
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
This document was translated from Chinese by AI and has not yet been reviewed.
Note: Installing Cherry Studio is not supported on Windows 7.
Installer Version (Setup)
Portable Version (Portable)
This document was translated from Chinese by AI and has not yet been reviewed.
Follow our social accounts: Twitter(X), Xiaohongshu, Weibo, Bilibili, Douyin
Join our communities: QQ Group(575014769), Telegram, Discord, WeChat Group(click to view)
Cherry Studio is an all-in-one AI assistant platform integrating multi-model conversations, knowledge base management, AI painting, translation, and more. Cherry Studio's highly customizable design, powerful extensibility, and user-friendly experience make it an ideal choice for professional users and AI enthusiasts. Whether you are a beginner or a developer, you can find suitable AI functions in Cherry Studio to enhance your work efficiency and creativity.
1. Basic Chat Functionality
One Question, Multiple Answers: Supports generating replies from multiple models simultaneously for the same question, allowing users to compare the performance of different models. For details, see Chat Interface.
Automatic Grouping: Conversation records for each assistant are automatically grouped and managed, making it easy for users to quickly find historical conversations.
Conversation Export: Supports exporting full or partial conversations to various formats (e.g., Markdown, Word) for easy storage and sharing.
Highly Customizable Parameters: In addition to basic parameter adjustments, it also supports custom parameters to meet personalized needs.
Assistant Market: Built-in with over a thousand industry-specific assistants, covering fields like translation, programming, and writing, while also supporting user-defined assistants.
Multiple Format Rendering: Supports Markdown rendering, formula rendering, real-time HTML preview, and other functions to enhance content display.
2. Integration of Various Special Features
AI Painting: Provides a dedicated painting panel where users can generate high-quality images through natural language descriptions.
AI Mini-programs: Integrates various free web-based AI tools, allowing direct use without switching browsers.
Translation Function: Supports a dedicated translation panel, in-conversation translation, prompt translation, and other translation scenarios.
File Management: Files from conversations, paintings, and knowledge bases are managed in a unified and classified manner, avoiding tedious searches.
Global Search: Supports quick location of historical records and knowledge base content, improving work efficiency.
3. Unified Management for Multiple Service Providers
Service Provider Model Aggregation: Supports unified calling of models from major service providers like OpenAI, Gemini, Anthropic, and Azure.
Automatic Model Fetching: One-click to get a complete list of models without manual configuration.
Multi-key Polling: Supports rotating multiple API keys to avoid rate limit issues.
Precise Avatar Matching: Automatically matches each model with an exclusive avatar for better recognition.
Custom Service Providers: Supports third-party service providers that comply with specifications like OpenAI, Gemini, and Anthropic, offering strong compatibility.
4. Highly Customizable Interface and Layout
Custom CSS: Supports global style customization to create a unique interface style.
Custom Chat Layout: Supports list or bubble style layouts and allows customization of message styles (e.g., code snippet styles).
Custom Avatars: Supports setting personalized avatars for the software and assistants.
Custom Sidebar Menu: Users can hide or reorder sidebar functions according to their needs to optimize the user experience.
5. Local Knowledge Base System
Multiple Format Support: Supports importing various file formats such as PDF, DOCX, PPTX, XLSX, TXT, and MD.
Multiple Data Source Support: Supports local files, URLs, sitemaps, and even manually entered content as knowledge base sources.
Knowledge Base Export: Supports exporting processed knowledge bases to share with others.
Search and Check Support: After importing a knowledge base, users can perform real-time retrieval tests to check the processing results and segmentation effects.
6. Special Focus Features
Quick Q&A: Summon a quick assistant in any context (e.g., WeChat, browser) to get answers quickly.
Quick Translation: Supports quick translation of words or text from other contexts.
Content Summarization: Quickly summarizes long text content to improve information extraction efficiency.
Explanation: Explains complex issues with one click, without needing complicated prompts.
7. Data Security
Multiple Backup Solutions: Supports local backup, WebDAV backup, and scheduled backups to ensure data safety.
Data Security: Supports fully local usage scenarios, combined with local large models, to avoid data leakage risks.
Beginner-Friendly: Cherry Studio is committed to lowering the technical barrier, allowing even users with no prior experience to get started quickly, focusing on their work, study, or creation.
Comprehensive Documentation: Provides detailed user manuals and FAQs to help users solve problems quickly.
Continuous Iteration: The project team actively responds to user feedback and continuously optimizes features to ensure the project's healthy development.
Open Source and Extensibility: Supports customization and extension through open-source code to meet personalized needs.
Knowledge Management and Query: Quickly build and query exclusive knowledge bases using the local knowledge base feature, suitable for research, education, and other fields.
Multi-model Conversation and Creation: Supports simultaneous conversation with multiple models, helping users quickly obtain information or generate content.
Translation and Office Automation: Built-in translation assistants and file processing functions are suitable for users who need cross-lingual communication or document processing.
AI Painting and Design: Generate images from natural language descriptions to meet creative design needs.
This document was translated from Chinese by AI and has not yet been reviewed.
Log in to Alibaba Cloud Bailian. If you don't have an Alibaba Cloud account, you'll need to register one.
Click the 创建我的 API-KEY (Create My API-KEY) button in the upper right corner.
In the pop-up window, select the default business space (or you can customize it), and you can enter a description if you want.
Click the 确定 (Confirm) button in the lower right corner.
Afterward, you should see a new row added to the list. Click the 查看 (View) button on the right.
Click the 复制 (Copy) button.
Go to Cherry Studio, navigate to Settings → Model Providers → Alibaba Cloud Bailian, find API Key, and paste the copied API key here.
You can adjust the relevant settings as described in Model Providers, and then you can start using it.
This document was translated from Chinese by AI and has not yet been reviewed.
Here you can set the default interface color mode (Light Mode, Dark Mode, or Follow System).
This setting is for the layout of the conversation interface.
Topic Position
Auto-switch to Topic
When this setting is enabled, clicking on the assistant's name will automatically switch to the corresponding topic page.
Show Topic Time
When enabled, the creation time of the topic will be displayed below the topic.
On this page, you can set the software's color theme, page layout, or use for personalized adjustments.
This setting allows for flexible and personalized changes to the interface. For specific methods, please refer to in the advanced tutorials.
This document was translated from Chinese by AI and has not yet been reviewed.
The Agents page is a hub for assistants. Here, you can select or search for the model presets you want. Clicking on a card will add the assistant to the assistant list on the chat page.
You can also edit and create your own assistants on this page.
Click on My, then click on Create Agent to start creating your own assistant.
This document was translated from Chinese by AI and has not yet been reviewed.
When an assistant does not have a default assistant model set, the model selected by default in a new conversation will be the one set here.
The model set here is also used for optimizing prompts and the pop-up text assistant.
After each conversation, a model is called to generate a topic name for the conversation. The model set here is the one used for naming.
The translation function in input boxes for conversations, drawing, etc., and the translation model on the translation interface all use the model set here.
The model used by the quick assistant feature. For details, see Quick Assistant
This document was translated from Chinese by AI and has not yet been reviewed.
Contact us via email at [email protected] to get editor access.
Title: Application for Cherry Studio Docs Editor Role
Body: State your reasons for applying
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio supports configuring the blacklist manually or by adding subscription sources. For configuration rules, please refer to ublacklist.
You can add rules for search results or click the toolbar icon to block specified websites. Rules can be specified using either: match patterns (example: *://*.example.com/*) or regular expressions (example: /example\.(net|org)/).
You can also subscribe to public rule sets. This website lists some subscriptions: https://iorate.github.io/ublacklist/subscriptions
Here are some recommended subscription source links:
https://git.io/ublacklist
Chinese
https://raw.githubusercontent.com/laylavish/uBlockOrigin-HUGE-AI-Blocklist/main/list_uBlacklist.txt
AI-generated
This document was translated from Chinese by AI and has not yet been reviewed.
In Cherry Studio, a single provider supports using multiple keys in a round-robin fashion. The rotation method is a list loop from front to back.
Add multiple keys separated by English commas. For example:
You must use English commas.
When using built-in providers, you generally do not need to fill in the API address. If you need to modify it, please strictly follow the address provided in the corresponding official documentation.
If the address provided by the provider is in the format https://xxx.xxx.com/v1/chat/completions, you only need to fill in the base URL part (https://xxx.xxx.com).
Cherry Studio will automatically append the remaining path (/v1/chat/completions). Failure to fill it in as required may result in it not working correctly.
Usually, clicking the Manage button at the bottom left of the provider configuration page will automatically fetch all models supported by that provider. Click the + sign from the fetched list to add them to the model list.
Click the check button after the API Key input box to test if the configuration is successful.
After successful configuration, be sure to turn on the switch in the upper right corner. Otherwise, the provider will remain disabled, and you will not be able to find the corresponding models in the model list.
This document was translated from Chinese by AI and has not yet been reviewed.
Log in and go to the token page
Create a new token (or you can directly use the default token ↑)
Copy the token
Open CherryStudio's provider settings and click Add at the bottom of the provider list.
Enter a note name, select OpenAI as the provider, and click OK.
Paste the key you just copied.
Go back to the page where you got the API Key and copy the root address from the browser's address bar, for example:
Add models (click Manage to automatically fetch or manually enter them) and toggle the switch in the upper right corner to enable them.
Other OneAPI themes may have different interfaces, but the method for adding them is the same as the process described above.
This document was translated from Chinese by AI and has not yet been reviewed.
Automatically installs MCP services (beta).
A basic implementation of persistent memory based on a local knowledge graph. This allows the model to remember relevant user information across different conversations.
An MCP server implementation that provides tools for dynamic and reflective problem-solving through structured thought processes.
An MCP server implementation that integrates the Brave Search API, providing dual functionality for web and local search.
An MCP server for fetching web page content from a URL.
A Node.js server that implements the Model Context Protocol (MCP) for file system operations.
This document was translated from Chinese by AI and has not yet been reviewed.
Use this method to clear CSS settings when you have set incorrect CSS or cannot enter the settings interface after setting the CSS.
Open the console, click on the CherryStudio window, and press the shortcut key Ctrl+Shift+I (MacOS: command+option+I).
In the console window that pops up, click Console.
Then, manually type document.getElementById('user-defined-custom-css').remove(). Copying and pasting will likely not execute.
After typing, press Enter to confirm and clear the CSS settings. Then, go back to CherryStudio's display settings and delete the problematic CSS code.
This document was translated from Chinese by AI and has not yet been reviewed.
Contact the developer via email: [email protected]
This page only introduces the interface functions. For configuration tutorials, please refer to the tutorial in the basic tutorials.
On the official , click + Create new secret key
Copy the generated key and open CherryStudio's .
The painting feature currently only supports the painting models from SiliconFlow. You can go to to register an account and to use it.
Join the Telegram discussion group for help:
GitHub Issues:
This document was translated from Chinese by AI and has not yet been reviewed.
We welcome contributions to Cherry Studio! You can contribute in the following ways:
Contribute Code: Develop new features or optimize existing code.
Fix Bugs: Submit fixes for bugs you find.
Maintain Issues: Help manage GitHub issues.
Product Design: Participate in design discussions.
Write Documentation: Improve user manuals and guides.
Community Engagement: Join discussions and help users.
Promote Usage: Spread the word about Cherry Studio.
Send an email to [email protected]
Email Subject: Apply to become a developer
Email Body: Reason for application
This document was translated from Chinese by AI and has not yet been reviewed.
Welcome to Cherry Studio (hereinafter referred to as "this software" or "we"). We place a high value on protecting your privacy. This Privacy Policy explains how we handle and protect your personal information and data. Please read and understand this policy carefully before using this software:
To optimize user experience and improve software quality, we may only collect the following anonymous, non-personal information:
• Software version information; • Activity and usage frequency of software features; • Anonymous crash and error log information;
The above information is completely anonymous, does not involve any personally identifiable data, and cannot be associated with your personal information.
To maximize the protection of your privacy and security, we explicitly promise:
• We will not collect, save, transmit, or process the model service API Key information you enter into this software; • We will not collect, save, transmit, or process any conversation data generated during your use of this software, including but not limited to chat content, command information, knowledge base information, vector data, and other custom content; • We will not collect, save, transmit, or process any personally identifiable sensitive information.
This software uses the API Key from a third-party model service provider that you apply for and configure yourself to perform model calls and conversation functions. The model services you use (e.g., large models, API interfaces, etc.) are provided by and are the sole responsibility of the third-party provider you choose. Cherry Studio only acts as a local tool to provide the interface calling function with third-party model services.
Therefore:
• All conversation data generated between you and the large model service is unrelated to Cherry Studio. We do not participate in data storage, nor do we conduct any form of data transmission or relay; • You need to review and accept the privacy policies and related terms of the corresponding third-party model service providers. The privacy policies for these services can be found on the official websites of each provider.
You are solely responsible for any privacy risks that may arise from using third-party model service providers. For specific privacy policies, data security measures, and related liabilities, please refer to the relevant content on the official website of your chosen model service provider. We assume no responsibility for this.
This policy may be adjusted appropriately with software version updates. Please check it regularly. When substantial changes to the policy occur, we will notify you in an appropriate manner.
If you have any questions about the content of this policy or Cherry Studio's privacy protection measures, please feel free to contact us.
Thank you for choosing and trusting Cherry Studio. We will continue to provide you with a secure and reliable product experience.
This document was translated from Chinese by AI and has not yet been reviewed.
For usage of the knowledge base, refer to the Knowledge Base Tutorial in the advanced tutorials.
This document was translated from Chinese by AI and has not yet been reviewed.
Quick Assistant is a convenient tool provided by Cherry Studio that allows you to quickly access AI functions in any application, enabling instant questioning, translation, summarization, and explanation.
Open Settings: Navigate to Settings -> Shortcuts -> Quick Assistant.
Enable the Switch: Find and turn on the switch for Quick Assistant.
Set Shortcut (Optional):
The default shortcut for Windows is Ctrl + E.
The default shortcut for macOS is ⌘ + E.
You can customize the shortcut here to avoid conflicts or to better suit your usage habits.
Invoke: In any application, press your set shortcut (or the default one) to open the Quick Assistant.
Interact: In the Quick Assistant window, you can perform the following actions directly:
Quick Question: Ask the AI any question.
Text Translation: Enter the text you need to translate.
Content Summarization: Input long text for a summary.
Explanation: Enter concepts or terms that need clarification.
Close: Press the ESC key or click anywhere outside the Quick Assistant window to close it.
Shortcut Conflicts: If the default shortcut conflicts with other applications, please modify it.
Explore More Features: In addition to the functions mentioned in the documentation, the Quick Assistant may support other operations, such as code generation, style conversion, etc. It is recommended that you continue to explore during use.
Feedback & Improvement: If you encounter any problems or have any suggestions for improvement during use, please provide feedback to the Cherry Studio team in a timely manner.
macOS 版本安装教程
This document was translated from Chinese by AI and has not yet been reviewed.
First, go to the official website's download page to download the Mac version, or click the direct link below.
Please make sure to download the correct chip version for your Mac.
After the download is complete, click here.
Drag the icon to install.
Go to Launchpad, find the Cherry Studio icon, and click it. If the Cherry Studio main interface opens, the installation is successful.
This document was translated from Chinese by AI and has not yet been reviewed.
Log in and open the token page
Click "Add Token"
Enter a token name and click "Submit" (other settings can be configured as needed).
Open the provider settings in CherryStudio and click Add at the bottom of the provider list.
Enter a memo name, select OpenAI as the provider, and click OK.
Paste the key you just copied.
Go back to the page where you obtained the API Key and copy the base URL from your browser's address bar. For example:
Add models (click "Manage" to fetch them automatically or enter them manually), then enable the switch in the top-right corner to start using them.
This document was translated from Chinese by AI and has not yet been reviewed.
The following uses the fetch feature as an example to demonstrate how to use MCP in Cherry Studio. You can find more details in the documentation.
In Settings - MCP Server, click the Install button to automatically download and install them. Since the downloads are directly from GitHub, the speed might be slow, and there is a high chance of failure. The success of the installation depends on whether the files exist in the folder mentioned below.
Executable Installation Directory:
Windows: C:\Users\YourUsername\.cherrystudio\bin
macOS, Linux: ~/.cherrystudio/bin
If the installation fails:
You can create a symbolic link (soft link) from the corresponding system command to this directory. If the directory does not exist, you need to create it manually. Alternatively, you can manually download the executable files and place them in this directory:
Bun: https://github.com/oven-sh/bun/releases UV: https://github.com/astral-sh/uv/releases
This document was translated from Chinese by AI and has not yet been reviewed.
Open Cherry Studio settings.
Find the MCP Server option.
Click Add Server.
Fill in the relevant parameters for the MCP Server (reference link). The content you may need to fill in includes:
Name: Customize a name, for example, fetch-server
Type: Select STDIO
Command: Fill in uvx
Arguments: Fill in mcp-server-fetch
(There may be other parameters, depending on the specific Server)
Click Save.
After completing the above configuration, Cherry Studio will automatically download the required MCP Server - fetch server. Once the download is complete, we can start using it! Note: If the mcp-server-fetch configuration is unsuccessful, you can try restarting your computer.
Successfully added an MCP server in the MCP Server settings
As you can see from the image above, by integrating MCP's fetch feature, Cherry Studio can better understand the user's query intent, retrieve relevant information from the web, and provide more accurate and comprehensive answers.
This document was translated from Chinese by AI and has not yet been reviewed.
Contact Person: Mr. Wang
📱:18954281942 (Not a customer service number)
For usage inquiries, you can join our user communication group at the bottom of the official website homepage, or email [email protected]
Or submit issues at: https://github.com/CherryHQ/cherry-studio/issues
If you need more guidance, you can join our Knowledge Planet
Commercial license details: https://docs.cherry-ai.com/contact-us/questions/cherrystudio-xu-ke-xie-yi
Windows 版本安装教程
This document was translated from Chinese by AI and has not yet been reviewed.
Note: Cherry Studio cannot be installed on Windows 7.
Click download and select the appropriate version
If the browser prompts that the file is not trusted, choose to keep it.
Choose Keep→Trust Cherry-Studio
This document was translated from Chinese by AI and has not yet been reviewed.
Supports exporting topics and messages to SiYuan Note.
Open SiYuan Note and create a new notebook.
Open the notebook settings and copy the Notebook ID.
Paste the copied Notebook ID into the Cherry Studio settings.
Enter the SiYuan Note address.
Local
Usually http://127.0.0.1:6806
Self-hosted
Your domain, e.g., http://note.domain.com
Copy the SiYuan Note API Token.
Paste it into the Cherry Studio settings and check the connection.
Congratulations, the SiYuan Note configuration is complete ✅ You can now export content from Cherry Studio to your SiYuan Note.
This document was translated from Chinese by AI and has not yet been reviewed.
The Dify Knowledge Base MCP requires upgrading Cherry Studio to v1.2.9 or higher.
Open Search MCP.
Add the dify-knowledge server.
Parameters and environment variables need to be configured
The Dify knowledge base key can be obtained as follows
This document was translated from Chinese by AI and has not yet been reviewed.
To use GitHub Copilot, you first need a GitHub account and a subscription to the GitHub Copilot service. A free version subscription is also acceptable, but the free version does not support the latest Claude 3.7 model. For details, please refer to the official GitHub Copilot website.
Click "Login with GitHub" to get the Device Code and copy it.
After successfully obtaining the Device Code, click the link to open your browser. Log in to your GitHub account in the browser, enter the Device Code, and authorize.
After successful authorization, return to Cherry Studio and click "Connect to GitHub". Upon success, your GitHub username and avatar will be displayed.
Click the "Manage" button below, and it will automatically connect to the internet to fetch the list of currently supported models.
Currently, requests are built using Axios, which does not support SOCKS proxies. Please use a system proxy or an HTTP proxy, or alternatively, do not set a proxy within CherryStudio and use a global proxy instead. First, ensure your network connection is stable to avoid failing to obtain the Device Code.
This document was translated from Chinese by AI and has not yet been reviewed.
Are you experiencing this: having 26 insightful articles saved in your WeChat Favorites that you never open again, more than 10 files scattered in a "study materials" folder on your computer, or trying to find a theory you read six months ago but only remembering a few keywords. When the daily amount of information exceeds your brain's processing limit, 90% of valuable knowledge is forgotten within 72 hours. Now, by building a personal knowledge base with the Infini-AI Large Model Service Platform API + Cherry Studio, you can transform those dust-gathering WeChat articles and fragmented course content into structured knowledge for precise retrieval.
1. Infini-AI API Service: The "Thinking Hub" of Your Knowledge Base, Easy-to-Use and Stable
As the "thinking hub" of the knowledge base, the Infini-AI Large Model Service Platform offers model versions like the full-power DeepSeek R1, providing stable API services. Currently, it's free to use with no barriers after registration. It supports mainstream embedding models like bge and jina for building knowledge bases. The platform also continuously updates with the latest, most powerful, and stable open-source model services, including various modalities such as images, videos, and voice.
2. Cherry Studio: Build a Knowledge Base with Zero Code
Cherry Studio is an easy-to-use AI tool. Compared to the 1-2 month deployment cycle required for RAG knowledge base development, this tool's advantage is its support for zero-code operation. You can import multiple formats like Markdown/PDF/webpages with one click. A 40MB file can be parsed in 1 minute. Additionally, you can add local computer folders, article URLs from WeChat Favorites, and course notes.
Step 1: Basic Preparation
Visit the official Cherry Studio website to download the appropriate version (https://cherry-ai.com/)
Register an account: Log in to the Infini-AI Large Model Service Platform (https://cloud.infini-ai.com/genstudio/model?cherrystudio)
Get API Key: In the "Model Square," select deepseek-r1, click create to get the APIKEY, and copy the model name.
Step 2: Open Cherry Studio settings, select Infini-AI in the Model Service, fill in the API Key, and enable the Infini-AI model service.
After completing the steps above, you can use Infini-AI's API service in Cherry Studio by selecting the desired large model during interaction. For convenience, you can also set a "Default Model" here.
Step 3: Add a Knowledge Base
Select any version of the bge series or jina series embedding models from the Infini-AI Large Model Service Platform.
After importing study materials, enter "Summarize the core formula derivations in Chapter 3 of 'Machine Learning'"
Generated result shown below
This document was translated from Chinese by AI and has not yet been reviewed.
1.2 Click on Settings in the bottom-left corner and select 【SiliconFlow】 under Model Service
1.2 Click the link to get the SiliconCloud API key
Log in to SiliconCloud (if you haven't registered, an account will be automatically created on your first login)
Visit API Keys to create a new key or copy an existing one
1.3 Click Manage to add a model
Click the "Chat" button in the left menu bar
Enter text in the input box to start chatting
You can switch models by selecting the model name in the top menu
This document was translated from Chinese by AI and has not yet been reviewed.
All data added to the Cherry Studio knowledge base is stored locally. During the addition process, a copy of the document will be placed in the Cherry Studio data storage directory.
Vector Database: https://turso.tech/libsql
After a document is added to the Cherry Studio knowledge base, the file will be split into several chunks, and then these chunks will be processed by an embedding model.
When using a large model for Q&A, text chunks related to the question will be retrieved and sent to the large language model for processing.
If you have data privacy requirements, it is recommended to use a local embedding database and a local large language model.
This document was translated from Chinese by AI and has not yet been reviewed.
Automatic MCP installation requires upgrading Cherry Studio to v1.1.18 or a higher version.
In addition to manual installation, Cherry Studio has a built-in tool, @mcpmarket/mcp-auto-install, which provides a more convenient way to install MCP servers. You just need to input the corresponding command in a large model conversation that supports MCP services.
Beta Phase Reminder:
@mcpmarket/mcp-auto-install is still in its beta phase.
The effectiveness depends on the "intelligence" of the large model. Some configurations will be added automatically, while others may still require manual changes to certain parameters in the MCP settings.
Currently, the search source is @modelcontextprotocol, which you can configure yourself (explained below).
For example, you can enter:
The system will automatically recognize your request and complete the installation via @mcpmarket/mcp-auto-install. This tool supports various types of MCP servers, including but not limited to:
filesystem
fetch
sqlite
and more...
The
MCP_PACKAGE_SCOPESvariable allows you to customize the MCP service search source. The default value is:@modelcontextprotocol, which can be configured.
@mcpmarket/mcp-auto-install LibraryThis document was translated from Chinese by AI and has not yet been reviewed.
Create an API Key.
After successful creation, click the eye icon next to the newly created API Key to reveal and copy it.
Paste the copied API Key into CherryStudio, then turn on the provider switch.
Click Add, and paste the previously obtained Model ID into the Model ID text box.
Follow this process to add models one by one.
There are two ways to write the API address:
The first is the client default: https://ark.cn-beijing.volces.com/api/v3/
The second way is: https://ark.cn-beijing.volces.com/api/v3/chat/completions#
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio supports importing topics into a Notion database.
Create an integration.
Name: Cherry Studio
Type: Select the first one
Icon: You can save this image
Copy the secret token and paste it into the Cherry Studio settings.
If your Notion database URL looks like this:
https://www.notion.so/<long_hash_1>?v=<long_hash_2>
Then the Notion database ID is the <long_hash_1> part.
Fill in the Page Title Field Name:
If your web page is in English, enter Name
If your web page is in Chinese, enter 名称
Congratulations, your Notion configuration is complete ✅ You can now export content from Cherry Studio to your Notion database.
This document was translated from Chinese by AI and has not yet been reviewed.
ModelScope MCP Server requires upgrading Cherry Studio to v1.2.9 or higher.
In version v1.2.9, Cherry Studio officially partnered with ModelScope, significantly simplifying the process of adding MCP servers. This helps avoid configuration errors and allows you to discover a vast number of MCP servers within the ModelScope community. Follow the steps below to learn how to sync ModelScope's MCP servers in Cherry Studio.
Click on MCP Server Settings in the settings, and select Sync Server.
Select ModelScope and browse to discover MCP services.
Register and log in to ModelScope, and view the MCP service details.
In the MCP service details, select "Connect Service".
Click "Get API Token" in Cherry Studio, which will redirect you to the official ModelScope website. Copy the API token and paste it back into Cherry Studio.
In the MCP server list in Cherry Studio, you can see the MCP service connected from ModelScope and call it in conversations.
For new MCP servers connected on the ModelScope webpage later, simply click Sync Server to add them incrementally.
By following the steps above, you have successfully learned how to easily sync MCP servers from ModelScope in Cherry Studio. The entire configuration process is not only greatly simplified, effectively avoiding the hassle and potential errors of manual configuration, but it also allows you to easily access the vast MCP server resources provided by the ModelScope community.
Start exploring and using these powerful MCP services to bring more convenience and possibilities to your Cherry Studio experience
MCP (Model Context Protocol) is an open-source protocol designed to provide context information to Large Language Models (LLMs) in a standardized way. For more information about MCP, please see
@mcpmarket/mcp-auto-install is an open-source npm package. You can view its detailed information and documentation on the . @mcpmarket is the official collection of MCP services for Cherry Studio.
Log in to
Click
Click on at the bottom of the sidebar.
In the at the bottom of the Ark console sidebar, activate the models you need. You can activate models like the Doubao series and DeepSeek as needed.
In the , find the Model ID corresponding to the desired model.
Open Cherry Studio's settings and find Volcano Engine.
For the difference between endings with / and #, refer to the API Address section in the provider settings documentation, .
Go to the website to create a new integration.
Go to the website and create a new page. Select the database type, name it Cherry Studio, and follow the illustration to connect.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio is a free and open-source project. As the project grows, the workload for the project team has also increased. To reduce communication costs and resolve your issues quickly and efficiently, we hope that you will follow the steps and methods below to handle problems before asking questions. This will allow the project team more time to focus on project maintenance and development. Thank you for your cooperation!
Most basic questions can be solved by carefully reading the documentation.
For questions about the software's features and usage, you can check the Feature Introduction documentation.
Frequently asked questions are collected on the FAQ page. You can check there first for solutions.
For more complex issues, you can try solving them directly by searching or asking in the search bar.
Be sure to carefully read the content in the hint boxes within each document, as this can help you avoid many problems.
Check or search the GitHub Issues page for similar problems and solutions.
For issues unrelated to the client's functionality (such as model errors, unexpected responses, or parameter settings), it is recommended to first search online for relevant solutions or describe the error message and problem to an AI to find a solution.
If the first two steps did not provide an answer or solve your problem, you can describe your issue in detail and seek help in our official Telegram Channel, Discord Channel, or (Click to Join).
If it's a model error, please provide a complete screenshot of the interface and the console error message. You can censor sensitive information, but the model name, parameter settings, and error content must be visible in the screenshot. To learn how to view console error messages, click here.
If it's a software bug, please provide a specific error description and detailed steps to help developers debug and fix it. If it's an intermittent issue that cannot be reproduced, please describe the relevant scenarios, context, and configuration parameters when the problem occurred in as much detail as possible. In addition, you also need to include platform information (Windows, Mac, or Linux) and the software version number in your problem description.
Requesting Documentation or Providing Suggestions
You can contact @Wangmouuu on our Telegram channel or QQ (1355873789), or send an email to: [email protected].












This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio is a multi-model desktop client that currently supports installation packages for Windows, Linux, and macOS. It aggregates mainstream LLM models and provides multi-scenario assistance. Users can improve their work efficiency through intelligent session management, open-source customization, and multi-themed interfaces.
Cherry Studio is now deeply integrated with the PPIO high-performance API channel—ensuring high-speed responses for DeepSeek-R1/V3 and 99.9% service availability through enterprise-grade computing power, bringing you a fast and smooth experience.
The tutorial below provides a complete integration plan (including API key configuration), allowing you to enable the advanced mode of "Cherry Studio Intelligent Scheduling + PPIO High-Performance API" in just 3 minutes.
First, go to the official website to download Cherry Studio: https://cherry-ai.com/download (If you can't access it, you can use the Quark Web Drive link below to download the version you need: https://pan.quark.cn/s/c8533a1ec63e#/list/share
(1) First, click on Settings in the bottom left corner, set the custom provider name to: PPIO, and click "OK"
(2) Go to PPIO Compute Cloud API Key Management, click on your [User Avatar] — [API Key Management] to enter the console
Click the [+ Create] button to create a new API key. Give it a custom name. The generated key is only displayed at the time of creation. Be sure to copy and save it to a document to avoid affecting future use.
(3) In CherryStudio, enter the API key. Click Settings, select [PPIO Cloud], enter the API key generated on the official website, and finally click [Check].
(4) Select the model: For example, deepseek/deepseek-r1/community. If you need to switch to another model, you can do so directly.
The community versions of DeepSeek R1 and V3 are for trial purposes. They are full-parameter models with no difference in stability or performance. For high-volume usage, you must top up your account and switch to a non-community version.
(1) Click [Check]. Once it shows "Connection successful," you can start using it normally.
(2) Finally, click on [@] and select the DeepSeek R1 model you just added under the PPIO provider to start chatting successfully~
[Some materials sourced from: 陈恩]
If you prefer visual learning, we have prepared a video tutorial on Bilibili. This step-by-step guide will help you quickly master the configuration of "PPIO API + Cherry Studio". Click the link below to go directly to the video and start your smooth development experience → 【Still frustrated by DeepSeek's endless loading?】PPIO Cloud + Full-power DeepSeek =? No more congestion, take off now!
[Video material sourced from: sola]
如何在 Cherry Studio 使用联网模式
This document was translated from Chinese by AI and has not yet been reviewed.
In the Cherry Studio question window, click the [Little Globe] icon to enable web search.
Mode 1: The model provider's large model has a built-in web search function
In this case, after enabling web search, you can use the service directly. It's very simple.
You can quickly determine if a model supports web search by checking for a small globe icon next to the model's name at the top of the chat interface.
On the model management page, this method also allows you to quickly distinguish which models support web search and which do not.
Cherry Studio currently supports the following model providers with web search capabilities:
Google Gemini
OpenRouter (all models support web search)
Tencent Hunyuan
Zhipu AI
Alibaba Cloud Bailian, etc.
Special Note:
There is a special case where a model can access the web even without the small globe icon, as explained in the tutorial below.
Mode 2: The model does not have a built-in web search function; use the Tavily service to enable it
When we use a large model without a built-in web search function (no small globe icon next to its name), but we need it to retrieve real-time information for processing, we need to use the Tavily web search service.
When using the Tavily service for the first time, a pop-up will prompt you to configure some settings. Please follow the instructions—it's very simple!
After clicking to get the API key, you will be automatically redirected to the official Tavily website's login/registration page. After registering and logging in, create an API key, then copy the key and paste it into Cherry Studio.
If you don't know how to register, refer to the Tavily web search login and registration tutorial in the same directory as this document.
Tavily registration reference document:
The interface below indicates that the registration was successful.
Let's try again to see the effect. The result shows that the web search is now working correctly, and the number of search results is our default setting: 5.
Note: Tavily has a monthly free usage limit. You will need to pay if you exceed it~~
PS: If you find any errors, please feel free to contact us.
This document was translated from Chinese by AI and has not yet been reviewed.
Go to Huawei Cloud to create an account and log in.
Click this link to enter the Maa S console.
Authorization
Click on Authentication Management in the sidebar, create an API Key (secret key), and copy it.
Then, create a new provider in CherryStudio.
After creation, fill in the secret key.
Click on Model Deployment in the sidebar and claim all models.
Click on Invoke.
Copy the address from ① and paste it into the Provider Address field in CherryStudio, and add a "#" symbol at the end.
And add a "#" symbol at the end.
And add a "#" symbol at the end.
And add a "#" symbol at the end.
And add a "#" symbol at the end.
Why add a "#" symbol? See here
Of course, you can also skip reading that and just follow the tutorial;
You can also fill it in by deleting
v1/chat/completions. As long as you know how to fill it in, any method works. If you don't know how, be sure to follow the tutorial.
Then, copy the model name from ②, and in CherryStudio, click the "+Add" button to create a new model.
Enter the model name. Do not add anything extra or include quotes. Copy it exactly as it is written in the example.
Click the Add Model button to finish adding.
This document was translated from Chinese by AI and has not yet been reviewed.
In version 0.9.1, CherryStudio introduced the long-awaited knowledge base feature.
Below, we will provide detailed instructions for using CherryStudio step-by-step.
In the Model Management service, find a model. You can click "Embedding Model" to filter quickly;
Find the model you need and add it to "My Models".
Knowledge Base Entry: On the left toolbar of CherryStudio, click the knowledge base icon to enter the management page;
Add Knowledge Base: Click "Add" to start creating a knowledge base;
Naming: Enter a name for the knowledge base and add an embedding model, for example, bge-m3, to complete the creation.
Add Files: Click the "Add Files" button to open the file selector;
Select Files: Choose supported file formats like pdf, docx, pptx, xlsx, txt, md, mdx, etc., and open them;
Vectorization: The system will automatically perform vectorization. When it shows "Completed" (green ✓), it means vectorization is finished.
CherryStudio supports adding data in multiple ways:
Folder Directory: You can add an entire folder directory. Files in supported formats within this directory will be automatically vectorized;
URL Link: Supports website URLs, such as https://docs.siliconflow.cn/introduction;
Sitemap: Supports XML-formatted sitemaps, such as https://docs.siliconflow.cn/sitemap.xml;
Plain Text Note: Supports inputting custom content as plain text.
Once files and other materials have been vectorized, you can start querying:
Click the "Search Knowledge Base" button at the bottom of the page;
Enter your query;
The search results will be displayed;
And the match score for each result will be shown.
Create a new topic. In the conversation toolbar, click on the knowledge base icon. A list of created knowledge bases will expand. Select the one you want to reference;
Enter and send your question. The model will return an answer generated from the search results;
Additionally, the referenced data sources will be attached below the answer, allowing for quick access to the source files.
This document was translated from Chinese by AI and has not yet been reviewed.
This interface allows you to perform operations such as cloud and local backup of client data, querying the local data directory, and clearing the cache.
Currently, data backup only supports WebDAV. You can choose a service that supports WebDAV for cloud backup.
Taking Jianguoyun as an Example
Log in to Jianguoyun, click on the username in the upper right corner, and select "Account Info":
Select "Security Options" and click "Add Application"
Enter the application name and generate a random password;
Copy and save the password;
Obtain the server address, account, and password;
In Cherry Studio Settings -> Data Settings, fill in the WebDAV information;
Choose to back up or restore data, and you can set the automatic backup time interval.
Generally, the easiest WebDAV services to get started with are cloud storage providers:
123Pan (Requires membership)
Aliyun Drive (Requires purchase)
Box (Free space is 10GB, single file size limit is 250MB.)
Dropbox (Dropbox offers 2GB for free, and you can get up to 16GB by inviting friends.)
TeraCloud (Free space is 10GB, and an additional 5GB can be obtained through referrals.)
Yandex Disk (Provides 10GB of capacity for free users.)
Next are some services that you need to deploy yourself:
如何注册tavily?
This document was translated from Chinese by AI and has not yet been reviewed.
Visit the official website mentioned above, or go to Cherry Studio -> Settings -> Web Search and click "Get API Key". This will redirect you to the Tavily login/registration page.
If this is your first time, you need to Sign up for an account before you can Log in. Note that the page defaults to the login page.
Click to sign up for an account to enter the following interface. Enter your commonly used email address, or use your Google/GitHub account. Then, enter your password in the next step. This is a standard procedure.
🚨🚨🚨[Crucial Step] After successful registration, there will be a dynamic verification code step. You need to scan a QR code to generate a one-time code to continue.
It's very simple. You have two options at this point.
Download an authenticator app, like Microsoft Authenticator. [Slightly more complicated]
Use the WeChat Mini Program: 腾讯身份验证器. [Simple, anyone can do it, recommended]
Open the WeChat Mini Program and search for: 腾讯身份验证器
After completing the steps above, you will see the interface below, which means your registration was successful. Copy the key to Cherry Studio, and you can start using it happily.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio not only integrates mainstream AI model services but also gives you powerful customization capabilities. With the Custom AI Provider feature, you can easily connect to any AI model you need.
Flexibility: No longer limited to the preset list of providers, you are free to choose the AI model that best suits your needs.
Diversity: Experiment with AI models from various platforms to discover their unique advantages.
Controllability: Directly manage your API keys and access addresses to ensure security and privacy.
Customization: Integrate privately deployed models to meet the needs of specific business scenarios.
You can add your custom AI provider in Cherry Studio in just a few simple steps:
Open Settings: In the left navigation bar of the Cherry Studio interface, click "Settings" (the gear icon).
Go to Model Services: On the settings page, select the "Model Services" tab.
Add Provider: On the "Model Services" page, you will see a list of existing providers. Click the "+ Add" button below the list to open the "Add Provider" pop-up window.
Fill in Information: In the pop-up window, you need to fill in the following information:
Provider Name: Give your custom provider an easily recognizable name (e.g., MyCustomOpenAI).
Provider Type: Select your provider type from the drop-down list. Currently supported types are:
OpenAI
Gemini
Anthropic
Azure OpenAI
Save Configuration: After filling in the information, click the "Add" button to save your configuration.
After adding a provider, you need to find it in the list and configure its details:
Enable Status: On the far right of the custom provider list, there is an enable switch. Turning it on enables this custom service.
API Key:
Fill in the API Key provided by your AI service provider.
Click the "Check" button on the right to verify the key's validity.
API Address:
Fill in the API access address (Base URL) for the AI service.
Be sure to refer to the official documentation provided by your AI service provider to get the correct API address.
Model Management:
Click the "+ Add" button to manually add the model IDs you want to use under this provider, such as gpt-3.5-turbo, gemini-pro, etc.
If you are unsure of the specific model names, please refer to the official documentation provided by your AI service provider.
Click the "Manage" button to edit or delete the models that have been added.
After completing the above configuration, you can select your custom AI provider and model in the Cherry Studio chat interface and start conversing with the AI!
vLLM is a fast and easy-to-use LLM inference library, similar to Ollama. Here are the steps to integrate vLLM into Cherry Studio:
Start the vLLM Service: Start the service using the OpenAI-compatible interface provided by vLLM. There are two main ways to do this:
Start using vllm.entrypoints.openai.api_server
Start using uvicorn
Ensure the service starts successfully and listens on the default port 8000. Of course, you can also specify the port number for the vLLM service using the --port parameter.
Add vLLM Provider in Cherry Studio:
Follow the steps described earlier to add a new custom AI provider in Cherry Studio.
Provider Name: vLLM
Provider Type: Select OpenAI.
Configure vLLM Provider:
API Key: Since vLLM does not require an API key, you can leave this field blank or fill in any content.
API Address: Fill in the API address of the vLLM service. By default, the address is: http://localhost:8000/ (if you use a different port, please modify it accordingly).
Model Management: Add the model name you loaded in vLLM. In the example python -m vllm.entrypoints.openai.api_server --model gpt2 above, you should enter gpt2 here.
Start Chatting: Now, you can select the vLLM provider and the gpt2 model in Cherry Studio and start chatting with the vLLM-powered LLM!
Read the Documentation Carefully: Before adding a custom provider, be sure to carefully read the official documentation of the AI service provider you are using to understand key information such as API keys, access addresses, and model names.
Check the API Key: Use the "Check" button to quickly verify the validity of the API key to avoid issues caused by an incorrect key.
Pay Attention to the API Address: The API address may vary for different AI service providers and models. Be sure to fill in the correct address.
Add Models On-Demand: Please only add the models you will actually use to avoid adding too many unnecessary models.
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio's data storage follows system specifications, and data is automatically placed in the user's directory. The specific directory locations are as follows:
macOS: /Users/username/Library/Application Support/CherryStudioDev
Windows: C:\Users\username\AppData\Roaming\CherryStudio
Linux: /home/username/.config/CherryStudio
You can also check the location here:
Method 1:
This can be achieved by creating a symbolic link. Exit the application, move the data to your desired location, and then create a link at the original location pointing to the new location.
Method 2: Based on the characteristics of Electron applications, you can modify the storage location by configuring launch parameters.
--user-data-dir e.g.: Cherry-Studio-*-x64-portable.exe --user-data-dir="%user_data_dir%"
Example:
init_cherry_studio.bat (encoding: ANSI)
Directory structure of user-data-dir after initialization:
This document was translated from Chinese by AI and has not yet been reviewed.
Tokens are the basic units that AI models use to process text. You can think of them as the smallest unit of "thought" for the model. They are not exactly equivalent to characters or words as we understand them, but rather a special way the model segments text.
1. Chinese Tokenization
A Chinese character is usually encoded as 1-2 tokens.
For example: "你好" ≈ 2-4 tokens
2. English Tokenization
Common words are usually 1 token.
Longer or less common words are broken down into multiple tokens.
For example:
"hello" = 1 token
"indescribable" = 4 tokens
3. Special Characters
Spaces, punctuation marks, etc., also consume tokens.
A newline character is usually 1 token.
A Tokenizer is the tool an AI model uses to convert text into tokens. It determines how to split the input text into the smallest units that the model can understand.
1. Different Training Data
Different corpora lead to different optimization directions.
Varying degrees of multilingual support.
Specialized optimizations for specific domains (e.g., medical, legal).
2. Different Tokenization Algorithms
BPE (Byte Pair Encoding) - OpenAI GPT series
WordPiece - Google BERT
SentencePiece - Suitable for multilingual scenarios
3. Different Optimization Goals
Some focus on compression efficiency.
Some focus on semantic preservation.
Some focus on processing speed.
The same text may have a different number of tokens in different models:
Basic Concept: An embedding model is a technique that converts high-dimensional discrete data (text, images, etc.) into low-dimensional continuous vectors. This transformation allows machines to better understand and process complex data. Imagine it as simplifying a complex puzzle into a simple coordinate point that still retains the key features of the puzzle. In the large model ecosystem, it acts as a "translator," converting human-understandable information into a numerical form that AI can compute.
How it Works: Taking natural language processing as an example, an embedding model can map words to specific positions in a vector space. In this space, words with similar meanings will automatically cluster together. For example:
The vectors for "king" and "queen" will be very close.
Pet-related words like "cat" and "dog" will also be near each other.
Words with unrelated meanings, like "car" and "bread," will be far apart.
Main Application Scenarios:
Text analysis: document classification, sentiment analysis
Recommendation systems: personalized content recommendations
Image processing: similar image retrieval
Search engines: semantic search optimization
Core Advantages:
Dimensionality Reduction: Simplifies complex data into easy-to-process vector form.
Semantic Preservation: Retains key semantic information from the original data.
Computational Efficiency: Significantly improves the training and inference efficiency of machine learning models.
Technical Value: Embedding models are fundamental components of modern AI systems. They provide high-quality data representations for machine learning tasks and are a key technology driving progress in fields like natural language processing and computer vision.
Basic Workflow:
Knowledge Base Preprocessing Stage
Split documents into appropriately sized chunks.
Use an embedding model to convert each chunk into a vector.
Store the vectors and the original text in a vector database.
Query Processing Stage
Convert the user's question into a vector.
Retrieve similar content from the vector database.
Provide the retrieved relevant content to the LLM as context.
MCP is an open-source protocol designed to provide contextual information to Large Language Models (LLMs) in a standardized way.
Analogy: You can think of MCP as the "USB drive" of the AI world. We know that a USB drive can store various files and be used directly after being plugged into a computer. Similarly, various "plugins" that provide context can be "plugged" into an MCP Server. An LLM can request these plugins from the MCP Server as needed to obtain richer contextual information and enhance its capabilities.
Comparison with Function Tools: Traditional Function Tools can also provide external functionalities for LLMs, but MCP is more like a higher-dimensional abstraction. A Function Tool is more of a tool for specific tasks, whereas MCP provides a more general, modular mechanism for acquiring context.
Standardization: MCP provides a unified interface and data format, allowing different LLMs and context providers to collaborate seamlessly.
Modularity: MCP allows developers to break down contextual information into independent modules (plugins), making them easier to manage and reuse.
Flexibility: LLMs can dynamically select the required context plugins based on their needs, enabling more intelligent and personalized interactions.
Extensibility: MCP's design supports the future addition of more types of context plugins, offering limitless possibilities for expanding the capabilities of LLMs.
This document was translated from Chinese by AI and has not yet been reviewed.
Knowledge base document preprocessing requires upgrading Cherry Studio to v1.5.0 or higher.
After clicking 'Get API KEY', the application URL will open in your browser. Click 'Apply Now', fill out the form to get the API KEY, and then enter it into the API KEY field.
Configure the created knowledge base as shown above to complete the knowledge base document preprocessing setup.
You can check the knowledge base results by using the search in the upper right corner.
Knowledge Base Tips: When using a more capable model, you can change the knowledge base search mode to intent recognition. Intent recognition can describe your questions more accurately and broadly.
You can also synchronize data across multiple devices by following the process: Computer A WebDAV Computer B.
Install vLLM: Install vLLM by following the official vLLM documentation ().
For specific steps, please refer to:
For more theme variables, please refer to the source code:
Cherry Studio Theme Library:
Share some Chinese-style Cherry Studio theme skins:








This document was translated from Chinese by AI and has not yet been reviewed.
By using or distributing any part or element of the Cherry Studio Materials, you will be deemed to have acknowledged and accepted the content of this Agreement, which shall become effective immediately.
This Cherry Studio License Agreement (hereinafter referred to as the “Agreement”) shall mean the terms and conditions for use, reproduction, distribution, and modification of the Materials as defined by this Agreement.
“We” (or “Us”) shall mean Shanghai Qianhui Technology Co., Ltd.
“You” (or “Your”) shall mean a natural person or legal entity exercising the rights granted by this Agreement, and/or using the Materials for any purpose and in any field of use.
“Third Party” shall mean an individual or legal entity that does not have common control with either Us or You.
“Cherry Studio” shall mean this software suite, including but not limited to [e.g., core libraries, editors, plugins, sample projects], as well as source code, documentation, sample code, and other elements of the foregoing distributed by Us. (Please describe in detail according to the actual composition of Cherry Studio)
“Materials” shall collectively refer to the proprietary Cherry Studio and documentation (and any part thereof) of Shanghai Qianhui Technology Co., Ltd., provided under this Agreement.
“Source” form shall mean the preferred form for making modifications, including but not limited to source code, documentation source files, and configuration files.
“Object” form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
“Commercial Use” means for the purpose of direct or indirect commercial gain or commercial advantage, including but not limited to sales, licensing, subscriptions, advertising, marketing, training, consulting services, etc.
“Modification” means any change, adjustment, derivation, or secondary development of the Source form of the Materials, including but not limited to modifying the application name, logo, code, functionality, interface, etc.
Free Commercial Use (Limited to Unmodified Code): We hereby grant You a non-exclusive, worldwide, non-transferable, royalty-free license, under the intellectual property or other rights owned by Us or embodied in the Materials, to use, reproduce, distribute, copy, and distribute the unmodified Materials, including for Commercial Use, subject to the terms and conditions of this Agreement.
Commercial License (When Required): When the conditions described in Section III “Commercial License” are met, you must obtain an explicit written commercial license from Us to exercise the rights under this Agreement.
In any of the following situations, you must contact Us and obtain an explicit written commercial license before you can continue to use the Cherry Studio Materials:
Modification and Derivation: You modify the Cherry Studio Materials or develop derivatives based on them (including but not limited to modifying the application name, logo, code, functionality, interface, etc.).
Enterprise Services: Providing services based on Cherry Studio within your enterprise or to enterprise customers, where such service supports 10 or more cumulative users.
Hardware Bundling: You pre-install or integrate Cherry Studio into hardware devices or products for bundled sales.
Large-Scale Procurement by Government or Educational Institutions: Your use case is part of a large-scale procurement project by a government or educational institution, especially when it involves sensitive requirements such as security and data privacy.
Public-Facing Cloud Services: Providing public-facing cloud services based on Cherry Studio.
You may distribute copies of the unmodified Materials, or provide them as part of a product or service that includes the unmodified Materials, in Source or Object form, provided that You meet the following conditions:
You must provide a copy of this Agreement to any other recipient of the Materials;
You must, in all copies of the Materials that you distribute, retain the following attribution notice and place it in a “NOTICE” or similar text file distributed as part of such copies: `"Cherry Studio is licensed under the Cherry Studio LICENSE AGREEMENT, Copyright (c) 上海千彗科技有限公司. All Rights Reserved."` (Cherry Studio is licensed under the Cherry Studio License Agreement, Copyright (c) 上海千彗科技有限公司. All rights reserved.)
The Materials may be subject to export controls or restrictions. You shall comply with applicable laws and regulations when using the Materials.
If You use the Materials or any of their outputs or results to create, train, fine-tune, or improve software or models that will be distributed or provided, We encourage You to prominently display “Built with Cherry Studio” or “Powered by Cherry Studio” in the relevant product documentation.
We retain all intellectual property rights in and to the Materials and derivative works made by or for Us. Subject to the terms and conditions of this Agreement, the ownership of intellectual property rights for modifications and derivative works of the Materials made by You will be stipulated in a specific commercial license agreement. Without obtaining a commercial license, You do not own the rights to your modifications and derivative works of the Materials, and their intellectual property rights remain with Us.
No trademark license is granted to use Our trade names, trademarks, service marks, or product names, except as required for reasonable and customary use in describing and redistributing the Materials or as required to fulfill the notice obligations under this Agreement.
If You initiate a lawsuit or other legal proceeding (including a counterclaim or cross-claim in a lawsuit) against Us or any entity, alleging that the Materials or any of its outputs, or any portion of the foregoing, infringes any intellectual property or other rights owned or licensable by You, then all licenses granted to You under this Agreement shall terminate as of the date such lawsuit or other legal proceeding is initiated or filed.
We have no obligation to support, update, provide training for, or develop any further versions of the Cherry Studio Materials, nor to grant any related licenses.
The Materials are provided "as is" without any warranty of any kind, either express or implied, including warranties of merchantability, non-infringement, or fitness for a particular purpose. We make no warranty and assume no responsibility for the security or stability of the Materials and their outputs.
In no event shall We be liable to You for any damages, including but not limited to any direct, indirect, special, or consequential damages, arising out of your use or inability to use the Materials or any of their outputs, however caused.
You will defend, indemnify, and hold Us harmless from any claims by any third party arising out of or related to your use or distribution of the Materials.
The term of this Agreement shall commence upon your acceptance of this Agreement or your access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions of this Agreement.
We may terminate this Agreement if You breach any of its terms or conditions. Upon termination of this Agreement, You must cease using the Materials. Section VII, Section IX, and "II. Contributor Agreement" shall survive the termination of this Agreement.
This Agreement and any dispute arising from or related to this Agreement shall be governed by the laws of China.
The Shanghai People's Court shall have exclusive jurisdiction over any dispute arising from this Agreement.









数据设置→Obsidian配置
This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio supports integration with Obsidian, allowing you to export entire conversations or single messages to your Obsidian vault.
This process does not require installing any additional Obsidian plugins. However, since Cherry Studio's import mechanism is similar to the Obsidian Web Clipper, it's recommended to upgrade Obsidian to the latest version (at least greater than 1.7.2) to avoid import failures with long conversations.
Open Cherry Studio's Settings → Data Settings → Obsidian Configuration menu. The dropdown will automatically list the Obsidian vaults that have been opened on your machine. Select your target Obsidian vault:
Exporting an Entire Conversation
Go back to the conversation interface in Cherry Studio, right-click on the conversation, select Export, and click Export to Obsidian:
A window will pop up, allowing you to adjust the Properties, the folder location in Obsidian, and the handling method for the exported note:
Vault: Click the dropdown menu to select other Obsidian vaults
Path: Click the dropdown menu to select the folder where the exported note will be stored
As Obsidian note properties (Properties):
Tags (tags)
Creation time (created)
Source (source)
There are three handling methods for exporting to Obsidian:
There are three handling methods for exporting to Obsidian:
Create new (overwrite if exists): Creates a new note in the folder specified in the Path. If a note with the same name already exists, it will be overwritten.
Prepend: If a note with the same name exists, the selected conversation content will be prepended to the beginning of that note.
Append: If a note with the same name exists, the selected conversation content will be appended to the end of that note.
After selecting all options, click OK to export the entire conversation to the corresponding folder in the specified Obsidian vault.
Exporting a Single Message
To export a single message, click the three-bar menu below the message, select Export, and click Export to Obsidian:
A window similar to the one for exporting an entire conversation will appear, asking you to configure the note properties and handling method. Follow the tutorial above to complete the process.
🎉 Congratulations! You have now completed all the configurations for integrating Cherry Studio with Obsidian and have gone through the entire export process. Enjoy!
Open your Obsidian vault and create a folder to save the exported conversations (the example in the image uses a folder named "Cherry Studio"):
Take note of the text in the bottom-left corner; this is your vault name.
In Cherry Studio's Settings → Data Settings → Obsidian Configuration menu, enter the vault name and folder name you noted in Step 1:
The Global Tags field is optional. You can set tags that will be applied to all exported conversations in Obsidian. Fill it in as needed.
Exporting an Entire Conversation
Go back to the conversation interface in Cherry Studio, right-click on the conversation, select Export, and click Export to Obsidian.
A window will pop up, allowing you to adjust the Properties for the exported note and the handling method. There are three handling methods for exporting to Obsidian:
Create new (overwrite if exists): Creates a new note in the folder you specified in Step 2. If a note with the same name already exists, it will be overwritten.
Prepend: If a note with the same name exists, the selected conversation content will be prepended to the beginning of that note.
Append: If a note with the same name exists, the selected conversation content will be appended to the end of that note.
Exporting a Single Message
To export a single message, click the three-bar menu below the message, select Export, and click Export to Obsidian.
A window similar to the one for exporting an entire conversation will appear, asking you to configure the note properties and handling method. Follow the tutorial above to complete the process.
🎉 Congratulations! You have now completed all the configurations for integrating Cherry Studio with Obsidian and have gone through the entire export process. Enjoy!
This document was translated from Chinese by AI and has not yet been reviewed.
Before obtaining a Gemini API key, you need to have a Google Cloud project (if you already have one, you can skip this process).
Go to Google Cloud to create a project, fill in the project name, and click Create Project.
On the official API Key page, click Create API key.
Copy the generated key and open the Provider Settings in CherryStudio.
Find the Gemini provider and paste the key you just obtained.
Click Manage or Add at the bottom, add the supported models, and enable the provider switch in the top right corner to start using it.

Monaspace
English Font Commercial Use
GitHub has launched an open-source font family called Monaspace, which offers five styles: Neon (modern), Argon (humanist), Xenon (serif), Radon (handwriting), and Krypton (mechanical).
MiSans Global
Multilingual Commercial Use
MiSans Global is a global font customization project led by Xiaomi, in collaboration with Monotype and Hanyi Fonts.
This is a vast font family, covering over 20 writing systems and supporting more than 600 languages.






















This document was translated from Chinese by AI and has not yet been reviewed.
Cherry Studio's translation feature provides you with fast and accurate text translation services, supporting mutual translation between multiple languages.
The translation interface mainly consists of the following parts:
Source Language Selection Area:
Any Language: Cherry Studio will automatically detect the source language and translate it.
Target Language Selection Area:
Dropdown Menu: Select the language you want to translate the text into.
Settings Button:
Clicking it will take you to the Default Model Settings.
Scroll Sync:
Click to toggle scroll sync (scrolling on one side will also scroll the other side).
Text Input Box (Left):
Enter or paste the text you need to translate.
Translation Result Box (Right):
Displays the translated text.
Copy Button: Click the button to copy the translation result to the clipboard.
Translate Button:
Click this button to start the translation.
Translation History (Top Left):
Click to view the translation history.
Select the Target Language:
In the target language selection area, choose the language you want to translate into.
Enter or Paste Text:
Enter or paste the text you want to translate into the text input box on the left.
Start Translation:
Click the Translate button.
View and Copy the Result:
The translation result will be displayed in the result box on the right.
Click the copy button to copy the translation result to the clipboard.
Q: What should I do if the translation is inaccurate?
A: While AI translation is powerful, it is not perfect. For professional fields or texts with complex context, manual proofreading is recommended. You can also try switching to different models.
Q: Which languages are supported?
A: The Cherry Studio translation feature supports various major languages. For a specific list of supported languages, please refer to the official Cherry Studio website or in-app instructions.
Q: Can I translate an entire file?
A: The current interface is primarily for text translation. For file translation, you may need to go to the Cherry Studio chat page and add the file to translate it.
Q: What if the translation speed is slow?
A: Translation speed can be affected by factors such as network connection, text length, and server load. Please ensure your network connection is stable and wait patiently.
This document was translated from Chinese by AI and has not yet been reviewed.
4xx (Client Error Status Codes): Generally indicate that the request cannot be completed due to a syntax error, authorization failure, or authentication failure.
5xx (Server Error Status Codes): Generally indicate a server-side error, such as the server being down, or the request processing timing out.
After clicking the Cherry Studio client window, press the shortcut key Ctrl + Shift + I (for Mac: Command + Option + I)
In the pop-up console window, click Network → click to view the last item in section ② marked with a red ×, which will be completions (for errors in conversations, translations, model connectivity checks, etc.) or generations (for errors in painting) → click Response to view the full returned content (area ④ in the figure).
This inspection method can be used not only to obtain error information during conversations, but also during model testing, adding knowledge bases, painting, etc. In any case, you need to open the debugging window first, and then perform the request operation to obtain the request information.
If the formula code is displayed directly instead of being rendered, check if the formula has delimiters.
Delimiter Usage
Inline formulas
Use single dollar signs:
$formula$Or use
\(and\), like:\(formula\)Block formulas
Use double dollar signs:
$$formula$$Or use
\[formula\]
Formula rendering errors/garbled text are common when the formula contains Chinese content. Try switching the formula engine to KateX.
Model status is unavailable
Confirm whether the service provider supports the model or if the model's service status is normal.
A non-embedding model was used.
First, you need to confirm if the model supports image recognition. Cherry Studio categorizes popular models; those with a small eye icon next to their name support image recognition.
Image recognition models support uploading image files. If the model's functionality is not correctly matched, you can find the model in the corresponding service provider's model list, click the settings button after its name, and check the image option.
For specific model information, you can check the details from the corresponding service provider. Similar to embedding models, models that do not support vision do not need to have the image function forced on; checking the image option will have no effect.
This document was translated from Chinese by AI and has not yet been reviewed.
Ollama is an excellent open-source tool that allows you to easily run and manage various Large Language Models (LLMs) locally. Cherry Studio now supports Ollama integration, enabling you to interact directly with locally deployed LLMs in a familiar interface, without relying on cloud services!
Ollama is a tool that simplifies the deployment and use of Large Language Models (LLMs). It has the following features:
Local Execution: Models run entirely on your local computer, without needing an internet connection, protecting your privacy and data security.
Easy to Use: Download, run, and manage various LLMs with simple command-line instructions.
Rich Model Library: Supports many popular open-source models like Llama 2, Deepseek, Mistral, and Gemma.
Cross-Platform: Supports macOS, Windows, and Linux systems.
Open API: Supports an OpenAI-compatible interface, allowing integration with other tools.
No Cloud Services Needed: No longer limited by cloud API quotas and fees. Enjoy the full power of local LLMs.
Data Privacy: All your conversation data remains on your local machine, eliminating concerns about privacy leaks.
Offline Availability: Continue interacting with LLMs even without an internet connection.
Customization: Choose and configure the LLMs that best suit your needs.
First, you need to install and run Ollama on your computer. Follow these steps:
Install Ollama: Follow the installer's instructions to complete the installation.
Download a Model: Open your terminal (or command prompt) and use the ollama run command to download the model you want to use. For example, to download the Llama 3.2 model, run:
Ollama will automatically download and run the model.
Keep Ollama Running: Ensure that Ollama remains running while you are interacting with Ollama models through Cherry Studio.
Next, add Ollama as a custom AI provider in Cherry Studio:
Open Settings: In the left navigation bar of the Cherry Studio interface, click on "Settings" (the gear icon).
Go to Model Services: On the settings page, select the "Model Services" tab.
Add Provider: Click on Ollama in the list.
Find the newly added Ollama in the provider list and configure its details:
Enable Status:
Ensure the switch on the far right of the Ollama provider is turned on, indicating it is enabled.
API Key:
Ollama does not require an API key by default. You can leave this field blank or fill it with any content.
API Endpoint:
Enter the local API address provided by Ollama. Typically, the address is:
If you have changed the port, please modify it accordingly.
Keep-Alive Time: This option sets the session keep-alive duration in minutes. If there are no new conversations within the set time, Cherry Studio will automatically disconnect from Ollama to release resources.
Model Management:
Click the "+ Add" button to manually add the names of the models you have already downloaded in Ollama.
For example, if you have already downloaded the llama3.2 model using ollama run llama3.2, you can enter llama3.2 here.
Click the "Manage" button to edit or delete the added models.
Once the configuration is complete, you can select the Ollama provider and your downloaded model in the Cherry Studio chat interface to start conversing with your local LLM!
First Model Run: When running a model for the first time, Ollama needs to download the model file, which may take some time. Please be patient.
View Available Models: Run the ollama list command in the terminal to see a list of the Ollama models you have downloaded.
Hardware Requirements: Running large language models requires certain computing resources (CPU, memory, GPU). Please ensure your computer's configuration meets the model's requirements.
Ollama Documentation: You can click the View Ollama documentation and models link on the configuration page to quickly navigate to the official Ollama documentation.
If you cannot determine the cause of the error, please send a screenshot of this interface to the for help.
Example: $$\sum_{i=1}^n x_i$$
Download Ollama: Visit the official Ollama website () and download the appropriate installer for your operating system. On Linux, you can install Ollama directly with the following command:
400
Incorrect request body format, etc.
Check the error message returned in the conversation or view the error content in the console, and follow the prompts.
[Common Case 1]: If it's a Gemini model, you may need to link a credit card; [Common Case 2]: Data size exceeds the limit, common with vision models. This error code is returned if the image size exceeds the upstream's single request traffic limit; [Common Case 3]: Added unsupported parameters or filled in parameters incorrectly. Try creating a new, clean assistant to test if it works normally; [Common Case 4]: Context exceeds the limit. Clear the context, start a new conversation, or reduce the number of context messages.
401
Authentication failed: The model is not supported or the server-side account is banned, etc.
Contact or check the status of the corresponding service provider's account.
403
No permission for the requested operation.
Perform the corresponding action based on the error message returned in the conversation or the error message in the console.
404
Cannot find the requested resource.
Check the request path, etc.
422
The request format is correct, but there is a semantic error.
The server can parse this type of error but cannot process it. Commonly occurs with JSON semantic errors (e.g., null values; a value required to be a string is written as a number or boolean, etc.).
429
Request rate has reached the limit.
The request rate (TPM or RPM) has reached the limit. Take a break and try again later.
500
Internal server error, unable to complete the request.
If it persists, contact the upstream service provider.
501
The server does not support the functionality required to fulfill the request.
502
The server, while acting as a gateway or proxy, received an invalid response from an inbound server it accessed in attempting to fulfill the request.
503
The server is temporarily unable to handle the client's request due to overload or system maintenance. The length of the delay may be included in the server's Retry-After header.
504
The server, acting as a gateway or proxy, did not receive a timely response from the upstream server.
















This document was translated from Chinese by AI and has not yet been reviewed.
Official Model Information Reference
Doubao-embedding
4095
Doubao-embedding-vision
8191
Doubao-embedding-large
4095
Official Model Information Reference
text-embedding-v3
8192
text-embedding-v2
2048
text-embedding-v1
2048
text-embedding-async-v2
2048
text-embedding-async-v1
2048
Official Model Information Reference
text-embedding-3-small
8191
text-embedding-3-large
8191
text-embedding-ada-002
8191
Official Model Information Reference
Embedding-V1
384
tao-8k
8192
Official Model Information Reference
embedding-2
1024
embedding-3
2048
Official Model Information Reference
hunyuan-embedding
1024
Official Model Information Reference
Baichuan-Text-Embedding
512
Official Model Information Reference
M2-BERT-80M-2K-Retrieval
2048
M2-BERT-80M-8K-Retrieval
8192
M2-BERT-80M-32K-Retrieval
32768
UAE-Large-v1
512
BGE-Large-EN-v1.5
512
BGE-Base-EN-v1.5
512
Official Model Information Reference
jina-embedding-b-en-v1
512
jina-embeddings-v2-base-en
8191
jina-embeddings-v2-base-zh
8191
jina-embeddings-v2-base-de
8191
jina-embeddings-v2-base-code
8191
jina-embeddings-v2-base-es
8191
jina-colbert-v1-en
8191
jina-reranker-v1-base-en
8191
jina-reranker-v1-turbo-en
8191
jina-reranker-v1-tiny-en
8191
jina-clip-v1
8191
jina-reranker-v2-base-multilingual
8191
reader-lm-1.5b
256000
reader-lm-0.5b
256000
jina-colbert-v2
8191
jina-embeddings-v3
8191
Official Model Information Reference
BAAI/bge-m3
8191
netease-youdao/bce-embedding-base_v1
512
BAAI/bge-large-zh-v1.5
512
BAAI/bge-large-en-v1.5
512
Pro/BAAI/bge-m3
8191
Official Model Information Reference
text-embedding-004
2048
Official Model Information Reference
nomic-embed-text-v1
8192
nomic-embed-text-v1.5
8192
gte-multilingual-base
8192
Official Model Information Reference
embedding-query
4000
embedding-passage
4000
Official Model Information Reference
embed-english-v3.0
512
embed-english-light-v3.0
512
embed-multilingual-v3.0
512
embed-multilingual-light-v3.0
512
embed-english-v2.0
512
embed-english-light-v2.0
512
embed-multilingual-v2.0
256
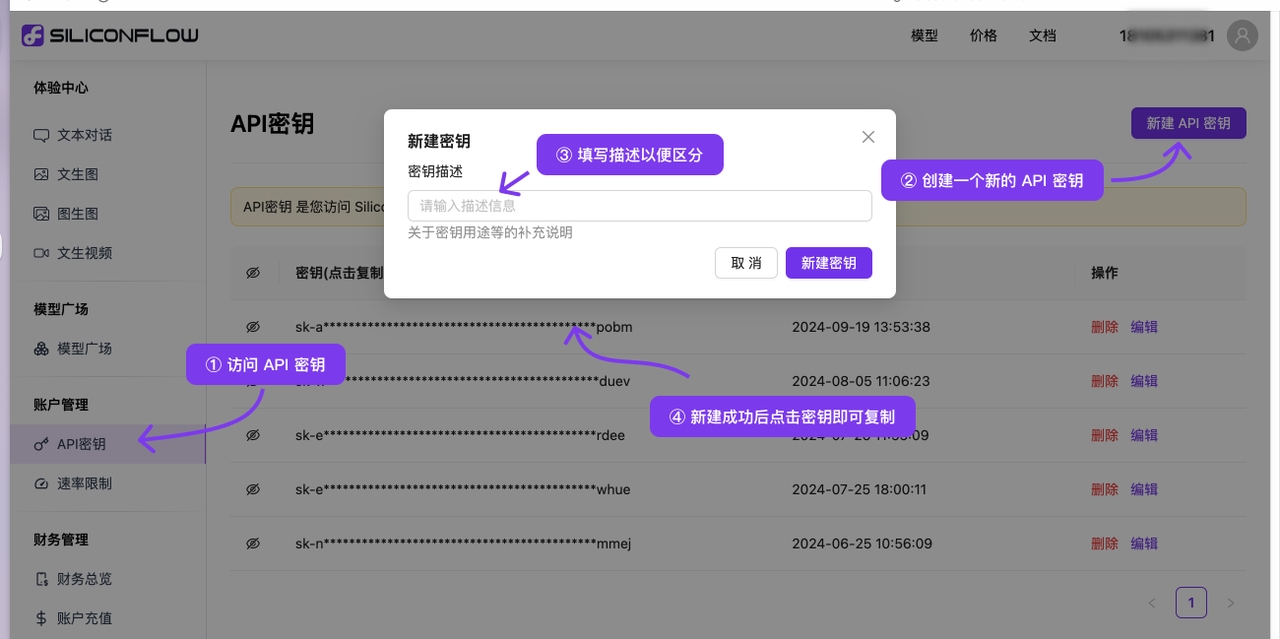








































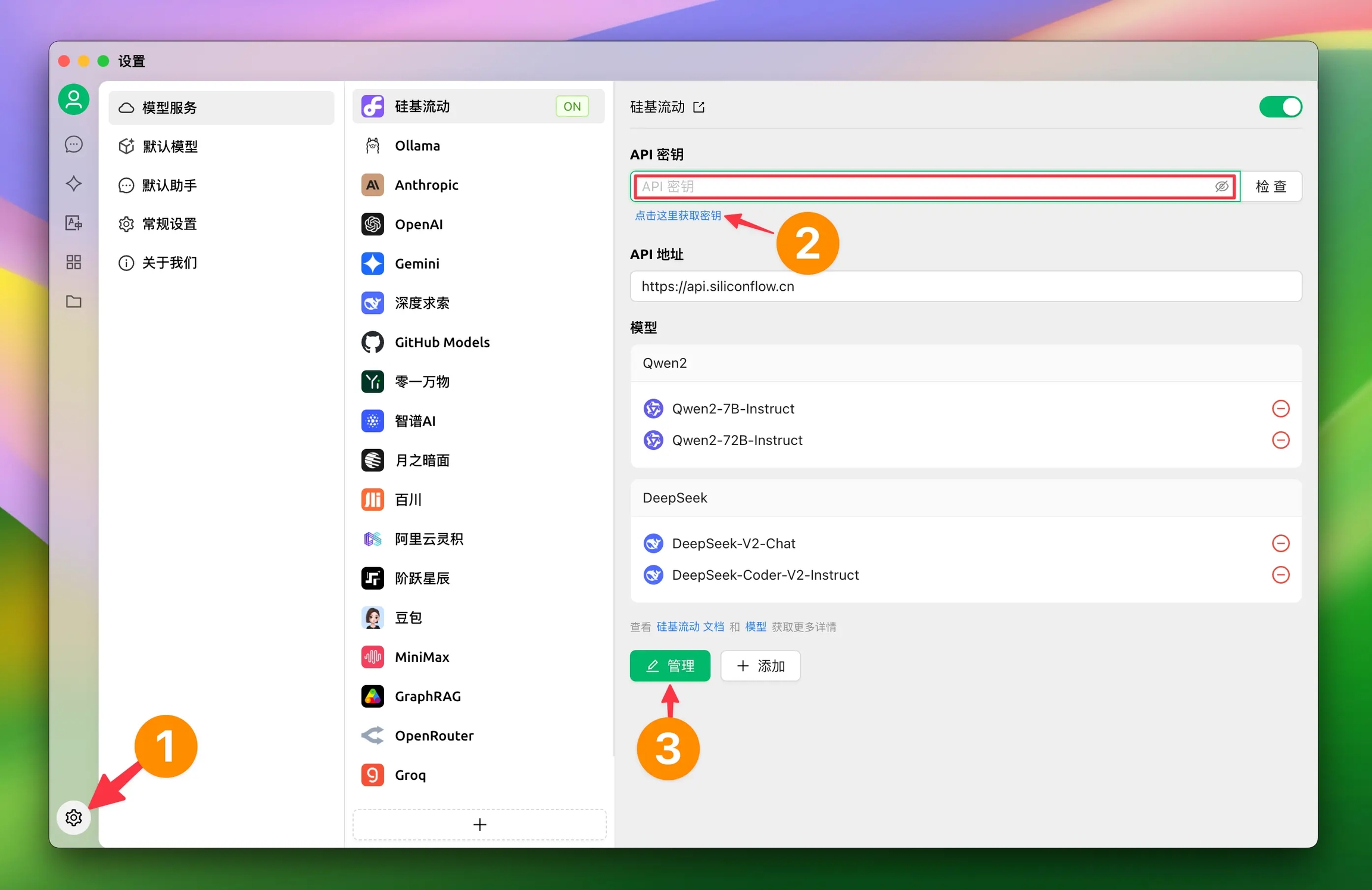


































This document was translated from Chinese by AI and has not yet been reviewed.
An Assistant is a personalized configuration of a selected model, including settings like prompt presets and parameter presets. These settings allow the selected model to better meet your expected work requirements.
The System Default Assistant has a fairly general parameter preset (no prompt), which you can use directly or go to the Agent Page to find a preset that suits your needs.
An Assistant is a parent set to a Topic. Multiple topics (i.e., conversations) can be created under a single assistant. All Topics share the Assistant's parameter settings, preset words (prompt), and other model settings.
Model settings are synchronized with the Model Settings parameters in the assistant settings. For details, see Assistant Settings.
Message Divider:
Separates the message body from the action bar with a divider.
Use Serif Font:
Switches the font style. You can now also change the font via custom CSS.
Show Line Numbers in Code:
Displays line numbers in code blocks when the model outputs code snippets.
Collapsible Code Blocks:
When enabled, long code snippets will be automatically collapsed.
Wrap Lines in Code Blocks:
When enabled, long single lines of code (exceeding the window) will automatically wrap.
Auto-collapse Thinking Process:
When enabled, models that support showing their thinking process will automatically collapse it after completion.
Message Style:
You can switch the chat interface to either bubble style or list style.
Code Style:
You can switch the display style of code snippets.
Math Formula Engine:
KaTeX renders faster as it is specifically designed for performance optimization.
MathJax renders slower but is more feature-complete, supporting more mathematical symbols and commands.
Message Font Size:
Adjusts the font size of the chat interface.
Show Estimated Token Count:
Displays the estimated token consumption of the input text in the input box (not the actual context token consumption, for reference only).
Paste Long Text as File:
When pasting a long text from another source into the input box, it will automatically be displayed as a file style to reduce interference with subsequent input.
Render Input Messages with Markdown:
When off, only the model's reply messages are rendered, not the messages you send.
Triple-press Space to Translate:
After typing a message in the chat input box, pressing the spacebar three times consecutively will translate the input into English.
Note: This action will overwrite the original text.
Target Language:
Sets the target language for the translate button in the input box and the triple-press space translation feature.
In the assistant interface, select the assistant name you want to configure → choose the corresponding setting from the right-click context menu.
Prompt Settings
Name:
You can customize the assistant's name for easy identification.
Prompt:
This is the prompt. You can refer to the prompt writing style on the agent page to edit the content.
Model Settings
Default Model:
You can set a fixed default model for this assistant. When adding from the agent page or copying an assistant, the initial model will be this one. If this is not set, the initial model will be the global initial model (i.e., the Default Assistant Model).
Auto Reset Model:
When on - If you switch to another model during a conversation in a topic, creating a new topic will reset the model for the new topic to the assistant's default model. When this option is off, the model for a new topic will follow the model used in the previous topic.
For example, if the assistant's default model is gpt-3.5-turbo, and I create Topic 1 under this assistant, and during the conversation in Topic 1, I switch to gpt-4o, then:
If auto-reset is on: When creating Topic 2, the default model for Topic 2 will be gpt-3.5-turbo.
If auto-reset is off: When creating Topic 2, the default model for Topic 2 will be gpt-4o.
Temperature :
The temperature parameter controls the degree of randomness and creativity in the text generated by the model (default is 0.7). Specifically:
Low temperature value (0-0.3):
Output is more deterministic and focused
Suitable for scenarios requiring accuracy, like code generation and data analysis
Tends to select the most likely words
Medium temperature value (0.4-0.7):
Balances creativity and coherence
Suitable for daily conversations and general writing
Recommended for chatbot conversations (around 0.5)
High temperature value (0.8-1.0):
Produces more creative and diverse output
Suitable for creative writing, brainstorming, etc.
May reduce the coherence of the text
Top P (Nucleus Sampling):
The default value is 1. The smaller the value, the more monotonous and easier to understand the AI-generated content is. The larger the value, the wider and more diverse the vocabulary of the AI's response.
Nucleus sampling affects the output by controlling the probability threshold for vocabulary selection:
Smaller value (0.1-0.3):
Considers only the highest probability words
Output is more conservative and controllable
Suitable for code comments, technical documentation, etc.
Medium value (0.4-0.6):
Balances vocabulary diversity and accuracy
Suitable for general conversation and writing tasks
Larger value (0.7-1.0):
Considers a wider range of vocabulary choices
Produces richer and more diverse content
Suitable for creative writing and other scenarios requiring diverse expression
Context Window
The number of messages to keep in the context. The larger the value, the longer the context and the more tokens are consumed:
5-10: Suitable for normal conversations
>10: For complex tasks requiring longer memory (e.g., generating a long article step-by-step according to an outline, which requires ensuring the generated context is logically coherent)
Note: The more messages, the greater the token consumption
Enable Message Length Limit (MaxToken)
The maximum number of Tokens for a single response. In large language models, max tokens is a key parameter that directly affects the quality and length of the generated response.
For example: When testing if a model is connected after filling in the key in CherryStudio, you only need to know if the model returns a message correctly without specific content. In this case, setting MaxToken to 1 is sufficient.
The MaxToken limit for most models is 32k Tokens, but some have 64k or even more. You need to check the corresponding introduction page for specifics.
The specific setting depends on your needs, but you can also refer to the following suggestions.
Suggestions:
Normal chat: 500-800
Short article generation: 800-2000
Code generation: 2000-3600
Long article generation: 4000 and above (requires model support)
Generally, the model's response will be limited within the MaxToken range. However, it might be truncated (e.g., when writing long code) or the expression may be incomplete. In special cases, you need to adjust it flexibly according to the actual situation.
Streaming Output (Stream)
Streaming output is a data processing method that allows data to be transmitted and processed as a continuous stream, rather than sending all data at once. This method allows data to be processed and output immediately after it is generated, greatly improving real-time performance and efficiency.
In an environment like the CherryStudio client, it's simply a typewriter effect.
When off (non-streaming): The model outputs the entire message at once after generating it (imagine receiving a message on WeChat).
When on: Word-by-word output. You can think of it as the large model sending you each word as it generates it, until the entire message is sent.
Custom Parameters
Adds extra request parameters to the request body, such as presence_penalty, which are generally not needed by most users.
The parameters mentioned above like top-p, maxtokens, stream, etc., are examples of these parameters.
How to fill: Parameter Name—Parameter Type (text, number, etc.)—Value. Refer to the documentation: Click to go

New Topic Creates a new topic within the current assistant.
Upload Image or Document Uploading images requires model support. Uploaded documents will be automatically parsed into text and provided to the model as context.
Web Search Requires configuring web search-related information in the settings. The search results are returned to the large model as context. For details, see Web Search Mode.
Knowledge Base Enables the knowledge base. For details, see Knowledge Base Tutorial.
MCP Server Enables the MCP server function. For details, see MCP Usage Tutorial.
Generate Image Not displayed by default. For models that support image generation (like Gemini), you need to manually activate it to generate images.
Select Model Switches to the specified model for the subsequent conversation while retaining the context.
Quick Phrases You need to preset common phrases in the settings first. They can be invoked here and entered directly, with support for variables.
Clear Messages Deletes all content under the current topic.
Expand Makes the chat box larger for entering long texts.
Clear Context Truncates the context available to the model without deleting the content, meaning the model will "forget" the previous conversation.
Estimate Token Count Displays the estimated token count. The four data points are Current Context Count, Max Context Count (∞ means infinite context), Character Count in Current Input Box, and Estimated Token Count.
Translate Translates the content in the current input box into English.


































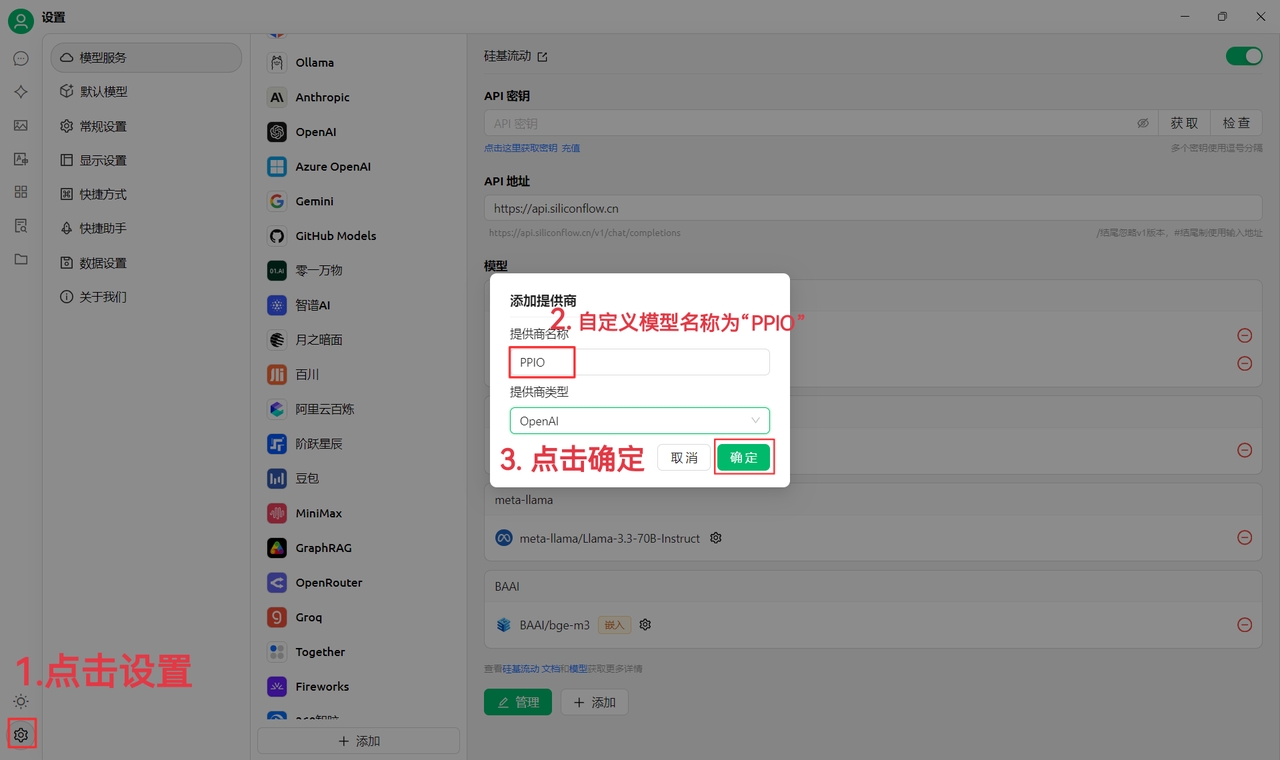

This document was translated from Chinese by AI and has not yet been reviewed.
CherryStudio supports web searches through SearXNG. SearXNG is an open-source project that can be deployed locally or on a server, so its configuration is slightly different from other methods that require an API provider.
SearXNG Project Link: SearXNG
Open-source and free, no API required
Relatively high privacy
Highly customizable
Since SearXNG does not require a complex environment setup, you can deploy it without using docker compose. Simply providing an available port is sufficient. Therefore, the quickest method is to directly pull the image and deploy it using Docker.
1. Download, install, and configure docker
After installation, select a path to store images:
2. Search for and pull the SearXNG image
Enter searxng in the search bar:
Pull the image:
3. Run the image
After the pull is successful, go to the images page:
Select the pulled image and click Run:
Open the settings to configure:
Using port 8085 as an example:
After it starts successfully, click the link to open the SearXNG frontend interface:
This page indicates a successful deployment:
Given that installing Docker on Windows can be quite troublesome, users can deploy SearXNG on a server, which also allows sharing it with others. Unfortunately, SearXNG itself does not currently support authentication, meaning others could scan for and abuse your deployed instance through technical means.
To address this, Cherry Studio now supports configuring HTTP Basic Authentication (RFC7617). If you plan to expose your self-deployed SearXNG to the public internet, you must configure HTTP Basic Authentication using a reverse proxy software like Nginx. The following is a brief tutorial that requires basic Linux system administration knowledge.
Similarly, we will still use Docker for deployment. Assuming you have already installed the latest version of Docker CE on your server following the official tutorial, here is a one-stop command for a fresh installation on a Debian system:
If you need to change the local listening port or reuse an existing local nginx, you can edit the docker-compose.yaml file. Refer to the following example:
Run docker compose up -d to start. Run docker compose logs -f searxng to view the logs.
If you are using a server control panel like Baota Panel or 1Panel, please refer to their documentation to add a website and configure the nginx reverse proxy. Then, find where to modify the nginx configuration file and make changes based on the example below:
Assuming the Nginx configuration file is saved in /etc/nginx/conf.d, we will save the password file in the same directory.
Execute the command (replace example_name and example_password with the username and password you intend to set):
Restart Nginx (reloading the configuration also works).
Now, try opening the webpage. You should be prompted to enter a username and password. Enter the credentials you set earlier to see if you can successfully access the SearXNG search page, thereby checking if the configuration is correct.
After successfully deploying SearXNG locally or on a server, the next step is to configure it in CherryStudio.
Go to the Web Search settings page and select Searxng:
If you enter the link for the local deployment directly and validation fails, don't worry:
This is because a direct deployment does not have the json return type configured by default, so data cannot be retrieved. You need to modify the configuration file.
Go back to Docker, and in the Files tab, find the tagged folder within the image:
After expanding it, scroll down further, and you will find another tagged folder:
Expand it again and find the settings.yml configuration file:
Click to open the file editor:
Find line 78. You will see that the only type is html
Add the json type, save, and restart the image
Return to Cherry Studio to validate again. Validation successful:
The address can be either local: http://localhost:<port_number>
or the Docker address: http://host.docker.internal:<port_number>
If you followed the previous example to deploy on a server and correctly configured the reverse proxy, the json return type will already be enabled. After entering the address and validating, since HTTP Basic Authentication has been configured for the reverse proxy, the validation should now return a 401 error code:
Configure HTTP Basic Authentication in the client, entering the username and password you just set:
Validate, and it should succeed.
At this point, SearXNG has default web search capabilities. If you need to customize the search engines, you need to configure it yourself.
Note that the preferences here do not affect the configuration when called by the large model.
To configure the search engines that the large model will use, you need to set them in the configuration file:
Language configuration reference:
If the content is too long and inconvenient to edit directly, you can copy it to a local IDE, modify it, and then paste it back into the configuration file.
Add json to the return formats in the configuration file:
Cherry Studio defaults to selecting engines whose categories include both "web" and "general" for searching. By default, engines like Google are selected, which fails in mainland China due to access restrictions. Adding the following configuration to force searxng to use the Baidu engine can solve the problem:
The limiter setting in searxng is blocking API access. Please try setting it to false in the settings:


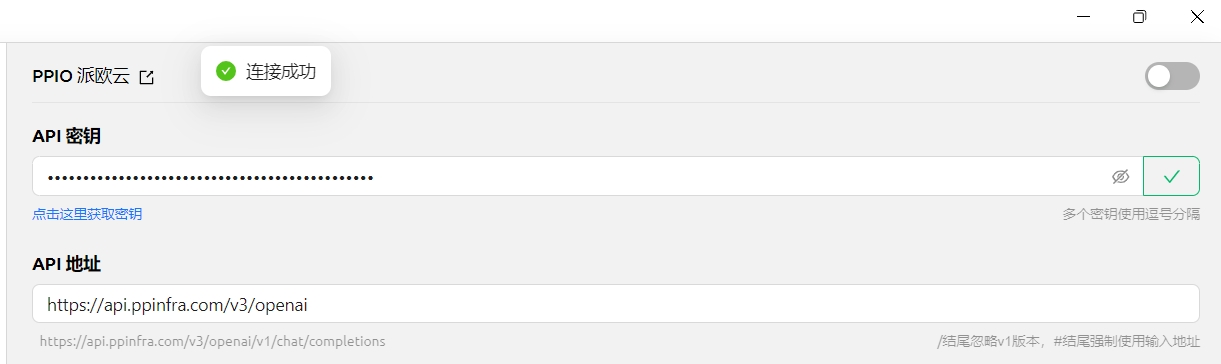














































This document was translated from Chinese by AI and has not yet been reviewed.
360gpt-pro
8k
-
Not Supported
Conversation
360AI_360gpt
The flagship hundred-billion-parameter large model in the 360 AI Brain series, with the best performance, widely applicable to complex task scenarios in various fields.
360gpt-turbo
7k
-
Not Supported
Conversation
360AI_360gpt
A ten-billion-parameter large model that balances performance and effectiveness, suitable for scenarios with high requirements for performance/cost.
360gpt-turbo-responsibility-8k
8k
-
Not Supported
Conversation
360AI_360gpt
A ten-billion-parameter large model that balances performance and effectiveness, suitable for scenarios with high requirements for performance/cost.
360gpt2-pro
8k
-
Not Supported
Conversation
360AI_360gpt
The flagship hundred-billion-parameter large model in the 360 AI Brain series, with the best performance, widely applicable to complex task scenarios in various fields.
claude-3-5-sonnet-20240620
200k
16k
Not Supported
Conversation, Vision
Anthropic_claude
A snapshot version released on June 20, 2024. Claude 3.5 Sonnet is a model that balances performance and speed, offering top-tier performance while maintaining high speed, and supports multimodal input.
claude-3-5-haiku-20241022
200k
16k
Not Supported
Conversation
Anthropic_claude
A snapshot version released on October 22, 2024. Claude 3.5 Haiku has improved across various skills, including coding, tool use, and reasoning. As the fastest model in the Anthropic family, it provides rapid response times, suitable for applications requiring high interactivity and low latency, such as user-facing chatbots and instant code completion. It also excels in specialized tasks like data extraction and real-time content moderation, making it a versatile tool for wide application across industries. It does not support image input.
claude-3-5-sonnet-20241022
200k
8K
Not Supported
Conversation, Vision
Anthropic_claude
A snapshot version released on October 22, 2024. Claude 3.5 Sonnet offers capabilities surpassing Opus and faster speeds than Sonnet, while maintaining the same price as Sonnet. Sonnet is particularly adept at programming, data science, visual processing, and agentic tasks.
claude-3-5-sonnet-latest
200K
8k
Not Supported
Conversation, Vision
Anthropic_claude
Dynamically points to the latest Claude 3.5 Sonnet version. Claude 3.5 Sonnet offers capabilities surpassing Opus and faster speeds than Sonnet, while maintaining the same price as Sonnet. Sonnet is particularly adept at programming, data science, visual processing, and agentic tasks. This model points to the latest version.
claude-3-haiku-20240307
200k
4k
Not Supported
Conversation, Vision
Anthropic_claude
Claude 3 Haiku is Anthropic's fastest and most compact model, designed for near-instantaneous responses. It features fast and accurate targeted performance.
claude-3-opus-20240229
200k
4k
Not Supported
Conversation, Vision
Anthropic_claude
Claude 3 Opus is Anthropic's most powerful model for handling highly complex tasks. It excels in performance, intelligence, fluency, and comprehension.
claude-3-sonnet-20240229
200k
8k
Not Supported
Conversation, Vision
Anthropic_claude
A snapshot version released on February 29, 2024. Sonnet is particularly adept at: - Coding: Can autonomously write, edit, and run code, with reasoning and troubleshooting capabilities - Data Science: Enhances human data science expertise; can process unstructured data when using multiple tools to gain insights - Visual Processing: Excels at interpreting charts, graphs, and images, accurately transcribing text to extract insights beyond the text itself - Agentic Tasks: Excellent tool use, making it ideal for handling agentic tasks (i.e., complex, multi-step problem-solving that requires interaction with other systems)
google/gemma-2-27b-it
8k
-
Not Supported
Conversation
Google_gamma
Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are decoder-only large language models that support English and come with open weights, pre-trained, and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning.
google/gemma-2-9b-it
8k
-
Not Supported
Conversation
Google_gamma
Gemma is one of the lightweight, state-of-the-art open model series developed by Google. It is a decoder-only large language model that supports English, with open weights, pre-trained, and instruction-tuned variants available. Gemma models are suitable for various text generation tasks, including question answering, summarization, and reasoning. This 9B model was trained on 8 trillion tokens.
gemini-1.5-pro
2m
8k
Not Supported
Conversation
Google_gemini
The latest stable version of Gemini 1.5 Pro. As a powerful multimodal model, it can handle up to 60,000 lines of code or 2,000 pages of text. It is particularly suitable for tasks requiring complex reasoning.
gemini-1.0-pro-001
33k
8k
Not Supported
Conversation
Google_gemini
This is a stable version of Gemini 1.0 Pro. As an NLP model, it specializes in tasks like multi-turn text and code chat, as well as code generation. This model will be discontinued on February 15, 2025, and it is recommended to migrate to the 1.5 series models.
gemini-1.0-pro-002
32k
8k
Not Supported
Conversation
Google_gemini
This is a stable version of Gemini 1.0 Pro. As an NLP model, it specializes in tasks like multi-turn text and code chat, as well as code generation. This model will be discontinued on February 15, 2025, and it is recommended to migrate to the 1.5 series models.
gemini-1.0-pro-latest
33k
8k
Not Supported
Conversation, Deprecated or soon to be deprecated
Google_gemini
This is the latest version of Gemini 1.0 Pro. As an NLP model, it specializes in tasks like multi-turn text and code chat, as well as code generation. This model will be discontinued on February 15, 2025, and it is recommended to migrate to the 1.5 series models.
gemini-1.0-pro-vision-001
16k
2k
Not Supported
Conversation
Google_gemini
This is the vision version of Gemini 1.0 Pro. This model will be discontinued on February 15, 2025, and it is recommended to migrate to the 1.5 series models.
gemini-1.0-pro-vision-latest
16k
2k
Not Supported
Vision
Google_gemini
This is the latest vision version of Gemini 1.0 Pro. This model will be discontinued on February 15, 2025, and it is recommended to migrate to the 1.5 series models.
gemini-1.5-flash
1m
8k
Not Supported
Conversation, Vision
Google_gemini
This is the latest stable version of Gemini 1.5 Flash. As a balanced multimodal model, it can process audio, image, video, and text inputs.
gemini-1.5-flash-001
1m
8k
Not Supported
Conversation, Vision
Google_gemini
This is a stable version of Gemini 1.5 Flash. It offers the same basic features as gemini-1.5-flash but is version-pinned, making it suitable for production environments.
gemini-1.5-flash-002
1m
8k
Not Supported
Conversation, Vision
Google_gemini
This is a stable version of Gemini 1.5 Flash. It offers the same basic features as gemini-1.5-flash but is version-pinned, making it suitable for production environments.
gemini-1.5-flash-8b
1m
8k
Not Supported
Conversation, Vision
Google_gemini
Gemini 1.5 Flash-8B is Google's latest multimodal AI model, designed for efficient handling of large-scale tasks. With 8 billion parameters, the model supports text, image, audio, and video inputs, making it suitable for various application scenarios such as chat, transcription, and translation. Compared to other Gemini models, Flash-8B is optimized for speed and cost-effectiveness, especially for cost-sensitive users. Its rate limit is doubled, allowing developers to handle large-scale tasks more efficiently. Additionally, Flash-8B uses "knowledge distillation" technology to extract key knowledge from larger models, ensuring it is lightweight and efficient while retaining core capabilities.
gemini-1.5-flash-exp-0827
1m
8k
Not Supported
Conversation, Vision
Google_gemini
This is an experimental version of Gemini 1.5 Flash, which is regularly updated with the latest improvements. It is suitable for exploratory testing and prototyping, but not recommended for production environments.
gemini-1.5-flash-latest
1m
8k
Not Supported
Conversation, Vision
Google_gemini
This is the cutting-edge version of Gemini 1.5 Flash, which is regularly updated with the latest improvements. It is suitable for exploratory testing and prototyping, but not recommended for production environments.
gemini-1.5-pro-001
2m
8k
Not Supported
Conversation, Vision
Google_gemini
This is a stable version of Gemini 1.5 Pro, offering fixed model behavior and performance characteristics. It is suitable for production environments that require stability.
gemini-1.5-pro-002
2m
8k
Not Supported
Conversation, Vision
Google_gemini
This is a stable version of Gemini 1.5 Pro, offering fixed model behavior and performance characteristics. It is suitable for production environments that require stability.
gemini-1.5-pro-exp-0801
2m
8k
Not Supported
Conversation, Vision
Google_gemini
An experimental version of Gemini 1.5 Pro. As a powerful multimodal model, it can handle up to 60,000 lines of code or 2,000 pages of text. It is particularly suitable for tasks requiring complex reasoning.
gemini-1.5-pro-exp-0827
2m
8k
Not Supported
Conversation, Vision
Google_gemini
An experimental version of Gemini 1.5 Pro. As a powerful multimodal model, it can handle up to 60,000 lines of code or 2,000 pages of text. It is particularly suitable for tasks requiring complex reasoning.
gemini-1.5-pro-latest
2m
8k
Not Supported
Conversation, Vision
Google_gemini
This is the latest version of Gemini 1.5 Pro, dynamically pointing to the most recent snapshot version.
gemini-2.0-flash
1m
8k
Not Supported
Conversation, Vision
Google_gemini
Gemini 2.0 Flash is Google's latest model, featuring a faster Time to First Token (TTFT) compared to the 1.5 version, while maintaining a quality level comparable to Gemini Pro 1.5. This model shows significant improvements in multimodal understanding, coding ability, complex instruction following, and function calling, thereby providing a smoother and more powerful intelligent experience.
gemini-2.0-flash-exp
100k
8k
Supported
Conversation, Vision
Google_gemini
Gemini 2.0 Flash introduces a real-time multimodal API, improved speed and performance, enhanced quality, stronger agent capabilities, and adds image generation and voice conversion functions.
gemini-2.0-flash-lite-preview-02-05
1M
8k
Not Supported
Conversation, Vision
Google_gemini
Gemini 2.0 Flash-Lite is Google's latest cost-effective AI model, offering better quality at the same speed as 1.5 Flash. It supports a 1 million token context window and can handle multimodal tasks involving images, audio, and code. As Google's most cost-effective model currently, it uses a simplified single pricing strategy, making it particularly suitable for large-scale application scenarios that require cost control.
gemini-2.0-flash-thinking-exp
40k
8k
Not Supported
Conversation, Reasoning
Google_gemini
gemini-2.0-flash-thinking-exp is an experimental model that can generate the "thinking process" it goes through when formulating a response. Therefore, "thinking mode" responses have stronger reasoning capabilities compared to the basic Gemini 2.0 Flash model.
gemini-2.0-flash-thinking-exp-01-21
1m
64k
Not Supported
Conversation, Reasoning
Google_gemini
Gemini 2.0 Flash Thinking EXP-01-21 is Google's latest AI model, focusing on enhancing reasoning abilities and user interaction experience. The model has strong reasoning capabilities, especially in math and programming, and supports a context window of up to 1 million tokens, suitable for complex tasks and in-depth analysis scenarios. Its unique feature is the ability to generate its thinking process, improving the comprehensibility of AI thinking. It also supports native code execution, enhancing the flexibility and practicality of interactions. By optimizing algorithms, the model reduces logical contradictions, further improving the accuracy and consistency of its answers.
gemini-2.0-flash-thinking-exp-1219
40k
8k
Not Supported
Conversation, Reasoning, Vision
Google_gemini
gemini-2.0-flash-thinking-exp-1219 is an experimental model that can generate the "thinking process" it goes through when formulating a response. Therefore, "thinking mode" responses have stronger reasoning capabilities compared to the basic Gemini 2.0 Flash model.
gemini-2.0-pro-exp-01-28
2m
64k
Not Supported
Conversation, Vision
Google_gemini
Pre-announced model, not yet online.
gemini-2.0-pro-exp-02-05
2m
8k
Not Supported
Conversation, Vision
Google_gemini
Gemini 2.0 Pro Exp 02-05 is Google's latest experimental model released in February 2024, excelling in world knowledge, code generation, and long-text understanding. The model supports an ultra-long context window of 2 million tokens, capable of processing content equivalent to 2 hours of video, 22 hours of audio, over 60,000 lines of code, and more than 1.4 million words. As part of the Gemini 2.0 series, this model adopts a new Flash Thinking training strategy, significantly improving its performance and ranking high on several LLM leaderboards, demonstrating strong comprehensive capabilities.
gemini-exp-1114
8k
4k
Not Supported
Conversation, Vision
Google_gemini
This is an experimental model released on November 14, 2024, primarily focusing on quality improvements.
gemini-exp-1121
8k
4k
Not Supported
Conversation, Vision, Code
Google_gemini
This is an experimental model released on November 21, 2024, with improvements in coding, reasoning, and visual capabilities.
gemini-exp-1206
8k
4k
Not Supported
Conversation, Vision
Google_gemini
This is an experimental model released on December 6, 2024, with improvements in coding, reasoning, and visual capabilities.
gemini-exp-latest
8k
4k
Not Supported
Conversation, Vision
Google_gemini
This is an experimental model, dynamically pointing to the latest version.
gemini-pro
33k
8k
Not Supported
Conversation
Google_gemini
Same as gemini-1.0-pro, it is an alias for gemini-1.0-pro.
gemini-pro-vision
16k
2k
Not Supported
Conversation, Vision
Google_gemini
This is the vision version of Gemini 1.0 Pro. This model will be discontinued on February 15, 2025, and it is recommended to migrate to the 1.5 series models.
grok-2
128k
-
Not Supported
Conversation
Grok_grok
A new version of the grok model released by X.ai on December 12, 2024.
grok-2-1212
128k
-
Not Supported
Conversation
Grok_grok
A new version of the grok model released by X.ai on December 12, 2024.
grok-2-latest
128k
-
Not Supported
Conversation
Grok_grok
A new version of the grok model released by X.ai on December 12, 2024.
grok-2-vision-1212
32k
-
Not Supported
Conversation, Vision
Grok_grok
The grok vision version model released by X.ai on December 12, 2024.
grok-beta
100k
-
Not Supported
Conversation
Grok_grok
Performance comparable to Grok 2, but with improved efficiency, speed, and functionality.
grok-vision-beta
8k
-
Not Supported
Conversation, Vision
Grok_grok
The latest image understanding model can process various visual information, including documents, charts, screenshots, and photos.
internlm/internlm2_5-20b-chat
32k
-
Supported
Conversation
internlm
InternLM2.5-20B-Chat is an open-source large-scale conversational model developed based on the InternLM2 architecture. With 20 billion parameters, this model excels in mathematical reasoning, surpassing comparable models like Llama3 and Gemma2-27B. InternLM2.5-20B-Chat has significantly improved tool-calling capabilities, supporting information collection from hundreds of web pages for analysis and reasoning, and possessing stronger instruction understanding, tool selection, and result reflection abilities.
meta-llama/Llama-3.2-11B-Vision-Instruct
8k
-
Not Supported
Conversation, Vision
Meta_llama
The current Llama series models can not only process text data but also image data. Some models in Llama 3.2 have added visual understanding functions. This model supports simultaneous input of text and image data, understands the image, and outputs text information.
meta-llama/Llama-3.2-3B-Instruct
32k
-
Not Supported
Conversation
Meta_llama
Meta Llama 3.2 multilingual Large Language Models (LLMs), where 1B and 3B are lightweight models that can run on edge and mobile devices. This model is the 3B version.
meta-llama/Llama-3.2-90B-Vision-Instruct
8k
-
Not Supported
Conversation, Vision
Meta_llama
The current Llama series models can not only process text data but also image data. Some models in Llama 3.2 have added visual understanding functions. This model supports simultaneous input of text and image data, understands the image, and outputs text information.
meta-llama/Llama-3.3-70B-Instruct
131k
-
Not Supported
Conversation
Meta_llama
Meta's latest 70B LLM, with performance comparable to Llama 3.1 405B.
meta-llama/Meta-Llama-3.1-405B-Instruct
32k
-
Not Supported
Conversation
Meta_llama
The Meta Llama 3.1 multilingual Large Language Model (LLM) collection is a set of pre-trained and instruction-tuned generative models in 8B, 70B, and 405B sizes. This model is the 405B version. The Llama 3.1 instruction-tuned text models (8B, 70B, 405B) are optimized for multilingual conversations and outperform many available open-source and closed-source chat models on common industry benchmarks.
meta-llama/Meta-Llama-3.1-70B-Instruct
32k
-
Not Supported
Conversation
Meta_llama
Meta Llama 3.1 is a family of multilingual large language models developed by Meta, including pre-trained and instruction-tuned variants in 8B, 70B, and 405B parameter sizes. This 70B instruction-tuned model is optimized for multilingual conversation scenarios and performs excellently on several industry benchmarks. The model was trained on over 15 trillion tokens of public data and uses techniques like supervised fine-tuning and reinforcement learning with human feedback to enhance its usefulness and safety.
meta-llama/Meta-Llama-3.1-8B-Instruct
32k
-
Not Supported
Conversation
Meta_llama
The Meta Llama 3.1 multilingual Large Language Model (LLM) collection is a set of pre-trained and instruction-tuned generative models in 8B, 70B, and 405B sizes. This model is the 8B version. The Llama 3.1 instruction-tuned text models (8B, 70B, 405B) are optimized for multilingual conversations and outperform many available open-source and closed-source chat models on common industry benchmarks.
abab5.5-chat
16k
-
Supported
Conversation
Minimax_abab
Chinese persona conversation scenarios.
abab5.5s-chat
8k
-
Supported
Conversation
Minimax_abab
Chinese persona conversation scenarios.
abab6.5g-chat
8k
-
Supported
Conversation
Minimax_abab
Persona conversation scenarios in English and other languages.
abab6.5s-chat
245k
-
Supported
Conversation
Minimax_abab
General scenarios.
abab6.5t-chat
8k
-
Supported
Conversation
Minimax_abab
Chinese persona conversation scenarios.
chatgpt-4o-latest
128k
16k
Not Supported
Conversation, Vision
OpenAI
The chatgpt-4o-latest model version continuously points to the GPT-4o version used in ChatGPT and is updated the fastest when there are significant changes.
gpt-4o-2024-11-20
128k
16k
Supported
Conversation
OpenAI
The latest gpt-4o snapshot version from November 20, 2024.
gpt-4o-audio-preview
128k
16k
Not Supported
Conversation
OpenAI
OpenAI's real-time voice conversation model.
gpt-4o-audio-preview-2024-10-01
128k
16k
Supported
Conversation
OpenAI
OpenAI's real-time voice conversation model.
o1
128k
32k
Not Supported
Conversation, Reasoning, Vision
OpenAI
OpenAI's new reasoning model for complex tasks that require extensive common sense. The model has a 200k context, is currently the most powerful model in the world, and supports image recognition.
o1-mini-2024-09-12
128k
64k
Not Supported
Conversation, Reasoning
OpenAI
A fixed snapshot version of o1-mini. It is smaller, faster, and 80% cheaper than o1-preview, performing well in code generation and small-context operations.
o1-preview-2024-09-12
128k
32k
Not Supported
Conversation, Reasoning
OpenAI
A fixed snapshot version of o1-preview.
gpt-3.5-turbo
16k
4k
Supported
Conversation
OpenAI_gpt-3
Based on GPT-3.5: GPT-3.5 Turbo is an improved version built on the GPT-3.5 model, developed by OpenAI. Performance Goals: Designed to improve model inference speed, processing efficiency, and resource utilization through optimized model structure and algorithms. Increased Inference Speed: Compared to GPT-3.5, GPT-3.5 Turbo typically offers faster inference speeds on the same hardware, which is particularly beneficial for applications requiring large-scale text processing. Higher Throughput: When processing a large number of requests or data, GPT-3.5 Turbo can achieve higher concurrent processing capabilities, thereby increasing overall system throughput. Optimized Resource Consumption: While maintaining performance, it may have reduced demand for hardware resources (such as memory and computing resources), which helps lower operating costs and improve system scalability. Wide Range of NLP Tasks: GPT-3.5 Turbo is suitable for a variety of natural language processing tasks, including but not limited to text generation, semantic understanding, dialogue systems, and machine translation. Developer Tools and API Support: Provides API interfaces that are easy for developers to integrate and use, supporting rapid application development and deployment.
gpt-3.5-turbo-0125
16k
4k
Supported
Conversation
OpenAI_gpt-3
An updated GPT 3.5 Turbo model with higher accuracy in responding to requested formats and a fix for a bug that caused text encoding issues for non-English language function calls. Returns a maximum of 4,096 output tokens.
gpt-3.5-turbo-0613
16k
4k
Supported
Conversation
OpenAI_gpt-3
Updated fixed snapshot version of GPT 3.5 Turbo. Now deprecated.
gpt-3.5-turbo-1106
16k
4k
Supported
Conversation
OpenAI_gpt-3
Features improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Returns a maximum of 4,096 output tokens.
gpt-3.5-turbo-16k
16k
4k
Supported
Conversation, Deprecated or soon to be deprecated
OpenAI_gpt-3
(Deprecated)
gpt-3.5-turbo-16k-0613
16k
4k
Supported
Conversation, Deprecated or soon to be deprecated
OpenAI_gpt-3
A snapshot of gpt-3.5-turbo from June 13, 2023. (Deprecated)
gpt-3.5-turbo-instruct
4k
4k
Supported
Conversation
OpenAI_gpt-3
Capabilities similar to GPT-3 era models. Compatible with the legacy Completions endpoint, not for Chat Completions.
gpt-3.5o
16k
4k
Not Supported
Conversation
OpenAI_gpt-3
Same as gpt-4o-lite.
gpt-4
8k
8k
Supported
Conversation
OpenAI_gpt-4
Currently points to gpt-4-0613.
gpt-4-0125-preview
128k
4k
Supported
Conversation
OpenAI_gpt-4
The latest GPT-4 model, designed to reduce "laziness" where the model does not complete tasks. Returns a maximum of 4,096 output tokens.
gpt-4-0314
8k
8k
Supported
Conversation
OpenAI_gpt-4
A snapshot of gpt-4 from March 14, 2023.
gpt-4-0613
8k
8k
Supported
Conversation
OpenAI_gpt-4
A snapshot of gpt-4 from June 13, 2023, with enhanced function calling support.
gpt-4-1106-preview
128k
4k
Supported
Conversation
OpenAI_gpt-4
A GPT-4 Turbo model with improved instruction following, JSON mode, reproducible outputs, function calling, and more. Returns a maximum of 4,096 output tokens. This is a preview model.
gpt-4-32k
32k
4k
Supported
Conversation
OpenAI_gpt-4
gpt-4-32k will be deprecated on 2025-06-06.
gpt-4-32k-0613
32k
4k
Supported
Conversation, Deprecated or soon to be deprecated
OpenAI_gpt-4
Will be deprecated on 2025-06-06.
gpt-4-turbo
128k
4k
Supported
Conversation
OpenAI_gpt-4
The latest version of the GPT-4 Turbo model adds vision capabilities, supporting visual requests via JSON mode and function calling. The current version of this model is gpt-4-turbo-2024-04-09.
gpt-4-turbo-2024-04-09
128k
4k
Supported
Conversation
OpenAI_gpt-4
GPT-4 Turbo model with vision capabilities. Vision requests can now be made via JSON mode and function calling. gpt-4-turbo currently points to this version.
gpt-4-turbo-preview
128k
4k
Supported
Conversation, Vision
OpenAI_gpt-4
Currently points to gpt-4-0125-preview.
gpt-4o
128k
16k
Supported
Conversation, Vision
OpenAI_gpt-4
OpenAI's highly intelligent flagship model, suitable for complex, multi-step tasks. GPT-4o is cheaper and faster than GPT-4 Turbo.
gpt-4o-2024-05-13
128k
4k
Supported
Conversation, Vision
OpenAI_gpt-4
The original gpt-4o snapshot from May 13, 2024.
gpt-4o-2024-08-06
128k
16k
Supported
Conversation, Vision
OpenAI_gpt-4
The first snapshot to support structured outputs. gpt-4o currently points to this version.
gpt-4o-mini
128k
16k
Supported
Conversation, Vision
OpenAI_gpt-4
OpenAI's affordable version of gpt-4o, suitable for fast, lightweight tasks. GPT-4o mini is cheaper and more powerful than GPT-3.5 Turbo. Currently points to gpt-4o-mini-2024-07-18.
gpt-4o-mini-2024-07-18
128k
16k
Supported
Conversation, Vision
OpenAI_gpt-4
A fixed snapshot version of gpt-4o-mini.
gpt-4o-realtime-preview
128k
4k
Supported
Conversation, Real-time Voice
OpenAI_gpt-4
OpenAI's real-time voice conversation model.
gpt-4o-realtime-preview-2024-10-01
128k
4k
Supported
Conversation, Real-time Voice, Vision
OpenAI_gpt-4
gpt-4o-realtime-preview currently points to this snapshot version.
o1-mini
128k
64k
Not Supported
Conversation, Reasoning
OpenAI_o1
Smaller, faster, and 80% cheaper than o1-preview, performing well in code generation and small-context operations.
o1-preview
128k
32k
Not Supported
Conversation, Reasoning
OpenAI_o1
o1-preview is a new reasoning model for complex tasks that require extensive common sense. The model has a 128K context and a knowledge cutoff of October 2023. It focuses on advanced reasoning and solving complex problems, including mathematical and scientific tasks. It is ideal for applications requiring deep contextual understanding and autonomous workflows.
o3-mini
200k
100k
Supported
Conversation, Reasoning
OpenAI_o1
o3-mini is OpenAI's latest small reasoning model, offering high intelligence while maintaining the same cost and latency as o1-mini. It focuses on science, math, and coding tasks, supports developer features like structured output, function calling, and batch API, with a knowledge cutoff of October 2023, demonstrating a significant balance in reasoning capability and cost-effectiveness.
o3-mini-2025-01-31
200k
100k
Supported
Conversation, Reasoning
OpenAI_o1
o3-mini currently points to this version. o3-mini-2025-01-31 is OpenAI's latest small reasoning model, offering high intelligence while maintaining the same cost and latency as o1-mini. It focuses on science, math, and coding tasks, supports developer features like structured output, function calling, and batch API, with a knowledge cutoff of October 2023, demonstrating a significant balance in reasoning capability and cost-effectiveness.
Baichuan2-Turbo
32k
-
Not Supported
Conversation
Baichuan_baichuan
Compared to similarly sized models in the industry, this model maintains a leading performance while significantly reducing the price.
Baichuan3-Turbo
32k
-
Not Supported
Conversation
Baichuan_baichuan
Compared to similarly sized models in the industry, this model maintains a leading performance while significantly reducing the price.
Baichuan3-Turbo-128k
128k
-
Not Supported
Conversation
Baichuan_baichuan
The Baichuan model processes complex text with a 128k ultra-long context window, is specifically optimized for industries like finance, and significantly reduces costs while maintaining high performance, providing a cost-effective solution for enterprises.
Baichuan4
32k
-
Not Supported
Conversation
Baichuan_baichuan
Baichuan's MoE model provides a highly efficient and cost-effective solution for enterprise applications through specialized optimization, cost reduction, and performance enhancement.
Baichuan4-Air
32k
-
Not Supported
Conversation
Baichuan_baichuan
Baichuan's MoE model provides a highly efficient and cost-effective solution for enterprise applications through specialized optimization, cost reduction, and performance enhancement.
Baichuan4-Turbo
32k
-
Not Supported
Conversation
Baichuan_baichuan
Trained on massive high-quality scenario data, usability in high-frequency enterprise scenarios is improved by 10%+ compared to Baichuan4, information summarization by 50%, multilingual capabilities by 31%, and content generation by 13%. Specially optimized for inference performance, the first token response speed is increased by 51% and token stream speed by 73% compared to Baichuan4.
ERNIE-3.5-128K
128k
4k
Supported
Conversation
Baidu_ernie
Baidu's self-developed flagship large language model, covering massive Chinese and English corpora, with powerful general capabilities to meet most dialogue, Q&A, creative generation, and plugin application requirements. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information.
ERNIE-3.5-8K
8k
1k
Supported
Conversation
Baidu_ernie
Baidu's self-developed flagship large language model, covering massive Chinese and English corpora, with powerful general capabilities to meet most dialogue, Q&A, creative generation, and plugin application requirements. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information.
ERNIE-3.5-8K-Preview
8k
1k
Supported
Conversation
Baidu_ernie
Baidu's self-developed flagship large language model, covering massive Chinese and English corpora, with powerful general capabilities to meet most dialogue, Q&A, creative generation, and plugin application requirements. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information.
ERNIE-4.0-8K
8k
1k
Supported
Conversation
Baidu_ernie
Baidu's self-developed flagship ultra-large-scale language model. Compared to ERNIE 3.5, it has a comprehensive upgrade in model capabilities, widely applicable to complex task scenarios in various fields. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information.
ERNIE-4.0-8K-Latest
8k
2k
Supported
Conversation
Baidu_ernie
ERNIE-4.0-8K-Latest has fully improved capabilities compared to ERNIE-4.0-8K, with significant enhancements in role-playing and instruction-following abilities. Compared to ERNIE 3.5, it has a comprehensive upgrade in model capabilities, widely applicable to complex task scenarios in various fields. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information, and supports 5K tokens input + 2K tokens output. This document introduces the method for calling the ERNIE-4.0-8K-Latest API.
ERNIE-4.0-8K-Preview
8k
1k
Supported
Conversation
Baidu_ernie
Baidu's self-developed flagship ultra-large-scale language model. Compared to ERNIE 3.5, it has a comprehensive upgrade in model capabilities, widely applicable to complex task scenarios in various fields. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information.
ERNIE-4.0-Turbo-128K
128k
4k
Supported
Conversation
Baidu_ernie
ERNIE 4.0 Turbo is Baidu's self-developed flagship ultra-large-scale language model with outstanding overall performance, widely applicable to complex task scenarios in various fields. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information. It has better performance compared to ERNIE 4.0. ERNIE-4.0-Turbo-128K is a version of the model with better overall performance on long documents than ERNIE-3.5-128K. This document introduces the relevant API and its usage.
ERNIE-4.0-Turbo-8K
8k
2k
Supported
Conversation
Baidu_ernie
ERNIE 4.0 Turbo is Baidu's self-developed flagship ultra-large-scale language model with outstanding overall performance, widely applicable to complex task scenarios in various fields. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information. It has better performance compared to ERNIE 4.0. ERNIE-4.0-Turbo-8K is a version of the model. This document introduces the relevant API and its usage.
ERNIE-4.0-Turbo-8K-Latest
8k
2k
Supported
Conversation
Baidu_ernie
ERNIE 4.0 Turbo is Baidu's self-developed flagship ultra-large-scale language model with outstanding overall performance, widely applicable to complex task scenarios in various fields. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information. It has better performance compared to ERNIE 4.0. ERNIE-4.0-Turbo-8K is a version of the model.
ERNIE-4.0-Turbo-8K-Preview
8k
2k
Supported
Conversation
Baidu_ernie
ERNIE 4.0 Turbo is Baidu's self-developed flagship ultra-large-scale language model with outstanding overall performance, widely applicable to complex task scenarios in various fields. Supports automatic integration with the Baidu search plugin to ensure the timeliness of Q&A information. ERNIE-4.0-Turbo-8K-Preview is a version of the model.
ERNIE-Character-8K
8k
1k
Not Supported
Conversation
Baidu_ernie
Baidu's self-developed vertical large language model, suitable for application scenarios such as game NPCs, customer service dialogues, and dialogue role-playing. It has a more distinct and consistent persona style, stronger instruction-following ability, and better inference performance.
ERNIE-Lite-8K
8k
4k
Not Supported
Conversation
Baidu_ernie
Baidu's self-developed lightweight large language model, balancing excellent model performance with inference efficiency, suitable for inference on low-power AI accelerator cards.
ERNIE-Lite-Pro-128K
128k
2k
Supported
Conversation
Baidu_ernie
Baidu's self-developed lightweight large language model, with better performance than ERNIE Lite, balancing excellent model performance with inference efficiency, suitable for inference on low-power AI accelerator cards. ERNIE-Lite-Pro-128K supports a 128K context length and has better performance than ERNIE-Lite-128K.
ERNIE-Novel-8K
8k
2k
Not Supported
Conversation
Baidu_ernie
ERNIE-Novel-8K is Baidu's self-developed general-purpose large language model, with a significant advantage in novel continuation capabilities. It can also be used in scenarios like short dramas and movies.
ERNIE-Speed-128K
128k
4k
Not Supported
Conversation
Baidu_ernie
Baidu's latest self-developed high-performance large language model released in 2024, with excellent general capabilities. It is suitable as a base model for fine-tuning to better handle specific scenario problems, while also having excellent inference performance.
ERNIE-Speed-8K
8k
1k
Not Supported
Conversation
Baidu_ernie
Baidu's latest self-developed high-performance large language model released in 2024, with excellent general capabilities. It is suitable as a base model for fine-tuning to better handle specific scenario problems, while also having excellent inference performance.
ERNIE-Speed-Pro-128K
128k
4k
Not Supported
Conversation
Baidu_ernie
ERNIE Speed Pro is Baidu's latest self-developed high-performance large language model released in 2024, with excellent general capabilities. It is suitable as a base model for fine-tuning to better handle specific scenario problems, while also having excellent inference performance. ERNIE-Speed-Pro-128K is the initial version released on August 30, 2024, supporting a 128K context length and having better performance than ERNIE-Speed-128K.
ERNIE-Tiny-8K
8k
1k
Not Supported
Conversation
Baidu_ernie
Baidu's self-developed ultra-high-performance large language model, with the lowest deployment and fine-tuning costs in the ERNIE series.
Doubao-1.5-lite-32k
32k
12k
Supported
Conversation
Doubao_doubao
Doubao1.5-lite is also among the world's top-tier lightweight language models, matching or surpassing GPT-4o mini and Claude 3.5 Haiku on authoritative evaluation benchmarks for general knowledge (MMLU_pro), reasoning (BBH), math (MATH), and professional knowledge (GPQA).
Doubao-1.5-pro-256k
256k
12k
Supported
Conversation
Doubao_doubao
Doubao-1.5-Pro-256k, a fully upgraded version based on Doubao-1.5-Pro. Compared to Doubao-pro-256k/241115, the overall performance is significantly improved by 10%. The output length is greatly increased, supporting up to 12k tokens.
Doubao-1.5-pro-32k
32k
12k
Supported
Conversation
Doubao_doubao
Doubao-1.5-pro, a new generation flagship model with comprehensive performance upgrades, excelling in knowledge, code, reasoning, and more. It achieves world-leading performance on multiple public evaluation benchmarks, especially achieving the best scores on knowledge, code, reasoning, and Chinese authoritative benchmarks, with a composite score superior to top industry models like GPT4o and Claude 3.5 Sonnet.
Doubao-1.5-vision-pro
32k
12k
Not Supported
Conversation, Vision
Doubao_doubao
Doubao-1.5-vision-pro, a newly upgraded multimodal large model, supports image recognition of any resolution and extreme aspect ratios, enhancing visual reasoning, document recognition, detailed information understanding, and instruction-following capabilities.
Doubao-embedding
4k
-
Supported
Embedding
Doubao_doubao
Doubao-embedding is a semantic vectorization model developed by ByteDance, primarily for vector retrieval scenarios. It supports Chinese and English, with a maximum context length of 4K. The following versions are currently available: text-240715: Maximum vector dimension of 2560, supports dimensionality reduction to 512, 1024, and 2048. Chinese and English retrieval performance is significantly improved compared to the text-240515 version, and this version is recommended. text-240515: Maximum vector dimension of 2048, supports dimensionality reduction to 512 and 1024.
Doubao-embedding-large
4k
-
Not Supported
Embedding
Doubao_doubao
Chinese and English retrieval performance is significantly improved compared to the Doubao-embedding/text-240715 version.
Doubao-embedding-vision
8k
-
Not Supported
Embedding
Doubao_doubao
Doubao-embedding-vision, a newly upgraded image-text multimodal vectorization model, is primarily for image-text multi-vector retrieval scenarios. It supports image input and Chinese/English text input, with a maximum context length of 8K.
Doubao-lite-128k
128k
4k
Supported
Conversation
Doubao_doubao
Doubao-lite offers extremely fast response speeds and better cost-effectiveness, providing more flexible choices for customers in different scenarios. Supports inference and fine-tuning with a 128k context window.
Doubao-lite-32k
32k
4k
Supported
Conversation
Doubao_doubao
Doubao-lite offers extremely fast response speeds and better cost-effectiveness, providing more flexible choices for customers in different scenarios. Supports inference and fine-tuning with a 32k context window.
Doubao-lite-4k
4k
4k
Supported
Conversation
Doubao_doubao
Doubao-lite offers extremely fast response speeds and better cost-effectiveness, providing more flexible choices for customers in different scenarios. Supports inference and fine-tuning with a 4k context window.
Doubao-pro-128k
128k
4k
Supported
Conversation
Doubao_doubao
The flagship model with the best performance, suitable for handling complex tasks, with excellent results in reference Q&A, summarization, creation, text classification, role-playing, and other scenarios. Supports inference and fine-tuning with a 128k context window.
Doubao-pro-32k
32k
4k
Supported
Conversation
Doubao_doubao
The flagship model with the best performance, suitable for handling complex tasks, with excellent results in reference Q&A, summarization, creation, text classification, role-playing, and other scenarios. Supports inference and fine-tuning with a 32k context window.
Doubao-pro-4k
4k
4k
Supported
Conversation
Doubao_doubao
The flagship model with the best performance, suitable for handling complex tasks, with excellent results in reference Q&A, summarization, creation, text classification, role-playing, and other scenarios. Supports inference and fine-tuning with a 4k context window.
step-1-128k
128k
-
Supported
Conversation
StepFun
The step-1-128k model is an ultra-large-scale language model capable of processing inputs of up to 128,000 tokens. This capability gives it a significant advantage in generating long-form content and performing complex reasoning, making it suitable for applications that require rich context, such as writing novels and scripts.
step-1-256k
256k
-
Supported
Conversation
StepFun
The step-1-256k model is one of the largest language models available, supporting inputs of 256,000 tokens. It is designed to meet extremely complex task requirements, such as large-scale data analysis and multi-turn dialogue systems, and can provide high-quality output in various domains.
step-1-32k
32k
-
Supported
Conversation
StepFun
The step-1-32k model extends the context window to support 32,000 tokens of input. This makes it perform excellently when handling long articles and complex conversations, suitable for tasks that require deep understanding and analysis, such as legal documents and academic research.
step-1-8k
8k
-
Supported
Conversation
StepFun
The step-1-8k model is an efficient language model designed for processing shorter texts. It can perform reasoning within a context of 8,000 tokens, making it suitable for application scenarios that require quick responses, such as chatbots and real-time translation.
step-1-flash
8k
-
Supported
Conversation
StepFun
The step-1-flash model focuses on rapid response and efficient processing, suitable for real-time applications. Its design allows it to provide high-quality language understanding and generation capabilities even with limited computing resources, making it suitable for mobile devices and edge computing scenarios.
step-1.5v-mini
32k
-
Supported
Conversation, Vision
StepFun
The step-1.5v-mini model is a lightweight version designed to run in resource-constrained environments. Despite its small size, it still retains good language processing capabilities, making it suitable for embedded systems and low-power devices.
step-1v-32k
32k
-
Supported
Conversation, Vision
StepFun
The step-1v-32k model supports inputs of 32,000 tokens, suitable for applications requiring longer context. It performs excellently in handling complex dialogues and long texts, making it suitable for fields such as customer service and content creation.
step-1v-8k
8k
-
Supported
Conversation, Vision
StepFun
The step-1v-8k model is an optimized version designed for 8,000-token inputs, suitable for fast generation and processing of short texts. It strikes a good balance between speed and accuracy, making it suitable for real-time applications.
step-2-16k
16k
-
Supported
Conversation
StepFun
The step-2-16k model is a medium-sized language model supporting 16,000 tokens of input. It performs well in various tasks and is suitable for application scenarios such as education, training, and knowledge management.
yi-lightning
16k
-
Supported
Conversation
01.AI_yi
The latest high-performance model, ensuring high-quality output while significantly increasing inference speed. Suitable for real-time interaction and highly complex reasoning scenarios, its extremely high cost-effectiveness can provide excellent support for commercial products.
yi-vision-v2
16K
-
Supported
Conversation, Vision
01.AI_yi
Suitable for scenarios that require analyzing and interpreting images and charts, such as image Q&A, chart understanding, OCR, visual reasoning, education, research report understanding, or multilingual document reading.
qwen-14b-chat
8k
2k
Supported
Conversation
Qwen_qwen
Alibaba Cloud's official open-source version of Tongyi Qianwen.
qwen-72b-chat
32k
2k
Supported
Conversation
Qwen_qwen
Alibaba Cloud's official open-source version of Tongyi Qianwen.
qwen-7b-chat
7.5k
1.5k
Supported
Conversation
Qwen_qwen
Alibaba Cloud's official open-source version of Tongyi Qianwen.
qwen-coder-plus
128k
8k
Supported
Conversation, Code
Qwen_qwen
Qwen-Coder-Plus is a programming-specific model in the Qwen series, designed to enhance code generation and understanding capabilities. Trained on a large scale of programming data, this model can handle multiple programming languages and supports functions like code completion, error detection, and code refactoring. Its design goal is to provide developers with more efficient programming assistance and improve development efficiency.
qwen-coder-plus-latest
128k
8k
Supported
Conversation, Code
Qwen_qwen
Qwen-Coder-Plus-Latest is the newest version of Qwen-Coder-Plus, incorporating the latest algorithm optimizations and dataset updates. This model shows significant performance improvements, enabling it to understand context more accurately and generate code that better meets developers' needs. It also introduces support for more programming languages, enhancing its multilingual programming capabilities.
qwen-coder-turbo
128k
8k
Supported
Conversation, Code
Qwen_qwen
The Tongyi Qianwen series of code and programming models are language models specifically for programming and code generation, featuring fast inference speed and low cost. This version always points to the latest stable snapshot.
qwen-coder-turbo-latest
128k
8k
Supported
Conversation, Code
Qwen_qwen
The Tongyi Qianwen series of code and programming models are language models specifically for programming and code generation, featuring fast inference speed and low cost. This version always points to the latest snapshot.
qwen-long
10m
6k
Supported
Conversation
Qwen_qwen
Qwen-Long is a large language model from Tongyi Qianwen for ultra-long context processing scenarios. It supports input in different languages such as Chinese and English, and supports ultra-long context dialogues of up to 10 million tokens (about 15 million words or 15,000 pages of documents). Combined with the synchronously launched document service, it can parse and have dialogues on various document formats such as Word, PDF, Markdown, EPUB, and MOBI. Note: For requests submitted directly via HTTP, it supports a length of 1M tokens. For lengths exceeding this, it is recommended to submit via file.
qwen-math-plus
4k
3k
Supported
Conversation
Qwen_qwen
Qwen-Math-Plus is a model focused on solving mathematical problems, designed to provide efficient mathematical reasoning and calculation capabilities. Trained on a large number of math problems, this model can handle complex mathematical expressions and problems, supporting a variety of calculation needs from basic arithmetic to higher mathematics. Its application scenarios include education, scientific research, and engineering.
qwen-math-plus-latest
4k
3k
Supported
Conversation
Qwen_qwen
Qwen-Math-Plus-Latest is the newest version of Qwen-Math-Plus, integrating the latest mathematical reasoning techniques and algorithm improvements. This model performs better in handling complex mathematical problems, providing more accurate solutions and reasoning processes. It also expands its understanding of mathematical symbols and formulas, making it suitable for a wider range of mathematical applications.
qwen-math-turbo
4k
3k
Supported
Conversation
Qwen_qwen
Qwen-Math-Turbo is a high-performance mathematical model designed for fast calculation and real-time inference. This model optimizes calculation speed, enabling it to process a large number of mathematical problems in a very short time, suitable for application scenarios that require quick feedback, such as online education and real-time data analysis. Its efficient algorithms allow users to get instant results in complex calculations.
qwen-math-turbo-latest
4k
3k
Supported
Conversation
Qwen_qwen
Qwen-Math-Turbo-Latest is the newest version of Qwen-Math-Turbo, further improving calculation efficiency and accuracy. This model has undergone multiple algorithmic optimizations, enabling it to handle more complex mathematical problems and maintain high efficiency in real-time inference. It is suitable for mathematical applications that require rapid response, such as financial analysis and scientific computing.
qwen-max
32k
8k
Supported
Conversation
Qwen_qwen
The Tongyi Qianwen 2.5 series hundred-billion-level ultra-large-scale language model supports input in different languages such as Chinese and English. As the model is upgraded, qwen-max will be updated on a rolling basis.
qwen-max-latest
32k
8k
Supported
Conversation
Qwen_qwen
The best-performing model in the Tongyi Qianwen series. This model is a dynamically updated version, and model updates will not be announced in advance. It is suitable for complex, multi-step tasks. The model's comprehensive abilities in Chinese and English are significantly improved, human preference is significantly enhanced, reasoning ability and complex instruction understanding are significantly strengthened, performance on difficult tasks is better, and math and code abilities are significantly improved. It also has enhanced understanding and generation capabilities for structured data like tables and JSON.
qwen-plus
128k
8k
Supported
Conversation
Qwen_qwen
A well-balanced model in the Tongyi Qianwen series, with inference performance and speed between Tongyi Qianwen-Max and Tongyi Qianwen-Turbo, suitable for moderately complex tasks. The model's comprehensive abilities in Chinese and English are significantly improved, human preference is significantly enhanced, reasoning ability and complex instruction understanding are significantly strengthened, performance on difficult tasks is better, and math and code abilities are significantly improved.
qwen-plus-latest
128k
8k
Supported
Conversation
Qwen_qwen
Qwen-Plus is an enhanced version of the visual language model in the Tongyi Qianwen series, designed to improve detail recognition and text recognition capabilities. This model supports images with resolutions over one million pixels and any aspect ratio, performing excellently in a wide range of visual language tasks, making it suitable for applications requiring high-precision image understanding.
qwen-turbo
128k
8k
Supported
Conversation
Qwen_qwen
The fastest and most cost-effective model in the Tongyi Qianwen series, suitable for simple tasks. The model's comprehensive abilities in Chinese and English are significantly improved, human preference is significantly enhanced, reasoning ability and complex instruction understanding are significantly strengthened, performance on difficult tasks is better, and math and code abilities are significantly improved.
qwen-turbo-latest
1m
8k
Supported
Conversation
Qwen_qwen
Qwen-Turbo is an efficient model designed for simple tasks, emphasizing speed and cost-effectiveness. It performs excellently in basic visual language tasks and is suitable for applications with strict response time requirements, such as real-time image recognition and simple Q&A systems.
qwen-vl-max
32k
2k
Supported
Conversation
Qwen_qwen
Tongyi Qianwen VL-Max (qwen-vl-max), the ultra-large-scale visual language model from Tongyi Qianwen. Compared to the enhanced version, it further improves visual reasoning and instruction-following capabilities, providing a higher level of visual perception and cognition. It offers the best performance on more complex tasks.
qwen-vl-max-latest
32k
2k
Supported
Conversation, Vision
Qwen_qwen
Qwen-VL-Max is the most advanced version in the Qwen-VL series, designed to solve complex multimodal tasks. It combines advanced visual and language processing technologies, capable of understanding and analyzing high-resolution images with extremely strong reasoning abilities, suitable for applications requiring deep understanding and complex reasoning.
qwen-vl-ocr
34k
4k
Supported
Conversation, Vision
Qwen_qwen
Only supports OCR, not conversation.
qwen-vl-ocr-latest
34k
4k
Supported
Conversation, Vision
Qwen_qwen
Only supports OCR, not conversation.
qwen-vl-plus
8k
2k
Supported
Conversation, Vision
Qwen_qwen
Tongyi Qianwen VL-Plus (qwen-vl-plus), the enhanced version of the Tongyi Qianwen large-scale visual language model. It significantly improves detail recognition and text recognition capabilities, supports images with resolutions over one million pixels and any aspect ratio. It provides excellent performance on a wide range of visual tasks.
qwen-vl-plus-latest
32k
2k
Supported
Conversation, Vision
Qwen_qwen
Qwen-VL-Plus-Latest is the newest version of Qwen-VL-Plus, enhancing the model's multimodal understanding capabilities. It excels in the combined processing of images and text, making it suitable for applications that need to efficiently handle multiple input formats, such as intelligent customer service and content generation.
Qwen/Qwen2-1.5B-Instruct
32k
6k
Not Supported
Conversation
Qwen_qwen
Qwen2-1.5B-Instruct is an instruction-tuned large language model in the Qwen2 series with a parameter size of 1.5B. Based on the Transformer architecture, the model uses SwiGLU activation functions, attention QKV biases, and group query attention. It excels in multiple benchmark tests for language understanding, generation, multilingual capabilities, coding, math, and reasoning, surpassing most open-source models.
Qwen/Qwen2-72B-Instruct
128k
6k
Not Supported
Conversation
Qwen_qwen
Qwen2-72B-Instruct is an instruction-tuned large language model in the Qwen2 series with a parameter size of 72B. Based on the Transformer architecture, the model uses SwiGLU activation functions, attention QKV biases, and group query attention. It can handle large-scale inputs. The model excels in multiple benchmark tests for language understanding, generation, multilingual capabilities, coding, math, and reasoning, surpassing most open-source models.
Qwen/Qwen2-7B-Instruct
128k
6k
Not Supported
Conversation
Qwen_qwen
Qwen2-7B-Instruct is an instruction-tuned large language model in the Qwen2 series with a parameter size of 7B. Based on the Transformer architecture, the model uses SwiGLU activation functions, attention QKV biases, and group query attention. It can handle large-scale inputs. The model excels in multiple benchmark tests for language understanding, generation, multilingual capabilities, coding, math, and reasoning, surpassing most open-source models.
Qwen/Qwen2-VL-72B-Instruct
32k
2k
Not Supported
Conversation
Qwen_qwen
Qwen2-VL is the latest iteration of the Qwen-VL model, achieving state-of-the-art performance in visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, and MTVQA. Qwen2-VL can understand videos over 20 minutes long for high-quality video-based Q&A, dialogue, and content creation. It also has complex reasoning and decision-making capabilities, and can be integrated with mobile devices, robots, etc., for automated operations based on visual environments and text instructions.
Qwen/Qwen2-VL-7B-Instruct
32k
-
Not Supported
Conversation
Qwen_qwen
Qwen2-VL-7B-Instruct is the latest iteration of the Qwen-VL model, achieving state-of-the-art performance in visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, and MTVQA. Qwen2-VL can be used for high-quality video-based Q&A, dialogue, and content creation, and also has complex reasoning and decision-making capabilities, and can be integrated with mobile devices, robots, etc., for automated operations based on visual environments and text instructions.
Qwen/Qwen2.5-72B-Instruct
128k
8k
Not Supported
Conversation
Qwen_qwen
Qwen2.5-72B-Instruct is one of the latest large language model series released by Alibaba Cloud. This 72B model has significantly improved capabilities in areas such as coding and mathematics. It supports inputs of up to 128K tokens and can generate long texts of over 8K tokens.
Qwen/Qwen2.5-72B-Instruct-128K
128k
8k
Not Supported
Conversation
Qwen_qwen
Qwen2.5-72B-Instruct is one of the latest large language model series released by Alibaba Cloud. This 72B model has significantly improved capabilities in areas such as coding and mathematics. It supports inputs of up to 128K tokens and can generate long texts of over 8K tokens.
Qwen/Qwen2.5-7B-Instruct
128k
8k
Not Supported
Conversation
Qwen_qwen
Qwen2.5-7B-Instruct is one of the latest large language model series released by Alibaba Cloud. This 7B model has significantly improved capabilities in areas such as coding and mathematics. The model also provides multilingual support, covering over 29 languages, including Chinese and English. The model has significant improvements in instruction following, understanding structured data, and generating structured output (especially JSON).
Qwen/Qwen2.5-Coder-32B-Instruct
128k
8k
Not Supported
Conversation, Code
Qwen_qwen
Qwen2.5-32B-Instruct is one of the latest large language model series released by Alibaba Cloud. This 32B model has significantly improved capabilities in areas such as coding and mathematics. The model also provides multilingual support, covering over 29 languages, including Chinese and English. The model has significant improvements in instruction following, understanding structured data, and generating structured output (especially JSON).
Qwen/Qwen2.5-Coder-7B-Instruct
128k
8k
Not Supported
Conversation
Qwen_qwen
Qwen2.5-7B-Instruct is one of the latest large language model series released by Alibaba Cloud. This 7B model has significantly improved capabilities in areas such as coding and mathematics. The model also provides multilingual support, covering over 29 languages, including Chinese and English. The model has significant improvements in instruction following, understanding structured data, and generating structured output (especially JSON).
Qwen/QwQ-32B-Preview
32k
16k
Not Supported
Conversation, Reasoning
Qwen_qwen
QwQ-32B-Preview is an experimental research model developed by the Qwen team, aimed at enhancing the reasoning capabilities of artificial intelligence. As a preview version, it demonstrates excellent analytical abilities, but also has some important limitations: 1. Language mixing and code-switching: The model may mix languages or switch between languages unexpectedly, affecting the clarity of the response. 2. Recursive reasoning loops: The model may enter a cyclic reasoning mode, leading to lengthy answers without a clear conclusion. 3. Safety and ethical considerations: The model requires strengthened safety measures to ensure reliable and safe performance, and users should exercise caution when using it. 4. Performance and benchmark limitations: The model performs excellently in mathematics and programming, but there is still room for improvement in other areas such as common sense reasoning and nuanced language understanding.
qwen1.5-110b-chat
32k
8k
Not Supported
Conversation
Qwen_qwen
-
qwen1.5-14b-chat
8k
2k
Not Supported
Conversation
Qwen_qwen
-
qwen1.5-32b-chat
32k
2k
Not Supported
Conversation
Qwen_qwen
-
qwen1.5-72b-chat
32k
2k
Not Supported
Conversation
Qwen_qwen
-
qwen1.5-7b-chat
8k
2k
Not Supported
Conversation
Qwen_qwen
-
qwen2-57b-a14b-instruct
65k
6k
Not Supported
Conversation
Qwen_qwen
-
Qwen2-72B-Instruct
-
-
Not Supported
Conversation
Qwen_qwen
-
qwen2-7b-instruct
128k
6k
Not Supported
Conversation
Qwen_qwen
-
qwen2-math-72b-instruct
4k
3k
Not Supported
Conversation
Qwen_qwen
-
qwen2-math-7b-instruct
4k
3k
Not Supported
Conversation
Qwen_qwen
-
qwen2.5-14b-instruct
128k
8k
Not Supported
Conversation
Qwen_qwen
-
qwen2.5-32b-instruct
128k
8k
Not Supported
Conversation
Qwen_qwen
-
qwen2.5-72b-instruct
128k
8k
Not Supported
Conversation
Qwen_qwen
-
qwen2.5-7b-instruct
128k
8k
Not Supported
Conversation
Qwen_qwen
-
qwen2.5-coder-14b-instruct
128k
8k
Not Supported
Conversation, Code
Qwen_qwen
-
qwen2.5-coder-32b-instruct
128k
8k
Not Supported
Conversation, Code
Qwen_qwen
-
qwen2.5-coder-7b-instruct
128k
8k
Not Supported
Conversation, Code
Qwen_qwen
-
qwen2.5-math-72b-instruct
4k
3k
Not Supported
Conversation
Qwen_qwen
-
qwen2.5-math-7b-instruct
4k
3k
Not Supported
Conversation
Qwen_qwen
-
deepseek-ai/DeepSeek-R1
64k
-
Not Supported
Conversation, Reasoning
DeepSeek_deepseek
The DeepSeek-R1 model is an open-source reasoning model based purely on reinforcement learning. It excels in tasks such as mathematics, code, and natural language reasoning, with performance comparable to OpenAI's o1 model and achieving excellent results in several benchmark tests.
deepseek-ai/DeepSeek-V2-Chat
128k
-
Not Supported
Conversation
DeepSeek_deepseek
DeepSeek-V2 is a powerful, cost-effective Mixture-of-Experts (MoE) language model. It was pre-trained on a high-quality corpus of 8.1 trillion tokens and further enhanced with Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). Compared to DeepSeek 67B, DeepSeek-V2 achieves stronger performance while saving 42.5% in training costs, reducing KV cache by 93.3%, and increasing maximum generation throughput by 5.76 times.
deepseek-ai/DeepSeek-V2.5
32k
-
Supported
Conversation
DeepSeek_deepseek
DeepSeek-V2.5 is an upgraded version of DeepSeek-V2-Chat and DeepSeek-Coder-V2-Instruct, integrating the general and coding capabilities of the two previous versions. This model has been optimized in several aspects, including writing and instruction-following abilities, to better align with human preferences.
deepseek-ai/DeepSeek-V3
128k
4k
Not Supported
Conversation
DeepSeek_deepseek
Open-source version of deepseek. Compared to the official version, it has a longer context and no issues with sensitive word refusal.
deepseek-chat
64k
8k
Supported
Conversation
DeepSeek_deepseek
236B parameters, 64K context (API), top-ranked on the open-source leaderboard for Chinese comprehensive ability (AlignBench), and in the same tier as closed-source models like GPT-4-Turbo and ERNIE 4.0 in evaluations.
deepseek-coder
64k
8k
Supported
Conversation, Code
DeepSeek_deepseek
236B parameters, 64K context (API), top-ranked on the open-source leaderboard for Chinese comprehensive ability (AlignBench), and in the same tier as closed-source models like GPT-4-Turbo and ERNIE 4.0 in evaluations.
deepseek-reasoner
64k
8k
Supported
Conversation, Reasoning
DeepSeek_deepseek
DeepSeek-Reasoner (DeepSeek-R1) is the latest reasoning model from DeepSeek, designed to enhance reasoning capabilities through reinforcement learning training. The model's reasoning process involves a large amount of reflection and validation, enabling it to handle complex logical reasoning tasks, with a chain-of-thought length that can reach tens of thousands of words. DeepSeek-R1 excels in solving mathematical, coding, and other complex problems and has been widely applied in various scenarios, demonstrating its powerful reasoning ability and flexibility. Compared to other models, DeepSeek-R1's reasoning performance is close to that of top-tier closed-source models, showcasing the potential and competitiveness of open-source models in the field of reasoning.
hunyuan-code
4k
4k
Not Supported
Conversation, Code
Tencent_hunyuan
Hunyuan's latest code generation model. The base model was augmented with 200B high-quality code data and trained with high-quality SFT data for half a year. The context window length has been increased to 8K. It ranks at the top in automatic evaluation metrics for code generation in five major languages. In high-quality manual evaluations of 10 comprehensive code tasks across five major languages, its performance is in the top tier.
hunyuan-functioncall
28k
4k
Supported
Conversation
Tencent_hunyuan
Hunyuan's latest MOE architecture FunctionCall model, trained with high-quality FunctionCall data, with a context window of up to 32K, leading in evaluation metrics across multiple dimensions.
hunyuan-large
28k
4k
Not Supported
Conversation
Tencent_hunyuan
The Hunyuan-large model has a total of about 389B parameters, with about 52B activated parameters, making it the open-source MoE model with the largest parameter scale and best performance in the industry.
hunyuan-large-longcontext
128k
6k
Not Supported
Conversation
Tencent_hunyuan
Excels at handling long-text tasks such as document summarization and document Q&A, while also being capable of handling general text generation tasks. It performs excellently in the analysis and generation of long texts, effectively handling complex and detailed long-form content processing needs.
hunyuan-lite
250k
6k
Not Supported
Conversation
Tencent_hunyuan
Upgraded to an MOE structure with a 256k context window, leading many open-source models in NLP, code, math, and industry-specific evaluation sets.
hunyuan-pro
28k
4k
Supported
Conversation
Tencent_hunyuan
A trillion-parameter scale MOE-32K long-text model. It achieves an absolute leading level on various benchmarks, with complex instruction and reasoning capabilities, complex mathematical abilities, and supports functioncall. It is specially optimized for applications in multilingual translation, finance, law, and medicine.
hunyuan-role
28k
4k
Not Supported
Conversation
Tencent_hunyuan
Hunyuan's latest role-playing model. This is a role-playing model officially fine-tuned and launched by Hunyuan, based on the Hunyuan model and augmented with role-playing scenario datasets, providing better foundational performance in role-playing scenarios.
hunyuan-standard
30k
2k
Not Supported
Conversation
Tencent_hunyuan
Adopts a better routing strategy, while also alleviating the problems of load balancing and expert convergence. MOE-32K has a relatively higher cost-performance ratio and can handle long text inputs while balancing performance and price.
hunyuan-standard-256K
250k
6k
Not Supported
Conversation
Tencent_hunyuan
Adopts a better routing strategy, while also alleviating the problems of load balancing and expert convergence. For long texts, the "needle in a haystack" metric reaches 99.9%. MOE-256K further breaks through in length and performance, greatly expanding the input length.
hunyuan-translation-lite
4k
4k
Not Supported
Conversation
Tencent_hunyuan
The Hunyuan translation model supports natural language conversational translation; it supports mutual translation between Chinese and 15 languages including English, Japanese, French, Portuguese, Spanish, Turkish, Russian, Arabic, Korean, Italian, German, Vietnamese, Malay, and Indonesian.
hunyuan-turbo
28k
4k
Supported
Conversation
Tencent_hunyuan
The default version of the Hunyuan-turbo model, which uses a new Mixture-of-Experts (MoE) structure, resulting in faster inference efficiency and stronger performance compared to hunyuan-pro.
hunyuan-turbo-latest
28k
4k
Supported
Conversation
Tencent_hunyuan
The dynamically updated version of the Hunyuan-turbo model. It is the best-performing version in the Hunyuan model series, consistent with the C-end (Tencent Yuanbao).
hunyuan-turbo-vision
8k
2k
Supported
Vision, Conversation
Tencent_hunyuan
Hunyuan's new generation flagship visual language model, using a new Mixture-of-Experts (MoE) structure. Its capabilities in basic recognition, content creation, knowledge Q&A, and analysis/reasoning related to image-text understanding are comprehensively improved compared to the previous generation model. Max input 6k, max output 2k.
hunyuan-vision
8k
2k
Supported
Conversation, Vision
Tencent_hunyuan
Hunyuan's latest multimodal model, supporting image + text input to generate text content. Basic Image Recognition: Recognizes subjects, elements, scenes, etc., in images. Image Content Creation: Summarizes images, creates advertising copy, social media posts, poems, etc. Multi-turn Image Dialogue: Engages in multi-turn interactive Q&A about a single image. Image Analysis and Reasoning: Performs statistical analysis on logical relationships, math problems, code, and charts in images. Image Knowledge Q&A: Answers questions about knowledge points contained in images, such as historical events, movie posters. Image OCR: Recognizes text in images from natural life scenes and non-natural scenes.
SparkDesk-Lite
4k
-
Not Supported
Conversation
Spark_SparkDesk
Supports online web search function, with fast and convenient responses, suitable for low-power inference and model fine-tuning and other customized scenarios.
SparkDesk-Max
128k
-
Supported
Conversation
Spark_SparkDesk
Quantized from the latest Spark Large Model Engine 4.0 Turbo. It supports multiple built-in plugins such as web search, weather, and date. Core capabilities are fully upgraded, with universal improvements in application effects across various scenarios. Supports System role persona and FunctionCall.
SparkDesk-Max-32k
32k
-
Supported
Conversation
Spark_SparkDesk
Stronger reasoning: Enhanced context understanding and logical reasoning abilities. Longer input: Supports 32K tokens of text input, suitable for long document reading, private knowledge Q&A, and other scenarios.
SparkDesk-Pro
128k
-
Not Supported
Conversation
Spark_SparkDesk
Specially optimized for scenarios such as math, code, medicine, and education. Supports multiple built-in plugins like web search, weather, and date, covering most knowledge Q&A, language understanding, and text creation scenarios.
SparkDesk-Pro-128K
128k
-
Not Supported
Conversation
Spark_SparkDesk
Professional-grade large language model with tens of billions of parameters. It has been specially optimized for scenarios in medicine, education, and code, with lower latency in search scenarios. Suitable for business scenarios that have higher requirements for performance and response speed, such as text and intelligent Q&A.
moonshot-v1-128k
128k
4k
Supported
Conversation
Moonshot AI_moonshot
A model with a length of 8k, suitable for generating short text.
moonshot-v1-32k
32k
4k
Supported
Conversation
Moonshot AI_moonshot
A model with a length of 32k, suitable for generating long text.
moonshot-v1-8k
8k
4k
Supported
Conversation
Moonshot AI_moonshot
A model with a length of 128k, suitable for generating ultra-long text.
codegeex-4
128k
4k
Not Supported
Conversation, Code
Zhipu_codegeex
Zhipu's code model: suitable for automatic code completion tasks.
charglm-3
4k
2k
Not Supported
Conversation
Zhipu_glm
Persona model.
emohaa
8k
4k
Not Supported
Conversation
Zhipu_glm
Psychology model: possesses professional counseling abilities to help users understand emotions and cope with emotional problems.
glm-3-turbo
128k
4k
Not Supported
Conversation
Zhipu_glm
To be deprecated (June 30, 2025).
glm-4
128k
4k
Supported
Conversation
Zhipu_glm
Old flagship: released on January 16, 2024, now replaced by GLM-4-0520.
glm-4-0520
128k
4k
Supported
Conversation
Zhipu_glm
High-intelligence model: suitable for handling highly complex and diverse tasks.
glm-4-air
128k
4k
Supported
Conversation
Zhipu_glm
High cost-performance: the most balanced model between inference capability and price.
glm-4-airx
8k
4k
Supported
Conversation
Zhipu_glm
Extremely fast inference: has ultra-fast inference speed and powerful inference effects.
glm-4-flash
128k
4k
Supported
Conversation
Zhipu_glm
High speed, low price: ultra-fast inference speed.
glm-4-flashx
128k
4k
Supported
Conversation
Zhipu_glm
High speed, low price: Enhanced version of Flash, ultra-fast inference speed.
glm-4-long
1m
4k
Supported
Conversation
Zhipu_glm
Ultra-long input: specially designed for handling ultra-long text and memory-intensive tasks.
glm-4-plus
128k
4k
Supported
Conversation
Zhipu_glm
High-intelligence flagship: comprehensive performance improvement, with significantly enhanced long-text and complex task capabilities.
glm-4v
2k
-
Not Supported
Conversation, Vision
Zhipu_glm
Image understanding: possesses image understanding and reasoning capabilities.
glm-4v-flash
2k
1k
Not Supported
Conversation, Vision
Zhipu_glm
Free model: possesses powerful image understanding capabilities.









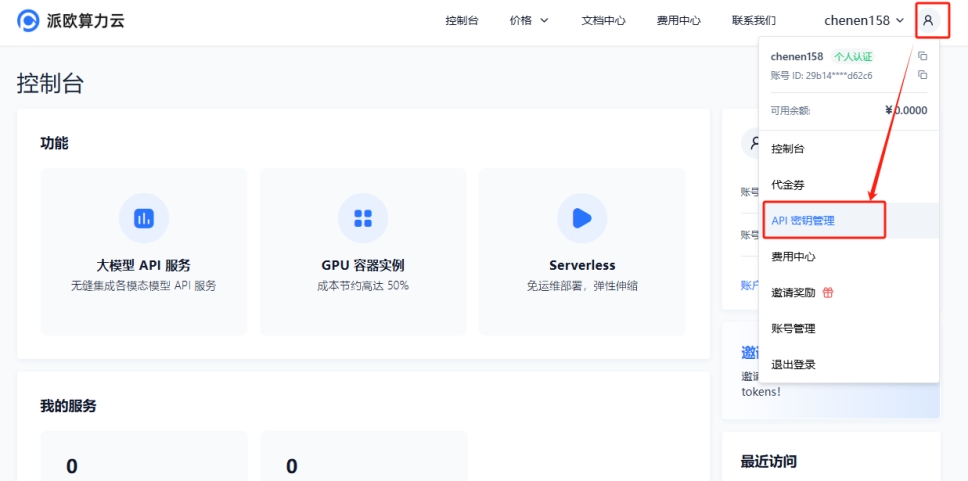



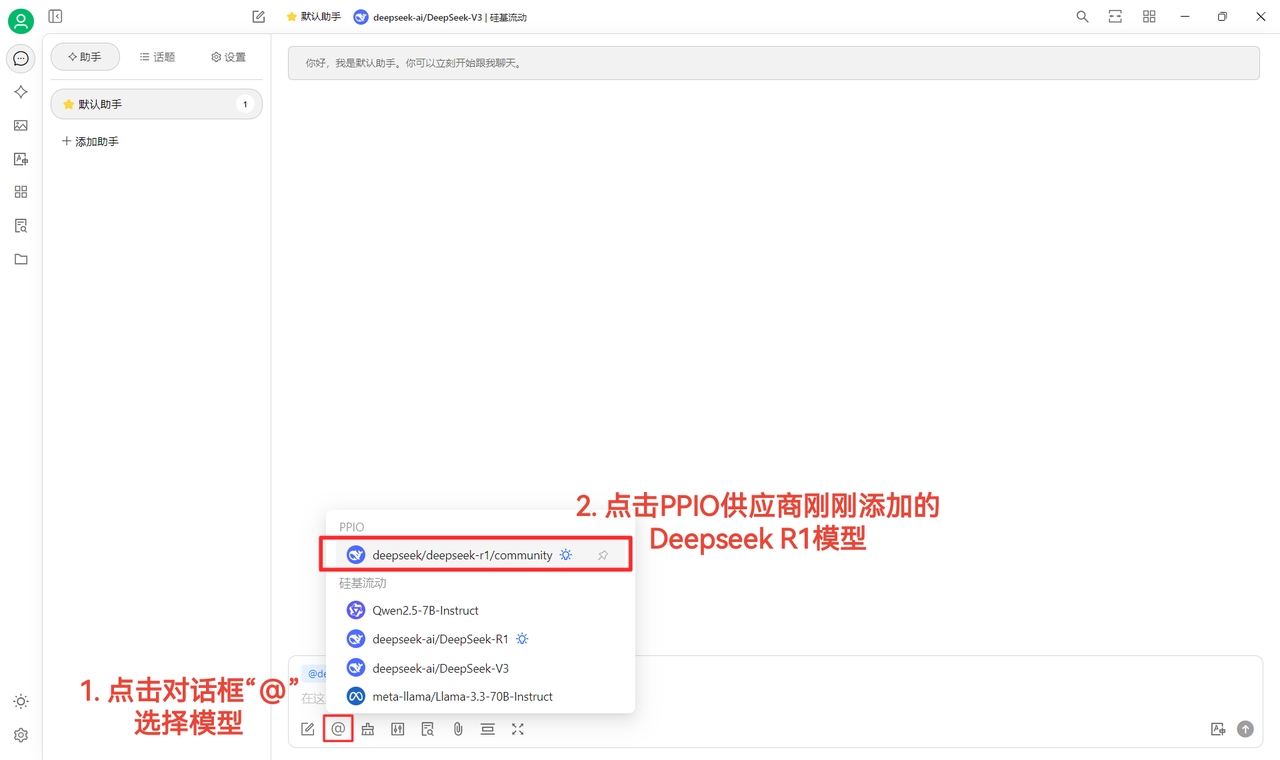





This document was translated from Chinese by AI and has not yet been reviewed.
This is a leaderboard based on data from Chatbot Arena (lmarena.ai), generated through an automated process.
Data Updated: 2025-06-12 11:42:10 UTC / 2025-06-12 19:42:10 CST (Beijing Time)
1
1
1478
+6/-7
7,343
Proprietary
No data
2
2
1446
+6/-7
12,351
Proprietary
No data
3
2
1425
+4/-5
15,210
OpenAI
Proprietary
No data
3
4
1423
+4/-4
19,762
OpenAI
Proprietary
No data
3
6
1420
+5/-5
12,614
Proprietary
No data
3
8
1417
+4/-4
21,879
xAI
Proprietary
No data
5
4
1411
+4/-5
15,271
OpenAI
Proprietary
No data
8
8
1396
+5/-6
14,148
Proprietary
No data
9
7
1384
+4/-5
13,830
OpenAI
Proprietary
No data
9
11
1382
+4/-4
16,550
DeepSeek
MIT
No data
11
5
1373
+4/-4
13,850
Anthropic
Proprietary
No data
11
16
1372
+6/-7
5,944
Tencent
Proprietary
No data
11
11
1371
+3/-4
19,430
DeepSeek
MIT
No data
11
16
1363
+6/-5
12,003
Mistral
Proprietary
No data
12
44
1361
+8/-6
6,636
xAI
Proprietary
No data
13
11
1363
+4/-3
29,038
OpenAI
Proprietary
No data
13
21
1362
+3/-3
34,240
Proprietary
No data
13
10
1361
+6/-5
13,554
OpenAI
Proprietary
No data
14
28
1360
+4/-5
10,677
Alibaba
Apache 2.0
No data
14
19
1358
+3/-3
29,484
Alibaba
Proprietary
No data
15
21
1355
+4/-5
20,295
Gemma
No data
21
16
1348
+3/-2
33,177
OpenAI
Proprietary
2023/10
21
9
1345
+5/-6
10,740
Anthropic
Proprietary
No data
23
20
1338
+4/-6
19,404
OpenAI
Proprietary
No data
23
16
1336
+5/-5
12,702
OpenAI
Proprietary
No data
23
28
1334
+7/-8
3,976
Gemma
No data
23
38
1330
+11/-11
2,595
Amazon
Proprietary
No data
24
26
1332
+3/-4
22,841
DeepSeek
DeepSeek
No data
24
47
1330
+5/-5
15,930
Alibaba
Apache 2.0
No data
25
28
1324
+8/-7
6,055
Alibaba
Proprietary
No data
26
28
1326
+3/-4
26,104
Proprietary
No data
26
32
1324
+6/-7
6,028
Zhipu
Proprietary
No data
27
28
1323
+4/-3
20,084
Cohere
CC-BY-NC-4.0
No data
27
27
1316
+10/-8
2,452
Tencent
Proprietary
No data
28
35
1318
+7/-6
5,126
StepFun
Proprietary
No data
30
28
1319
+3/-3
32,421
OpenAI
Proprietary
No data
30
35
1310
+11/-8
2,371
Nvidia
Nvidia
No data
30
28
1310
+11/-11
2,510
Tencent
Proprietary
No data
31
35
1317
+2/-2
54,951
OpenAI
Proprietary
2023/10
32
28
1316
+2/-2
58,645
Proprietary
No data
32
18
1313
+4/-4
21,310
Anthropic
Proprietary
No data
38
52
1301
+8/-8
3,913
Gemma
No data
39
17
1306
+3/-3
25,983
Anthropic
Proprietary
No data
40
38
1301
+2/-2
67,084
xAI
Proprietary
2024/3
40
43
1301
+4/-3
28,968
01 AI
Proprietary
No data
42
31
1298
+2/-2
117,747
OpenAI
Proprietary
2023/10
42
53
1296
+5/-6
10,715
Alibaba
Proprietary
No data
43
21
1297
+2/-2
73,327
Anthropic
Proprietary
2024/4
43
46
1293
+7/-5
7,243
DeepSeek
DeepSeek
No data
46
69
1289
+8/-10
4,321
Gemma
No data
47
43
1285
+9/-7
3,856
Tencent
Proprietary
No data
48
55
1289
+3/-3
26,074
NexusFlow
NexusFlow
No data
48
51
1287
+4/-3
27,788
Zhipu AI
Proprietary
No data
48
37
1287
+4/-5
13,750
Meta
Llama 4
No data
48
44
1284
+8/-7
6,302
OpenAI
Proprietary
No data
49
52
1285
+3/-2
72,536
OpenAI
Proprietary
2023/10
49
62
1285
+3/-3
37,021
Proprietary
No data
49
71
1282
+6/-6
7,577
Nvidia
Llama 3.1
2023/12
51
35
1282
+2/-3
43,788
Meta
Llama 3.1 Community
2023/12
52
33
1282
+2/-2
86,159
Anthropic
Proprietary
2024/4
52
51
1274
+10/-9
4,014
Tencent
Proprietary
No data
53
35
1281
+2/-2
63,038
Meta
Llama 3.1 Community
2023/12
53
35
1280
+3/-2
52,144
Proprietary
Online
54
69
1280
+2/-3
55,442
xAI
Proprietary
2024/3
55
37
1279
+3/-3
47,973
OpenAI
Proprietary
2023/10
55
53
1277
+4/-4
17,432
Alibaba
Qwen
No data
65
49
1273
+2/-2
82,435
Proprietary
2023/11
65
64
1272
+2/-5
26,344
DeepSeek
DeepSeek
No data
65
70
1271
+2/-3
41,519
Alibaba
Qwen
2024/9
65
51
1270
+3/-3
44,800
Meta
Llama-3.3
No data
65
69
1263
+10/-11
2,484
Mistral
Apache 2.0
No data
66
47
1270
+2/-2
102,133
OpenAI
Proprietary
2023/12
69
54
1265
+2/-3
48,217
Mistral
Mistral Research
2024/7
69
67
1264
+4/-3
20,580
NexusFlow
CC-BY-NC-4.0
2024/7
71
74
1258
+8/-8
3,010
Ai2
Llama 3.1
No data
72
52
1263
+1/-2
103,748
OpenAI
Proprietary
2023/4
72
70
1262
+2/-2
29,633
Mistral
MRL
No data
72
77
1261
+3/-2
58,637
Meta
Llama 3.1 Community
2023/12
73
49
1261
+1/-2
202,641
Anthropic
Proprietary
2023/8
74
78
1258
+3/-4
26,371
Amazon
Proprietary
No data
75
57
1258
+2/-2
97,079
OpenAI
Proprietary
2023/12
80
52
1251
+3/-3
44,893
Anthropic
Propretary
No data
80
77
1249
+6/-5
7,948
Reka AI
Proprietary
No data
84
80
1240
+2/-2
65,661
Proprietary
2023/11
84
78
1235
+6/-5
9,125
AI21 Labs
Jamba Open
2024/3
84
88
1231
+7/-6
5,730
Alibaba
Apache 2.0
No data
85
80
1233
+2/-2
79,538
Gemma license
2024/6
85
88
1231
+5/-4
15,321
Mistral
Apache 2.0
No data
85
95
1230
+3/-4
20,646
Amazon
Proprietary
No data
85
82
1230
+6/-5
10,548
Princeton
MIT
2024/7
85
83
1229
+4/-6
10,535
Cohere
CC-BY-NC-4.0
2024/8
85
77
1225
+8/-7
3,889
Nvidia
Llama 3.1
2023/12
87
99
1226
+3/-2
37,697
Proprietary
No data
87
96
1219
+9/-10
3,460
Allen AI
Apache-2.0
No data
89
94
1223
+3/-3
28,768
Cohere
CC-BY-NC-4.0
No data
89
86
1223
+4/-5
20,608
Nvidia
NVIDIA Open Model
2023/6
89
91
1220
+5/-6
10,221
Zhipu AI
Proprietary
No data
89
85
1219
+6/-6
8,132
Reka AI
Proprietary
No data
93
88
1220
+2/-2
163,629
Meta
Llama 3 Community
2023/12
93
101
1219
+3/-3
25,213
Microsoft
MIT
No data
97
86
1214
+2/-2
113,067
Anthropic
Proprietary
2023/8
98
109
1211
+4/-3
20,654
Amazon
Proprietary
No data
99
109
1202
+12/-11
2,901
Tencent
Proprietary
No data
103
98
1206
+3/-2
57,197
Gemma license
2024/6
103
96
1203
+2/-2
80,846
Cohere
CC-BY-NC-4.0
2024/3
103
111
1199
+9/-9
3,074
Ai2
Llama 3.1
No data
104
98
1201
+3/-3
38,872
Alibaba
Qianwen LICENSE
2024/6
104
83
1200
+3/-3
55,962
OpenAI
Proprietary
2021/9
104
109
1196
+7/-7
5,111
Mistral
MRL
No data
105
111
1193
+5/-5
10,391
Cohere
CC-BY-NC-4.0
No data
105
100
1193
+7/-4
10,851
Cohere
CC-BY-NC-4.0
2024/8
107
101
1193
+2/-2
122,309
Anthropic
Proprietary
2023/8
107
95
1192
+4/-4
15,753
DeepSeek AI
DeepSeek License
2024/6
107
109
1189
+5/-6
9,274
AI21 Labs
Jamba Open
2024/3
108
126
1189
+2/-3
52,578
Meta
Llama 3.1 Community
2023/12
116
94
1177
+2/-2
91,614
OpenAI
Proprietary
2021/9
116
111
1175
+3/-3
27,430
Alibaba
Qianwen LICENSE
2024/4
116
144
1166
+11/-9
3,410
Alibaba
Apache 2.0
No data
117
126
1171
+4/-3
25,135
01 AI
Apache-2.0
2024/5
117
111
1171
+2/-3
64,926
Mistral
Proprietary
No data
117
111
1169
+4/-4
16,027
Reka AI
Proprietary
Online
119
120
1165
+2/-2
109,056
Meta
Llama 3 Community
2023/3
120
133
1162
+5/-7
10,599
InternLM
Other
2024/8
121
115
1162
+2/-3
56,398
Cohere
CC-BY-NC-4.0
2024/3
121
120
1161
+3/-3
35,556
Mistral
Proprietary
No data
121
114
1161
+2/-2
53,751
Mistral
Apache 2.0
2024/4
121
118
1161
+3/-3
25,803
Reka AI
Proprietary
2023/11
121
115
1161
+3/-3
40,658
Alibaba
Qianwen LICENSE
2024/2
121
121
1156
+8/-9
3,289
IBM
Apache 2.0
No data
122
133
1157
+2/-3
48,892
Gemma license
2024/7
130
115
1145
+4/-4
18,800
Proprietary
2023/4
130
126
1141
+8/-8
4,854
HuggingFace
Apache 2.0
2024/4
131
129
1139
+4/-4
22,765
Alibaba
Qianwen LICENSE
2024/2
131
135
1133
+8/-7
3,380
IBM
Apache 2.0
No data
132
133
1136
+3/-4
26,105
Microsoft
MIT
2023/10
132
143
1132
+4/-4
16,676
Nexusflow
Apache-2.0
2024/3
135
133
1128
+3/-2
76,126
Mistral
Apache 2.0
2023/12
135
138
1125
+4/-4
15,917
01 AI
Yi License
2023/6
135
125
1124
+7/-7
6,557
Proprietary
2023/4
136
136
1122
+5/-3
18,687
Alibaba
Qianwen LICENSE
2024/2
136
135
1120
+6/-4
8,383
Microsoft
Llama 2 Community
2023/8
138
123
1119
+3/-2
68,867
OpenAI
Proprietary
2021/9
138
143
1116
+7/-6
8,390
Meta
Llama 3.2
2023/12
139
133
1117
+3/-3
33,743
Databricks
DBRX LICENSE
2023/12
139
140
1116
+4/-4
18,476
Microsoft
MIT
2023/10
139
143
1113
+7/-5
6,658
AllenAI/UW
AI2 ImpACT Low-risk
2023/11
143
133
1107
+8/-7
7,002
IBM
Apache 2.0
No data
145
138
1105
+5/-4
12,990
OpenChat
Apache-2.0
2024/1
146
152
1106
+3/-3
39,595
Meta
Llama 2 Community
2023/7
146
144
1104
+3/-4
22,936
LMSYS
Non-commercial
2023/8
146
148
1102
+6/-5
10,415
UC Berkeley
CC-BY-NC-4.0
2023/11
147
138
1103
+2/-3
34,173
Snowflake
Apache 2.0
2024/4
147
156
1098
+7/-8
3,836
NousResearch
Apache-2.0
2024/1
147
154
1094
+10/-9
3,636
Nvidia
Llama 2 Community
2023/11
151
140
1097
+3/-4
25,070
Gemma license
2024/2
152
143
1090
+9/-8
4,988
DeepSeek AI
DeepSeek License
2023/11
153
141
1090
+6/-5
8,106
OpenChat
Apache-2.0
2023/11
153
143
1088
+7/-11
5,088
NousResearch
Apache-2.0
2023/11
153
148
1087
+6/-7
7,191
IBM
Apache 2.0
No data
154
159
1083
+8/-10
4,872
Alibaba
Qianwen LICENSE
2024/2
155
159
1086
+4/-5
20,067
Mistral
Apache-2.0
2023/12
155
159
1084
+5/-5
12,808
Microsoft
MIT
2023/10
155
135
1081
+5/-4
17,036
OpenAI
Proprietary
2021/9
155
154
1076
+11/-13
1,714
Cognitive Computations
Apache-2.0
2023/10
157
163
1080
+4/-3
21,097
Microsoft
MIT
2023/10
157
159
1076
+8/-10
4,286
Upstage AI
CC-BY-NC-4.0
2023/11
160
163
1077
+3/-4
19,722
Meta
Llama 2 Community
2023/7
161
159
1072
+7/-7
7,176
Microsoft
Llama 2 Community
2023/7
165
169
1067
+6/-6
8,523
Meta
Llama 3.2
2023/12
166
167
1067
+4/-5
11,321
HuggingFace
MIT
2023/10
166
162
1060
+12/-10
2,375
HuggingFace
Apache 2.0
No data
166
159
1059
+9/-12
2,644
MosaicML
CC-BY-NC-SA-4.0
2023/6
166
168
1056
+9/-6
7,509
Meta
Llama 2 Community
2023/7
166
168
1055
+16/-17
1,192
Meta
Llama 2 Community
2024/1
166
163
1054
+15/-14
1,811
HuggingFace
MIT
2023/10
169
159
1048
+16/-16
1,327
TII
Falcon-180B TII License
2023/9
171
162
1055
+4/-4
19,775
LMSYS
Llama 2 Community
2023/7
171
169
1051
+6/-5
9,176
Gemma license
2024/2
171
168
1050
+3/-4
21,622
Microsoft
MIT
2023/10
171
183
1050
+4/-6
14,532
Meta
Llama 2 Community
2023/7
171
162
1048
+9/-7
5,065
Alibaba
Qianwen LICENSE
2023/8
171
169
1046
+11/-12
2,996
UW
Non-commercial
2023/5
180
174
1034
+5/-4
11,351
Gemma license
2024/2
180
176
1031
+8/-8
5,276
Together AI
Apache 2.0
2023/12
181
189
1029
+6/-8
6,503
Allen AI
Apache-2.0
2024/2
184
181
1021
+7/-6
9,142
Mistral
Apache 2.0
2023/9
184
183
1018
+6/-6
7,017
LMSYS
Llama 2 Community
2023/7
184
172
1017
+7/-6
8,713
Proprietary
2021/6
188
187
1003
+9/-9
4,918
Gemma license
2024/2
189
185
1002
+5/-6
7,816
Alibaba
Qianwen LICENSE
2024/2
191
190
978
+6/-8
7,020
UC Berkeley
Non-commercial
2023/4
191
191
968
+8/-8
4,763
Tsinghua
Apache-2.0
2023/10
193
190
946
+14/-15
1,788
Nomic AI
Non-commercial
2023/3
193
191
942
+9/-9
3,997
MosaicML
CC-BY-NC-SA-4.0
2023/5
193
196
938
+13/-14
2,713
Tsinghua
Apache-2.0
2023/6
193
196
935
+9/-8
4,920
RWKV
Apache 2.0
2023/4
197
191
915
+6/-9
5,864
Stanford
Non-commercial
2023/3
197
196
906
+8/-9
6,368
OpenAssistant
Apache 2.0
2023/4
198
199
892
+9/-10
4,983
Tsinghua
Non-commercial
2023/3
199
199
881
+8/-9
4,288
LMSYS
Apache 2.0
2023/4
201
201
853
+10/-10
3,336
Stability AI
CC-BY-NC-SA-4.0
2023/4
201
199
836
+12/-12
3,480
Databricks
MIT
2023/4
202
200
813
+14/-12
2,446
Meta
Non-commercial
2023/2
Rank (UB): A ranking calculated based on the Bradley-Terry model. This rank reflects the model's overall performance in the arena and provides an upper bound estimate of its Elo score, helping to understand the model's potential competitiveness.
Rank (StyleCtrl): The ranking after applying dialogue style control. This ranking aims to reduce preference bias caused by the model's response style (e.g., verbosity, conciseness) to more purely evaluate its core capabilities.
Model Name: The name of the Large Language Model (LLM). This column has embedded links to the models; click to navigate.
Score: The Elo rating the model received from user votes in the arena. The Elo rating is a relative ranking system where a higher score indicates better performance. This score is dynamic and reflects the model's relative strength in the current competitive environment.
Confidence Interval: The 95% confidence interval for the model's Elo rating (e.g., +6/-6). A smaller interval indicates that the model's rating is more stable and reliable; conversely, a larger interval may suggest insufficient data or significant performance fluctuations. It provides a quantitative assessment of the rating's accuracy.
Votes: The total number of votes the model has received in the arena. A higher number of votes generally means higher statistical reliability of its rating.
Provider: The organization or company that provides the model.
License: The type of license for the model, such as Proprietary, Apache 2.0, MIT, etc.
Knowledge Cutoff: The knowledge cutoff date for the model's training data. No data indicates that the relevant information is not provided or is unknown.
The data for this leaderboard is automatically generated and provided by the fboulnois/llm-leaderboard-csv project, which sources and processes data from lmarena.ai. This leaderboard is updated daily via GitHub Actions.
This report is for reference only. The leaderboard data is dynamic and based on user preference votes on Chatbot Arena over a specific period. The completeness and accuracy of the data depend on the upstream data source and the updates and processing from the fboulnois/llm-leaderboard-csv project. Different models may have different license agreements; please refer to the official documentation from the model provider before use.
