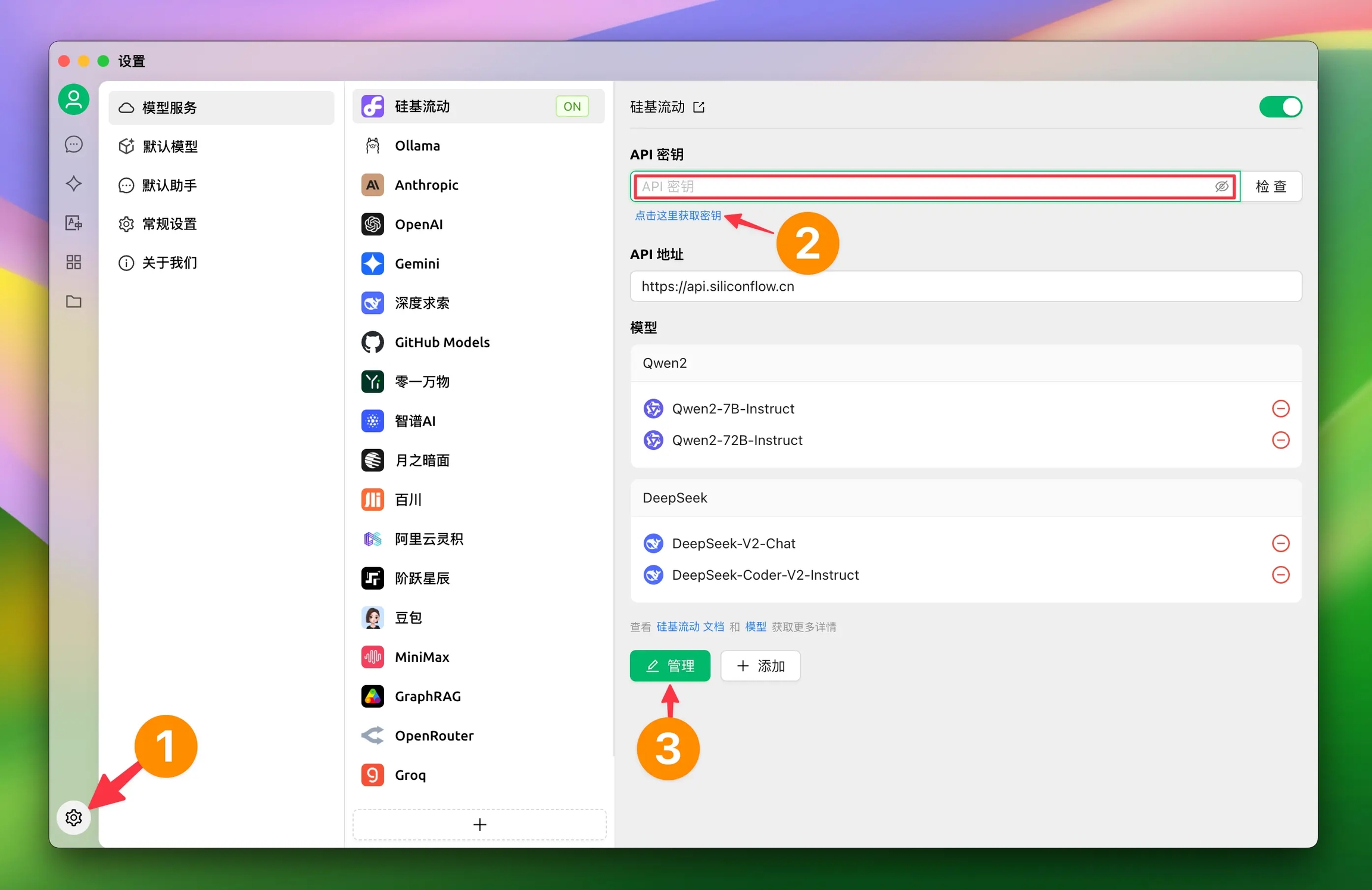
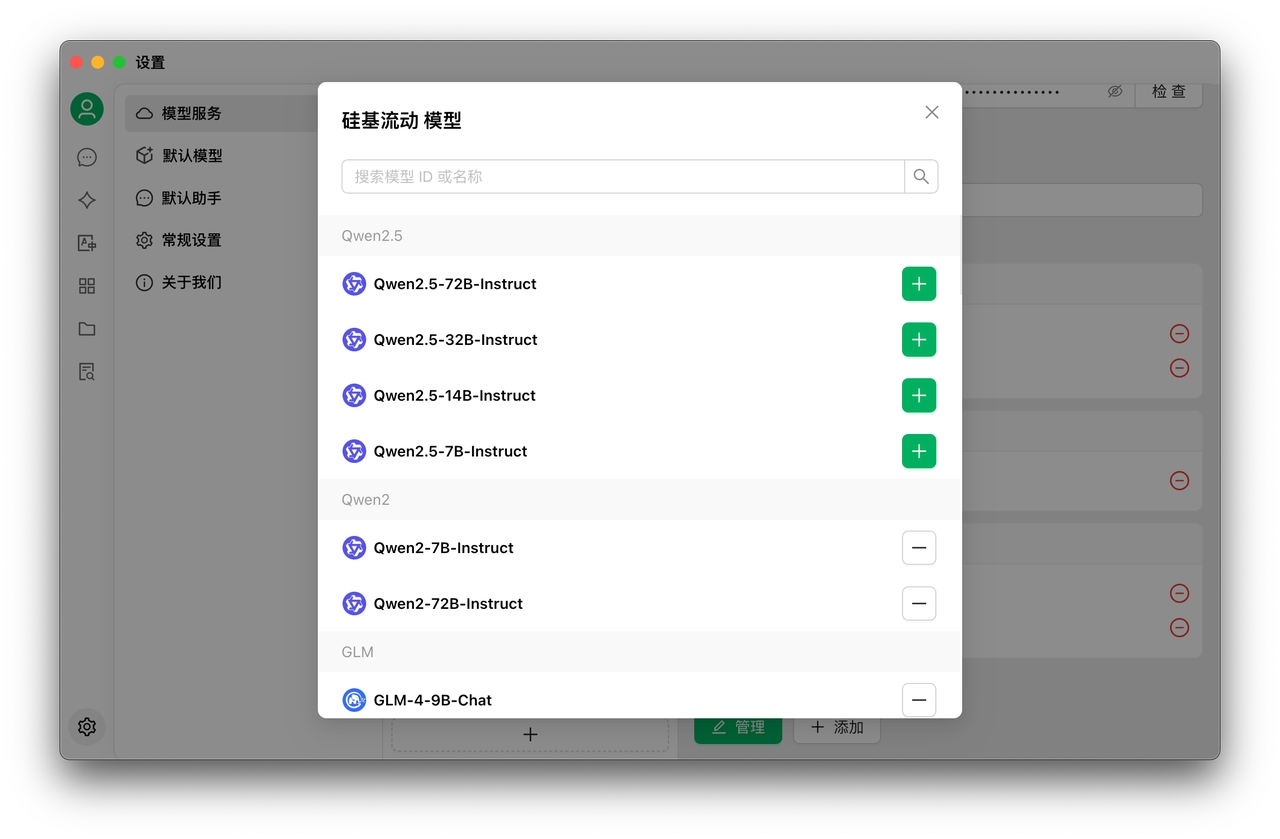
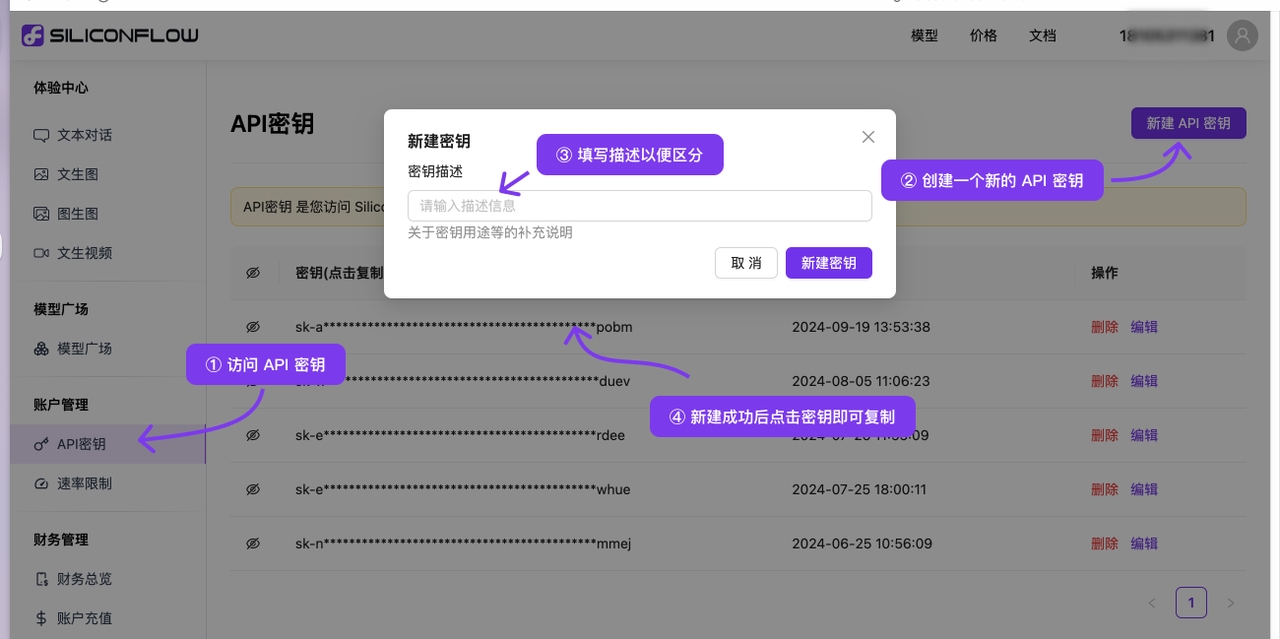

This document was translated from Chinese by AI and has not yet been reviewed.
Official Model Information Reference
Doubao-embedding
4095
Doubao-embedding-vision
8191
Doubao-embedding-large
4095
Official Model Information Reference
text-embedding-v3
8192
text-embedding-v2
2048
text-embedding-v1
2048
text-embedding-async-v2
2048
text-embedding-async-v1
2048
Official Model Information Reference
text-embedding-3-small
8191
text-embedding-3-large
8191
text-embedding-ada-002
8191
Official Model Information Reference
Embedding-V1
384
tao-8k
8192
Official Model Information Reference
embedding-2
1024
embedding-3
2048
Official Model Information Reference
hunyuan-embedding
1024
Official Model Information Reference
Baichuan-Text-Embedding
512
Official Model Information Reference
M2-BERT-80M-2K-Retrieval
2048
M2-BERT-80M-8K-Retrieval
8192
M2-BERT-80M-32K-Retrieval
32768
UAE-Large-v1
512
BGE-Large-EN-v1.5
512
BGE-Base-EN-v1.5
512
Official Model Information Reference
jina-embedding-b-en-v1
512
jina-embeddings-v2-base-en
8191
jina-embeddings-v2-base-zh
8191
jina-embeddings-v2-base-de
8191
jina-embeddings-v2-base-code
8191
jina-embeddings-v2-base-es
8191
jina-colbert-v1-en
8191
jina-reranker-v1-base-en
8191
jina-reranker-v1-turbo-en
8191
jina-reranker-v1-tiny-en
8191
jina-clip-v1
8191
jina-reranker-v2-base-multilingual
8191
reader-lm-1.5b
256000
reader-lm-0.5b
256000
jina-colbert-v2
8191
jina-embeddings-v3
8191
Official Model Information Reference
BAAI/bge-m3
8191
netease-youdao/bce-embedding-base_v1
512
BAAI/bge-large-zh-v1.5
512
BAAI/bge-large-en-v1.5
512
Pro/BAAI/bge-m3
8191
Official Model Information Reference
text-embedding-004
2048
Official Model Information Reference
nomic-embed-text-v1
8192
nomic-embed-text-v1.5
8192
gte-multilingual-base
8192
Official Model Information Reference
embedding-query
4000
embedding-passage
4000
Official Model Information Reference
embed-english-v3.0
512
embed-english-light-v3.0
512
embed-multilingual-v3.0
512
embed-multilingual-light-v3.0
512
embed-english-v2.0
512
embed-english-light-v2.0
512
embed-multilingual-v2.0
256





This document was translated from Chinese by AI and has not yet been reviewed.
An Assistant allows you to personalize the selected model with settings such as prompt presets and parameter presets, making the model work more in line with your expectations.
The System Default Assistant provides a general parameter preset (no prompt). You can use it directly or find the preset you need on the Agents Page.
An Assistant is the parent set of Topics. Multiple topics (i.e., conversations) can be created under a single assistant. All Topics share the Assistant's parameter settings and prompt presets, among other model settings.
New Topic creates a new topic within the current assistant.
Upload Image or Document requires model support for image uploads. Uploading documents will automatically parse them into text to be provided as context to the model.
Web Search requires configuring web search related information in the settings. Search results are returned to the large model as context. For details, see Web Search Mode.
Knowledge Base enables the knowledge base feature. For details, see Knowledge Base Tutorial.
MCP Server enables the MCP server feature. For details, see MCP Usage Tutorial.
Generate Image is not displayed by default. For models that support image generation (e.g., Gemini), it needs to be manually enabled before images can be generated.
Select Model switches to the specified model for subsequent conversations while preserving the context.
Quick Phrases requires pre-setting common phrases in the settings to be called here, allowing direct input and supporting variables.
Clear Messages deletes all content under this topic.
Expand makes the chatbox larger for entering longer texts.
Clear Context truncates the context available to the model without deleting content, meaning the model will "forget" previous conversation content.
Estimated Token Count displays the estimated token count. The four values represent Current Context Count, Maximum Context Count (∞ indicates unlimited context), Current Input Box Message Character Count, and Estimated Token Count.
Translate translates the content in the current input box into English.
Model settings are synchronized with the Model Settings parameters in the assistant settings. For details, see Assistant Settings.
Message Separator:Uses a separator to divide the message body from the action bar.
Use Serif Font:Font style toggle. You can now also change fonts via custom CSS.
Display Line Numbers for Code:Displays line numbers for code blocks when the model outputs code snippets.
Collapsible Code Blocks:When enabled, code blocks will automatically collapse if the code snippet is long.
Code Block Word Wrap:When enabled, single lines of code within a code snippet will automatically wrap if they are too long (exceed the window).
Auto-collapse Thinking Content:When enabled, models that support thinking will automatically collapse the thinking process after completion.
Message Style:Allows switching the conversation interface to bubble style or list style.
Code Style:Allows switching the display style of code snippets.
Mathematical Formula Engine:KaTeX renders faster because it is specifically designed for performance optimization.
MathJax renders slower but is more comprehensive, supporting more mathematical symbols and commands.
Message Font Size:Adjusts the font size of the conversation interface.
Display Estimated Token Count:Displays the estimated token count consumed by the input text in the input box (not the actual context token consumption, for reference only).
Paste Long Text as File:When copying and pasting a long block of text from elsewhere into the input box, it will automatically display as a file, reducing interference during subsequent input.
Markdown Render Input Messages:When disabled, only model replies are rendered, not sent messages.
Triple Space for Translation:After entering a message in the conversation interface input box, pressing the spacebar three times consecutively will translate the input content into English.
Note: This operation will overwrite the original text.
Target Language:Sets the target language for the input box translation button and the triple space translation feature.
In the assistant interface, select the assistant name you want to set → select the corresponding setting in the right-click menu.
Name:Customizable assistant name for easy identification.
Prompt:The prompt itself. You can refer to the prompt writing style on the agent page to edit the content.
Default Model:You can fix a default model for this assistant. When adding from the agent page or copying an assistant, the initial model will be this model. If this item is not set, the initial model will be the global initial model (i.e., Default Assistant Model).
Auto Reset Model:When enabled - if you switch to another model during use in this topic, creating a new topic will reset the new topic's model to the assistant's default model. When this item is disabled, the model for a new topic will follow the model used in the previous topic.
For example, if the assistant's default model is gpt-3.5-turbo, and I create Topic 1 under this assistant, then switch to gpt-4o during the conversation in Topic 1:
If auto-reset is enabled: When creating Topic 2, the default model selected for Topic 2 will be gpt-3.5-turbo.
If auto-reset is not enabled: When creating Topic 2, the default model selected for Topic 2 will be gpt-4o.
Temperature:The temperature parameter controls the degree of randomness and creativity in the text generated by the model (default value is 0.7). Specifically:
Low temperature values (0-0.3):
Output is more deterministic and focused.
Suitable for scenarios requiring accuracy, such as code generation and data analysis.
Tends to select the most probable words for output.
Medium temperature values (0.4-0.7):
Balances creativity and coherence.
Suitable for daily conversations and general writing.
Recommended for chatbot conversations (around 0.5).
High temperature values (0.8-1.0):
Produces more creative and diverse output.
Suitable for creative writing, brainstorming, etc.
May reduce text coherence.
Top P (Nucleus Sampling):The default value is 1. A smaller value makes the AI-generated content more monotonous and easier to understand; a larger value gives the AI a wider and more diverse range of vocabulary for replies.
Nucleus sampling affects output by controlling the probability threshold for vocabulary selection:
Smaller values (0.1-0.3):
Only consider words with the highest probability.
Output is more conservative and controllable.
Suitable for scenarios like code comments and technical documentation.
Medium values (0.4-0.6):
Balances vocabulary diversity and accuracy.
Suitable for general conversations and writing tasks.
Larger values (0.7-1.0):
Considers a wider range of vocabulary.
Produces richer and more diverse content.
Suitable for creative writing and other scenarios requiring diverse expression.
Context WindowThe number of messages to keep in the context. A larger value means a longer context and consumes more tokens:
5-10: Suitable for general conversations.
10: For complex tasks requiring longer memory (e.g., generating long texts step-by-step according to an outline, where generated context needs to ensure logical coherence).
Note: More messages consume more tokens.
Enable Message Length Limit (MaxToken)The maximum Token count for a single response. In large language models, max token (maximum token count) is a crucial parameter that directly affects the quality and length of the model's generated responses.
For example, when testing if a model is connected after filling in the key in CherryStudio, if you only need to know if the model returns a message correctly without specific content, you can set MaxToken to 1.
The MaxToken limit for most models is 32k Tokens, but some support 64k or even more; you need to check the relevant introduction page for details.
The specific setting depends on your needs, but you can also refer to the following suggestions.
Suggestions:
General Chat: 500-800
Short Text Generation: 800-2000
Code Generation: 2000-3600
Long Text Generation: 4000 and above (requires model support)
Generally, the model's generated response will be limited within the MaxToken range. However, it may also be truncated (e.g., when writing long code) or expressed incompletely. In special cases, adjustments need to be made flexibly according to the actual situation.
Streaming Output (Stream)Streaming output is a data processing method that allows data to be transmitted and processed in a continuous stream, rather than sending all data at once. This method allows data to be processed and output immediately after it is generated, greatly improving real-time performance and efficiency.
In environments like the CherryStudio client, it basically means a "typewriter effect."
When disabled (non-streaming): The model generates information and outputs the entire segment at once (imagine receiving a message on WeChat).
When enabled: Outputs character by character. This can be understood as the large model sending you each character as soon as it generates it, until all characters are sent.
Custom ParametersAdds additional request parameters to the request body, such as presence_penalty and other fields. Generally, most users will not need this.
Parameters like top-p, maxtokens, stream, etc., mentioned above are some of these parameters.
Input format: Parameter Name — Parameter Type (text, number, etc.) — Value. Reference documentation: Click to go.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio supports web search via SearXNG, an open-source project deployable both locally and on servers. Its configuration differs slightly from other setups requiring API providers.
SearXNG Project Link: SearXNG
Open-source and free, no API required
Relatively high privacy
Highly customizable
SearXNG doesn't require complex environment configuration and can deploy using Docker with just a single available port.
1. Download, install, and configure docker
After installation, select an image storage path:
2. Search and pull the SearXNG image
Enter searxng in the search bar:
Pull the image:
3. Run the image
After successful pull, go to Images:
Select the pulled image and click run:
Open settings for configuration:
Take port 8085 as example:
After successful run, open SearXNG frontend via link:
This page indicates successful deployment:
Since Docker installation on Windows can be cumbersome, users can deploy SearXNG on servers for sharing. Unfortunately, SearXNG currently lacks built-in authentication, making deployed instances vulnerable to scanning and abuse.
To address this, Cherry Studio supports HTTP Basic Authentication (RFC7617). If exposing SearXNG publicly, you must configure HTTP Basic Authentication via reverse proxies like Nginx. This tutorial assumes basic Linux operations knowledge.
Similarly deploy via Docker. Assuming Docker CE is installed per official guide, run these commands on fresh Debian systems:
sudo apt update
sudo apt install git -y
# Pull official repo
cd /opt
git clone https://github.com/searxng/searxng-docker.git
cd /opt/searxng-docker
# Set to false for limited server bandwidth
export IMAGE_PROXY=true
# Modify config
cat <<EOF > /opt/searxng-docker/searxng/settings.yml
# see https://docs.searxng.org/admin/settings/settings.html#settings-use-default-settings
use_default_settings: true
server:
# base_url is defined in the SEARXNG_BASE_URL environment variable, see .env and docker-compose.yml
secret_key: $(openssl rand -hex 32)
limiter: false # can be disabled for a private instance
image_proxy: $IMAGE_PROXY
ui:
static_use_hash: true
redis:
url: redis://redis:6379/0
search:
formats:
- html
- json
EOFEdit docker-compose.yaml to change ports or reuse existing Nginx:
version: "3.7"
services:
# Remove below if reusing existing Nginx instead of Caddy
caddy:
container_name: caddy
image: docker.io/library/caddy:2-alpine
network_mode: host
restart: unless-stopped
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile:ro
- caddy-data:/data:rw
- caddy-config:/config:rw
environment:
- SEARXNG_HOSTNAME=${SEARXNG_HOSTNAME:-http://localhost}
- SEARXNG_TLS=${LETSENCRYPT_EMAIL:-internal}
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
# Remove above if reusing existing Nginx instead of Caddy
redis:
container_name: redis
image: docker.io/valkey/valkey:8-alpine
command: valkey-server --save 30 1 --loglevel warning
restart: unless-stopped
networks:
- searxng
volumes:
- valkey-data2:/data
cap_drop:
- ALL
cap_add:
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
searxng:
container_name: searxng
image: docker.io/searxng/searxng:latest
restart: unless-stopped
networks:
- searxng
# Default host port:8080, change to "127.0.0.1:8000:8080" for port 8000
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
environment:
- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/
- UWSGI_WORKERS=${SEARXNG_UWSGI_WORKERS:-4}
- UWSGI_THREADS=${SEARXNG_UWSGI_THREADS:-4}
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
networks:
searxng:
volumes:
# Remove below if reusing existing Nginx
caddy-data:
caddy-config:
# Remove above if reusing existing Nginx
valkey-data2:Start with docker compose up -d. View logs using docker compose logs -f searxng.
For server panels like Baota or 1Panel:
Add site and configure Nginx reverse proxy per their docs
Locate Nginx config, modify per below example:
server
{
listen 443 ssl;
# Your hostname
server_name search.example.com;
# index index.html;
# root /data/www/default;
# SSL config
ssl_certificate /path/to/your/cert/fullchain.pem;
ssl_certificate_key /path/to/your/cert/privkey.pem;
# HSTS
# add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload";
# Reverse proxy config
location / {
# Add these two lines in location block
auth_basic "Please enter your username and password";
auth_basic_user_file /etc/nginx/conf.d/search.htpasswd;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_protocol_addr;
proxy_pass http://127.0.0.1:8000;
client_max_body_size 0;
}
# access_log ...;
# error_log ...;
}Save password file in /etc/nginx/conf.d:
echo "example_name:$(openssl passwd -5 'example_password')" > /etc/nginx/conf.d/search.htpasswdRestart or reload Nginx. Access should prompt for credentials:
After successful SearXNG deployment:
Go to web search settings > Select Searxng
Initial verification may fail due to missing JSON format:
In Docker > Files tab, locate tagged folder > settings.yml
Edit file, add "json" to formats (line 78)
Rerun image
Successful verification in Cherry Studio
Use:
Local: http://localhost:port
Docker: http://host.docker.internal:port
For server deployments with HTTP Basic Authentication:
Initial verification returns 401
Configure credentials in client:
To customize search engines:
Default preferences don't affect model invocations
Configure model-invoked engines in settings.yml:
Syntax reference:
For lengthy edits, modify in local IDE then paste back.
Add "json" to return formats:
Cherry Studio defaults to engines with "web" and "general" categories (e.g., Google). In mainland China, force Baidu:
use_default_settings:
engines:
keep_only:
- baidu
engines:
- name: baidu
engine: baidu
categories:
- web
- general
disabled: falseDisable limiter in settings:




























This document was translated from Chinese by AI and has not yet been reviewed.
This is a leaderboard based on Chatbot Arena (lmarena.ai) data, generated through an automated process.
Data update time: 2025-09-18 11:35:51 UTC / 2025-09-18 19:35:51 CST (Beijing Time)
1
1
1470
+5/-5
26,019
Proprietary
nan
2
2
1446
+6/-6
13,715
Proprietary
nan
3
2
1434
+9/-9
4,112
Z.ai
MIT
nan
4
2
1434
+6/-6
13,058
xAI
Proprietary
nan
5
3
1429
+4/-4
30,777
OpenAI
Proprietary
nan
6
3
1428
+4/-4
32,033
OpenAI
Proprietary
nan
7
3
1427
+9/-9
4,154
Alibaba
Apache 2.0
nan
8
3
1427
+5/-5
18,284
DeepSeek
MIT
nan
9
4
1423
+4/-4
31,757
xAI
Proprietary
nan
10
8
1416
+4/-4
26,604
Meta
nan
nan
11
8
1415
+5/-5
15,271
OpenAI
Proprietary
nan
12
7
1413
+9/-9
3,715
Alibaba
Apache 2.0
nan
13
8
1412
+6/-6
13,837
xAI
Proprietary
nan
14
10
1411
+4/-4
31,359
Proprietary
nan
15
15
1397
+4/-4
27,552
Proprietary
nan
16
15
1397
+5/-5
20,120
Proprietary
nan
17
15
1396
+5/-5
18,655
Proprietary
nan
18
15
1393
+9/-9
4,306
Z.ai
MIT
nan
19
15
1391
+5/-5
24,372
Alibaba
Apache 2.0
nan
20
15
1389
+4/-4
23,657
Proprietary
nan
21
15
1389
+4/-4
23,858
OpenAI
Proprietary
nan
22
19
1381
+3/-3
40,509
OpenAI
Proprietary
nan
23
18
1380
+6/-6
11,676
Moonshot
Modified MIT
nan
24
19
1380
+5/-5
24,834
OpenAI
Proprietary
nan
25
16
1380
+12/-12
2,258
Alibaba
Apache 2.0
nan
26
22
1379
+5/-5
17,328
Proprietary
nan
27
22
1378
+5/-5
16,963
Proprietary
nan
28
22
1376
+6/-6
11,657
Tencent
Proprietary
nan
29
22
1376
+4/-4
27,391
DeepSeek
MIT
nan
30
22
1373
+5/-5
17,970
Anthropic
Proprietary
nan
31
23
1372
+4/-4
19,430
DeepSeek
MIT
nan
32
24
1370
+4/-4
22,500
Proprietary
nan
33
24
1370
+5/-5
28,010
Mistral
Proprietary
nan
34
24
1368
+5/-5
17,088
Proprietary
nan
35
28
1366
+3/-3
35,457
Alibaba
Proprietary
nan
36
27
1366
+5/-5
26,141
Anthropic
Proprietary
nan
37
28
1365
+5/-5
20,489
Alibaba
Apache 2.0
nan
38
29
1365
+4/-4
29,038
OpenAI
Proprietary
nan
39
32
1362
+3/-3
41,036
Proprietary
nan
40
32
1362
+5/-5
24,472
OpenAI
Proprietary
nan
41
32
1361
+6/-6
10,194
xAI
Proprietary
nan
42
32
1360
+5/-5
16,845
xAI
Proprietary
nan
43
33
1357
+7/-7
6,012
Alibaba
Apache 2.0
nan
44
36
1357
+4/-4
32,176
Gemma
nan
45
39
1354
+4/-4
48,669
OpenAI
Proprietary
2023/10
46
39
1354
+5/-5
17,524
MiniMax
Apache 2.0
nan
47
40
1353
+4/-4
33,177
OpenAI
Proprietary
2023/10
48
41
1350
+5/-5
17,124
Anthropic
Proprietary
nan
49
44
1341
+9/-9
4,074
Alibaba
Apache 2.0
nan
50
46
1339
+10/-10
3,106
Nvidia
Nvidia Open
nan
51
49
1338
+5/-5
19,404
OpenAI
Proprietary
nan
52
49
1338
+5/-5
22,629
Anthropic
Proprietary
nan
53
49
1336
+5/-5
23,892
OpenAI
Proprietary
nan
54
49
1335
+6/-6
9,147
Mistral
Apache 2.0
nan
55
49
1335
+9/-9
3,976
Gemma
nan
56
49
1334
+3/-3
35,503
OpenAI
Proprietary
2023/10
57
49
1333
+4/-4
22,841
DeepSeek
DeepSeek
nan
58
49
1332
+8/-8
6,028
Zhipu
Proprietary
nan
59
49
1331
+4/-4
22,178
Alibaba
Apache 2.0
nan
60
49
1330
+4/-4
26,104
Proprietary
nan
61
49
1327
+8/-8
6,055
Alibaba
Proprietary
nan
62
54
1326
+4/-4
30,944
Cohere
CC-BY-NC-4.0
nan
63
57
1322
+5/-5
13,900
Amazon
Proprietary
nan
64
55
1320
+8/-8
5,126
StepFun
Proprietary
nan
65
52
1320
+11/-11
2,656
Nvidia
Nvidia Open Model
nan
66
60
1320
+5/-5
20,360
Alibaba
Apache 2.0
nan
67
61
1320
+3/-3
58,645
Proprietary
nan
68
53
1320
+10/-10
2,452
Tencent
Proprietary
nan
69
61
1318
+3/-3
54,951
OpenAI
Proprietary
2023/10
70
61
1318
+3/-3
43,216
OpenAI
Proprietary
nan
71
62
1317
+4/-4
32,592
Anthropic
Proprietary
nan
72
62
1316
+4/-4
32,262
Proprietary
2023/11
73
62
1315
+4/-4
25,988
Proprietary
2023/11
74
60
1313
+10/-10
2,510
Tencent
Proprietary
nan
75
62
1309
+11/-11
2,371
Nvidia
Nvidia
nan
76
73
1305
+3/-3
67,084
xAI
Proprietary
2024/3
77
71
1305
+6/-6
13,182
Gemma
nan
78
74
1303
+4/-4
28,968
01 AI
Proprietary
nan
79
74
1302
+3/-3
117,747
OpenAI
Proprietary
2023/10
80
74
1301
+4/-4
37,645
Anthropic
Proprietary
nan
81
74
1300
+6/-6
10,715
Alibaba
Proprietary
nan
82
76
1299
+2/-2
84,537
Anthropic
Proprietary
2024/4
83
74
1295
+7/-7
7,243
DeepSeek
DeepSeek
nan
84
80
1293
+4/-4
26,074
NexusFlow
NexusFlow
nan
85
76
1293
+9/-9
4,321
Gemma
nan
86
81
1292
+4/-4
24,544
Meta
Llama 4
nan
87
82
1291
+4/-4
27,788
Zhipu AI
Proprietary
nan
88
76
1290
+9/-9
3,856
Tencent
Proprietary
nan
89
83
1289
+3/-3
37,021
Proprietary
nan
90
83
1288
+3/-3
72,427
OpenAI
Proprietary
2023/10
91
82
1287
+7/-7
6,302
OpenAI
Proprietary
nan
92
83
1286
+3/-3
43,788
Meta
Llama 3.1 Community
2023/12
93
84
1285
+3/-3
47,973
OpenAI
Proprietary
2023/10
94
83
1284
+7/-7
7,577
Nvidia
Llama 3.1
2023/12
95
83
1284
+5/-5
17,432
Alibaba
Qwen
nan
96
84
1284
+4/-4
25,409
Proprietary
2023/11
97
85
1284
+3/-3
63,038
Meta
Llama 3.1 Community
2023/12
98
84
1283
+5/-5
17,067
01 AI
Proprietary
nan
99
87
1283
+3/-3
55,442
xAI
Proprietary
2024/3
100
87
1283
+3/-3
86,159
Anthropic
Proprietary
2024/4
101
89
1280
+4/-4
52,144
Proprietary
Online
102
95
1276
+3/-3
82,435
Proprietary
2023/11
103
91
1276
+5/-5
14,153
Meta
Llama
nan
104
88
1276
+9/-9
4,014
Tencent
Proprietary
nan
105
99
1275
+3/-3
51,931
Meta
Llama-3.3
nan
106
100
1274
+3/-3
102,133
OpenAI
Proprietary
2023/12
107
99
1274
+4/-4
26,344
DeepSeek
DeepSeek
nan
108
100
1273
+4/-4
55,569
Proprietary
2023/11
109
101
1272
+3/-3
41,519
Alibaba
Qwen
2024/9
110
99
1270
+8/-8
6,093
Tencent
Proprietary
nan
111
102
1269
+3/-3
48,217
Mistral
Mistral Research
2024/7
112
102
1269
+5/-5
14,091
Mistral
Apache 2.0
nan
113
102
1268
+4/-4
29,633
Mistral
MRL
nan
114
102
1267
+5/-5
20,580
NexusFlow
CC-BY-NC-4.0
2024/7
115
107
1266
+3/-3
103,748
OpenAI
Proprietary
2023/4
116
107
1265
+3/-3
97,079
OpenAI
Proprietary
2023/12
117
109
1265
+2/-2
202,641
Anthropic
Proprietary
2023/8
118
109
1264
+3/-3
58,637
Meta
Llama 3.1 Community
2023/12
119
111
1261
+4/-4
26,371
Amazon
Proprietary
nan
120
107
1259
+10/-10
3,010
Ai2
Llama 3.1
nan
121
114
1258
+4/-4
51,628
01 AI
Proprietary
No data available
122
119
1255
+3/-3
55,928
Anthropic
Propretary
nan
123
119
1252
+7/-7
8,534
Mistral
Proprietary
nan
124
119
1251
+6/-6
7,948
Reka AI
Proprietary
nan
125
120
1249
+6/-6
13,279
Reka AI
Proprietary
nan
126
123
1243
+4/-4
65,661
Proprietary
2023/11
127
123
1242
+5/-5
14,626
Alibaba
Proprietary
nan
128
123
1241
+6/-6
9,125
AI21 Labs
Jamba Open
2024/3
129
125
1239
+5/-5
19,508
DeepSeek AI
DeepSeek
nan
130
125
1238
+5/-5
15,321
Mistral
Apache 2.0
nan
131
125
1236
+6/-6
11,725
DeepSeek
Proprietary
nan
132
126
1235
+6/-6
16,624
01 AI
Proprietary
No data available
133
127
1235
+2/-2
79,538
Gemma license
2024/6
134
126
1234
+7/-7
5,730
Alibaba
Apache 2.0
nan
135
126
1233
+6/-6
10,535
Cohere
CC-BY-NC-4.0
2024/8
136
127
1233
+4/-4
20,646
Amazon
Proprietary
nan
137
126
1232
+6/-6
10,548
Princeton
MIT
2024/7
138
126
1231
+9/-9
3,889
Nvidia
Llama 3.1
2023/12
139
128
1230
+3/-3
37,697
Proprietary
nan
140
127
1230
+6/-6
10,221
Zhipu AI
Proprietary
No data available
141
130
1229
+4/-4
20,608
Nvidia
NVIDIA Open Model
2023/6
142
130
1228
+4/-4
28,768
Cohere
CC-BY-NC-4.0
nan
143
128
1227
+8/-8
11,833
Proprietary
Online
144
132
1224
+6/-6
8,132
Reka AI
Proprietary
nan
145
135
1224
+3/-3
163,629
Meta
Llama 3 Community
2023/12
146
130
1223
+10/-10
3,460
Allen AI
Apache-2.0
nan
147
138
1222
+3/-3
113,067
Anthropic
Proprietary
2023/8
148
138
1222
+4/-4
25,213
Microsoft
MIT
nan
149
138
1221
+4/-4
25,346
Proprietary
2023/11
150
142
1217
+3/-3
62,555
Reka AI
Proprietary
nan
151
142
1217
+6/-6
13,725
Reka AI
Proprietary
nan
152
144
1214
+4/-4
20,654
Amazon
Proprietary
nan
153
149
1212
+3/-3
57,197
Gemma license
2024/6
154
149
1210
+4/-4
55,962
OpenAI
Proprietary
2021/9
155
151
1208
+3/-3
80,846
Cohere
CC-BY-NC-4.0
2024/3
156
144
1208
+11/-11
2,901
Tencent
Proprietary
nan
157
151
1208
+4/-4
38,872
Alibaba
Qianwen LICENSE
2024/6
158
156
1200
+3/-3
122,309
Anthropic
Proprietary
2023/8
159
153
1199
+10/-10
3,074
Ai2
Llama 3.1
nan
160
156
1199
+5/-5
25,696
Alibaba
Proprietary
nan
161
154
1198
+9/-9
7,579
Zhipu AI
Proprietary
No data available
162
154
1198
+8/-8
5,111
Mistral
MRL
nan
163
157
1196
+6/-6
15,753
DeepSeek AI
DeepSeek License
2024/6
164
157
1195
+6/-6
10,851
Cohere
CC-BY-NC-4.0
2024/8
165
157
1193
+6/-6
10,391
Cohere
CC-BY-NC-4.0
nan
166
157
1193
+6/-6
9,274
AI21 Labs
Jamba Open
2024/3
167
159
1193
+3/-3
52,578
Meta
Llama 3.1 Community
2023/12
168
159
1191
+3/-3
91,614
OpenAI
Proprietary
2021/9
169
159
1188
+5/-5
20,427
Reka AI
Proprietary
nan
170
169
1181
+4/-4
64,926
Mistral
Proprietary
nan
171
169
1180
+5/-5
27,430
Alibaba
Qianwen LICENSE
2024/4
172
169
1178
+6/-6
21,149
Anthropic
Proprietary
nan
173
170
1178
+4/-4
25,135
01 AI
Apache-2.0
2024/5
174
169
1176
+7/-7
16,027
Reka AI
Proprietary
Online
175
170
1171
+4/-4
40,658
Alibaba
Qianwen LICENSE
2024/2
176
172
1171
+3/-3
109,056
Meta
Llama 3 Community
2023/3
177
171
1170
+5/-5
35,556
Mistral
Proprietary
nan
178
171
1170
+5/-5
25,803
Reka AI
Proprietary
2023/11
179
170
1170
+10/-10
3,410
Alibaba
Apache 2.0
nan
180
172
1169
+4/-4
56,398
Cohere
CC-BY-NC-4.0
2024/3
181
172
1168
+6/-6
10,599
InternLM
Other
2024/8
182
173
1167
+4/-4
53,751
Mistral
Apache 2.0
2024/4
183
176
1163
+3/-3
48,892
Gemma license
2024/7
184
177
1158
+8/-8
12,763
Anthropic
Proprietary
nan
185
175
1157
+10/-10
3,289
IBM
Apache 2.0
nan
186
181
1154
+7/-7
18,800
Proprietary
2023/4
187
181
1153
+8/-8
12,375
Mistral
Proprietary
nan
188
182
1150
+10/-10
4,854
HuggingFace
Apache 2.0
2024/4
189
184
1146
+6/-6
37,699
Anthropic
Proprietary
nan
190
184
1145
+5/-5
38,955
OpenAI
Proprietary
2021/9
191
184
1144
+5/-5
22,765
Alibaba
Qianwen LICENSE
2024/2
192
185
1143
+4/-4
26,105
Microsoft
MIT
2023/10
193
187
1138
+7/-7
16,676
Nexusflow
Apache-2.0
2024/3
194
188
1138
+3/-3
76,126
Mistral
Apache 2.0
2023/12
195
185
1137
+11/-11
5,640
OpenAI
Proprietary
2021/9
196
185
1137
+11/-11
6,557
Proprietary
2023/4
197
187
1135
+10/-10
3,380
IBM
Apache 2.0
nan
198
188
1135
+7/-7
20,631
Anthropic
Proprietary
nan
199
188
1135
+6/-6
18,687
Alibaba
Qianwen LICENSE
2024/2
200
188
1134
+6/-6
15,917
01 AI
Yi License
2023/6
201
188
1134
+6/-6
15,917
01 AI
Yi License
2023/6
202
193
1131
+4/-4
68,867
OpenAI
Proprietary
2021/9
203
193
1127
+9/-9
6,658
AllenAI/UW
AI2 ImpACT Low-risk
2023/11
204
195
1125
+5/-5
33,743
Databricks
DBRX LICENSE
2023/12
205
193
1125
+9/-9
8,383
Microsoft
Llama 2 Community
2023/8
206
199
1122
+5/-5
39,595
Meta
Llama 2 Community
2023/7
207
195
1119
+11/-11
3,836
NousResearch
Apache-2.0
2024/1
208
202
1117
+7/-7
8,390
Meta
Llama 3.2
2023/12
209
202
1117
+5/-5
18,476
Microsoft
MIT
2023/10
210
202
1114
+7/-7
10,415
UC Berkeley
CC-BY-NC-4.0
2023/11
211
202
1113
+7/-7
12,990
OpenChat
Apache-2.0
2024/1
212
203
1112
+5/-5
22,936
LMSYS
Non-commercial
2023/8
213
202
1110
+11/-11
4,988
DeepSeek AI
DeepSeek License
2023/11
214
206
1108
+5/-5
34,173
Snowflake
Apache 2.0
2024/4
215
206
1107
+8/-8
7,002
IBM
Apache 2.0
nan
216
203
1105
+12/-12
3,636
Nvidia
Llama 2 Community
2023/11
217
206
1103
+9/-9
8,106
OpenChat
Apache-2.0
2023/11
218
208
1102
+5/-5
25,070
Gemma license
2024/2
219
208
1100
+8/-8
17,036
OpenAI
Proprietary
2021/9
220
208
1100
+10/-10
5,088
NousResearch
Apache-2.0
2023/11
221
208
1099
+10/-10
6,898
Perplexity AI
Proprietary
Online
222
212
1097
+6/-6
20,067
Mistral
Apache-2.0
2023/12
223
215
1092
+6/-6
19,722
Meta
Llama 2 Community
2023/7
224
212
1091
+12/-12
4,286
Upstage AI
CC-BY-NC-4.0
2023/11
225
215
1090
+7/-7
7,191
IBM
Apache 2.0
nan
226
213
1090
+9/-9
4,872
Alibaba
Qianwen LICENSE
2024/2
227
212
1088
+15/-15
1,714
Cognitive Computations
Apache-2.0
2023/10
228
216
1087
+6/-6
12,808
Microsoft
MIT
2023/10
229
217
1084
+9/-9
7,176
Microsoft
Llama 2 Community
2023/7
230
222
1081
+5/-5
21,097
Microsoft
MIT
2023/10
231
223
1076
+8/-8
11,321
HuggingFace
MIT
2023/10
232
222
1075
+12/-12
2,644
MosaicML
CC-BY-NC-SA-4.0
2023/6
233
225
1072
+8/-8
7,509
Meta
Llama 2 Community
2023/7
234
229
1067
+7/-7
8,523
Meta
Llama 3.2
2023/12
235
224
1066
+15/-15
1,811
HuggingFace
MIT
2023/10
236
230
1065
+6/-6
19,775
LMSYS
Llama 2 Community
2023/7
237
223
1065
+17/-17
1,192
Meta
Llama 2 Community
2024/1
238
229
1064
+10/-10
6,339
Perplexity AI
Proprietary
Online
239
230
1063
+9/-9
9,176
Gemma license
2024/2
240
228
1062
+13/-13
2,375
HuggingFace
Apache 2.0
nan
241
226
1061
+17/-17
1,327
TII
Falcon-180B TII License
2023/9
242
230
1061
+6/-6
21,622
Microsoft
MIT
2023/10
243
230
1060
+6/-6
14,532
Meta
Llama 2 Community
2023/7
244
230
1060
+12/-12
2,996
UW
Non-commercial
2023/5
245
230
1058
+10/-10
5,065
Alibaba
Qianwen LICENSE
2023/8
246
235
1044
+10/-10
5,276
Together AI
Apache 2.0
2023/12
247
243
1038
+9/-9
7,017
LMSYS
Llama 2 Community
2023/7
248
240
1037
+10/-10
6,503
Allen AI
Apache-2.0
2024/2
249
245
1034
+9/-9
8,713
Proprietary
2021/6
250
245
1032
+7/-7
11,351
Gemma license
2024/2
251
245
1031
+9/-9
9,142
Mistral
Apache 2.0
2023/9
252
251
1011
+11/-11
4,918
Gemma license
2024/2
253
251
1006
+9/-9
7,816
Alibaba
Qianwen LICENSE
2024/2
254
251
996
+9/-9
7,020
UC Berkeley
Non-commercial
2023/4
255
253
978
+11/-11
4,763
Tsinghua
Apache-2.0
2023/10
256
254
963
+11/-11
3,997
MosaicML
CC-BY-NC-SA-4.0
2023/5
257
254
962
+15/-15
1,788
Nomic AI
Non-commercial
2023/3
258
254
956
+11/-11
4,920
RWKV
Apache 2.0
2023/4
259
255
947
+13/-13
2,713
Tsinghua
Apache-2.0
2023/6
260
255
940
+11/-11
5,864
Stanford
Non-commercial
2023/3
261
258
925
+12/-12
4,983
Tsinghua
Non-commercial
2023/3
262
258
923
+10/-10
6,368
OpenAssistant
Apache 2.0
2023/4
263
260
901
+12/-12
4,288
LMSYS
Apache 2.0
2023/4
264
263
873
+12/-12
3,336
Stability AI
CC-BY-NC-SA-4.0
2023/4
265
263
857
+13/-13
3,480
Databricks
MIT
2023/4
266
264
840
+16/-16
2,446
Meta
Non-commercial
2023/2
Rank (UB): Ranking calculated based on the Bradley-Terry model. This ranking reflects the overall performance of models in the arena and provides an upper bound estimate for their Elo scores, helping to understand the models' potential competitiveness.
Rank (StyleCtrl): Ranking after controlling for conversational style. This ranking aims to reduce preference bias caused by model response styles (e.g., verbosity, conciseness), providing a purer assessment of the model's core capabilities.
Model Name: The name of the Large Language Model (LLM). This column includes embedded links to model details, which can be clicked to navigate.
Score: The Elo rating obtained by the model through user votes in the arena. Elo rating is a relative ranking system, where a higher score indicates better model performance. This score is dynamic and reflects the model's relative strength in the current competitive environment.
Confidence Interval: The 95% confidence interval for the model's Elo rating (e.g., +6/-6). A smaller interval indicates a more stable and reliable model rating; conversely, a larger interval may suggest insufficient data or greater fluctuations in model performance. It provides a quantitative assessment of rating accuracy.
Votes: The total number of votes received by the model in the arena. More votes generally mean higher statistical reliability of its rating.
Provider: The organization or company that provides the model.
License: The type of license for the model, such as Proprietary, Apache 2.0, MIT, etc.
Knowledge Cutoff Date: The knowledge cutoff date for the model's training data. No data available indicates that the relevant information is not provided or unknown.
This leaderboard data is automatically generated and provided by the fboulnois/llm-leaderboard-csv project, which obtains and processes data from lmarena.ai. This leaderboard is automatically updated daily by GitHub Actions.
This report is for reference only. The leaderboard data is dynamic and based on user preference votes on Chatbot Arena during specific periods. The completeness and accuracy of the data depend on the updates and processing of the upstream data source and the fboulnois/llm-leaderboard-csv project. Different models may adopt different license agreements; please refer to the official documentation of the model provider when using them.